[toc]
Bucket & Metrc 聚合分析及嵌套聚合
在"ES入门"中最后的章节提到 ES 也提供了类似对文档进行聚合(分桶)和统计的方法,称之为 Aggregation。
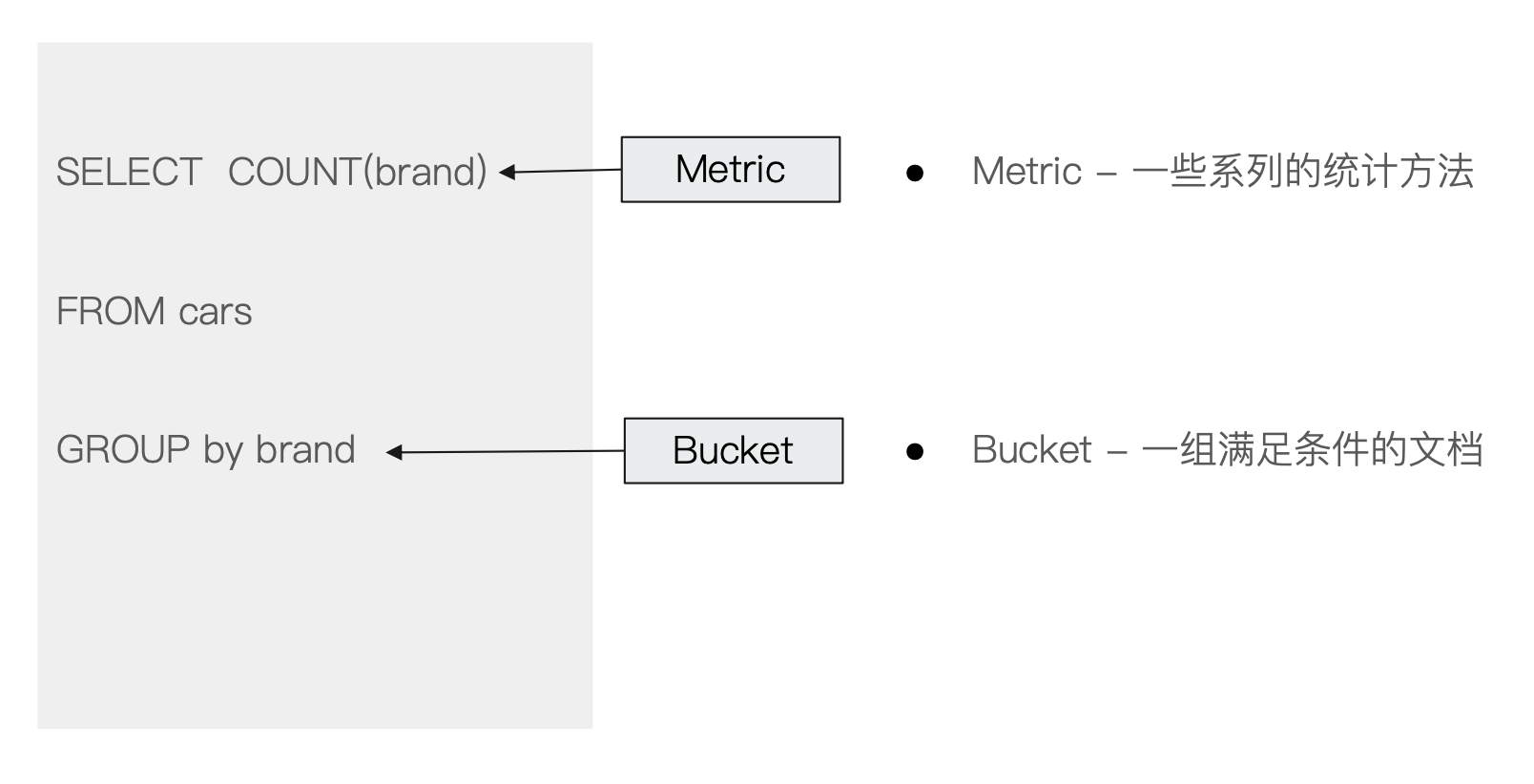
¶零、Aggregation 语法
Aggregation 属于 search 的一部分。一般情况下,建议将其 size 指定为0(表示不返回具体的文档信息,如果不这样设置,查询会像正常的查询一样也会在 hits 中返回查询命中的一些具体的文档信息)。
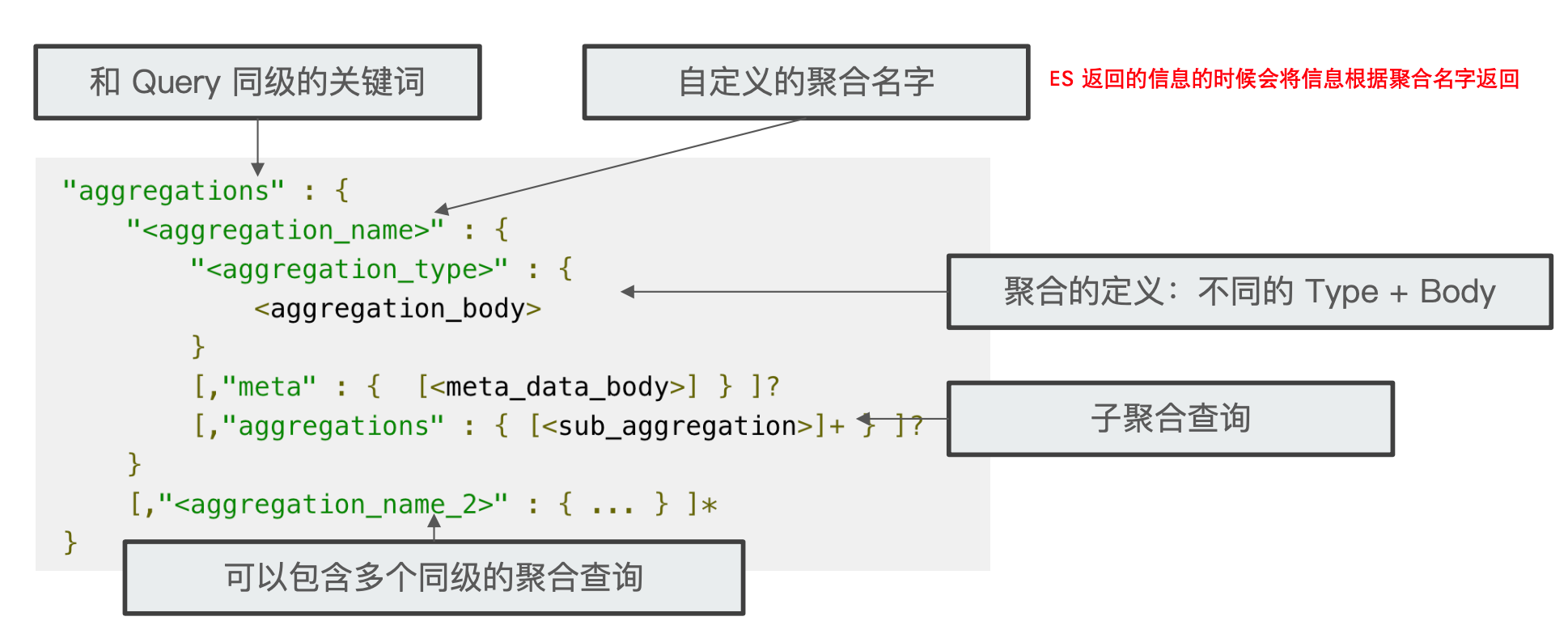
¶一、Metric Aggregation
Metric Aggregation 用来统计数据的,它可以分为两类:
- 单值分析:指输出一个分析结果
- min、max、avg、sum
- Cardinality(类似 distinct count)
- 多值分析:输出多个分析结果
- stats、extened stats
- percentile、percentile rank
- top hits
¶示例
下面我们来看一下一些具体的示例:
-
先准备1个索引和20个员工信息的文档数据
DELETE /employees PUT /employees/ { "mappings" : { "properties" : { "age" : { "type" : "integer" }, "gender" : { "type" : "keyword" }, "job" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 50 } } }, "name" : { "type" : "keyword" }, "salary" : { "type" : "integer" } } } } PUT /employees/_bulk { "index" : { "_id" : "1" } } { "name" : "Emma","age":32,"job":"Product Manager","gender":"female","salary":35000 } { "index" : { "_id" : "2" } } { "name" : "Underwood","age":41,"job":"Dev Manager","gender":"male","salary": 50000} { "index" : { "_id" : "3" } } { "name" : "Tran","age":25,"job":"Web Designer","gender":"male","salary":18000 } { "index" : { "_id" : "4" } } { "name" : "Rivera","age":26,"job":"Web Designer","gender":"female","salary": 22000} { "index" : { "_id" : "5" } } { "name" : "Rose","age":25,"job":"QA","gender":"female","salary":18000 } { "index" : { "_id" : "6" } } { "name" : "Lucy","age":31,"job":"QA","gender":"female","salary": 25000} { "index" : { "_id" : "7" } } { "name" : "Byrd","age":27,"job":"QA","gender":"male","salary":20000 } { "index" : { "_id" : "8" } } { "name" : "Foster","age":27,"job":"Java Programmer","gender":"male","salary": 20000} { "index" : { "_id" : "9" } } { "name" : "Gregory","age":32,"job":"Java Programmer","gender":"male","salary":22000 } { "index" : { "_id" : "10" } } { "name" : "Bryant","age":20,"job":"Java Programmer","gender":"male","salary": 9000} { "index" : { "_id" : "11" } } { "name" : "Jenny","age":36,"job":"Java Programmer","gender":"female","salary":38000 } { "index" : { "_id" : "12" } } { "name" : "Mcdonald","age":31,"job":"Java Programmer","gender":"male","salary": 32000} { "index" : { "_id" : "13" } } { "name" : "Jonthna","age":30,"job":"Java Programmer","gender":"female","salary":30000 } { "index" : { "_id" : "14" } } { "name" : "Marshall","age":32,"job":"Javascript Programmer","gender":"male","salary": 25000} { "index" : { "_id" : "15" } } { "name" : "King","age":33,"job":"Java Programmer","gender":"male","salary":28000 } { "index" : { "_id" : "16" } } { "name" : "Mccarthy","age":21,"job":"Javascript Programmer","gender":"male","salary": 16000} { "index" : { "_id" : "17" } } { "name" : "Goodwin","age":25,"job":"Javascript Programmer","gender":"male","salary": 16000} { "index" : { "_id" : "18" } } { "name" : "Catherine","age":29,"job":"Javascript Programmer","gender":"female","salary": 20000} { "index" : { "_id" : "19" } } { "name" : "Boone","age":30,"job":"DBA","gender":"male","salary": 30000} { "index" : { "_id" : "20" } } { "name" : "Kathy","age":29,"job":"DBA","gender":"female","salary": 20000} -
简单的Metrc 聚合:
我们下面分别通过调用_search api 进行了 agg 的操作。我们在第一个和第二个调用中分别使用了 “min” 和 “max” agg,其中"min_salary"和"max_salary"是我们对于这次agg 的业务操作的名称定义,可以看到在 ES 返回给我们的信息中的"aggregations"对象下面就是以我们起的这些业务名称作为它的属性进行返回的,里面包含了我们需要统计的信息。
另外,可以看到返回的结果中都命中了20条数据,因为我们的查询并没有加上任何条件,仅仅是一次简单的 agg 操作,所以命中了我们写入的全部20条文档数据。但是因为我们在查询的时候指定了 size 是0,所以在返回的 hits 下面的再一个 hits 属性数组是空的,没有返回任何详细的文档数据。
而在第三个 _serach查询中,我们在 aggs 下面同时指定了3个 agg,进行三个 agg 操作,ES 在返回信息给我们的时候在 aggregation 数组中将3个 agg 操作的结果全部一起返回。并用我们起的agg名字进行分隔。
而第四个操作,我们使用了一个 stats 聚合分析,它作为一个聚合 api 会同时对指定数值字段(salary)的最小、最大、平均、和、行数这5个统计。
# Metric 聚合,找到最低的工资 POST employees/_search { "size": 0, "aggs": { "min_salary": { "min": { "field":"salary" } } } } # Metric 聚合,找到最高的工资 POST employees/_search { "size": 0, "aggs": { "max_salary": { "max": { "field":"salary" } } } } # 多个 Metric 聚合,找到最低最高和平均工资 POST employees/_search { "size": 0, "aggs": { "max_salary": { "max": { "field": "salary" } }, "min_salary": { "min": { "field": "salary" } }, "avg_salary": { "avg": { "field": "salary" } } } } # 一个聚合,输出多值 POST employees/_search { "size": 0, "aggs": { "stats_salary": { "stats": { "field":"salary" } } } }
¶二、Bucket Aggregation
这个 agg 是按照一定的规则,将文档分配到不同桶中,从而达到分类的目的。ES 提供了一些常见的 Bucket Aggregation
- terms
- 对于数字类型有:
- Range、Date Range
- Histogram、Date Histogram
另外,Bucket Aggregation 是支持嵌套的。
¶Terms Aggregation
¶1、对结构化数据进行 term aggregation
结构化数据(keyword、时间、数值、布尔)默认支持 doc_values,对于这类字段默认可以进行 Terms Aggregation。但是如果是对 text 类型的字段进行 Terms Aggregation 的时候,需要打开 fielddata(在 Mapping 中设置为 enable),然后会按照分词之后的词条(term)进行分组聚合。
下面是我们对 job.keyword 字段进行 terms aggregation
# 对keword 进行聚合
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword"
}
}
}
}
可以看到是可以正常执行并返回结果的,ES 将我们的文档按照我们 job.keyword 的内容对文档进行了分桶,但是并没有将我们的 job 字段的内容进行分词(例如 Java Programmer 它还是完整的)。我们可以看到 ES 给我们返回的数据信息主要包含分桶的 key 和 桶中文档的数量,所有的桶作为一个个元素放到一个 buckets 数组中进行返回。

