[toc]
一、基本概念:索引、文档和 REST API
¶文档
-
Elasticsearch 是面向文档的,文档是所有可搜索数据的最小单位,以下都可以理解为一个文档
- 日志文件中的日志项
- 一本电影的具体信息、一张唱片的详细信息
- MP3播放器里的一首歌、一篇 PDF 文档中的具体内容
从数据结构的定位上来讲可以类比到关系型数据库中的行或者记录(row/record)。
-
文档会被序列化成 JSON 格式,保存在 Elasticsearch 中
- JSON 对象由字段组成
- 每个字段都有对应的字段类型(字符串、数值、布尔、日期、二进制、范围类型)
- JSON 文档,格式灵活,不需要预先定义格式,字段类型可以指定或者通过 Elasticsearch 自动推算
- 支持数组、支持嵌套
下面是一个 CSV 文件的一行数据导入 Es 之后转换成的一个 JSON 文档:
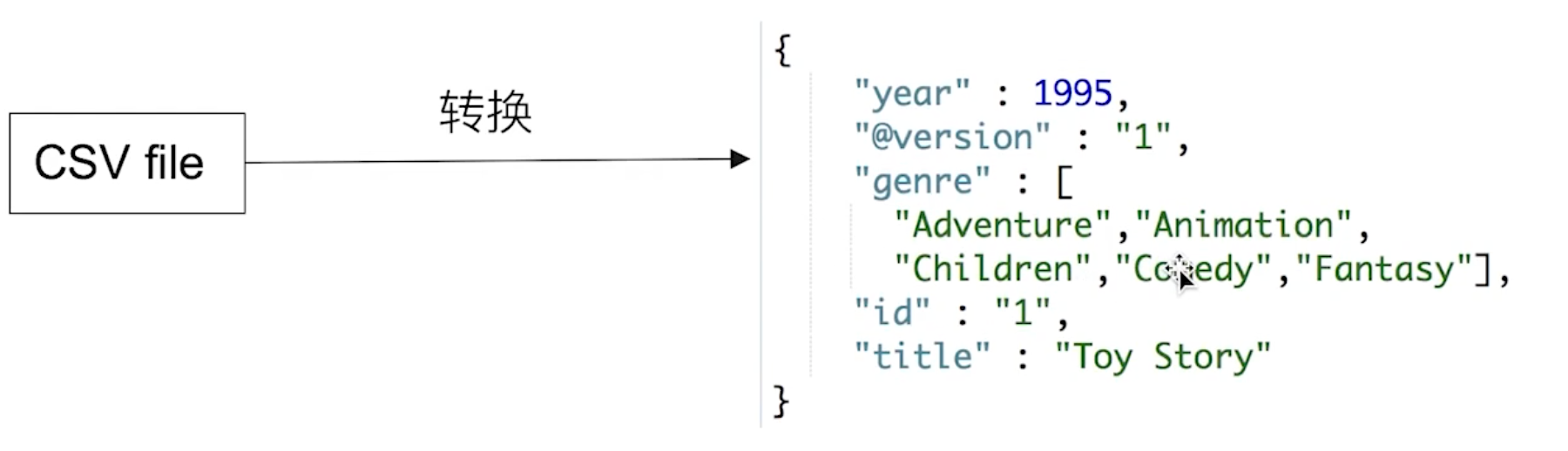
-
每个文档都有一个 Unique ID
- 可以自己指定 ID
- 或者通过 Elasticsearch 自动生成
-
文档的元数据,用于标注文档的相关信息
- _index:文档所属的索引名
- _type:文档的类型的名称
- _id:文档唯一 ID
- _source:文档的原始 JSON 数据
- _all:整合所有字段内容到该字段,7.0开始已被废除。(早期是将所有这些字段整合到这一个字段,方便文档的检索)
- _version:文档的版本信息(当有大量数据并发读写的时候,可以解决文档冲突问题)
- _score:相关性打分
¶索引
-
Index:索引是文档的容器,是一类相似文档的集合
- Index 体现了逻辑空间的概念:每个索引都有自己的 Mapping 定义,用于定义包含的文档的字段名和字段类型
- Shard 体现了物理空间的概念:索引中的数据分散在 Shard 上。