¶2、对 text 数据进行 term aggregation
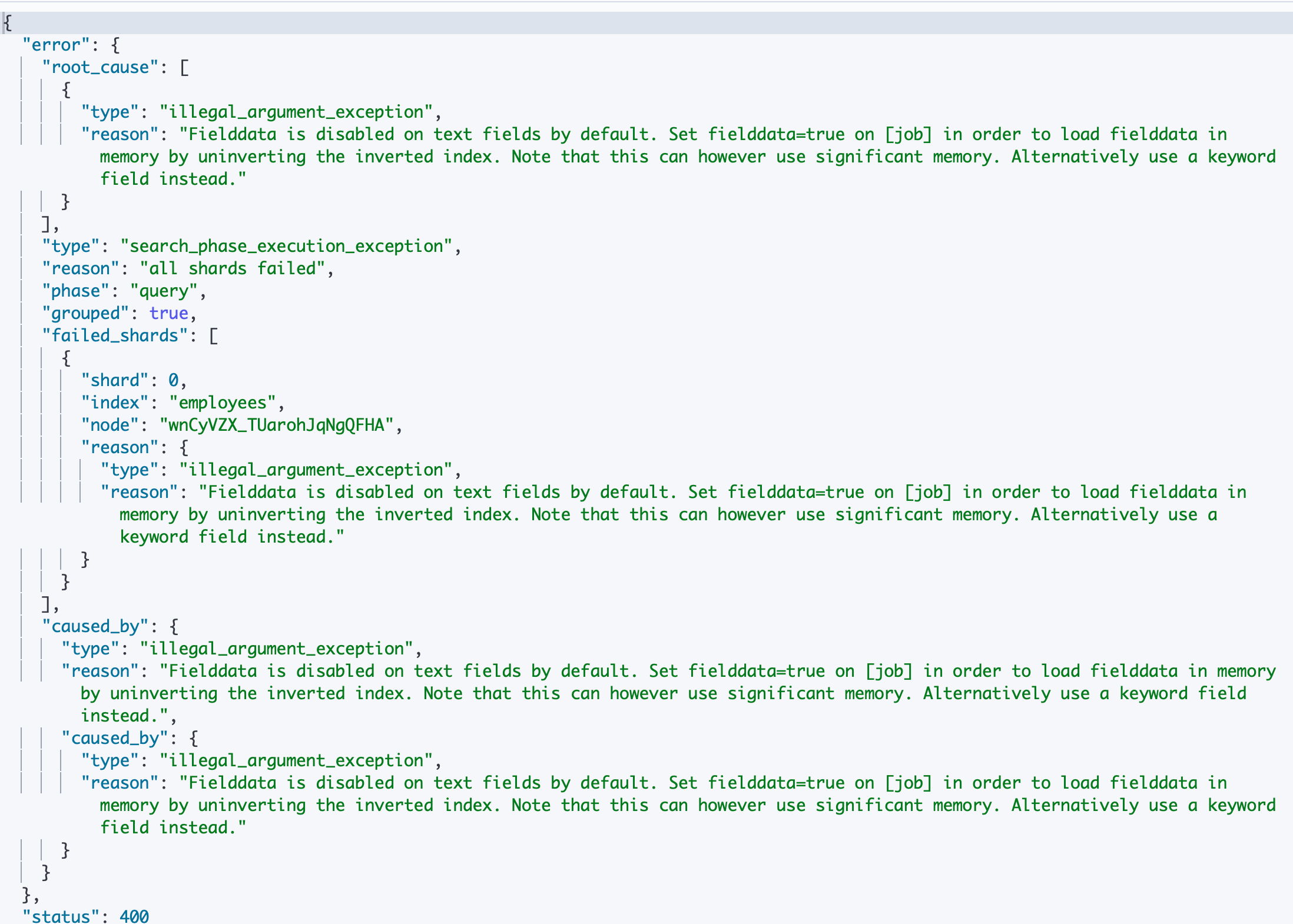
下面我们对 text 类型的 job 字段进行 term aggregation 操作,可以看到,ES 直接给我们搞错了。“Fielddata is disabled on text fields by default. Set fielddata=true on [job] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.”。告诉我们需要打开 Fieiddata
# 对 Text 字段进行 terms 聚合查询,失败
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job"
}
}
}
}
下面我们打开 fielddata
# 对 Text 字段打开 fielddata,支持terms aggregation
PUT employees/_mapping
{
"properties" : {
"job":{
"type": "text",
"fielddata": true
}
}
}
再进行term aggregation 操作
# 对 Text 字段进行 terms 分词。分词后的terms
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job"
}
}
}
}
可以看到,现在是可以对 text 字段进行 terms aggregation 操作了,但是有个问题就是它是将 text 字段进行分词之后对词条进行分组统计,例如 Java Programmer 有7个员工,Javascript Programmer 有 4个员工,那么 ES 会对这两个文本进行分词为 java、javascript和 programmer,其中 java 词条关联的文档就是7个,javascript 词条关联的文档就是4个,但是 programmer 因为关联了7个"Java Programmer"和4个"Javascript Programmer"的文档,所以这个词条(桶)下的文档数就是11个。
对于这样的结果,我们需要知道,然后根据需求来判断这个结果是否是我们需要的,如果我们的需求是原本的文本类型字段的内容作为一个完整的key对文档进行分桶,那么就像上面那样使用text 类型字段的子字段 keyword(keyword 类型)进行分桶。

¶3、Bucket Size
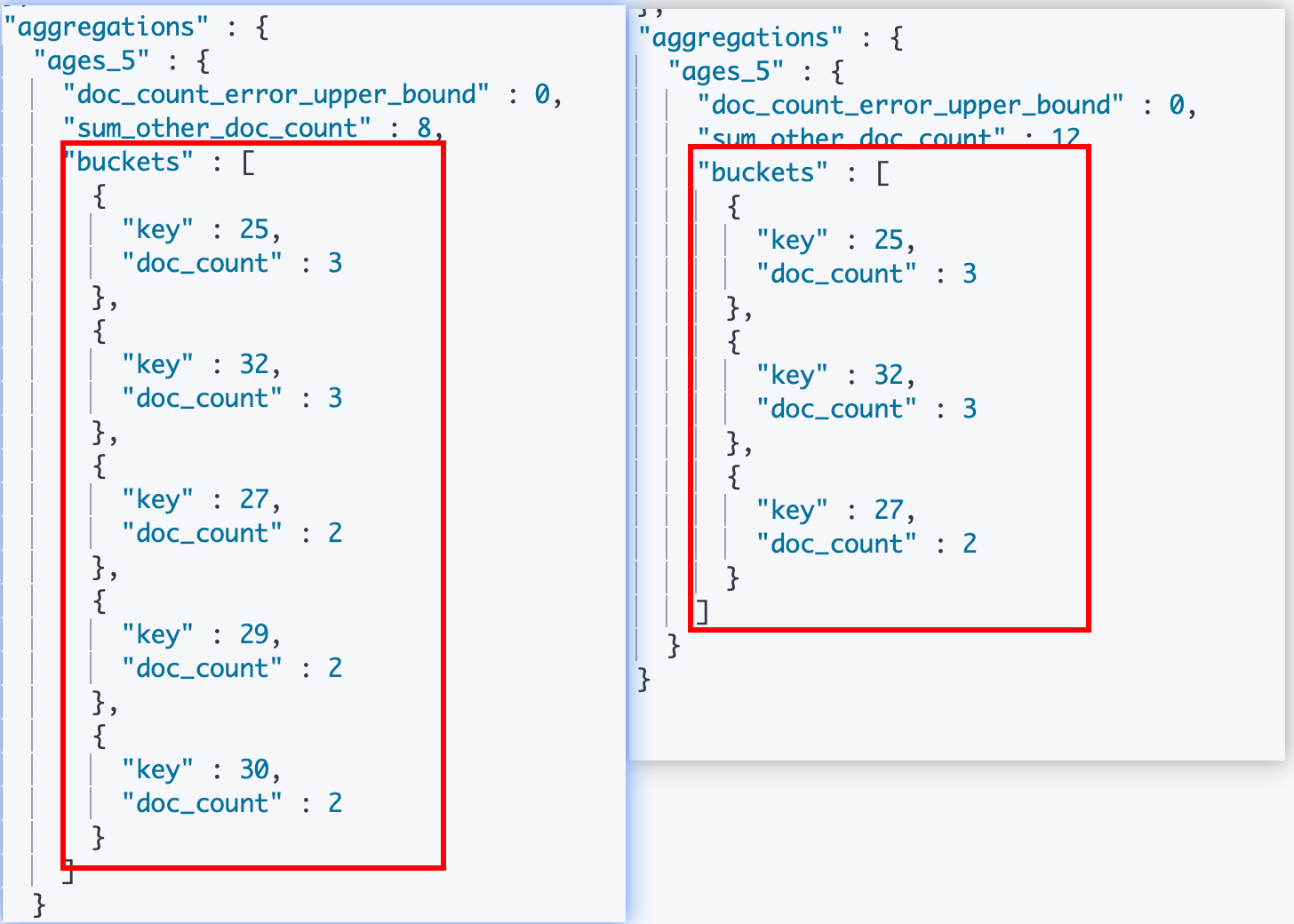
我们可以通过指定 terms agg 的 size 来配置ES 给我们返回的桶数量,看下面的例子,我们通过分别指定了 terms agg的 size 为5或者3,ES 分别给我们返回了前5个桶和前3个桶(这里我们没有指定桶的排序,所以是按照 ES 的默认排序)。
#指定 bucket 的 size
POST employees/_search
{
"size": 0,
"aggs": {
"ages_5": {
"terms": {
"field":"age",
//"size":5
"size": 3
}
}
}
}
¶4、Top Hits
在现实生活中往往有这样的需求,在某某范围内找出最 XX 的数据,即 Top K 问题。下面是一个这样的需求的实现:我们需要将所有员工按照不同工种(job)进行分类,然后找出每个工种中年龄最大的三个员工。
- 可以看到我们是先在 _search 请求 body 下面指定了一个 agg,我们起名为"jobs",然后设置一个对字段"job.keyword" 进行 terms aggregation,实现对员工按照工种分类。
- 然后在我们配置的"jobs"(会被 ES 转化成一个 term agg 对象)agg 对象下面再嵌套定义一个子的 agg,我们起名为"old_employee",然后设置该 agg 类型为 top_hits,并设置 size属性 为3,表示找出前3个文档,然后通过 sort 属性来指定按照某个字段进行排序。
可以看到 ES 给我们返回了我们想要的数据,首先是在返回对象中包含了"aggregations"属性,下面的一个子属性"jobs" 就是对应我们的第一层对于字段 job.keyword 的 terms aggregation的结果,即根据工种进行分类的各个员工桶,所有的桶又放到一个子属性"buckets"中。其中每个桶都有它的名字,即job.keyword 的一个字段值,另外还通过 doc_count 告诉了我们这个桶中有多少文档命中。而每个桶中还有一个属性就是"old_emplyee",它就是我们指定的第二个 agg,嵌套在 terms agg 内的 top_hits agg的处理结果。它包含了一个 hits 属性,该属性下面有一个 total 属性告诉我们 这个子 agg 中命中了多个文档,并在另外一个一个子属性 hits 数组中给我们返回了按照指定排序的前三个文档。
# 指定size,不同工种中,年纪最大的3个员工的具体信息
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword"
},
"aggs":{
"old_employee":{
"top_hits":{
"size":3,
"sort":[
{
"age":{
"order":"desc"
}
}
]
}
}
}
}
}
}

¶优化 Terms 聚合的性能
关于 Terms 聚合的性能优化,参考下面的官方文档在要进行Terms 聚合的字段的 mapping 上配置一个"eager_global_ordinals"的参数为 true。总的来说就是ES 中对于 terms aggregations 的操作需要保存一个"global ordinals"的数据结构在内存中的,但是默认这个数据结构是懒加载的(就是在具体收到 terms agg 请求之后才会去加载这个数据结构或者更新这个数据结构到和当前的索引数据一致),因为 ES 不知道用户要对哪个字段进行 term agg。用户可以通过对特定字段进行配置,这样 ES 就会立即在内存中对该字段加载这个数据结构,并且之后每当有新的索引进来的时候,新索引的信息也会立即同步到这个数据结构中。那么当我们进行 terms agg的时候,所有的数据都是预加载好的,在查询的时候就会有很好的性能。

https://www.elastic.co/guide/en/elasticsearch/reference/7.1/tune-for-search-speed.html
开启这个选项的一些场景:
我们明确清除哪些字段是需要做 term agg 的,并且这个操作是比较频繁的,然后该索引是一直不断有数据写入的。
¶Cardinality
前面介绍到 Cardinality 类似 sql 中的 distinct 操作,即对分组中的数据进行去重操作(可以指定某个或者某些字段,也可以不指定)。看下面的例子,我们在开启了 fielddata 之后分别对字段 job 和它的子字段 job.keyword 进行了 cardinality 操作,可以看到分别得到了两个不同的结果。作别 job 字段得到的结果是10、右边 job.keyword 得到的结果是7。这个也是因为对于结构化数据和 text 类型数据的处理差异导致的。
# 对job.keyword 和 job 进行 terms 聚合,分桶的总数并不一样
POST employees/_search
{
"size": 0,
"aggs": {
"cardinate": {
"cardinality": {
"field": "job"
//"field": "job.keyword"
}
}
}
}

¶Range聚合
前面我们提到,在 Bucket aggregation 中,除了进行 Terms 分桶之后,还可以使用 Range 对一个范围进行分桶。在 Range Aggregatioin 中可以自定义 Key。可以看到下面的例子,我们对于员工的薪资范围(数值型字段)进行分桶,通过在 _search api 的 “aggs” 属性中指定 agg 名称,然后指定 agg 类型为 “range” ,并通过"field"属性指定分桶字段为"salary",最后在"rangs"属性中定义分桶的逻辑:其中第一个桶为最小值到10000的范围的员工文档,第二个桶为10000到20000范围的员工文档,第三个范围为从20000到最大值的员工文档。
另外我们还能手动设置 range agg 中的桶的 key,例如我们在定义第三个桶的范围的时候就指定了 key 为">20000"。
然后通过执行看到 ES 给我们返回的数据中看到,第一个桶的文档有1个,第二个有4个,第三个有15个。另外第三个桶的 key 就是我们设置的">20000",而其他 key 因为没有指定,所以是 ES 默认生成的。
#Salary Ranges 分桶,可以自己定义 key
POST employees/_search
{
"size": 0,
"aggs": {
"salary_range": {
"range": {
"field":"salary",
"ranges":[
{
"to":10000
},
{
"from":10000,
"to":20000
},
{
"key":">20000",
"from":20000
}
]
}
}
}
}

¶Histogram 聚合
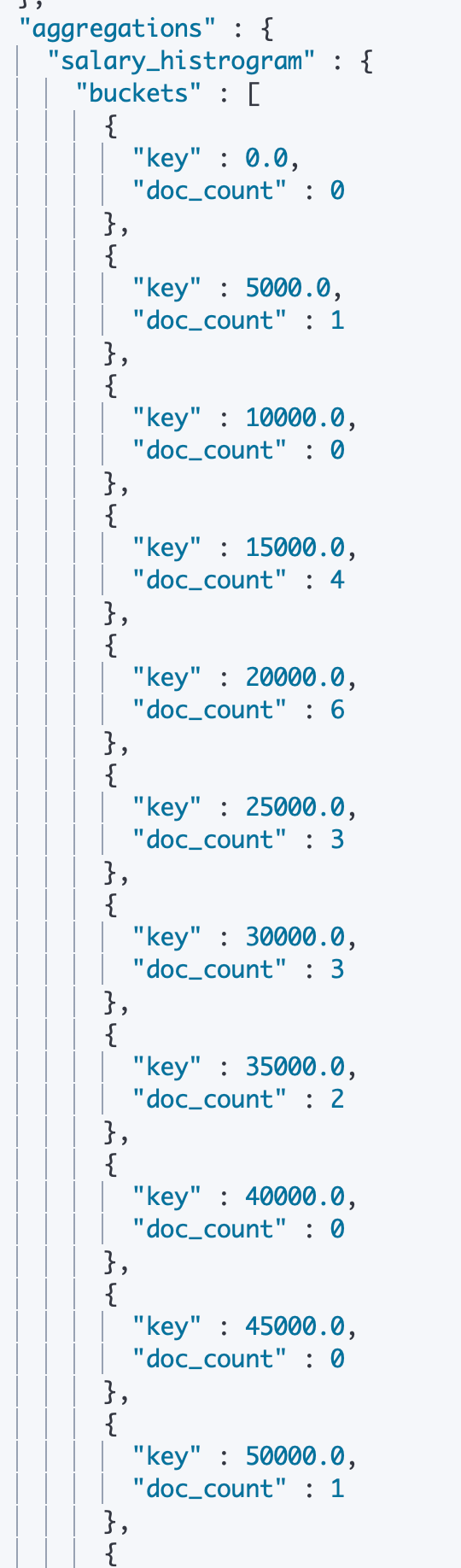
下面我们来介绍 Histogram 聚合(直方图、柱状图)。同样的我们在 _search.aggs 中设置我们的 agg 名称,然后指定 agg type 为 “histogram”,并指定 field 为 salary,然后设置间隔 interval 为5000。并通过 extened_bounds 指定了上限和下限。这指示 ES 对检索查询之后的员工文档数据取薪资为0到100000之间的数据,每差5000则分为一个桶,然后返回 agg 的结果。
通过观察结果可以看到,即使桶中没有信息,ES 也会进行返回,但是桶中文档 doc_value 的数量是0.
#Salary Histogram,工资0到10万,以 5000一个区间进行分桶
POST employees/_search
{
"size": 0,
"aggs": {
"salary_histrogram": {
"histogram": {
"field":"salary",
"interval":5000,
"extended_bounds":{
"min":0,
"max":100000
}
}
}
}
}
¶Bucket + Metric Aggregation
¶Demo1:
前面提到,Bucket 聚合分析允许通过添加子聚合分析来进一步分析(即嵌套),其子聚合分析可以是 Bucket 和 Metric。
下面是一个 Bucket 嵌套 Metic 的例子,可以看到我们在第一层 aggs 中设定一个 term agg,它根据"job.keyword"进行分桶;然后在 term agg( 名称为Job_salary_stats)中又指定了一个 stats agg,表示对桶内的数据进行常用的数值统计。
ES 给我们的返回结果也是按照第一个 term agg 分组之后的各个桶进行返回,然后桶内是第二个 stats agg 统计的相关数据。
# 嵌套聚合1,按照工作类型分桶,并统计工资信息
POST employees/_search
{
"size": 0,
"aggs": {
"Job_salary_stats": {
"terms": {
"field": "job.keyword"
},
"aggs": {
"salary": {
"stats": {
"field": "salary"
}
}
}
}
}
}