-
索引的 Mapping 和 Settings
- Mapping 定义文档字段的类型
- Setting 定义不同的数据分布(Shard)
-
索引的不同语意
- 名称:一个 Elasticsearch 集群中,可以创建很多不同的索引
- 动词:保存一个文档到 Elasticsearch 的过程也叫索引(indexing)
- ES 中,创建一个倒排索引的过程
- 名称:一个 B 树索引,一个倒排索引
-
Type
- 在7.0之前,一个 Index 可以设置多个 Type,每个 Type 下面拥有一些相同结构的文档
- 6.0开始,Type 已经被 Deprecated。7.0开始,一个索引只能创建一个 Type–“_doc”。
¶抽象与类比
-
传统关系型数据库和 ES概念类比
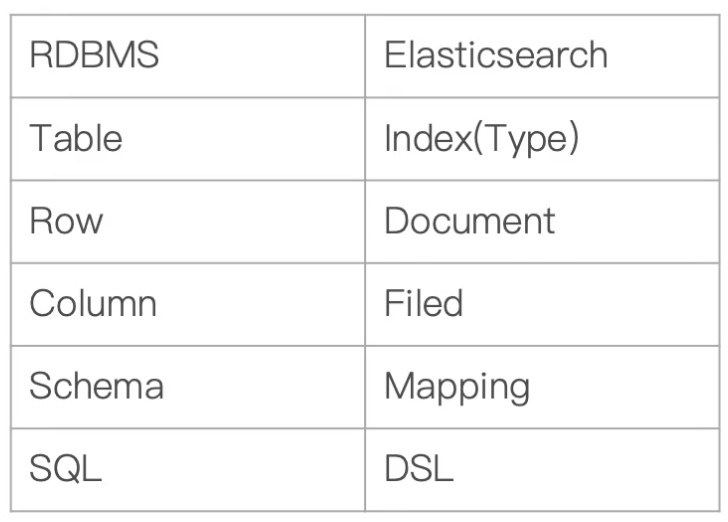
-
两者区别:
- Elasticsearch:Schemaless、相关性、高性能全文检索
- RDBMS:事务性、Join
¶REST API
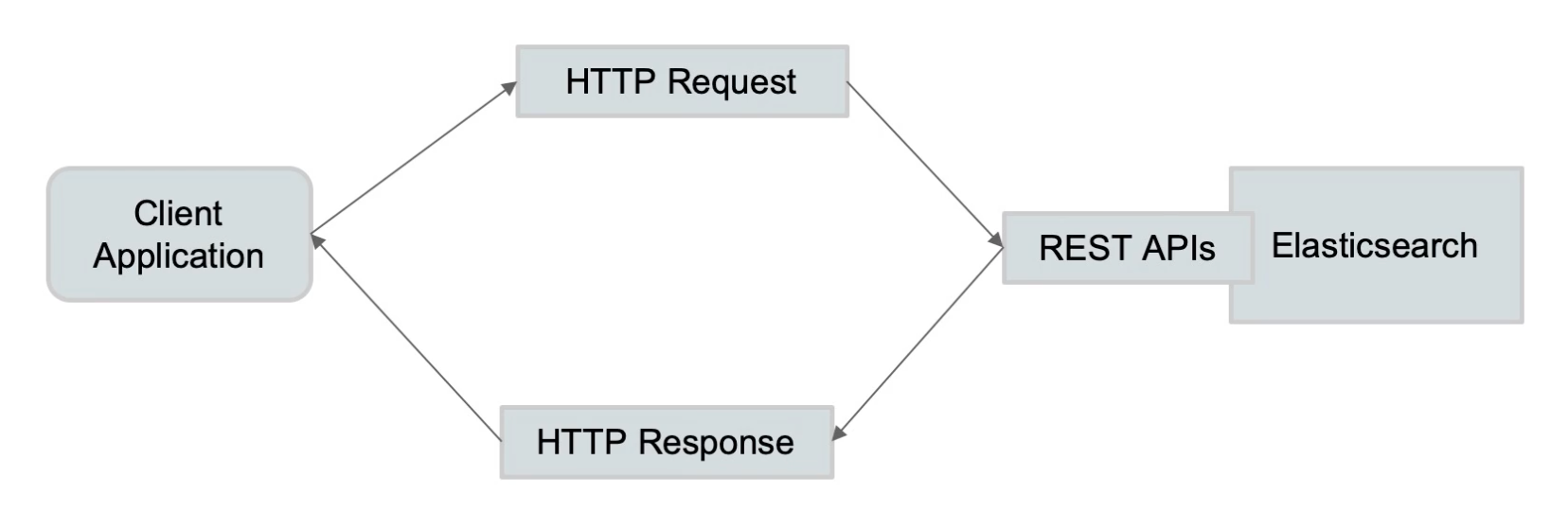
Elasticsearch 支持 Transport API 和 REST API,推荐使用 REST API。
¶一些基本的 API
-
Indices
- 创建 Index
- PUT Movies
- 查看所有 Index
- _cat/indices
- 创建 Index
-
API 尝试
#查看索引相关信息 GET kibana_sample_data_ecommerce #查看索引的文档总数 GET kibana_sample_data_ecommerce/_count #查看前10条文档,了解文档格式 POST kibana_sample_data_ecommerce/_search { } #_cat indices API #查看indices GET /_cat/indices/kibana*?v&s=index #查看状态为绿的索引 GET /_cat/indices?v&health=green #按照文档个数排序 GET /_cat/indices?v&s=docs.count:desc #查看具体的字段 GET /_cat/indices/kibana*?pri&v&h=health,index,pri,rep,docs.count,mt #How much memory is used per index? GET /_cat/indices?v&h=i,tm&s=tm:desc
¶索引管理功能
二、基本概念:节点、集群、分片及副本
¶分布式系统的可用性与扩展性
- 高可用性
- 服务可用性:允许有节点停止服务
- 数据可用性:部分节点丢失,不会丢失数据
- 可扩展性
- 请求量提升、数据的不断增长(将数据分布到所有节点上,实现水平扩展)
¶分布式特性
- Elasticsearch 的分布式架构的好处
- 存储的水平扩容
- 提高系统的可用性,部分节点停止服务,整个集群的服务不受影响
- Elasticsearach 的分布式架构
- 不同的集群通过不同的名字来区分,默认名称"elasticsearch"
- 通过配置文件修改,或者在命令行
-E cluster.name=geektime进行设定 - 一个集群可以有一个或者多个节点
¶节点
- 节点是一个 Elasticsearch 的实例
- 本质上就是一个 JAVA 进程
- 一台机器上可以运行多个 Elasticsearch 进程,但是生产环境一般建议一台机器上只运行一个 Elasticsearch 实例
- 每一个节点都有名字,通过配置文件配置,或者启动的时候
-E node.name=node1指定 - 每一个节点在启动之后,会分配一个 UID,保存在 data 目录下
¶Master-eligible nodes 和 Master Node
- 每个节点启动后,默认就是一个 Master eligible 节点
- 可以设置
node.master:false禁止
- 可以设置
- Master-eligible 节点可以参加选主流程,称为 Master 节点
- 当第一个节点启动的时候,它会将自己选举成 Master 节点
- 每个节点上都保存了集群的状态,只有 Master 节点才能修改集群的状态信息
- 集群状态(Cluster State),维护了一个集群中必要的信息
- 所有的节点信息
- 所有的索引和其相关的 Mapping 与 Setting 信息
- 分片的路由信息
- 如果任意节点都能修改信息会导致数据的不一致性,使得集群变得混乱
- 集群状态(Cluster State),维护了一个集群中必要的信息
¶Data Node & Coordinating Node
- Data Node
- 可以保存数据的节点,叫做 Data Node。负责保存分片数据。在数据扩展是起到了至关重要的作用
- 当集群无法再分配数据的时候,可以增加一个数据节点来解决
- Coordinating Node
- 负责接受 Client 的请求,将请求分发到合适的节点,最终把结果汇集到一起进行响应给调用的客户端
- 每个节点默认都起到了 Coordinating Node 的职责
¶其他类型的节点
- Hot & Warm Node
- 不同硬件配置的 Data Node,用来实现 Hot & Warm 架构,热数据存储在 Hot 节点(高配),冷数据存储在 Warm 节点(低配),降低集群部署的成本
- Machine Learning Node
- 负责跑机器学习的 Job,用来做异常检测及告警
- Tribe Node
- (5.3开始使用 Cross Cluster Search)Tribe Node 连接到不同的 Elasticsearch 集群,并且支持将这些集群当成一个单独的集群处理
¶配置节点类型
- 开发环境中一个节点可以承担多种角色
- 生产环境中,应该设置单一的角色的节点(dedicated node)
- 可以有更好的性能
- 职责明确,根据不同节点配置不同硬件
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| Master eligible | node.master | true |
| data | node.data | true |
| ingest | node.ingest | true |
| coordinating only | 无 | 每一个节点默认都是 coordinating 节点。设置其他类型全部为 false。 |
| Machine learning | node.ml | True(需要 enable x=pack) |
¶分片(Primary Shard & Replica Shard)
-
主分片
用来解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内的所有节点之上
- 一个分片是一个运行的 Lucene 的实例(索引)
- 主分片数在索引创建时指定,后续不允许修改,除非 Reindex
-
副本分片
用来解决数据高可用的问题,避免部分节点不可用导致数据丢失。分片是主分片的拷贝
- 副本分片数,可以动态调整
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
-
举例
一个3节点的集群中,blogs 索引的分片分布情况
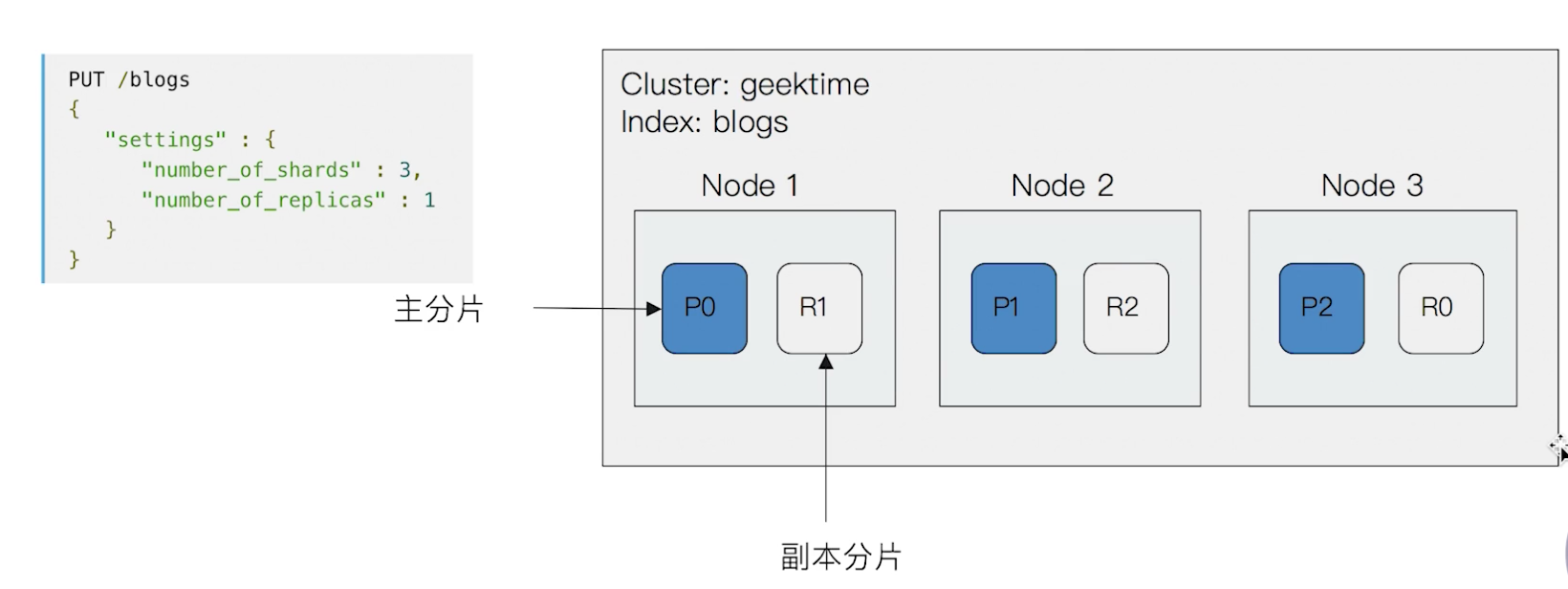
-
分片的设定
对于生产环境中分片的设定,需要提前做好容量规划
- 分片数设置过小
- 导致后续无法增加节点实现水平扩展
- 单个分片的数据量太大,导致数据重新分配耗时
- 分片数设置过大,7.0开始,默认主分片从5改成1,解决了 over-sharding 的问题
- 影响搜索结果的相关性打分,影响统计结果的准确性
- 单个节点上过多的分片,会导致资源浪费,同时也会影响性能
¶查看集群的健康状态
-
REST API:
GET _cluster/health
- Green:主分片与副本都正常分配
- Yellow:主分片全部正常分配,有副本分片未正常分配
- Red:有主分片未能分配
- 例如,当服务器的磁盘容量超过85%时,去创建了一个新的索引
-
通过 Kibana 查看集群状态
-
查看一个集群的健康状态
-
CAT API
- httpL//myecs.com:9200/_cat/nodes
- 查看索引和分片
-
设置分片数
GET _cat/nodes?v GET /_nodes/es7_01,es7_02 GET /_cat/nodes?v GET /_cat/nodes?v&h=id,ip,port,v,m GET _cluster/health GET _cluster/health?level=shards GET /_cluster/health/kibana_sample_data_ecommerce,kibana_sample_data_flights GET /_cluster/health/kibana_sample_data_flights?level=shards #### cluster state The cluster state API allows access to metadata representing the state of the whole cluster. This includes information such as GET /_cluster/state #cluster get settings GET /_cluster/settings GET /_cluster/settings?include_defaults=true GET _cat/shards GET _cat/shards?h=index,shard,prirep,state,unassigned.reason -
-
通过 Cerebro 查看集群状态
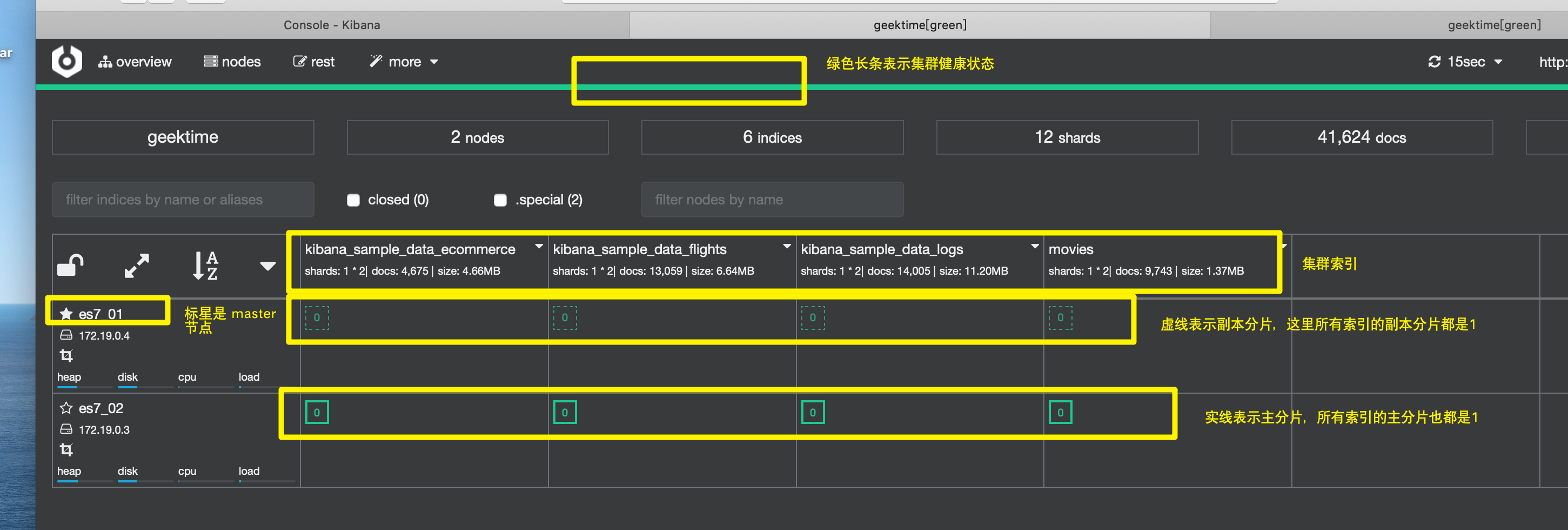
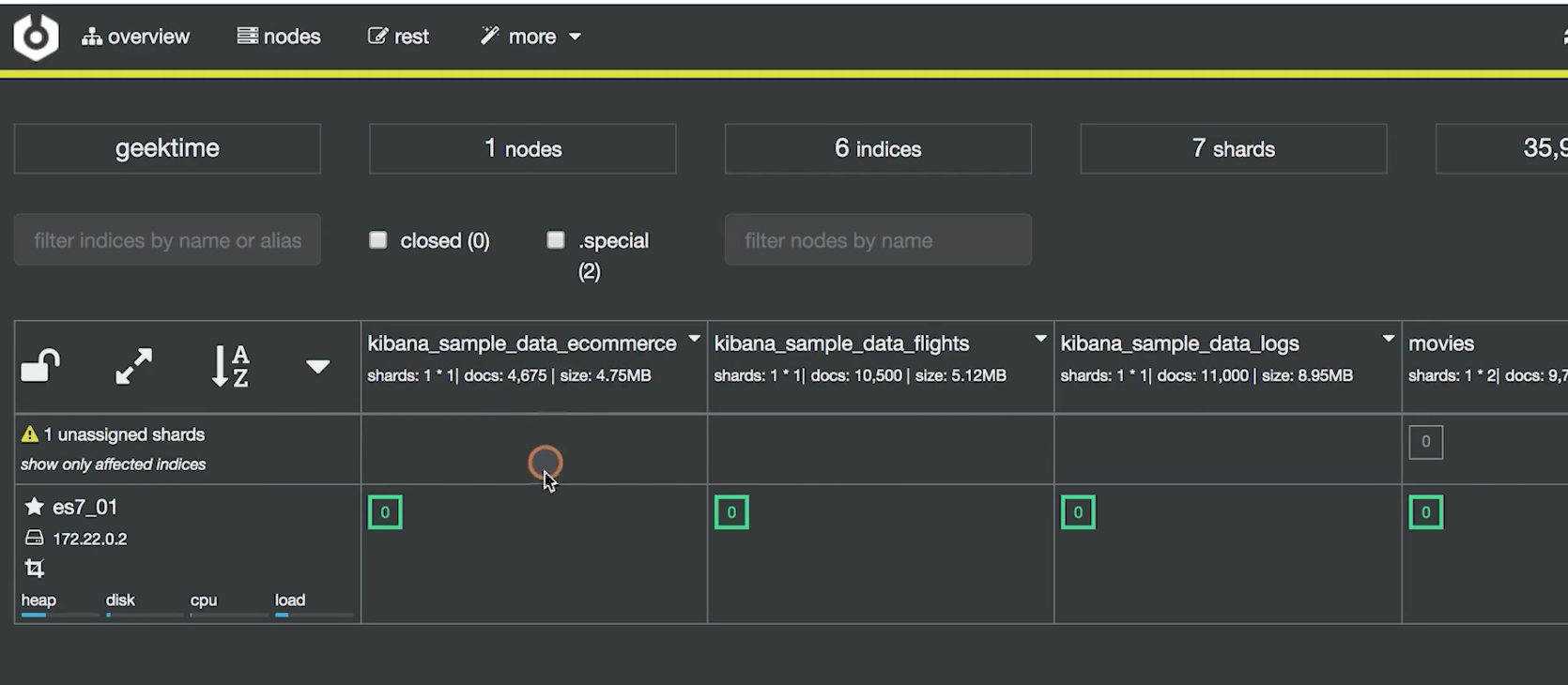
当我们尝试停掉一个节点的时候,发现上面的长条变成了黄色
三、文档的 CRUD与批量操作
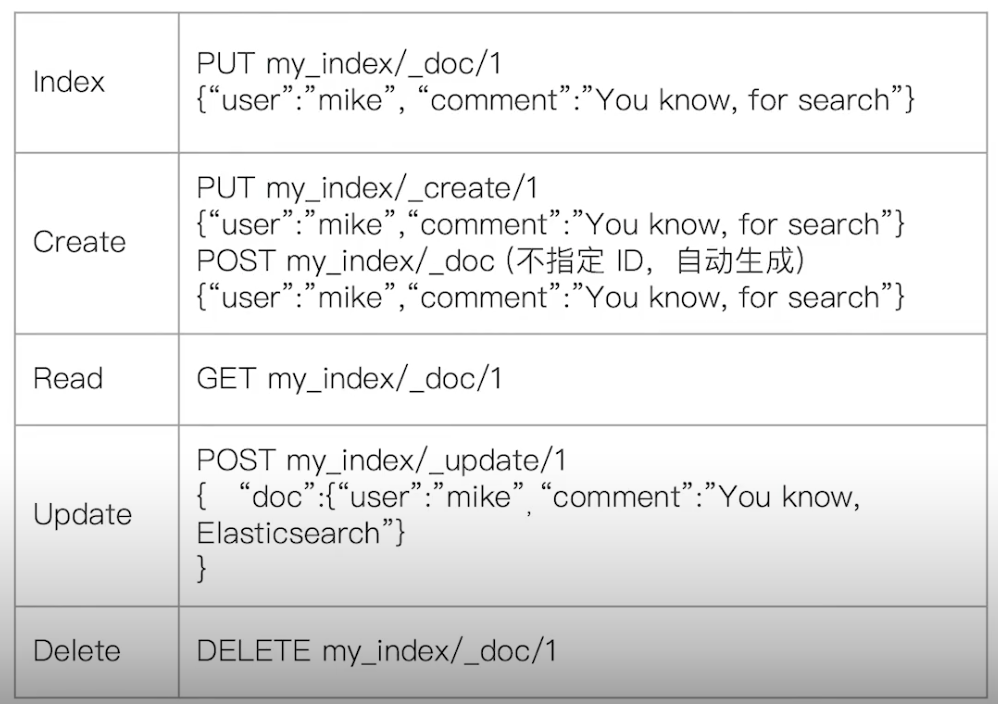
¶文档的 CRUD
- Type名,约定都用_doc
- Create:如果 ID 已经存在,会失败
- Index:如果 ID 不存在,创建新的文档;否则,先删除现有的文档,再创建新的文档,版本会增加
- Update:文档必须已经存在,然后对相应字段做增量修改,版本号增加
¶create
- 支持自动生成文档 id 和指定文档 id 两种方式
- 通过调用
post /users/_doc- 系统会自动生成 document id
- 使用 HTTP PUT user/_create/1 创建时,URI中显示指定_create,此时如果该 ID 的文档已经存在,操作失败
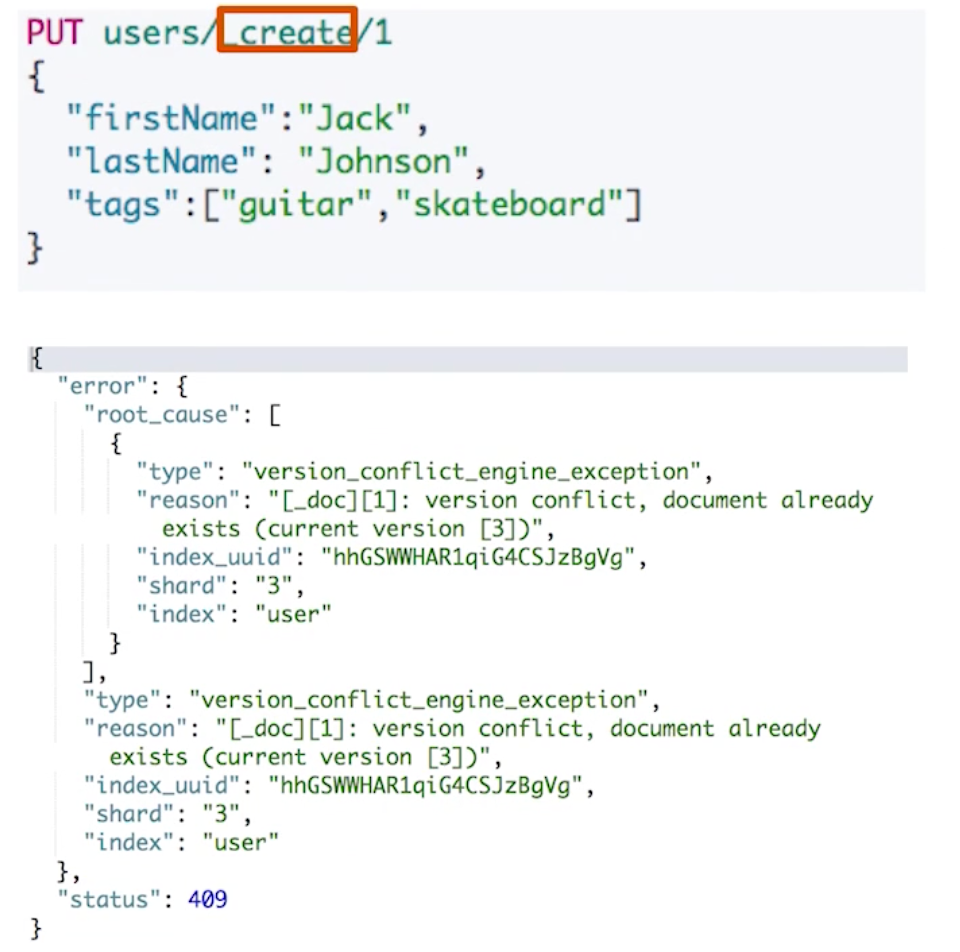
¶get
- 找到文档,返回 HTTP 200
- 文档元信息
- _index、_type
- 版本信息,同一个 id 的文档,被删除,version 号不断增加
- _source 中默认包含了了文档的所有原始信息
- 找不到文档,返回 HTTP 404

¶index
- index 和 create 区别:如果文档(ID)已存在,前者会删除然后重建然后版本+1;后者会报错
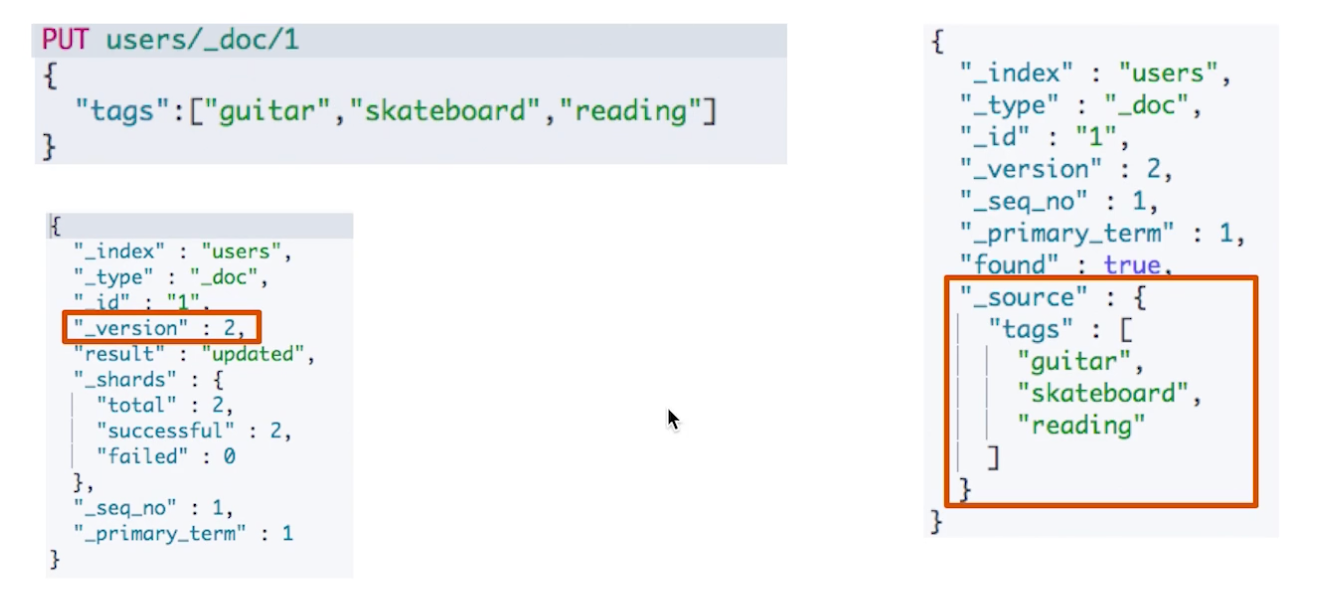
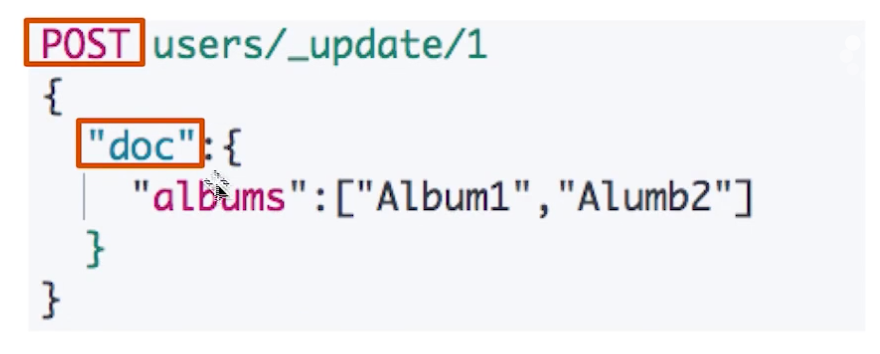
¶update
-
update 方法不会删除原来的文档,要求文档必须存在,否则失败。是实现真正的数据更新
-
post 方法,在请求体中将信息包含在"doc"中
¶Bulk API
- 支持在一次 API 调用中,对不同的索引进行操作,减少网络请求
- 支持4种操作类型
- index
- create
- update
- delete
- 可以在 URI 中指定 index,也可以在请求的 payload 中进行
- 操作中单挑操作失败,并不会影响其他操作
- 返回结果包含了每一条操作执行的结果

¶mget-批量读取
批量操作,可以减少网络连接所产生的开销,提高性能

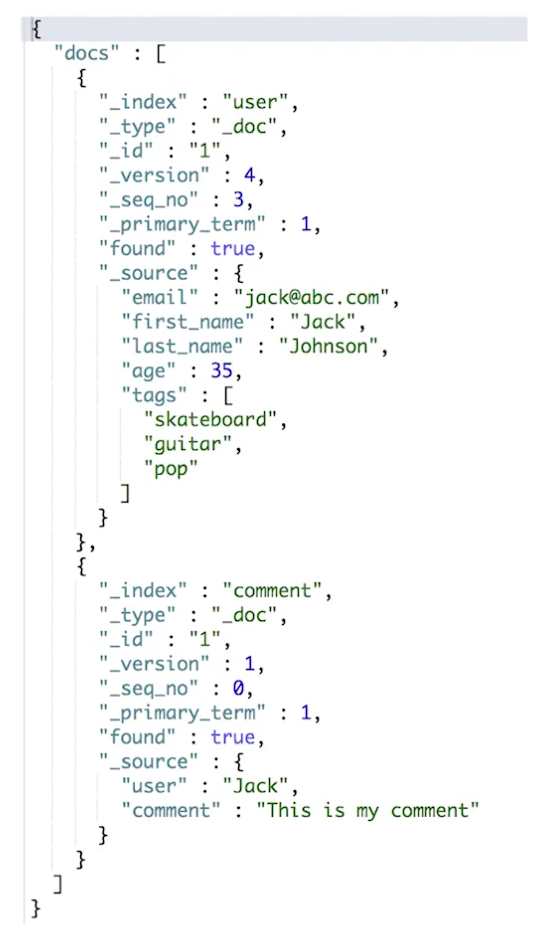
¶msearch-批量查询

注意,虽然上面介绍了批量查询API,但是单次批量查询的数据过大也会引发性能问题。
¶操作的 API demo
############Create Document############
#create document. 自动生成 _id
POST users/_doc
{
"user" : "Mike",
"post_date" : "2019-04-15T14:12:12",
"message" : "trying out Kibana"
}
#create document. 指定Id。如果id已经存在,报错
PUT users/_doc/1?op_type=create
{
"user" : "Jack",
"post_date" : "2019-05-15T14:12:12",
"message" : "trying out Elasticsearch"
}
#create document. 指定 ID 如果已经存在,就报错
PUT users/_create/1
{
"user" : "Jack",
"post_date" : "2019-05-15T14:12:12",
"message" : "trying out Elasticsearch"
}
### Get Document by ID
#Get the document by ID
GET users/_doc/1
### Index & Update
#Update 指定 ID (先删除,在写入)
GET users/_doc/1
PUT users/_doc/1
{
"user" : "Mike"
}
#GET users/_doc/1
#在原文档上增加字段
POST users/_update/1/
{
"doc":{
"post_date" : "2019-05-15T14:12:12",
"message" : "trying out Elasticsearch"
}
}
### Delete by Id
# 删除文档
DELETE users/_doc/1
### Bulk 操作
#执行两次,查看每次的结果
#执行第1次
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test2", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
#执行第2次
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test2", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
### mget 操作
GET /_mget
{
"docs" : [
{
"_index" : "test",
"_id" : "1"
},
{
"_index" : "test",
"_id" : "2"
}
]
}
#URI中指定index
GET /test/_mget
{
"docs" : [
{
"_id" : "1"
},
{
"_id" : "2"
}
]
}
GET /_mget
{
"docs" : [
{
"_index" : "test",
"_id" : "1",
"_source" : false
},
{
"_index" : "test",
"_id" : "2",
"_source" : ["field3", "field4"]
},
{
"_index" : "test",
"_id" : "3",
"_source" : {
"include": ["user"],
"exclude": ["user.location"]
}
}
]
}
### msearch 操作
POST kibana_sample_data_ecommerce/_msearch
{}
{"query" : {"match_all" : {}},"size":1}
{"index" : "kibana_sample_data_flights"}
{"query" : {"match_all" : {}},"size":2}
### 清除测试数据
#清除数据
DELETE users
DELETE test
DELETE test2
¶常见错误返回

四、倒排索引介绍
¶正排索引和倒排索引
¶类比理解
假设现在有一本关于 Elasticsearch 的书籍,书籍中的每一页可以类比为 Elasticsearch 中的document,文档中所有字段从第一个到最后一个形成一个链条列表,拥有唯一的位置索引。
书籍的目录上记录了页码以及对应的内容名称,整本书可以理解为一个物理存储介质,页码让我们可以快速定位到我们想要找的文档。所以这个目录就是一个索引,而从 id 指向一个文档就是一个正排索引。
另外一些技术书籍会在最后几页放一些技术术语(单词,term)的列表,并标注了它在哪几页出现,这个将文档中的内容指向文档 id 再找到文档进行加载文档内容的过程就是一个倒排索引。
看下表,右边就是一个倒排索引。
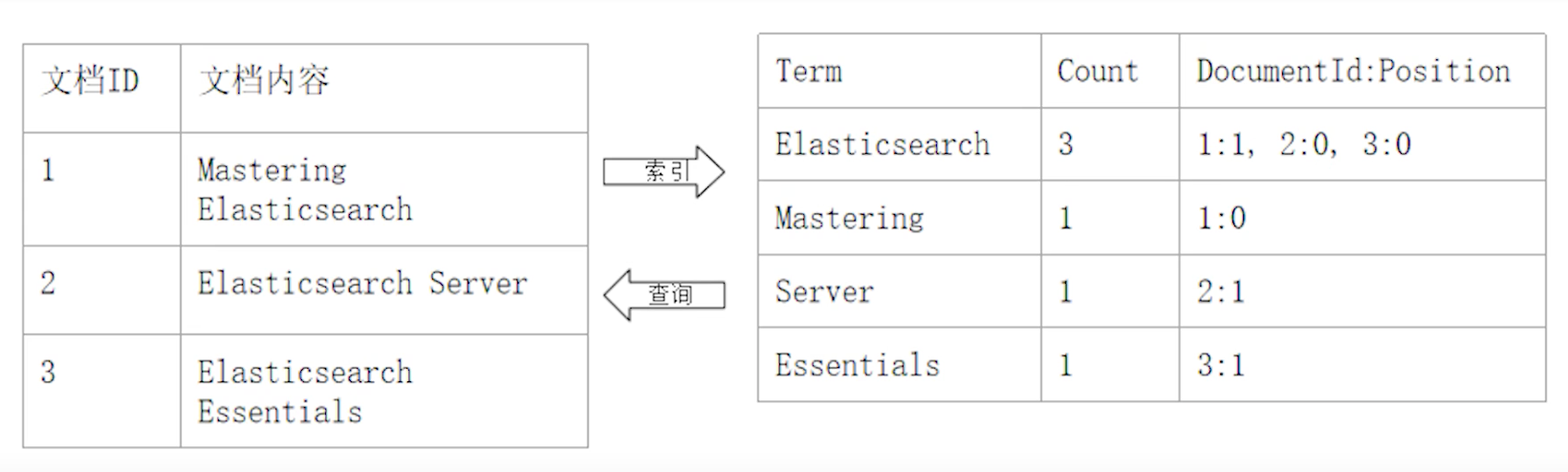
¶倒排索引的核心组成
倒排索引包含两个部分
- 单词词典(Term Directory),记录所有文档的单词,记录单词到倒排列表的关联关系(另外,需要注意,文档下面还有 Field 的概念,它是由 Field 构成的,而 Field 则由 Term 构成)。单词词典一般比较大,可以通过 B+树或者哈希拉链实现存储,以满足高性能的插入与查询
- 倒排列表(Posting Lisrt),记录了单词对应的文档集合,由倒排索引项组成:
- 文档 ID
- 词频 TF:该单词在文档中出现的次数,用于相关性评分
- 位置(Position):单词在文档中分词的位置。用于语句搜索(phrase query)
- 偏移(Offset):记录单词的开始结束位置,实现高亮显示