¶Demo2:
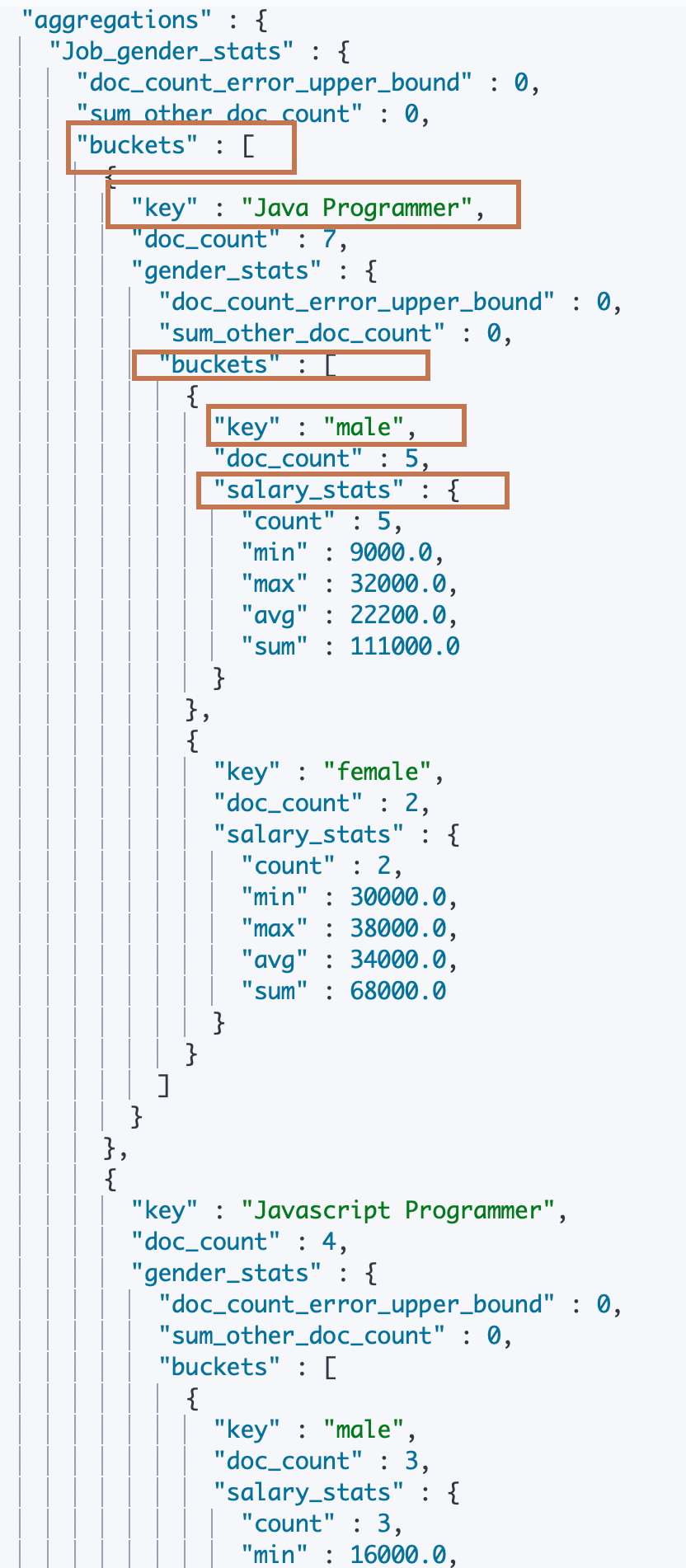
下面我们再来看一个相对又复杂了一点的 Agg 嵌套,这次我们是先对 字段 “job.keyword” 进行分桶,即将所有员工按照工种进行分类,然后在各个工种桶中再按照性别字段 “gender” 进行分桶,即在工种之下再对员工进行性别的分类,然后再在性别桶下使用 stats agg 对员工薪资"salary"字段进行统计。
# 多次嵌套。根据工作类型分桶,然后按照性别分桶,计算工资的统计信息
POST employees/_search
{
"size": 0,
"aggs": {
"Job_gender_stats": {
"terms": {
"field": "job.keyword"
},
"aggs": {
"gender_stats": {
"terms": {
"field": "gender"
},
"aggs": {
"salary_stats": {
"stats": {
"field": "salary"
}
}
}
}
}
}
}
}
¶三、Pipeline Aggregation
Pipeline Aggregation 指的是支持对聚合分析的结果( 即经过分桶之后的或者还同时进行 Metric 的Bucket),再次进行聚合分析。
Pipeline 的分析结果会输出到愿结果中,根据位置的不同,分为两类:
- Sibling:结果和现有分析结果同级
- max、min、avg & sum Bucket
- Stats、Extended Stats Bucket
- Percentiles Bucket
- Parent:结果内嵌到现有的聚合分析结果中
- Derivative(求导)
- Cumultive Sum(累计求和)
- Moving Function(滑动窗口)
¶Sibling Pipeline
¶1)求所有工种中平均员工薪资最低的工种
-
准备数据
DELETE employees PUT /employees/_bulk { "index" : { "_id" : "1" } } { "name" : "Emma","age":32,"job":"Product Manager","gender":"female","salary":35000 } { "index" : { "_id" : "2" } } { "name" : "Underwood","age":41,"job":"Dev Manager","gender":"male","salary": 50000} { "index" : { "_id" : "3" } } { "name" : "Tran","age":25,"job":"Web Designer","gender":"male","salary":18000 } { "index" : { "_id" : "4" } } { "name" : "Rivera","age":26,"job":"Web Designer","gender":"female","salary": 22000} { "index" : { "_id" : "5" } } { "name" : "Rose","age":25,"job":"QA","gender":"female","salary":18000 } { "index" : { "_id" : "6" } } { "name" : "Lucy","age":31,"job":"QA","gender":"female","salary": 25000} { "index" : { "_id" : "7" } } { "name" : "Byrd","age":27,"job":"QA","gender":"male","salary":20000 } { "index" : { "_id" : "8" } } { "name" : "Foster","age":27,"job":"Java Programmer","gender":"male","salary": 20000} { "index" : { "_id" : "9" } } { "name" : "Gregory","age":32,"job":"Java Programmer","gender":"male","salary":22000 } { "index" : { "_id" : "10" } } { "name" : "Bryant","age":20,"job":"Java Programmer","gender":"male","salary": 9000} { "index" : { "_id" : "11" } } { "name" : "Jenny","age":36,"job":"Java Programmer","gender":"female","salary":38000 } { "index" : { "_id" : "12" } } { "name" : "Mcdonald","age":31,"job":"Java Programmer","gender":"male","salary": 32000} { "index" : { "_id" : "13" } } { "name" : "Jonthna","age":30,"job":"Java Programmer","gender":"female","salary":30000 } { "index" : { "_id" : "14" } } { "name" : "Marshall","age":32,"job":"Javascript Programmer","gender":"male","salary": 25000} { "index" : { "_id" : "15" } } { "name" : "King","age":33,"job":"Java Programmer","gender":"male","salary":28000 } { "index" : { "_id" : "16" } } { "name" : "Mccarthy","age":21,"job":"Javascript Programmer","gender":"male","salary": 16000} { "index" : { "_id" : "17" } } { "name" : "Goodwin","age":25,"job":"Javascript Programmer","gender":"male","salary": 16000} { "index" : { "_id" : "18" } } { "name" : "Catherine","age":29,"job":"Javascript Programmer","gender":"female","salary": 20000} { "index" : { "_id" : "19" } } { "name" : "Boone","age":30,"job":"DBA","gender":"male","salary": 30000} { "index" : { "_id" : "20" } } { "name" : "Kathy","age":29,"job":"DBA","gender":"female","salary": 20000} -
我们对员工按照工种进行分组之后,找出平均工资最低的工种。
可以看到,上面的需求可以理解为,将员工文档按照工种"job.keyword"进行分组分组之后(Terms of Bucket Agg),然后求出所有分桶中员工文档的平均工资 salary(Metric Agg),然后再对所有的桶进行分析(每个返回的桶都包含了这个 Metric Agg 的结果),即求出 Metric Agg 结果最低的那个桶。
我们在 aggs 同级的属性中声明了一个"min_salary_by_job"的属性,然后再给它设置一个"min_bucket" 的子属性。表述这是一个用户自定义的名为"min_salary_by_job"的 "min_bucket"类型的 Pipeline Agg,然后给"min_bucket"设置一个"buckets_path"的子属性, 这是一个 pipeline Agg 的通用属性,表示需要进行分析的 Aggregation 的路径,我们上面先是名为"jobs"的 trems agg 进行了分桶,然后在"jobs"里面嵌套定义了一个 “avg_salary"的 Metric agg。所以我们需要做 pipeline agg 的路径就是"jobs > avg_salary”。
后面的返回结果中在 “jobs” agg 的结果下面有一个同级的返回就是"min_salary_by_job",即我们的 pipeline agg 的结果,返回的就是平均工资最少的 key 为"Javascript Programmer"的 Bucket。
因为它是定义在我们需要分析的桶的同级的,然后在"buckets_path"中指定要分析的对象是bucket agg 的一个子属性(Metric agg),返回结果也是同级,所以称之为 Sibling Pipeline(Bucket As Sibling/Brothers)。
# 平均工资最低的工作类型 POST employees/_search { "size": 0, "aggs": { "jobs": { "terms": { "field": "job.keyword", "size": 10 }, "aggs": { "avg_salary": { "avg": { "field": "salary" } } } }, "min_salary_by_job":{ "min_bucket": { "buckets_path": "jobs>avg_salary" } } } }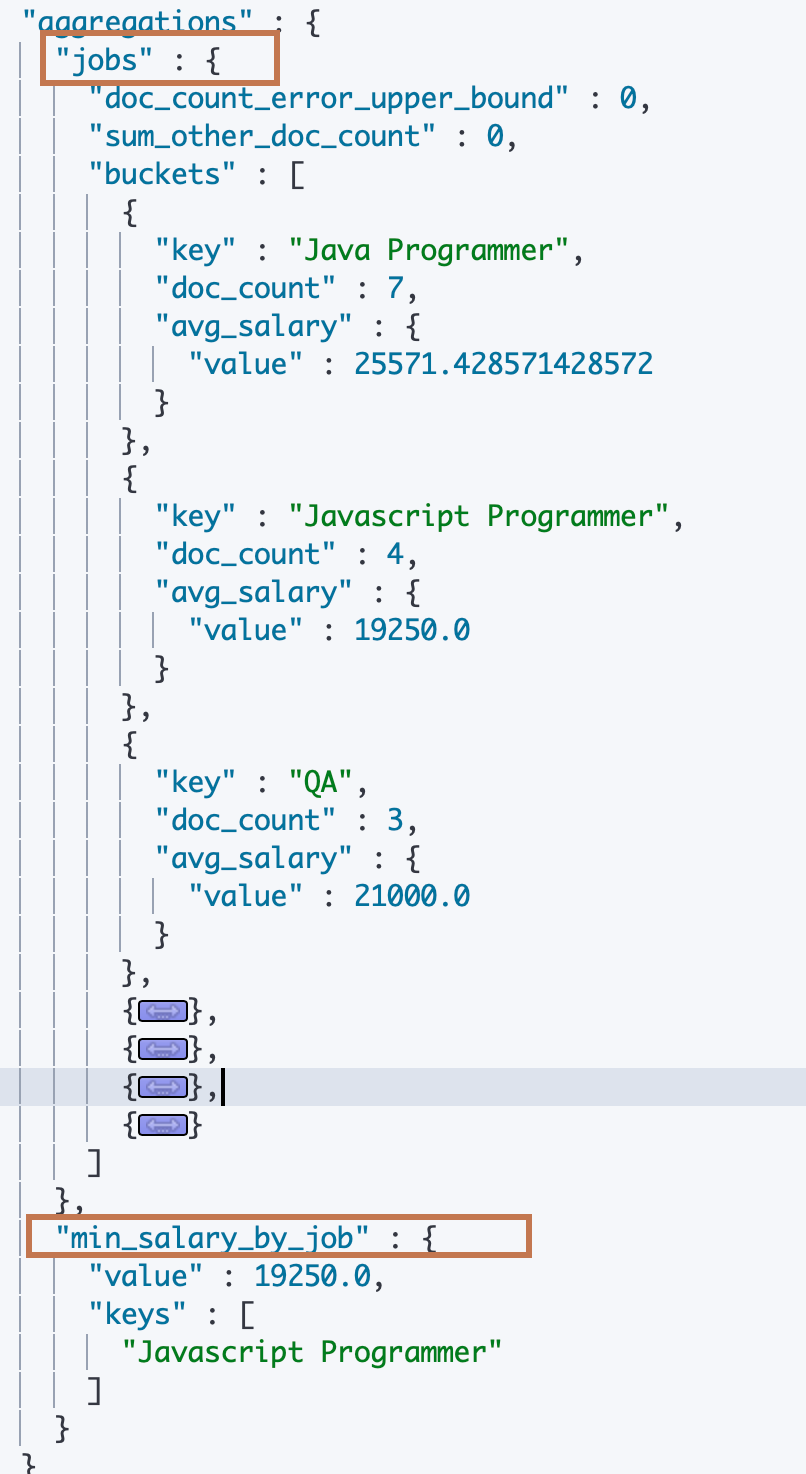
¶2)基于所有工种的平均工资进行求平均工资
以下是对分桶后的工种 Buckets 进行一次求平均工资的 pipeline agg,可以看到这次 pipeline agg 返回的结果仅仅是一个数值。
# 平均工资的平均工资
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"avg_salary_by_job":{
"avg_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}