¶一个例子
Term:“Elasticsearch”
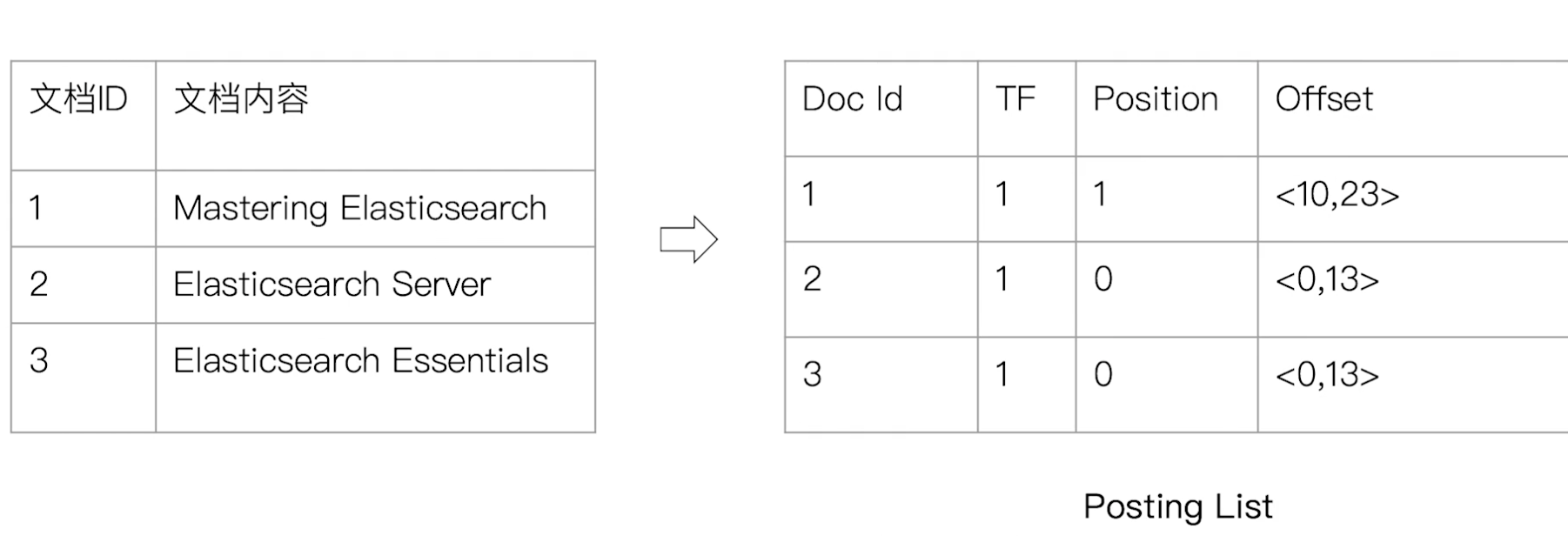
¶Elasticsearch 的倒排索引
- Elasticsearch 的 JSON 文档中的每个字段,都有自己的倒排索引
- 可以指定对某些字段不做索引
- 优点:节省存储空间
- 缺点:字段无法被搜索
五、通过 Analyzer 进行分词
¶Analysis 与 Analyzer
-
Analyses(动词):文本分析是把全文本转换一系列单次(term/token)的过程,也叫分词。
-
Analysis 是通过 Analyzer 来实现的, Analyzer 叫分析器也叫分词器,可以使用 Elasticsearch 内置的分词器,或者按需定制化分词器。
在数据写入的时候,Es 对所有需要进行索引的字段或者字符串进行分词转换成词条(Term)并建立倒排索引,在匹配 Query 语句(例如用户搜索)的时候也需要用相同的分词器对查询语句进行分析
¶Analyzer 的组成
分词器时专门处理分词的组件,Analyzer 由三部分组成
- Character Filters:针对原始文本处理,例如去除 html 标签等
- Tokenizer:按照规则切分为单词
- Token Filter:将切分的单词进行加工,例如转小写、删除
stopwords、增加同义词等。
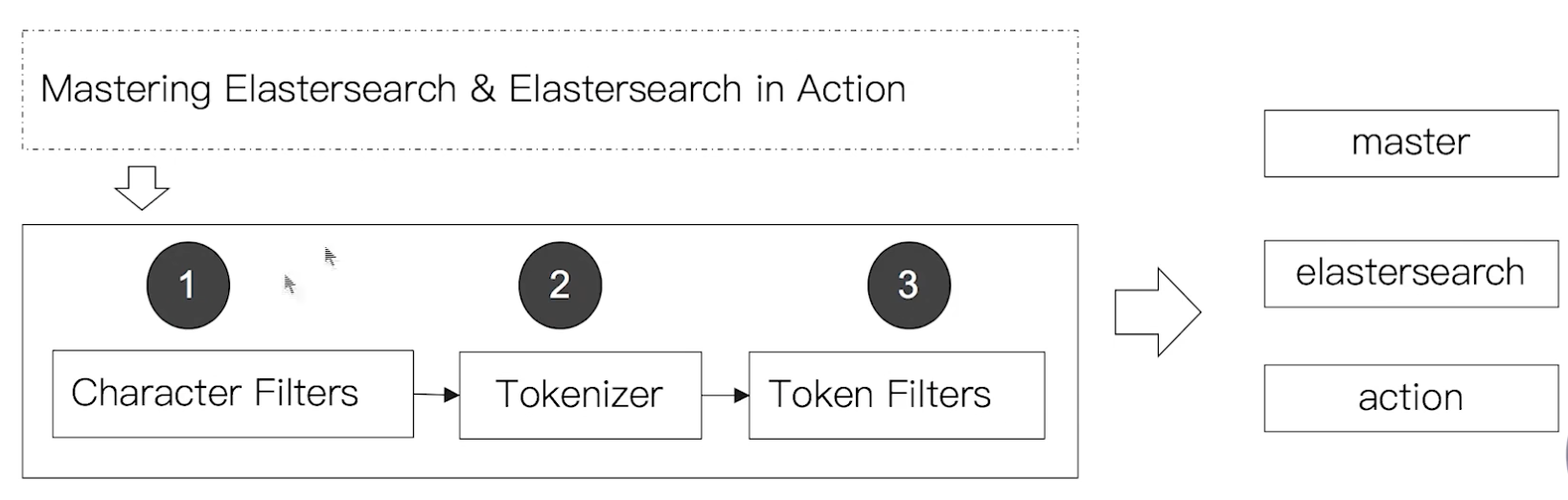
¶Elasticsearch 的内置分词器
-
Standard Analyzer:默认分词器,按词切分,小写处理
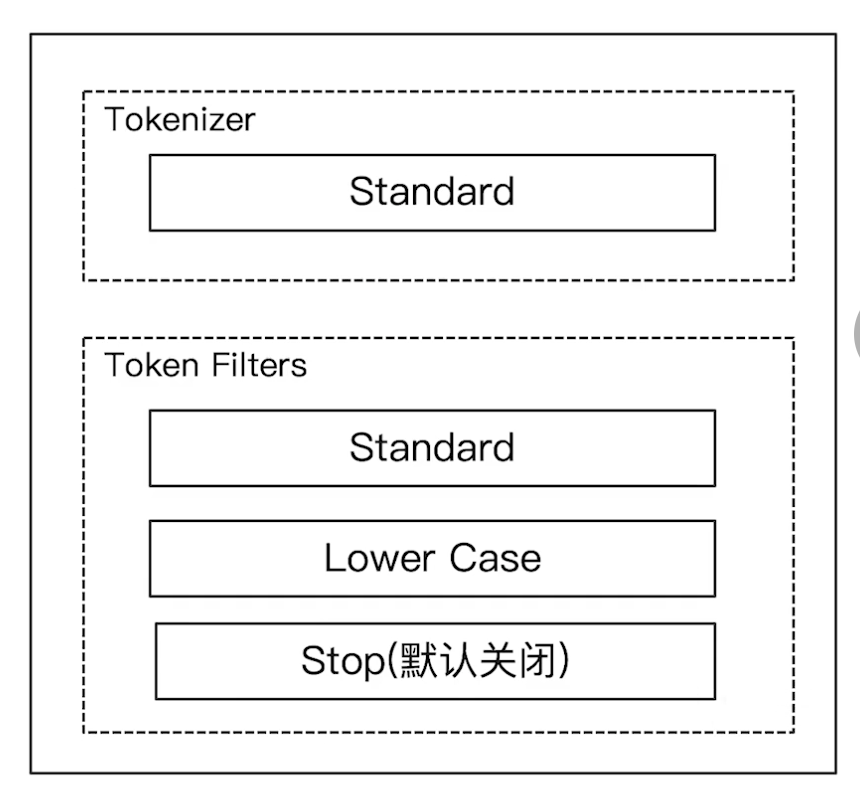
-
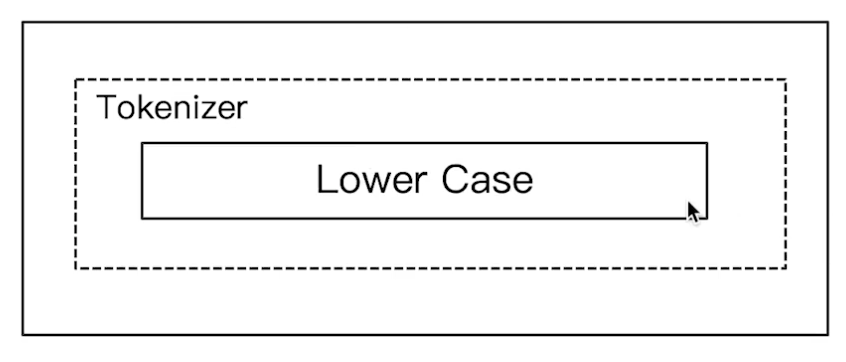
Simple Analyzer:按照非字母切分(非字母字符被过滤),小写处理
-
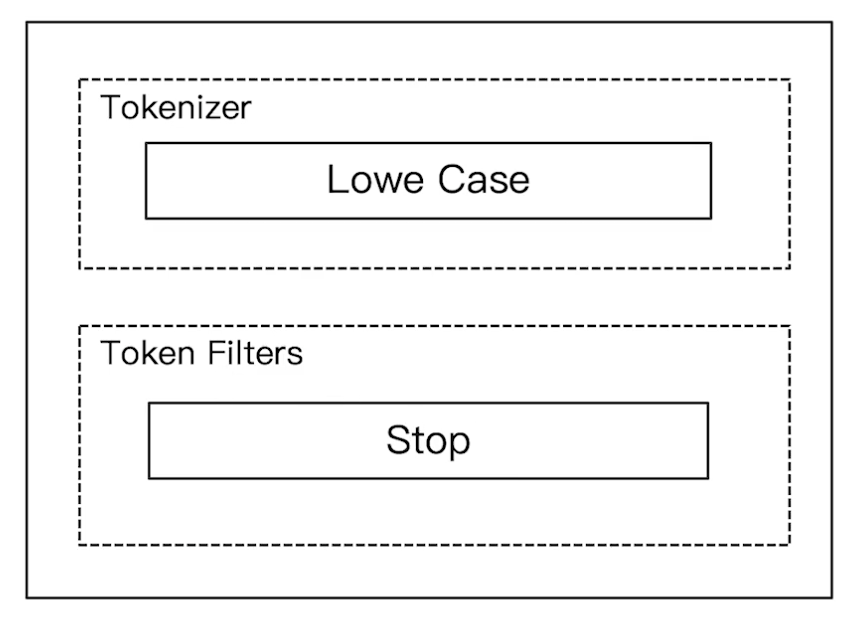
Stop Analyzer:小写处理,过滤停用词(the,a,is 等)
-
Whitespace Analyzer:按照空格切分,不转小写

-
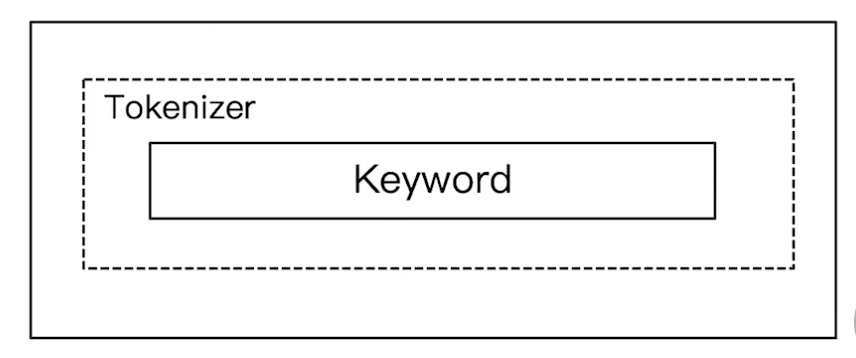
Keyword Analyzer:不分词,直接将输入当做输出
-
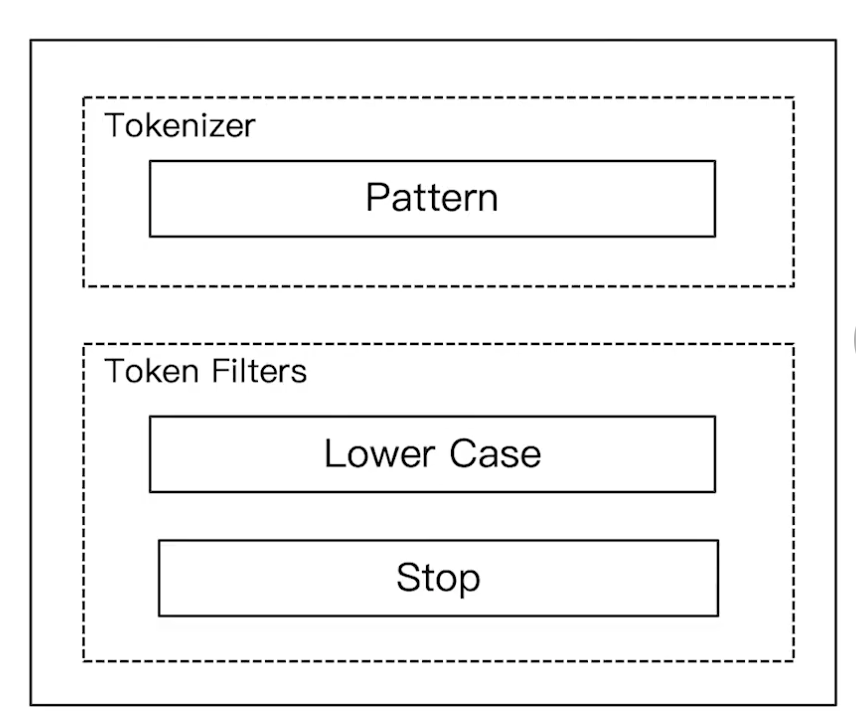
Patter Analyzer:按照正则表达式作为词条匹配进行分词,默认"\W+"(非字符分割)
-
Customer Analyzer:自定义分词器
-
Language:提供了30多种常见语言的分词器

¶特别的中文分词与非官方分词器
-
中文分词的难点:
- 中文句子不像英文这样单词之间有自然的空格作为分隔,也不能直接将一个句子直接切分一个个字。
- 一句中文,在不同的上下文,有不同的理解。(“这个苹果,不大好吃"与"这个苹果不大,好吃”、"他说的确实在理"和"这事的确定不下来"的"确实"怎么分词)
-
ICU Analyzer:提供了 Unicode 的支持,更好的支持亚洲语言。它是一个插件,需要额外安装
Elasticsearch-plugin install analysis-icu
docker 容器安装 ICU Analyzer:
[root@izwz920kp0myp15p982vp4z ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d9b19ed43e4c kibana:7.1.0 "/usr/local/bin/ki..." 12 hours ago Up 12 hours 0.0.0.0:5601->5601/tcp kibana7 d5e50115e6ad elasticsearch:7.1.0 "/usr/local/bin/do..." 12 hours ago Up 12 hours 0.0.0.0:9200->9200/tcp, 9300/tcp es7_01 cc44536c68b5 elasticsearch:7.1.0 "/usr/local/bin/do..." 12 hours ago Up 12 hours 9200/tcp, 9300/tcp es7_02 e99e24660b33 lmenezes/cerebro:0.8.3 "/opt/cerebro/bin/..." 12 hours ago Up 12 hours 0.0.0.0:9000->9000/tcp cerebro [root@izwz920kp0myp15p982vp4z ~]# docker exec -it es7_01 bash [root@d5e50115e6ad elasticsearch]# ./bin/elasticsearch-plugin install analysis-icu -> Downloading analysis-icu from elastic [=================================================] 100%?? WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.bouncycastle.jcajce.provider.drbg.DRBG (file:/usr/share/elasticsearch/lib/tools/plugin-cli/bcprov-jdk15on-1.61.jar) to constructor sun.security.provider.Sun() WARNING: Please consider reporting this to the maintainers of org.bouncycastle.jcajce.provider.drbg.DRBG WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release -> Installed analysis-icu [root@d5e50115e6ad elasticsearch]# exit exit [root@izwz920kp0myp15p982vp4z ~]# docker exec -it es7_02 bash [root@cc44536c68b5 elasticsearch]# ./bin/elasticsearch-plugin install analysis-icu -> Downloading analysis-icu from elastic [=================================================] 100%?? WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.bouncycastle.jcajce.provider.drbg.DRBG (file:/usr/share/elasticsearch/lib/tools/plugin-cli/bcprov-jdk15on-1.61.jar) to constructor sun.security.provider.Sun() WARNING: Please consider reporting this to the maintainers of org.bouncycastle.jcajce.provider.drbg.DRBG WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release -> Installed analysis-icu [root@cc44536c68b5 elasticsearch]# exit exit [root@izwz920kp0myp15p982vp4z ~]# cd /usr/local/software/elasticsearch/docker-es-7.x/ [root@izwz920kp0myp15p982vp4z docker-es-7.x]# docker-compose restart Restarting kibana7 ... done Restarting es7_01 ... done Restarting es7_02 ... done Restarting cerebro ... done
安装成功!
-
更多的中文分词器
-
IK:支持自定义词库,支持热更新分词字典。安装方法参考上面的
AnalysisICU。[root@cc44536c68b5 elasticsearch]# bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.1.0/elasticsearch-analysis-ik-7.1.0.zip
分词效果测试:
POST _analyze { "analyzer": "ik_smart" , "text": "中华人民共和国国歌" } POST _analyze { "analyzer": "ik_max_word" , "text": "中华人民共和国国歌" }结果:
-
ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
-
ik_smart:会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
-
-
THULAC:THU Lexucal Analyzer for Chinese,清华大学自然语言处理和社会人文计算实验室的一套中文分词器
-
¶使用_analyzer API
-
直接指定 Analyzer 进行测试,并传入一个字符串看分词器对字符串的分词结果

-
指定索引的字段进行测试

-
自定义分词器进行测试(例如自定义它的"tokenizer"和"filter")

测试请求:
#Simple Analyzer – 按照非字母切分(符号被过滤),小写处理
#Stop Analyzer – 小写处理,停用词过滤(the,a,is)
#Whitespace Analyzer – 按照空格切分,不转小写
#Keyword Analyzer – 不分词,直接将输入当作输出
#Patter Analyzer – 正则表达式,默认 \W+ (非字符分隔)
#Language – 提供了30多种常见语言的分词器
#2 running Quick brown-foxes leap over lazy dogs in the summer evening
#查看不同的analyzer的效果
#standard
GET _analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#simpe
GET _analyze
{
"analyzer": "simple",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
GET _analyze
{
"analyzer": "stop",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#stop
GET _analyze
{
"analyzer": "whitespace",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#keyword
GET _analyze
{
"analyzer": "keyword",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
GET _analyze
{
"analyzer": "pattern",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#english
GET _analyze
{
"analyzer": "english",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "他说的确实在理”"
}
POST _analyze
{
"analyzer": "standard",
"text": "他说的确实在理”"
}
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "这个苹果不大好吃"
}
POST _analyze
{
"analyzer": "ik_smart"
, "text": "中华人民共和国国歌"
}
POST _analyze
{
"analyzer": "ik_max_word"
, "text": "中华人民共和国国歌"
}
六、Search API
¶API URI
| 语法 | 范围 |
|---|---|
| /_search | 集群上所有的索引 |
| /index1/_search | index1 |
| /index,index2/_search | index1和 index2 |
| /index*/_search | 以index 开头的索引 |
¶API 请求方式
-
URI Search(GET)
在 URL 中使用查询参数
-
"q"为 http get 作为参数,“query string syntax"为 http get 参数值,内容为"key:value”

-
-
Request Body Search(GET、POST)
使用 Elasticsearch 提供的,基于 JSON 格式的更加完备的 Query Domain Specific Language(DSL)

¶返回结果
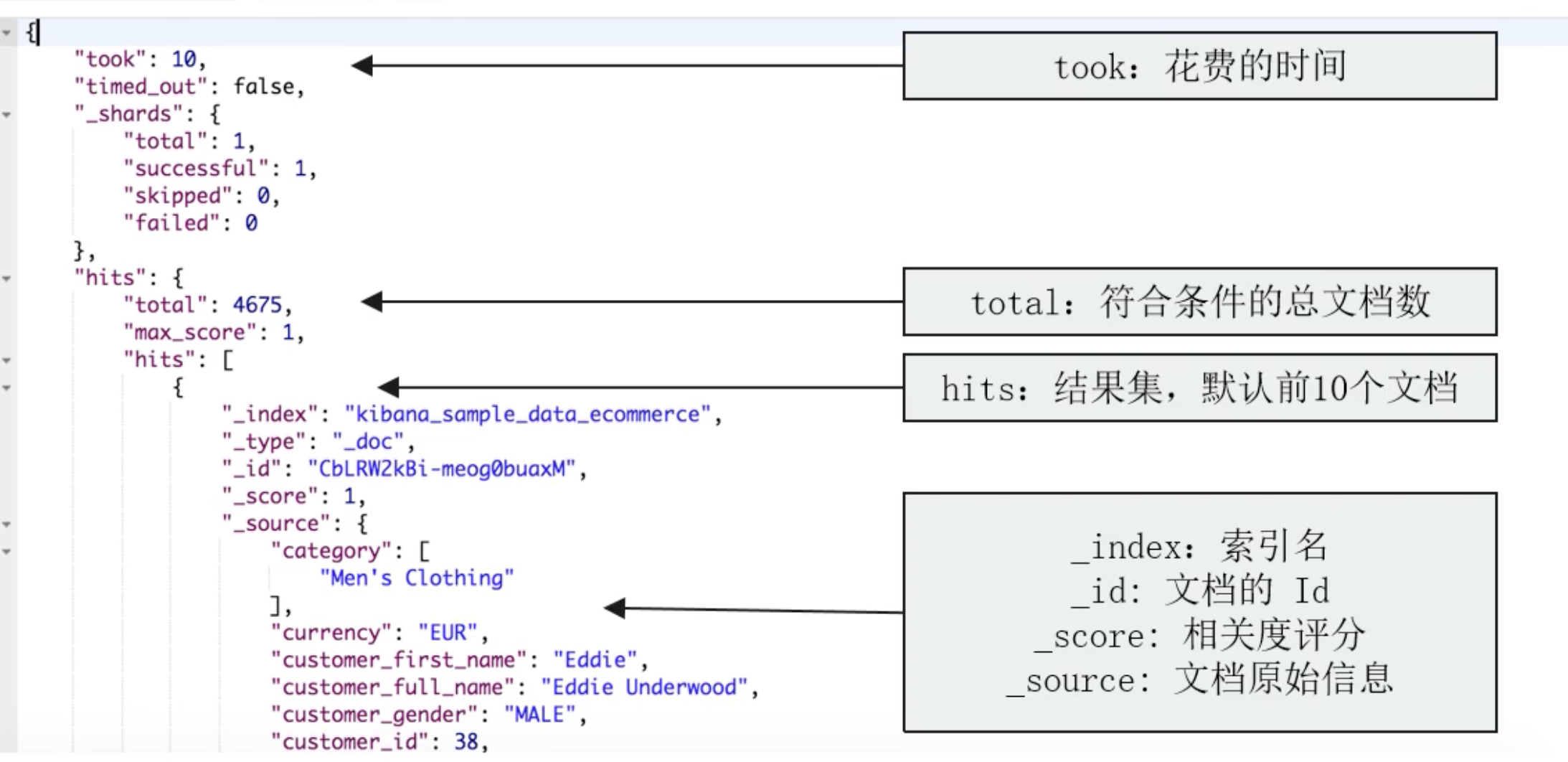
¶文档元信息:_score
这个字段表示了这个文档的匹配打分,表示了其与搜索关键字的相关性(Relevance)。
-
搜索是用户和搜索引擎的对话
-
用户关心的是搜索结果的相关性:
- 是否可以找到所有相关的内容
- 有多少不相关的内容被返回了
- 文档的打分是否合理
- 结合业务需求,平衡结果排名
例如搜索苹果,如果我想找的是苹果手机就不能返回水果的苹果
¶Web搜索
-
Page Rank算法
- 不仅仅是内容相关性
- 更重要的是内容的可信度
¶电商搜索
-
搜索引擎扮演-销售的角色
- 提高用户购物体验
- 提升网站销售业绩
- 帮助仓库消除积压库存,需要对这些需要清仓的商品进行排序提升
¶衡量相关性(Information Retrieval)
- Precision(查准率):尽可能返回较少的无关文档
- Recall(查全率):尽量返回较多的相关文档
- Ranking:是否能够按照相关度进行排序
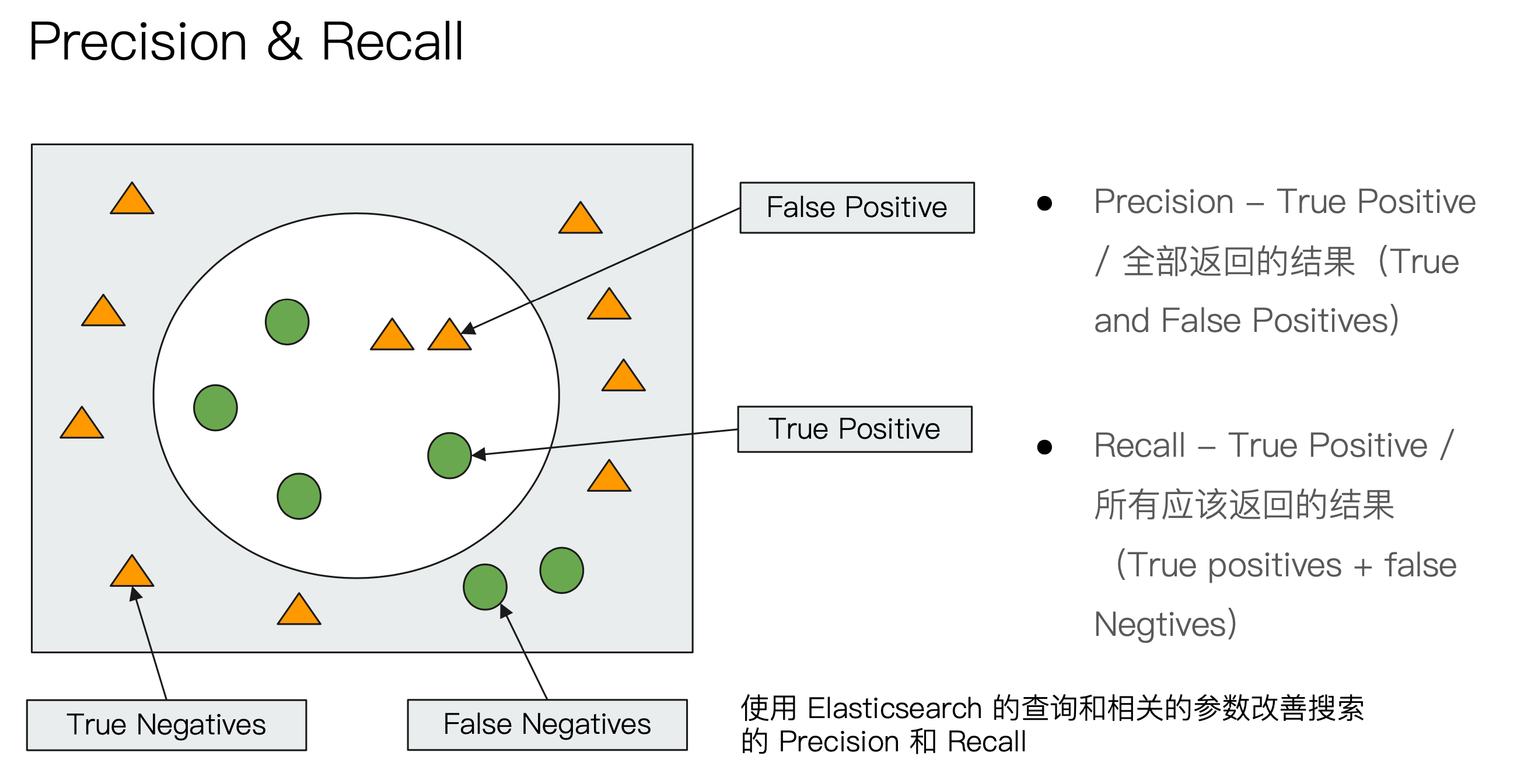
Elasticsearch 提供了很多参数来调整 Precision 和 Recall。
¶URI search 详解