¶3)对各工种的平均工资求百分数
可以看到 ES 默认只是求出第1、5、25、50、75、95、99百分位数,分别是19250(Javascript Programmer)、21000(QA)、25000(DBA)、35000(Product Manager)、50000(Dev Manager)、50000(Dev Manager)。即只有百分之一的工种的平均工资低于等于19250(Js)、有百分之五低于等于21000(QA)、有百分之五十低于等于25000(DBA)有百分之七十五的工资低于等于35000(PM)、有百分之九十五和九十九工种都低于等于50000(Dev Manager)。
# 平均工资的百分位数
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"percentiles_salary_by_job":{
"percentiles_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}

¶4)其他例子
# 平均工资最高的工作类型
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"max_salary_by_job":{
"max_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
# 平均工资的统计分析
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"stats_salary_by_job":{
"stats_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
¶Parent Pipeline
¶1)Derivative Aggregation
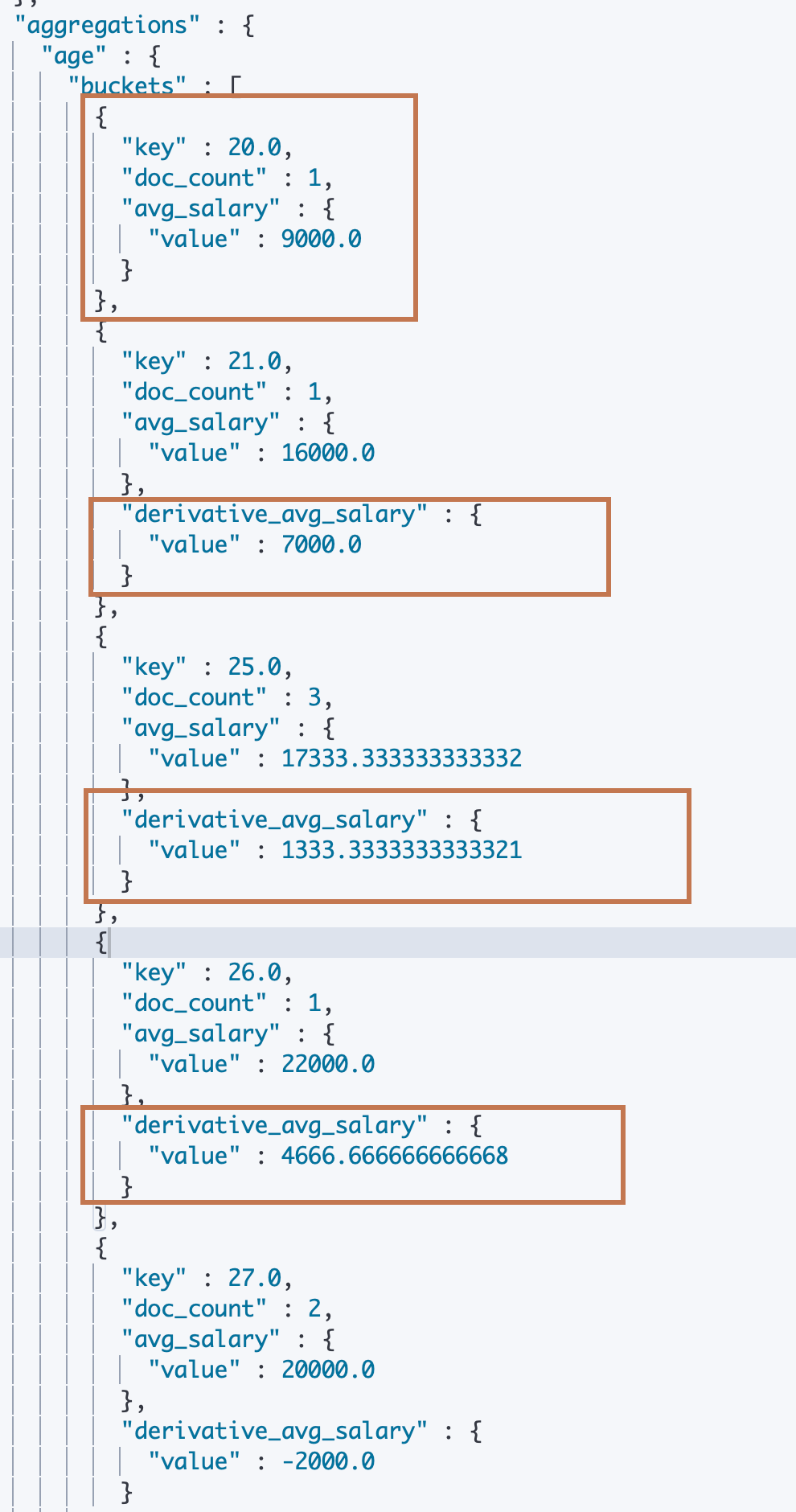
对员工的年龄每间隔一岁为一组进行分组,然后求分组内的平均工资(直方图),并求出所有年龄分组的平均工资与(减去)前一个年龄分组的平均工资的差值。这里我们使用 Derivative Aggregation。
可以看到,我们先是定义了一个 “histogram” (bucket) agg,实现员工按照一岁的年龄间隔的分桶,然后再对每个桶定义一个 “avg” (Metric) agg求每隔桶内员工的平均工资。最后我们在avg metric agg 的同级,也是 histogram bucket agg 的子级(桶内)定义了一个名为"derivative_avg_salary"的derivative (pipeline) agg,进行直方图每个区间(bucket)与上一个区间的 metic agg 的差值求解。
可以看到我们这个pipeline agg 是定义在 bucket agg 之内的(因为每个 bucket 都会对应一个属于该 bucket 的 pipeline 分析结果,所以理所应当定义在每隔 bucket 之内),而 pipeline agg的 “buckets_path"属性指定的是"avg_salary”,它是"histogram" bucket agg 的子 agg(Metric agg)。
另外看到 ES 的返回结果,除了第一个 histogram bucket之外其他的 bucket 之内都带有"derivative_avg_salary"的一个分析结果。所以我们称这种 pipeline agg 为 Parent Pipeline(Bucket As Parent)。
#按照年龄对平均工资求导
POST employees/_search
{
"size": 0,
"aggs": {
"age": {
"histogram": {
"field": "age",
"min_doc_count": 1,
"interval": 1
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
},
"derivative_avg_salary":{
"derivative": {
"buckets_path": "avg_salary"
}
}
}
}
}
}
¶2)cumulative_sum aggregation
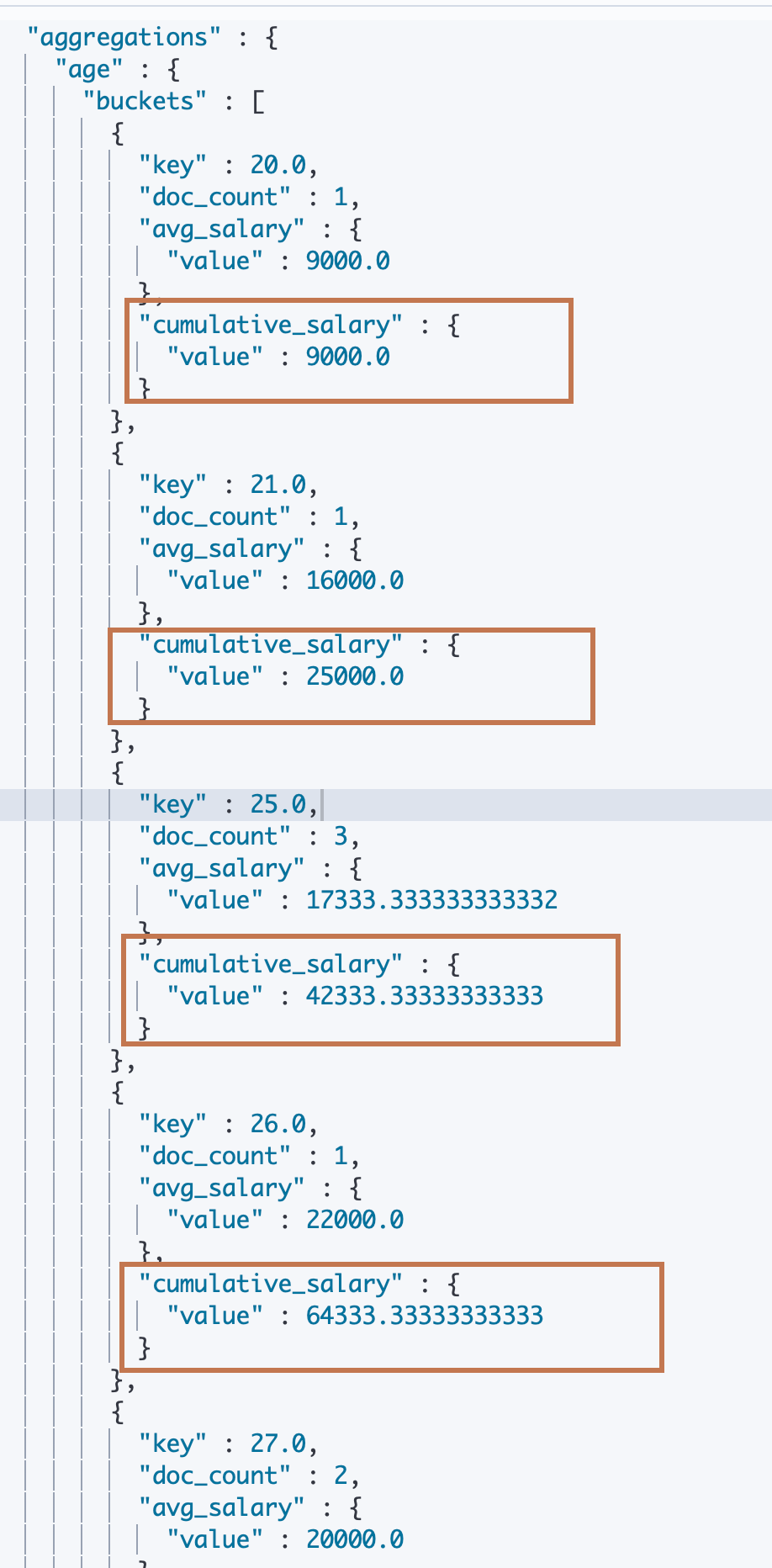
这是一个对 bucket(parent of pipeline) 进行累加求和的 agg,可以看到结果返回的每一个 bucket 中都包含了对其 Metric agg 的结果再次进行 cumulative_sum agg 的结果,第一个 bucket 的cumulative_sum 的结果就 Metric agg 原本的结果,之后每个cumulative_sum agg 的结果都是对前一个 cumulative agg 结果的累加。
#Cumulative_sum
POST employees/_search
{
"size": 0,
"aggs": {
"age": {
"histogram": {
"field": "age",
"min_doc_count": 1,
"interval": 1
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
},
"cumulative_salary":{
"cumulative_sum": {
"buckets_path": "avg_salary"
}
}
}
}
}
}
¶3)Moving Function
Moving Function也是一个Parent Pipeline Agg。它表示对于一个一定顺序的集合,维护一个窗口大小 N(当前 Bucket 往前的 N 个Buckets,支持用户自定义,默认不确定,待看,这里指定了是10),然后对这 N 个 Buckets 进行一个 Function 求解(默认值不确定,待看,支持用户自定义,这里我们定义了一个"script"类型的 Function:“MovingFunctions.min(values)” :表示对 "avg_salary"的结果"value"求最小值,也就是求窗口之内的 Bucket 的 Metric 最小值)。
#Moving Function
POST employees/_search
{
"size": 0,
"aggs": {
"age": {
"histogram": {
"field": "age",
"min_doc_count": 1,
"interval": 1
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
},
"moving_avg_salary":{
"moving_fn": {
"buckets_path": "avg_salary",
"window":10,
"script": "MovingFunctions.min(values)"
}
}
}
}
}
}