- q指定查询语句,使用 Query String Syntax
- df 默认字段,不指定时,会对所有字段进行查询
- sort 排序
- from、size 用于分页
- Profile 可以查看查询是如何被执行的
¶Query String Syntax
-
指定字段 v.s. 泛查询(DisjunctionMaxQuery)
q=title:2012、q=2012&df=title
q=2012、没有指定字段,会对所有字段进行查询
-
TermQuery v.s. PhraseQuery(最严格的规则求尽量准的合集)
-
TermQuery:最松懈的规则匹配的求尽量大的合集,也就是将查询字符串尽可能地拆分成最多的 Term 进行到倒排索引中检索文档,示例:
Beautiful Mind(等效于 Beautiful OR Mind)
-
PhraseQuery:最严格的规则求尽量准的合集,示例:
“Beautiful Mind”(用双引号包住,等效于 Beautiful AND Mind。还要求前后顺序保持一致)
-
-
分组(圆括号)与引号
-
title:Beautiful Mind
会对"Beautiful"做"title"字段的 TremQuery,对"Mind"做所有字段的 DisjunctionMaxQuery,和我们预计的对 title 字段做"Beautiful OR Mind"的操作不一致,此时需要用到 Elasticsearch 的分组的概念,就是用圆括号括住
-
title:(Beautiful Mind)
对字段 title 做"Beautiful OR Mind"的查询
-
title:(Beautilful AND Mind)
-
tile=“Beautiful Mind”(PhraseQuery)
-
-
布尔操作
AND、OR、NOT 或者 &&、||、!
- 必须大写
- title:(matrix NOT reloaded)
-
是否必须
- +表示 MUST(URI 编码之后为"%2B")
- -表示 MUST_NOT(同样也可以使用 URI 编码)
- title:(+matrix -reloaded)
-
范围查询
- []:闭区间;{}开区间
- year:[2019 TO 2018]
- year:[* TO 2018]
- 算术符号
- year:>2010
- year:(>2010 && <=2018)
- year:(+>2010 +<=2018)
- []:闭区间;{}开区间
-
通配符查询
通配符查询效率低,占用内存大,不建议使用,特别是放查询条件在最前面
- ? 表示 i个字符:title:mi?d
- * 表示0个字符:title:be*
正则表达
- title:[bt]oy
模糊匹配与近似查询(通过波浪号调整 recall,后面的数字越大,recall 值越大,precision 越小)
- title:befutifl~1
-
相关阅读
https://www.elastic.co/guide/en/elasticsearch/reference/7.0/search-uri-request.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.0/search-search.html
-
Kibana请求示例:
#基本查询
GET /movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10&timeout=1s
#带profile
GET /movies/_search?q=2012&df=title
{
"profile":"true"
}
# 指定字段
GET /movies/_search?q=title:2012
{
"profile":"true"
}
#泛查询,正对_all,所有字段
GET /movies/_search?q=2012
{
"profile":"true"
}
#指定字段
GET /movies/_search?q=title:2012&sort=year:desc&from=0&size=10&timeout=1s
{
"profile":"true"
}
# 查找美丽心灵, Mind为泛查询
GET /movies/_search?q=title:Beautiful Mind
{
"profile":"true"
}
#使用引号,Phrase查询
GET /movies/_search?q=title:"Beautiful Mind"
{
"profile":"true"
}
#分组,Bool查询
GET /movies/_search?q=title:(Beautiful Mind)
{
"profile":"true"
}
#布尔操作符
# 查找美丽心灵
GET /movies/_search?q=title:(Beautiful AND Mind)
{
"profile":"true"
}
# 查找美丽心灵
GET /movies/_search?q=title:(Beautiful NOT Mind)
{
"profile":"true"
}
# 查找美丽心灵
GET /movies/_search?q=title:(Beautiful %2BMind)
{
"profile":"true"
}
#范围查询 ,区间写法
GET /movies/_search?q=title:beautiful AND year:[2002 TO 2018%7D
{
"profile":"true"
}
#通配符查询
GET /movies/_search?q=title:[bt]oy
{
"profile":"true"
}
//模糊匹配&近似度匹配
GET /movies/_search?q=title:beatifl~2
{
"profile":"true"
}
GET /movies/_search?q=title:"Lord Rings"~6
{
"profile":"true"
}
¶Request Body 与 Query DSL 简介
前面介绍了 URI 的 search 方式,另外我们还可以将查询语句(Query DSL)通过 HTTP 将 Request Body 发送给 Elasticsearch 进行 query。在 Elasticsearch 中,一些高阶的 search 操作只能在 Request Body 中做,所以建议使用 Request Body 的方式进行query 。

¶分页
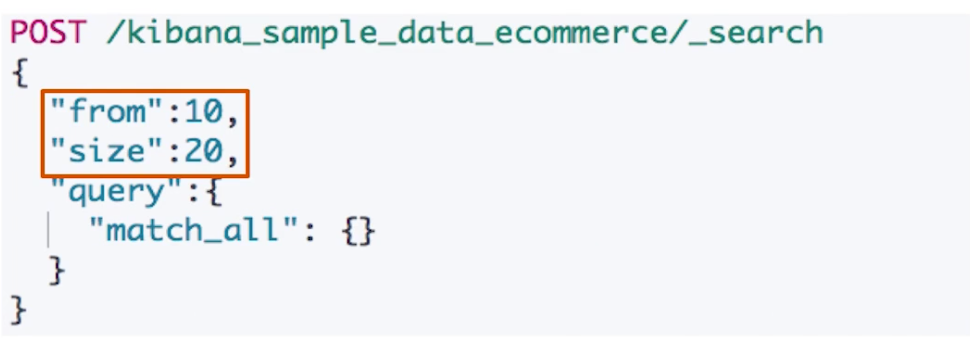
在请求体第一层属性设置 from 和 size,from 从0开始,默认 size 是10。另外获取靠后的翻页成本较高
¶排序
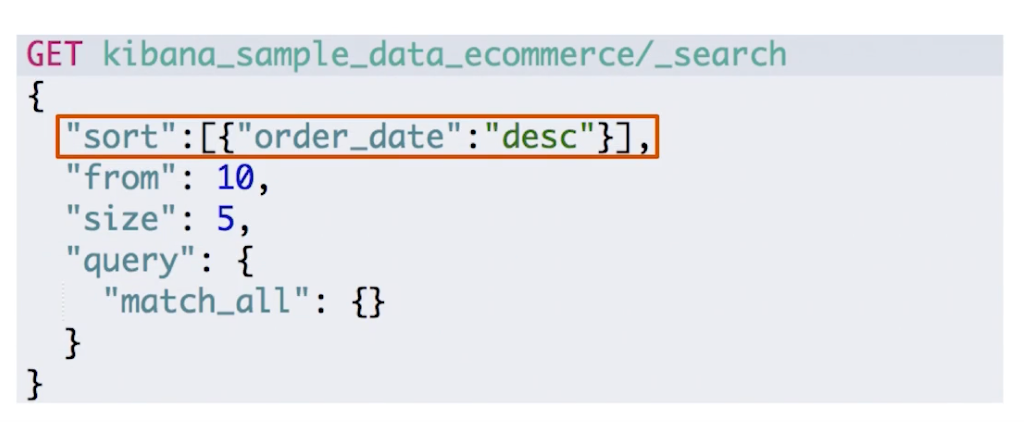
在请求体第一层属性设置 sort 属性。最好在"数字型"与"日期型"字段上排序
因为由于多值类型或分析过的字段排序,系统会选一个值,无法得知该值?
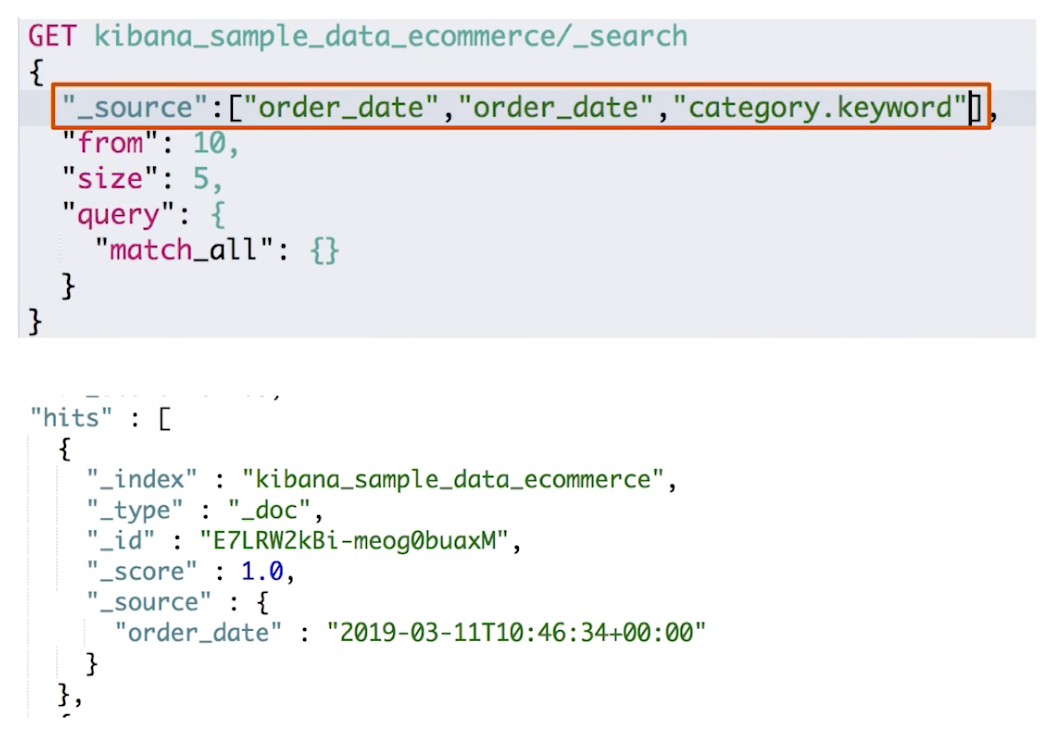
¶_source filtering
Es 默认返回的是匹配的文档的所有 Field,如果我们只需要特定的 Field,可以在请求体第一层设置_source属性
- 如果设置_source为空 ,那就只返回匹配的文档的元数据
- _source 支持使用通配符:_source[“name*, desc*”]
¶脚本字段
我们根据提供的脚本计算得到一个值作为一个新字段进行输出,示例:
订单中有不同的汇率,需要结合汇率对,订单价格进行排序。下面通过 Es 的"painless"脚本对文档中的订单日期字段拼接上一个 hello:
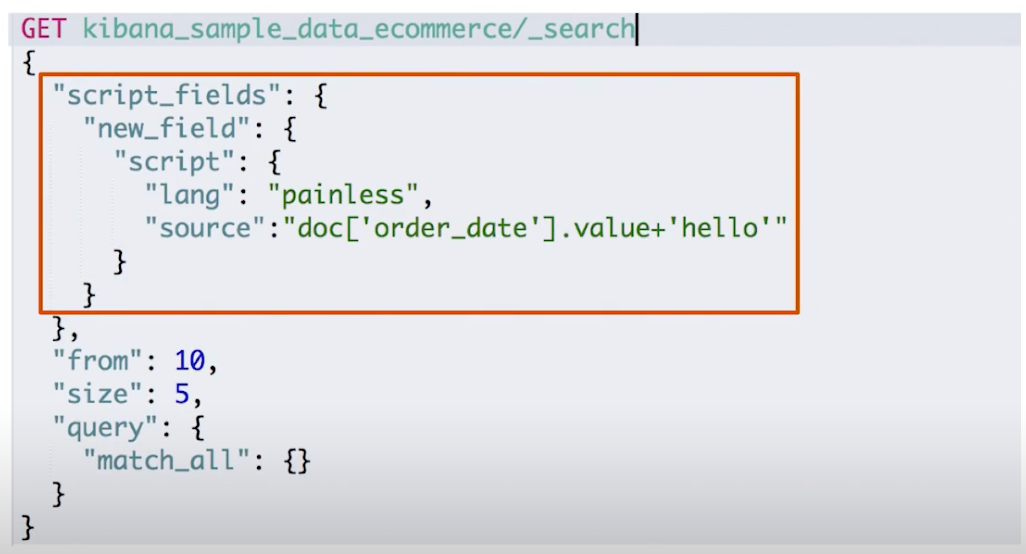
¶使用查询表达式:Match
如下所示:
- 第一个示例中 comment 直接输入一个字符串,则会默认对该字符串进行分词之后得到的 term 进行 or 匹配。
- 如果想进行 AND 匹配,则看第二个示例,comment 需要传入一个 JSON 对象,这个对象的 query 属性是要查询的字符串,operator 属性指定了 AND 逻辑。

¶短语搜索:Match Phrase
这里会导致 query 属性进行 Phrase Query,所有 Term 都要匹配并且顺序一致。
另外通过指定一个 slop 字段来指定 Term 之间可以插入的字符数量
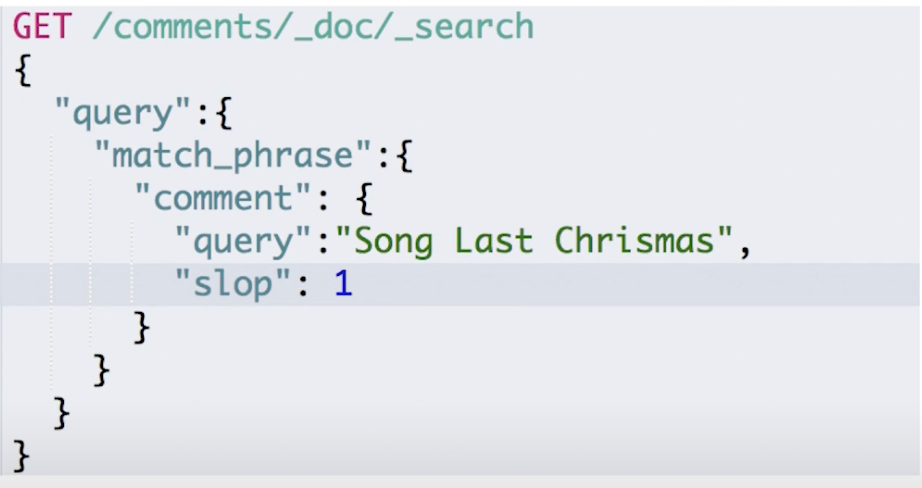
¶Kibana 测试请求
#ignore_unavailable=true,可以忽略尝试访问不存在的索引“404_idx”导致的报错
#查询movies分页
POST /movies,404_idx/_search?ignore_unavailable=true
{
"profile": true,
"query": {
"match_all": {}
}
}
POST /kibana_sample_data_ecommerce/_search
{
"from":10,
"size":20,
"query":{
"match_all": {}
}
}
#对日期排序
POST kibana_sample_data_ecommerce/_search
{
"sort":[{"order_date":"desc"}],
"query":{
"match_all": {}
}
}
#source filtering
POST kibana_sample_data_ecommerce/_search
{
"_source":["order_date"],
"query":{
"match_all": {}
}
}
#脚本字段
GET kibana_sample_data_ecommerce/_search
{
"script_fields": {
"new_field": {
"script": {
"lang": "painless",
"source": "doc['order_date'].value+'hello'"
}
}
},
"query": {
"match_all": {}
}
}
POST movies/_search
{
"query": {
"match": {
"title": "last christmas"
}
}
}
POST movies/_search
{
"query": {
"match": {
"title": {
"query": "last christmas",
"operator": "and"
}
}
}
}
POST movies/_search
{
"query": {
"match_phrase": {
"title":{
"query": "one love"
}
}
}
}
POST movies/_search
{
"query": {
"match_phrase": {
"title":{
"query": "one love",
"slop": 1
}
}
}
}
¶Query String & Simple Query String 查询
-
Query String:类似 URI Query

-
Simple Query String
- 类似 Query String,但是会忽略错误的语法,同时只支持部分查询语法
- 不支持 AND、OR、NOT,会当成字符串处理
- Term 之间默认的关系是 OR,可以指定 Operator
- 支持部分逻辑:+替代 AND、|替代 OR、-替代 NOT

-
Kibana测试请求
PUT /users/_doc/1 { "name":"Ruan Yiming", "about":"java, golang, node, swift, elasticsearch" } PUT /users/_doc/2 { "name":"Li Yiming", "about":"Hadoop" } POST users/_search { "query": { "query_string": { "default_field": "name", "query": "Ruan AND Yiming" } } } POST users/_search { "query": { "query_string": { "fields":["name","about"], "query": "(Ruan AND Yiming) OR (Java AND Elasticsearch)" } } } #Simple Query 默认的operator是 Or POST users/_search { "query": { "simple_query_string": { "query": "Ruan AND Yiming", "fields": ["name"] } } } POST users/_search { "query": { "simple_query_string": { "query": "Ruan Yiming", "fields": ["name"], "default_operator": "AND" } } } GET /movies/_search { "profile": true, "query":{ "query_string":{ "default_field": "title", "query": "Beafiful AND Mind" } } } # 多fields GET /movies/_search { "profile": true, "query":{ "query_string":{ "fields":[ "title", "year" ], "query": "2012" } } } GET /movies/_search { "profile":true, "query":{ "simple_query_string":{ "query":"Beautiful +mind", "fields":["title"] } } }
七、Dynamic Mapping 和常见字段类型
¶1、什么是 Mapping
Mapping 类似数据库中的 schema 的定义,作用如下:
- 定义索引中包含的字段名称(即哪些字段可以被索引)
- 定义可索引字段的数据类型,例如字符串,数字,布尔… …
- 字段,倒排索引的相关配置( Analyzed or Not Analyzed、分词器)
Mapping 会把 JSON 文档映射成 Lucene 所需要的扁平格式
在第一节中提到,在7.0之前,一个索引可以有多个 Type,每一个 Type 对应一个 Mapping 定义,Mapping 定义了这个 Type 下面被索引的文档需要满足的结构(文档只会属于一个 type),所以文档在索引中被 Type 进行了分组。(也就说,在以前应该是可以同一个字段可以定义多种类型在一个 Index 下多个 Type 中的 Mapping 的,这样是的索引更加抽象,可以兼容更多结构的数据)
但是在7.0之后,一个索引只会有一个 Type,即"_DOC",这样就会导致一个字段在一个索引中只能是一种类型。也因为只有一个Type,所以不需要在 Mapping 定义中指定 type 信息。
¶2、字段的数据类型
简单类型
- Text、Keyword
- Date
- Integer、Floating
- Boolean
- IPv4 & IPv6
复杂类型(对象和嵌套对象)
- 对象类型、嵌套类型
特殊类型
- geo_point & geo_shape、percolator(过滤器?)
¶3、Dynamic Mapping
- 在写入文档时,如果索引不存在,会自动创建索引
- Dynamic Mapping 的机制,使得我们无需手动定义 Mappinigs。Elasticsearch 会自动根据文档信息,推算出字段类型
- 但是有时候会推算得不对,例如地理位置信息
- 当类型如果设置不对时,会导致一些功能无法正常运行,例如 Range 查询。
¶4、类型识别
| JSON 类型 | Elasticsearch 类型 |
|---|---|
| 字符串 | 1. 匹配日期格式,设置成 Date,这个也是可以配置的,默认是开启的;2. 通过配置是的其识别数字设置成 float 或者 long,该选项默认关闭;3. 设置为 Text,并且增加 keyword 子字段 |
| 布尔值 | boolean |
| 浮点型 | float |
| 整数 | long |
| 对象 | Object |
| 数组 | 由第一个非空数字得类型所决定 |
| 空值 | 忽略 |
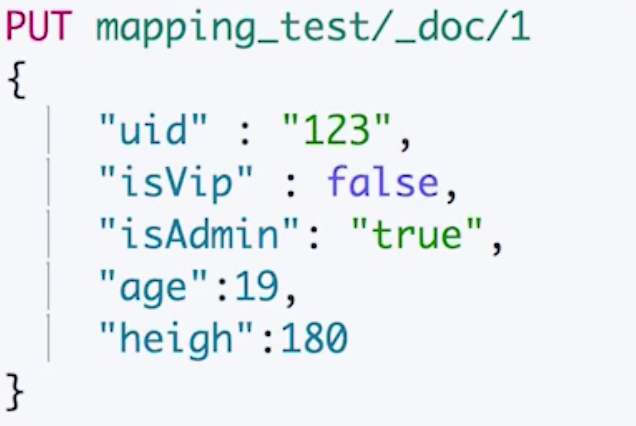
我们看一下下面的示例:uid 和 isAdmin 字段都将被设置成 text,因为默认下是没有开启自动识别数字字符串的,而对于 boolean 值字符串是更加不会自动转换了
¶5、能否更改 Mapping 的字段类型
¶新增字段
- 如果 Dynamic 设置为 true时,一旦有新增字段的文档写入,Mapping 也同时被更新
- Dynamic 设为 false,Mapping 不会被更新,新增字段不会被索引,如果用户根据指定这个字段来搜索信息,就会报错(如果不指定该字段搜索,不会报错,但是不会检索该字段内容);但是字段的信息会被随着文档存储到 Elasticsearch 中,如果这个文档其他字段被索引了,那么这个文档还是可以被搜索出来,该字段也会出现在文档的_source 中
- Dynamic 设置为 Strict,这个文档写入动作将直接抛出错误 400

¶已有字段
- 对已有字段,一旦已经有数据写入,就不再支持修改字段定义(Lucene 实现的倒排索引,一旦生成后,就不允许修改)
- 如果希望修改字段类型,必须 ReIndex API,重新索引
¶原因
- 如果修改了字段的数据类型,会导致已被索引的索引无法被搜索
- 但是如果是增加新的字段,就不会有这样的影响
¶Kibana 测试请求数据
#写入文档,查看 Mapping
PUT mapping_test/_doc/1
{
"firstName":"Chan",
"lastName": "Jackie",
"loginDate":"2018-07-24T10:29:48.103Z"
}
#查看 Mapping文件
GET mapping_test/_mapping
#Delete index
DELETE mapping_test
#dynamic mapping,推断字段的类型
PUT mapping_test/_doc/1
{
"uid" : "123",
"isVip" : false,
"isAdmin": "true",
"age":19,
"heigh":180
}
#查看 Dynamic
GET mapping_test/_mapping
#默认Mapping支持dynamic,写入的文档中加入新的字段
PUT dynamic_mapping_test/_doc/1
{
"newField":"someValue"
}
#该字段可以被搜索,数据也在_source中出现
POST dynamic_mapping_test/_search
{
"query":{
"match":{
"newField":"someValue"
}
}
}
#修改为dynamic false
PUT dynamic_mapping_test/_mapping
{
"dynamic": false
}
#新增 anotherField
PUT dynamic_mapping_test/_doc/10
{
"anotherField":"someValue"
}
#该字段不可以被搜索,因为dynamic已经被设置为false
POST dynamic_mapping_test/_search
{
"query":{
"match":{
"anotherField":"someValue"
}
}
}
get dynamic_mapping_test/_doc/10
#修改为strict
PUT dynamic_mapping_test/_mapping
{
"dynamic": "strict"
}
#写入数据出错,HTTP Code 400
PUT dynamic_mapping_test/_doc/12
{
"lastField":"value"
}
DELETE dynamic_mapping_test
¶6、显式 Mapping 设置与常见参数介绍
¶如何定义一个 Mapping
-
可以参考 API 手册,纯手写
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/dynamic-mapping.html
-
为了减少输入的工作量,减少出错率,可以依照以下步骤
- 创建一个临时的 index,写入一些样本数据
- 通过访问 Mapping API获得临时文件的动态 Mapping 定义
- 修改后用,使用该配置创建你的索引
- 删除临时索引
¶Mapping 参数设置(官网介绍)
-
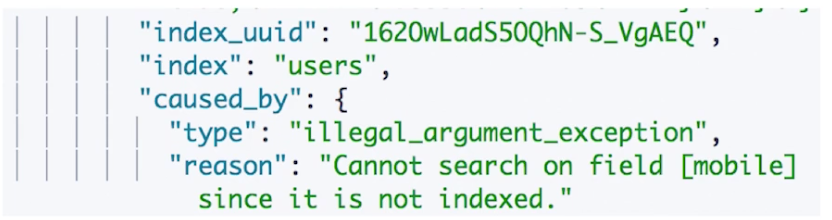
通过字段的 index 属性设置控制当前字段是否被索引,默认为 true,即可被索引

设置为 false 之后,如果还指定该字段进行索引,将会遇到以下报错
-
通过 index_options 属性设置字段索引的级别
- docs:记录 doc id
- freqs:记录 doc id 和 term frequencies
- position:记录 doc id 、term frequencies 和 term position
- offsets:记录 doc id、term frequencies、term position 和 character offsets
Text 类型默认记录 positions,其他默认为 docs。(记录内容越多,占用存储空间越大)
-
实现对字段进行 null 值搜索
通过设定索引字段的"null_value"属性为字符串"NULL",即可进行 NULL 值搜索。(注意:只有 Keyword 类型支持设定 Null_value)

-
通过 copy_to 属性指定一个字段表示将当前字段的索引映射到该字段,从而可以实现一个字段索引其他多个字段的内容
- copy_to 将字段的数值拷贝到目标字段,实现类似_all的作用
- 之前的_all 字段,在7中已经被 copy_to 所替代
- 满足一些特定的搜索需求
- copy_to 的目标字段不出现在_source 中

¶数组类型
Elasticsearch 中不提供专门的数组类型。但是任何字段,都可以包含多个相同类型的数据。可以看下以下测试内容,第一个请求执行之后,插入了一个 text 类型的 interests 的字段,第二个请求也是可以执行成功,我们看一下此时的 Mapping 定义,发现这个字段的类型还是 text,并不是一个数组,同时也符合我们前面讲到的,Mapping 的字段类型在该字段已经有数据被索引之后是不可以被修改的


¶多字段类型
当我们为一个索引定义 mapping的时候,可以为索引字段定义子字段,而 Elasticsearch 本身对于 text 类型的字段都会加上一个"keyword"类型的子字段。
这个多字段的特性使得我们可以为一个字段定制更多其他的索引以及检索方式(通过指定不同的 analyzer):
- 例如一个字段同时支持不同语言的搜索
- 对字段支持 pinyin 的搜索
- 还支持设置在搜索和索引的时候使用不同的 analyzer

¶Exact Values v.s. Full Text
精确值与全文本
- Exact Value:包括数字、日期、具体一个字符串(例如"App Store",这是一个业务意义上的最小单元短语,这在 Elasticsearch 中类型为 keyword)
- Full Text:非结构化的文本数据(Elasticsearch 中的 text)
对于 keyword 类型的数据来说,是没有必要再进行分词处理的了,在 Elasticsearch 中定义了 keyword 类型就是为了避免不必要的分词处理,所以 Elasticsearch 在对每一个字段进行检索的时候如果遇到 Exact Value(如果是创建的时候遇到了自定义了 keyword 类型的字段呢?),不需要做特殊的分词处理,较少性能的浪费。

¶自定义分词
当 Elasticsearch 自带的分词器无法满足时,可以自定义分词器。通过自组合不同的组件实现:
-
Character Filter
在 Tokenizer 之前对文本进行处理,例如增加删除及替换字符。可以配置多个 Character Filters。会影响 Tokenizer 的 position 和 offset 信息。以下是一些 Es 自带的 Character FIlters:
- HTML strip:去掉 html 标签
- Mapping:字符串替换
- Pattern replace:正则匹配替换
-
Tokenizer
将原始文本按照一定的规则,切分为词(Term or token),以下是一些 Es 内置的 Tokenizer,当然也可以自己使用 Java 开发实现自己的 Tokenizer:
- whitespace
- standard
- uax_url_email
- pattern
- keyword:不做任何处理
- path hierarchy
-
Token Filter
将 Tokenizer 输出的单词(term)进行增加修改删除,以下时自带的一些 Token FIlters:
- Lowercase
- stop
- synonym(添加同义词)
在定义索引的 mapping 的时候通过组合以上三种组件定义自己想要的分词器