¶四、Matrix Aggregation
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/search-aggregations-matrix.html
¶五、相关阅读
以上介绍都是一些入门的介绍,当遇到要详细使用的时候,如果上面的介绍无法满足,可以去阅读以下文档,或者去寻找其他相关的文档。
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/search-aggregations-metrics.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/search-aggregations-bucket.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/search-aggregations-pipeline.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/search-aggregations-matrix.html
聚合的作用范围与排序
ES 聚合分析的默认作用范围是 query 的查询结果集,如果没有使用指定 query,那么就是指定索引的所有文档数据。

同时 ES 还支持以下方式改变聚合的作用范围:
- Filter
- Post_Filter
- Global
下面我们来对这三种改变聚合的作用范围的操作进行分析,在此之前先准备数据:
DELETE /employees
PUT /employees/
{
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"gender" : {
"type" : "keyword"
},
"job" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 50
}
}
},
"name" : {
"type" : "keyword"
},
"salary" : {
"type" : "integer"
}
}
}
}
PUT /employees/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "Emma","age":32,"job":"Product Manager","gender":"female","salary":35000 }
{ "index" : { "_id" : "2" } }
{ "name" : "Underwood","age":41,"job":"Dev Manager","gender":"male","salary": 50000}
{ "index" : { "_id" : "3" } }
{ "name" : "Tran","age":25,"job":"Web Designer","gender":"male","salary":18000 }
{ "index" : { "_id" : "4" } }
{ "name" : "Rivera","age":26,"job":"Web Designer","gender":"female","salary": 22000}
{ "index" : { "_id" : "5" } }
{ "name" : "Rose","age":25,"job":"QA","gender":"female","salary":18000 }
{ "index" : { "_id" : "6" } }
{ "name" : "Lucy","age":31,"job":"QA","gender":"female","salary": 25000}
{ "index" : { "_id" : "7" } }
{ "name" : "Byrd","age":27,"job":"QA","gender":"male","salary":20000 }
{ "index" : { "_id" : "8" } }
{ "name" : "Foster","age":27,"job":"Java Programmer","gender":"male","salary": 20000}
{ "index" : { "_id" : "9" } }
{ "name" : "Gregory","age":32,"job":"Java Programmer","gender":"male","salary":22000 }
{ "index" : { "_id" : "10" } }
{ "name" : "Bryant","age":20,"job":"Java Programmer","gender":"male","salary": 9000}
{ "index" : { "_id" : "11" } }
{ "name" : "Jenny","age":36,"job":"Java Programmer","gender":"female","salary":38000 }
{ "index" : { "_id" : "12" } }
{ "name" : "Mcdonald","age":31,"job":"Java Programmer","gender":"male","salary": 32000}
{ "index" : { "_id" : "13" } }
{ "name" : "Jonthna","age":30,"job":"Java Programmer","gender":"female","salary":30000 }
{ "index" : { "_id" : "14" } }
{ "name" : "Marshall","age":32,"job":"Javascript Programmer","gender":"male","salary": 25000}
{ "index" : { "_id" : "15" } }
{ "name" : "King","age":33,"job":"Java Programmer","gender":"male","salary":28000 }
{ "index" : { "_id" : "16" } }
{ "name" : "Mccarthy","age":21,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "index" : { "_id" : "17" } }
{ "name" : "Goodwin","age":25,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "index" : { "_id" : "18" } }
{ "name" : "Catherine","age":29,"job":"Javascript Programmer","gender":"female","salary": 20000}
{ "index" : { "_id" : "19" } }
{ "name" : "Boone","age":30,"job":"DBA","gender":"male","salary": 30000}
{ "index" : { "_id" : "20" } }
{ "name" : "Kathy","age":29,"job":"DBA","gender":"female","salary": 20000}
¶Filter
前面提到 agg 是基于query 的结果进行的,但是我们还可以基于 query 的结果再进行一次 filter,然后将 filter 之后的数据进行 agg。这里将介绍在 agg 内部使用 filter 对查询出来的数据范围进行过滤。
可以看到下面的例子中,我们没有使用 query 操作,那么 agg 接收到的数据将是 employees 下的所有文档数据。然后我们在 aggs 属性下定义了两个 agg,分别是 older_person 和 all_jobs:
-
其中 older_person 下面先是指定了一个 filter 子属性以及再定义了一个 aggs 子属性。这表示一个 filter 操作,ES 会对该"older_person" agg 的数据先进行一个 filter操作(过滤数据),然后将操作之后的结果输入到"aggs",其中 aggs 中定义了一个 term 类型的名为 jobs 的 bucket agg。
所以整个操作就是在所有员工中过滤出来35岁以上的员工然后按照工种进行分桶。
-
而下面的 all_jobs 子属性直接定义了一个"term"类型的 agg 操作,所以就是不过滤任何数据,直接进行一个 term agg 的分桶操作。
从返回结果可以看到进过 filter 操作之后的 older_person 只有2个员工文档数据,分桶之后得到了"Dev Manager"和"Java Programmer"两个桶,桶中分别有1个文档。
#Filter
POST employees/_search
{
"size": 0,
"aggs": {
"older_person": {
"filter":{
"range":{
"age":{
"from":35
}
}
},
"aggs":{
"jobs":{
"terms": {
"field":"job.keyword"
}
}
}},
"all_jobs": {
"terms": {
"field":"job.keyword"
}
}
}
}

¶Post Filter
顾名思义,Post FIlter 指的就是进行 agg 之后再进行一次 filter,当然,和 filter 的作用对象一样,就是 query 之后的所有文档数据,也就是输入到 aggs 中的所有进行 agg 的文档。
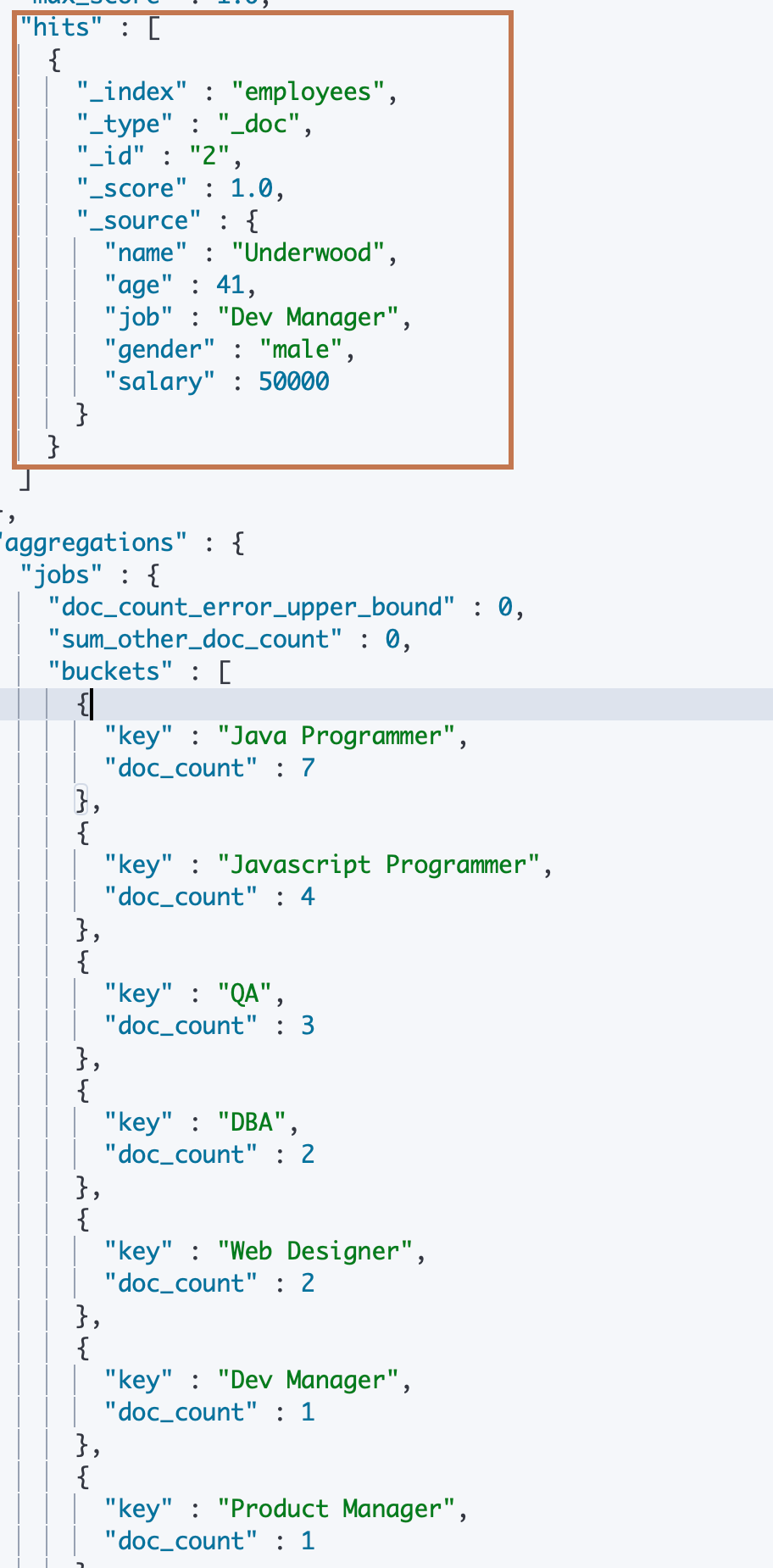
可以看到下面例子中,我们默认对 emplyees 中的所有文档数据以"job.keyword"字段进行 term agg 分桶。然后在 “aggs” 对象后面定义了一个同级的"post_filter"对象,并指定 filter 类型为 match,指定 match 的字段和值分别是"job.keyword"和"Dev Manager"。表示我们对所有的数据进行 aggs 操作之后(只有一个名为"jobs"的 term bucket agg)再进行"job.keyword=Dev Manager"到数据匹配的过滤。
从返回结果可以看到,“hits” 中返回了所有字段"job"为"Dev Manager" 的文档数据,只有一条,而下面的 “aggregations” 就是terms agg 的结果了。
#Post field. 一条语句,找出所有的job类型。还能找到聚合后符合条件的结果
POST employees/_search
{
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword"
}
}
},
"post_filter": {
"match": {
"job.keyword": "Dev Manager"
}
}
}
¶Global
在下面的例子,我们在第一层 aggs 前面定义了一个 query 对象查询出大于等于40岁的员工。然后传入到第一层 aggs 对象中。而 aggs 对象中定义了两个子对象,一个是 jobs,一个是 all。
-
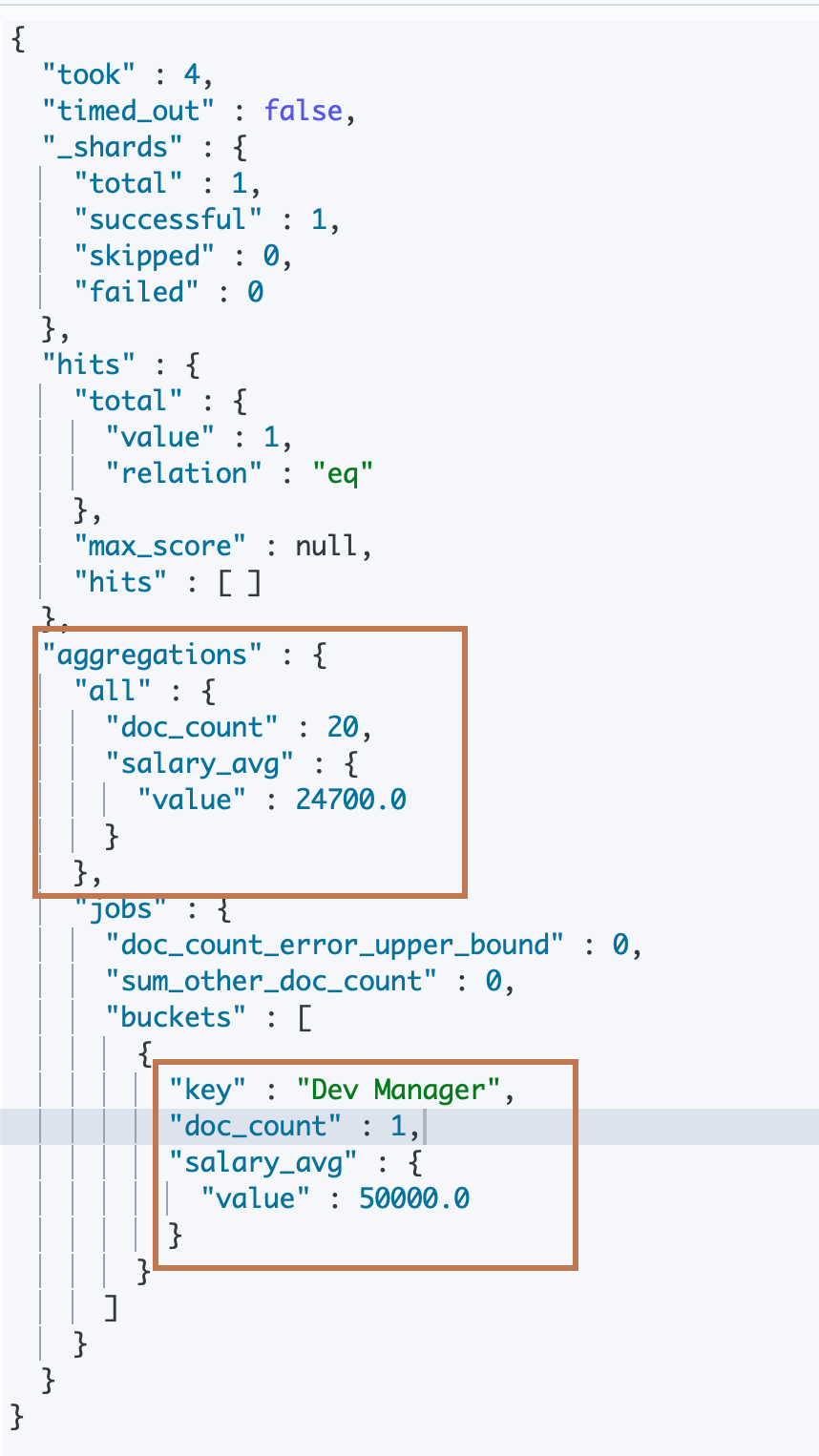
jobs 是一个 term bucket agg,它下面还定义了一个 aggs,里面只有一个 avg metric agg。表示对员工按照工种分桶然后求平均工资,而作用范围就是 query 传入到第一层 aggs 的所有数据,即求所有工种中40以上的员工的平均工资。
-
而 all 下面则是直接定义了一个 avg metric agg,即没有进行分桶操作直接求员工的平均值。但是留意到前面还定义了一个"global"属性,它表示一个查询对象,即和第一层"query"生成的对象是一样的,在这里定义的查询对象会忽略第一层 query传入到第一层 aggs 传入到 all 的数据范围(实际上就是忽略所有输入数据),用这个查询对象去查询当前指定索引的文档数据直接进行 avg metric agg 操作。
可以看到结果返回中名为 all 的 agg 命中数据有20条,而 jobs 只有1条。
#global
POST employees/_search
{
"size": 0,
"query": {
"range": {
"age": {
"gte": 40
}
}
},
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword"
},
"aggs": {
"salary_avg": {
"avg": {
"field": "salary"
}
}
}
},
"all":{
"global":{},
"aggs":{
"salary_avg":{
"avg":{
"field":"salary"
}
}
}
}
}
}
¶排序
¶1、基于 bucket agg 的普通属性进行排序
默认情况下,aggs 的结果是按照 buckets 的 doc_count(_count)进行降序排序返回的(所有 agg 都基于 buckets agg,即数据聚合分组,有了一个数据分组才会有其他分析的操作,如果不进行 bucket 操作,那么所有数据就是一个缺省的 bucket)。
可以看到下面的例子中,没有指定任何排序,返回的分桶按照 doc_count 从7到1进行降序排序返回。
POST employees/_search
{
"size": 0,
"query": {
"range": {
"age": {
"gte": 20
}
}
},
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword"
}
}
}
}

我们通过给 agg 对象指定 order 属性可以实现对于返回 bucket 的自定义排序。可以看到下面例子中,我们通过给一个 terms agg 对象 job 指定一个"order"属性,并定义了两个排序规则,分别是按照bucket 的"_count"字段进行升序排序,在"_count"字段一样的 buckets 中按照 bucket 的"_key"对象进行降序排序。
从返回结果可以看到所有 bucket 按照从1到7的_count 字段的升序排序。其中前两个 bucket 的 doc_count 是一样的,此时按照 _key 进行降序排序。
POST employees/_search
{
"size": 0,
"query": {
"range": {
"age": {
"gte": 20
}
}
},
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword",
"order":[
{"_count":"asc"},
{"_key":"desc"}
]
}
}
}
}

¶2、基于 bucket agg 的子 agg 的属性(多层属性)进行排序
此外,我们还能在 order 中指定对 bucket agg的子 metric agg 的结果进行排序,请看下面例子,我们在 order 中指定了 jobs (terms bucket)agg 的子 avg metric agg 的名称,并指定排序类型为降序排序。
下面的 ES 返回结果中对返回的按照工种分桶的 buckets 按照平均工资 降序返回。
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword",
"order":[ {
"avg_salary":"desc"
}]
},
"aggs": {
"avg_salary": {
"avg": {
"field":"salary"
}
}
}
}
}
}