Kibana 请求参数测试:
PUT logs/_doc/1
{"level":"DEBUG"}
GET /logs/_mapping
POST _analyze
{
"tokenizer":"keyword",
"char_filter":["html_strip"],
"text": "<b>hello world</b>"
}
POST _analyze
{
"tokenizer":"path_hierarchy",
"text":"/user/ymruan/a/b/c/d/e"
}
#使用char filter进行替换
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "mapping",
"mappings" : [ "- => _"]
}
],
"text": "123-456, I-test! test-990 650-555-1234"
}
//char filter 替换表情符号
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "mapping",
"mappings" : [ ":) => happy", ":( => sad"]
}
],
"text": ["I am felling :)", "Feeling :( today"]
}
// white space and snowball
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["stop","snowball"],
"text": ["The gilrs in China are playing this game!"]
}
// whitespace与stop
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["stop","snowball"],
"text": ["The rain in Spain falls mainly on the plain."]
}
//remove 加入lowercase后,The被当成 stopword删除
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["lowercase","stop","snowball"],
"text": ["The gilrs in China are playing this game!"]
}
//正则表达式
GET _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "pattern_replace",
"pattern" : "http://(.*)",
"replacement" : "$1"
}
],
"text" : "http://www.elastic.co"
}
¶7、Index Template和 Dynamic Template
¶Index Template
帮助你设定 Mappings 和 Settings,并按照一定的规则,自动匹配到新创建的索引之上(其匹配属性是一个数组,即可以设定多个匹配规则)
- 模板仅在一个索引被新创建之前存在,才会对这个准备新建的索引产生作用。修改模板不会影响已创建的索引。
- 你可以设定多个索引模板,这些设置会被"merge"在一起
- 你可以指定"order"的数值,控制"merging"的过程
¶两个 Index Templates 例子:
- 第一个例子中设定了所有索引的创建都设定主分片和副本分片数量是1
- 第二个例子中设定了以test 开头的索引的主分片数量是1,副本分片数量是2;另外我们将 Es 自动识别日期字符串且转换类型的功能关闭,然后把自动识别数值字符串且转换类型的功能启用。

¶Index Template 的工作方式
当一个索引被新创建时,会按照一下步骤设置 Mappings:
- 应用 Elasticsearch 默认的 settings 和 mappings
- 应用 order 数值低的 index template 中的设定,之前的设定会被覆盖
- 应用 order 高的 index template 中的设定,之前的设定会被覆盖
- 如果用户创建索引的时候自己指定了 Settings 和 Mappings,则覆盖其设置的设定到之前的设定中。
¶Dynamic Template
上面提到的 Index Template 是应用在所有索引上面的,它是定义在一个_template 的命名空间的,index_patterns 是它的其中一个匹配属性(其匹配属性也是一个数组,即可以设定多个匹配规则),该属性匹配的是索引对象;
而 Dynamic Template 是定义在一个具体的索引上的,同样它也有匹配属性,但是它的匹配属性匹配的是当前这个 Mapping 的字段,也就是说 Dynamic Template 是直接应用在当前 Index 的字段上的,所以我们可以使用 Dynamic Template 设置字段匹配规则对特定的字段进行特定 mapping 设定,从而实现一个"动态的索引"。例如可以实现以下需求:
- 所有的字符串类型都设定成 Keyword,或者关闭 keyword 字段。
- is 开头的字段都设置成 boolean
- long_开头的都设置成 long 类型
下面是三个 Dynamic Template 的例子:
- 第一个 Index 中定义了两个 Dynamic Template,它们的名字分别是"strings_as_boolean"和"strings_as_keywords",前者将所有 is 开头的字符串设置成 boolean 类型,后者将其他类型转成 keyword 类型(所以 templates 的应用优先顺序应该是和定义顺序是一样的)
- 第二个 Index 定义了一个 Dynamic Template,将 name.开头,非.middle 结尾的字段设置为 text 类型并链接索引到一个 full_name 字段


¶Kibana 测试请求
#数字字符串被映射成text,日期字符串被映射成日期
PUT ttemplate/_doc/1
{
"someNumber":"1",
"someDate":"2019/01/01"
}
GET ttemplate/_mapping
#Create a default template
PUT _template/template_default
{
"index_patterns": ["*"],
"order" : 0,
"version": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas":1
}
}
PUT /_template/template_test
{
"index_patterns" : ["test*"],
"order" : 1,
"settings" : {
"number_of_shards": 1,
"number_of_replicas" : 2
},
"mappings" : {
"date_detection": false,
"numeric_detection": true
}
}
#查看template信息
GET /_template/template_default
GET /_template/temp*
#写入新的数据,index以test开头
PUT testtemplate/_doc/1
{
"someNumber":"1",
"someDate":"2019/01/01"
}
GET testtemplate/_mapping
get testtemplate/_settings
PUT testmy
{
"settings":{
"number_of_replicas":5
}
}
put testmy/_doc/1
{
"key":"value"
}
get testmy/_settings
DELETE testmy
DELETE /_template/template_default
DELETE /_template/template_test
#Dynaminc Mapping 根据类型和字段名
DELETE my_index
PUT my_index/_doc/1
{
"firstName":"Ruan",
"isVIP":"true"
}
GET my_index/_mapping
DELETE my_index
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"strings_as_boolean": {
"match_mapping_type": "string",
"match":"is*",
"mapping": {
"type": "boolean"
}
}
},
{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
DELETE my_index
#结合路径
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"full_name": {
"path_match": "name.*",
"path_unmatch": "*.middle",
"mapping": {
"type": "text",
"copy_to": "full_name"
}
}
}
]
}
}
PUT my_index/_doc/1
{
"name": {
"first": "John",
"middle": "Winston",
"last": "Lennon"
}
}
GET my_index/_search?q=full_name:John
八、Elasticsearch 聚合分析简介(官方介绍地址)
Elasticsearch 除搜索以外,提供的针对 ES 数据进行统计分析的功能
- 实时性高
- Hadoop(T+1)
通过聚合,我们会得到一个数据的概览,是分析和总结全套的数据,而不是寻找单个文档
- 尖沙咀和香港岛的客户数量
- 不同的价格区间,可预定的经济型酒店和五星级酒店的数量
高性能,只需要一条语句,就可以从 Elasticsearch 得到分析结果,无需在客户端自己去实现分析逻辑

¶集合的分类
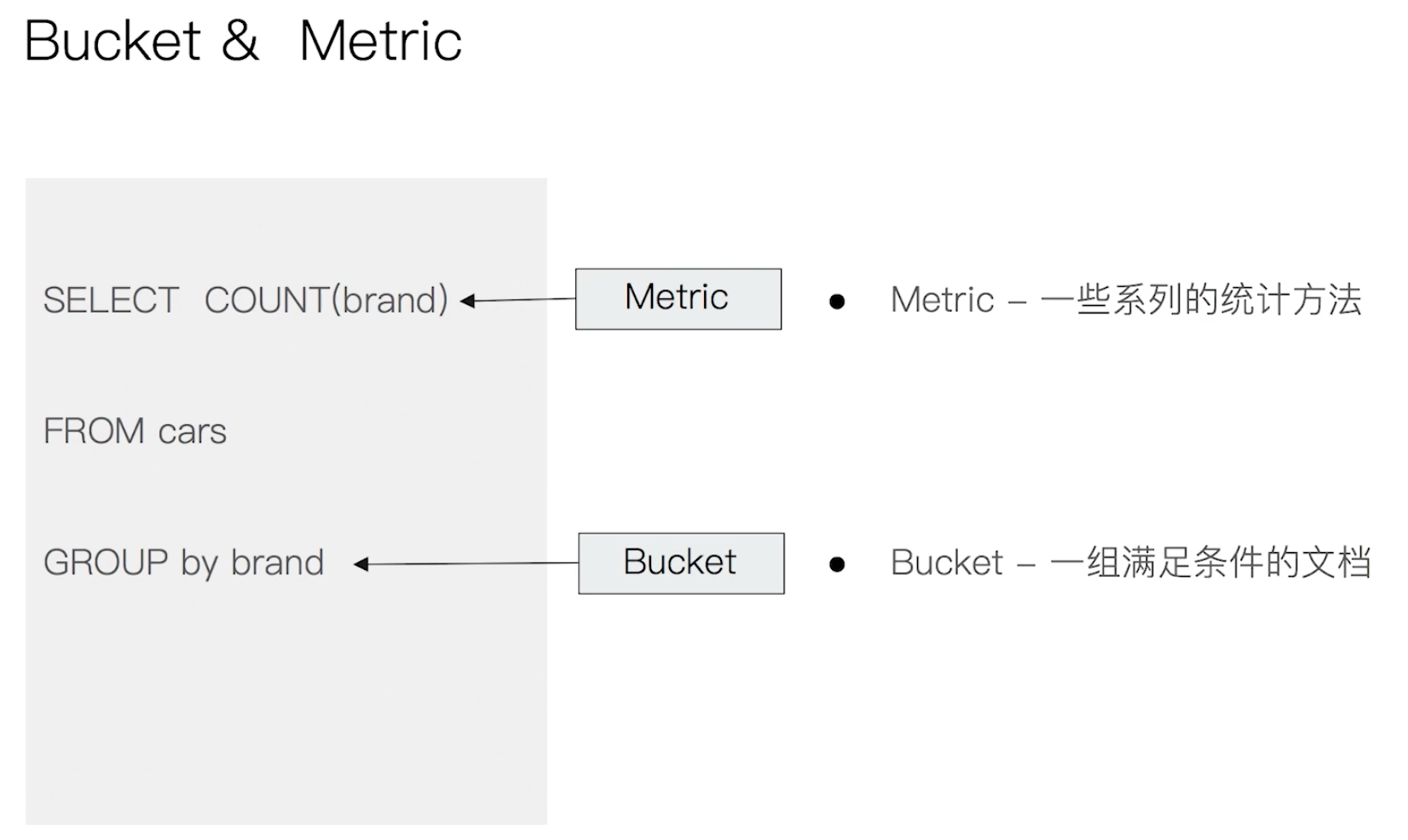
¶Bucket 和 Metric
- Bucket Aggregation:一系列满足特定条件的文档的集合
- 一些例子:
- 杭州属于浙江、一个演员属于男性或者女性
- 嵌套关系:杭州属于浙江属于中国属于亚洲
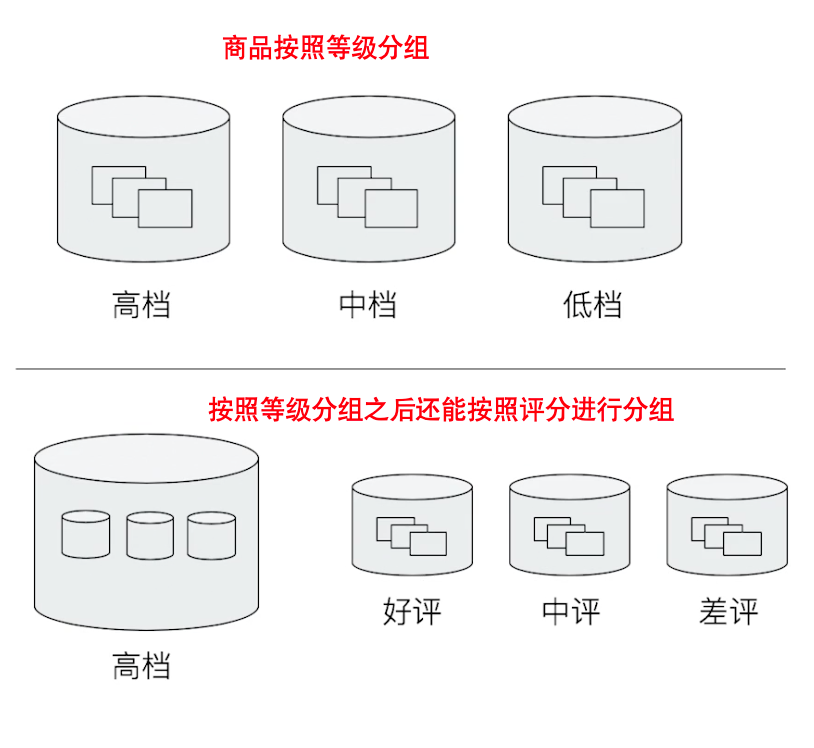
- Elasticsearch 提供了很多类型的 Bucket,帮助你用多种方式划分文档。(如 Term 或者 Range,按照时间、年龄区间、地理位置进行划分等)

- Metric Aggregation:一些数学运算,可以对文档字段进行统计分析
- Metric 会基于数据集计算结果,除了支持在字段上进行计算,同样也支持在脚本(painless script)产生的结果之上进行计算
- 大多数 Metric 是数学计算,仅输出一个值:min、max、sum、avg、cardinlity
- 部分 Metric 支持输出多个数值:stats、percentiles、precentille_ranks
- 两者类比
- Kibana 测试请求
#按照目的地进行分桶统计
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs":{
"flight_dest":{
"terms":{
"field":"DestCountry"
}
}
}
}
#查看航班目的地的统计信息,增加平均,最高最低价格
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs":{
"flight_dest":{
"terms":{
"field":"DestCountry"
},
"aggs":{
"avg_price":{
"avg":{
"field":"AvgTicketPrice"
}
},
"max_price":{
"max":{
"field":"AvgTicketPrice"
}
},
"min_price":{
"min":{
"field":"AvgTicketPrice"
}
}
}
}
}
}
#价格统计信息+天气信息
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs":{
"flight_dest":{
"terms":{
"field":"DestCountry"
},
"aggs":{
"stats_price":{
"stats":{
"field":"AvgTicketPrice"
}
},
"wather":{
"terms": {
"field": "DestWeather",
"size": 5
}
}
}
}
}
}
-
Pipeline Aggregation:对其他的聚合结果进行二次聚合
-
Matrix Aggregation:支持对多个字段的操作并提供一个结果矩阵