上面的例子中,term bucket agg 的子 agg 是一个只有一个输出值的 avg metric agg。下面的例子展示的是一个拥有多输出值的 stats agg。可以看到我们可以通过"xxx.属性"的方式来指定按照 bucket 的子对象(应该不仅仅包括子 bucket)进行排序。
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword",
"order":[ {
"stats_salary.min":"desc"
}]
},
"aggs": {
"stats_salary": {
"stats": {
"field":"salary"
}
}
}
}
}
}
聚合的精准问题
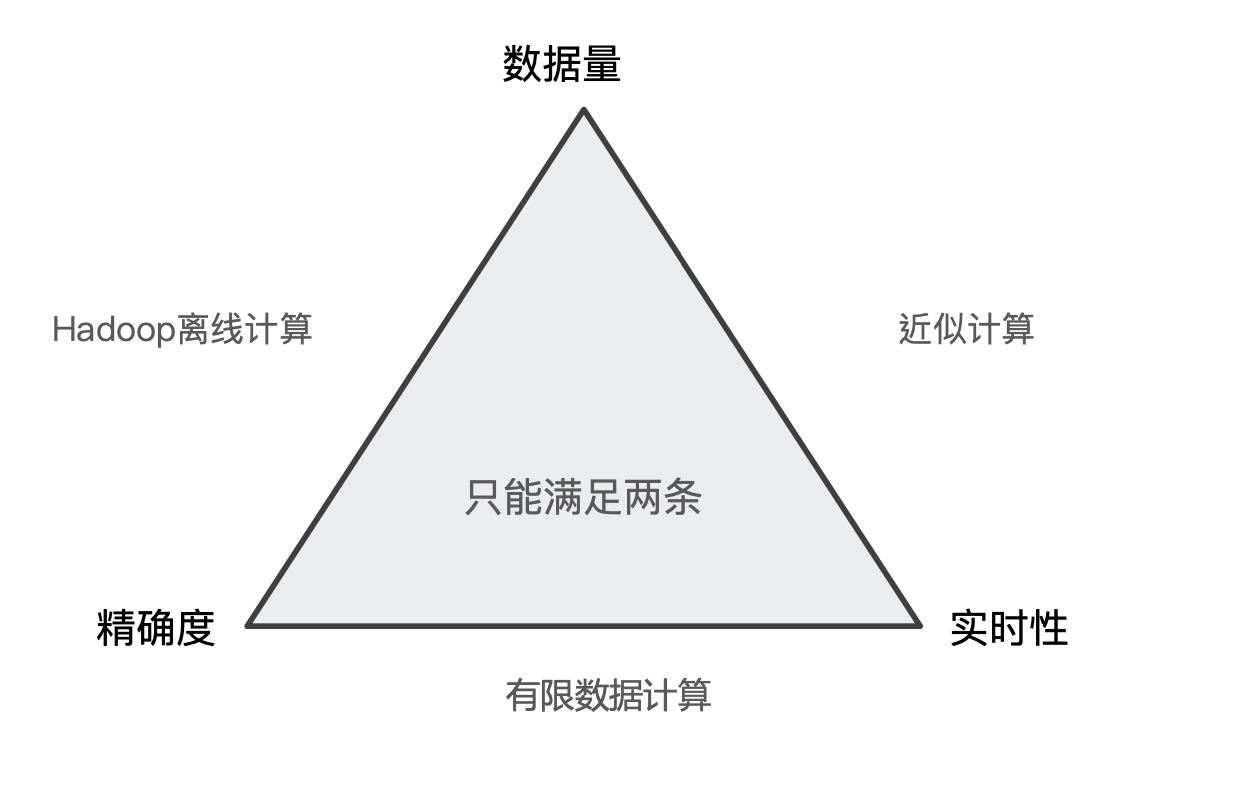
前面提到,ES 是一个可以支持对海量数据进行一个近实时搜索的搜索引擎,但是 ES 是牺牲了一定的搜索精准度来实现这个近实时的效果的。
对于所有的数据计算来说,在数据量、精准度和实时性三个维度,只能同时满足两个。
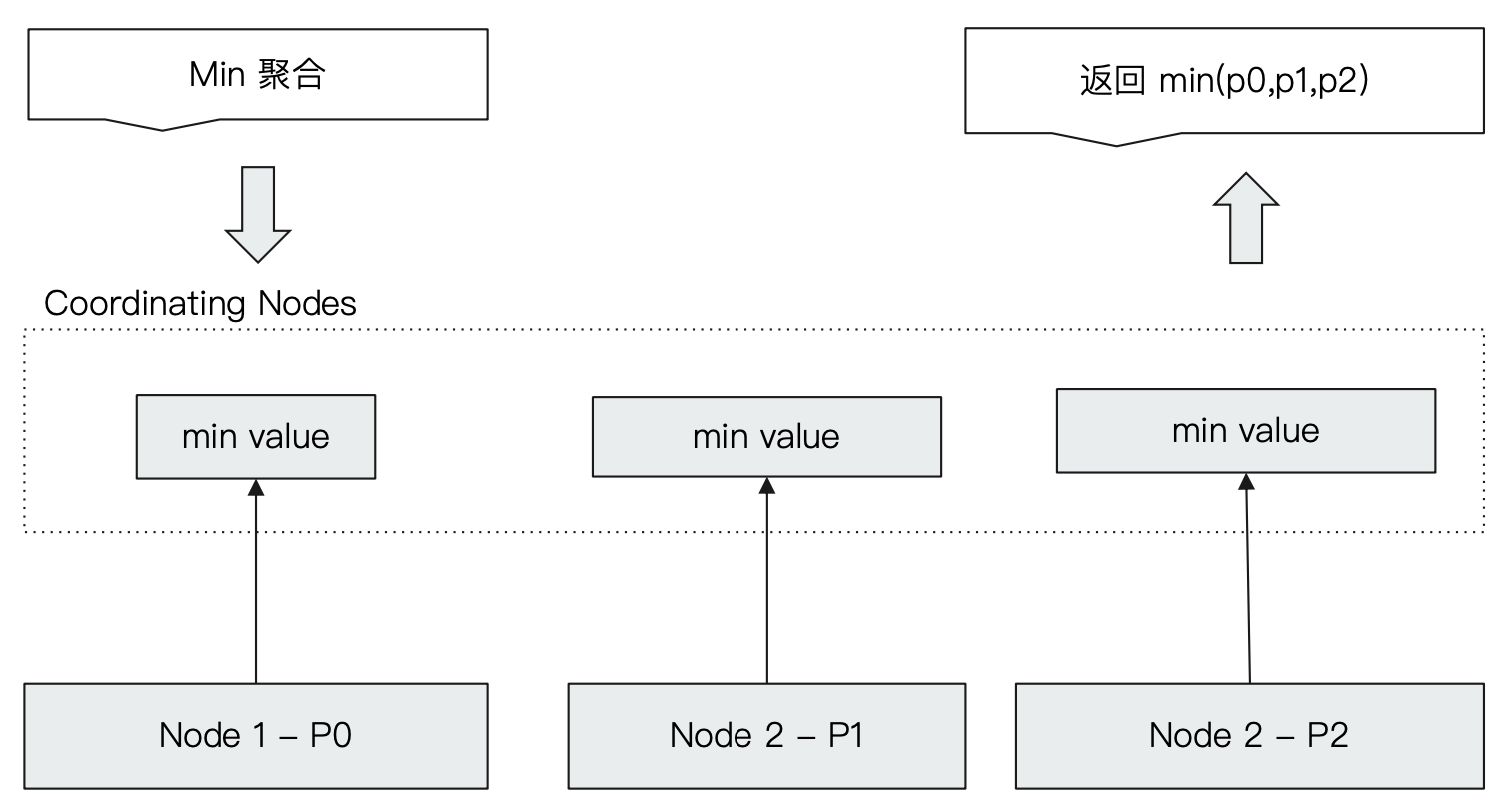
¶Min 聚合分析的执行流程(准确)
我们可以看到,当 ES 的一个 coordinating节点接收到一个 min 聚合请求的时候,当聚合的数据范围分布在三个分片上,那么 coordinating 节点就会分别像这三个 data node 发出求 min 聚合的请求,此时这三个数据节点都分别求出自己的 min 聚合结果然后返回到 coordinating node,coordinating node 再在三个分片的结果中求出最小值,最终把结果返回给用户。
所以对于 min 操作来说,是完全没有精准度损失的问题的。
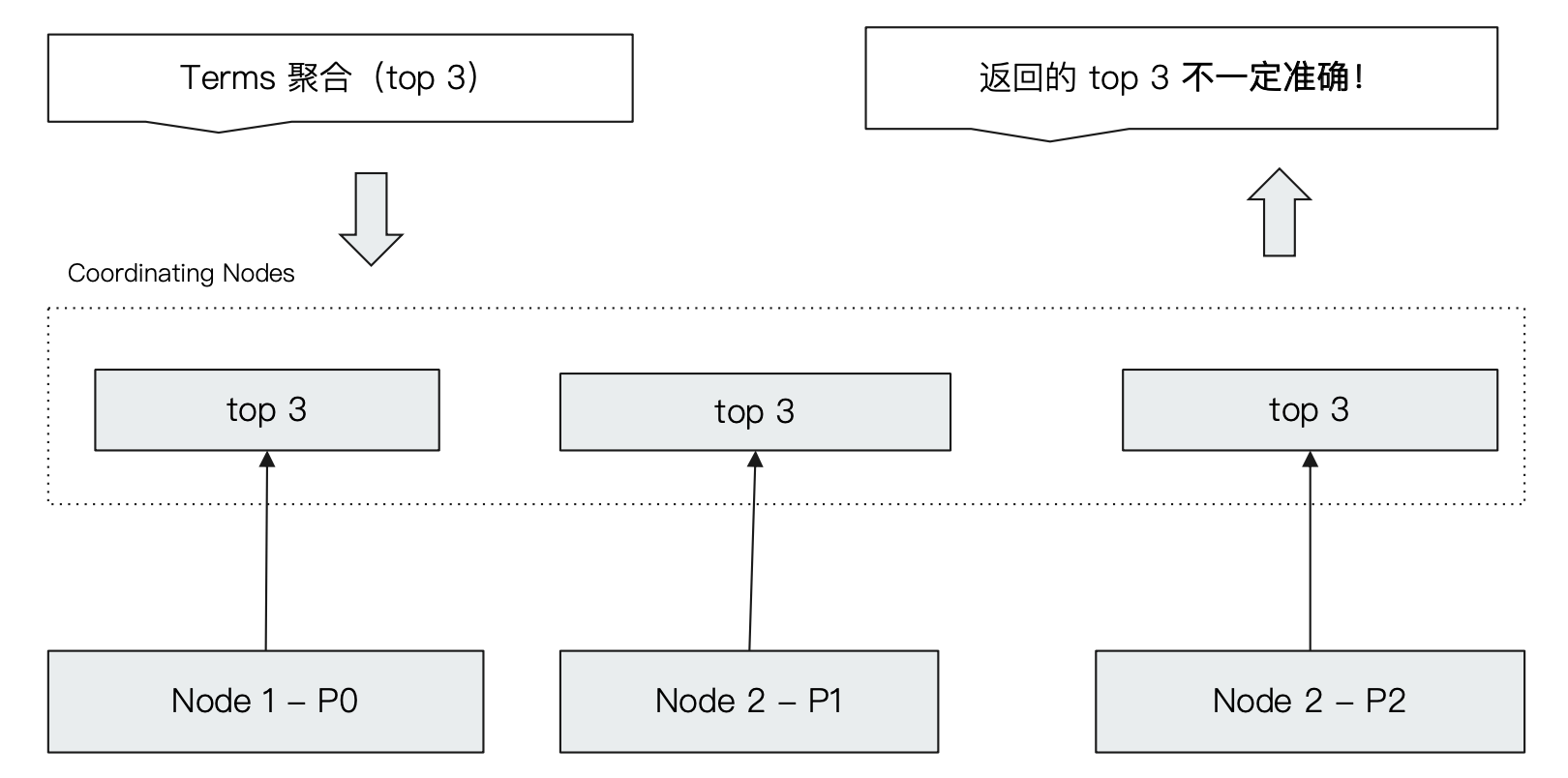
¶Terms 聚合分析的执行流程(可能不准)
我们从 terms aggregation 的两个参数入手分析其执行流程:
-
doc_count_error_upper_cound:指的是在对各分片进行 buckets agg 的时候各个分片中没有返回的桶(例如用户请求返回前 N 个桶,此时 coordinating 节点向所有数据分片发出返回前 N 个桶的请求,此时指的就是按照顺序的第 N+1个桶中的可能的最大的文档数)中 doc_count 的可能最大值的总和。
这个属性在agg 的返回信息中有一个对所有桶的总值,另外在每个桶下面还有一个对于该桶计算的值。 桶的 doc_count_error_upper_bound 属性默认没有计算和返回,通过设置 terms agg 对象的
show_term_doc_count_error:true属性启用。这个属性反应了可能当前桶内少算的文档数量的最大值。我们可以通过观察和调低这个值来让 terms agg 更加准确。
-
sum_other_doc_count:指的是实际的文档总数与返回的分桶数中的文档总数的差值。
我们通过下面的详细例子来了解这两个参数的含义:

我们来看下面 terms 聚合的一个流程:
当一个 coordinating node 接收到一个 terms agg 操作的请求,该请求还通过指定了一个 _size 字段要求返回前3个分桶。
前面提到 ES 的 agg 默认情况下 bucket 是按照 doc_count 进行降序排序的。所以理论上应该返回前三个文档数最多的分桶。
ES 发现需要进行分桶的数据分布在三个分片上面,就会分别发送请求到这三个分片上面分别求出在该 data node 上的前三个分桶,然后在 coordinating node 进行汇总并返回。
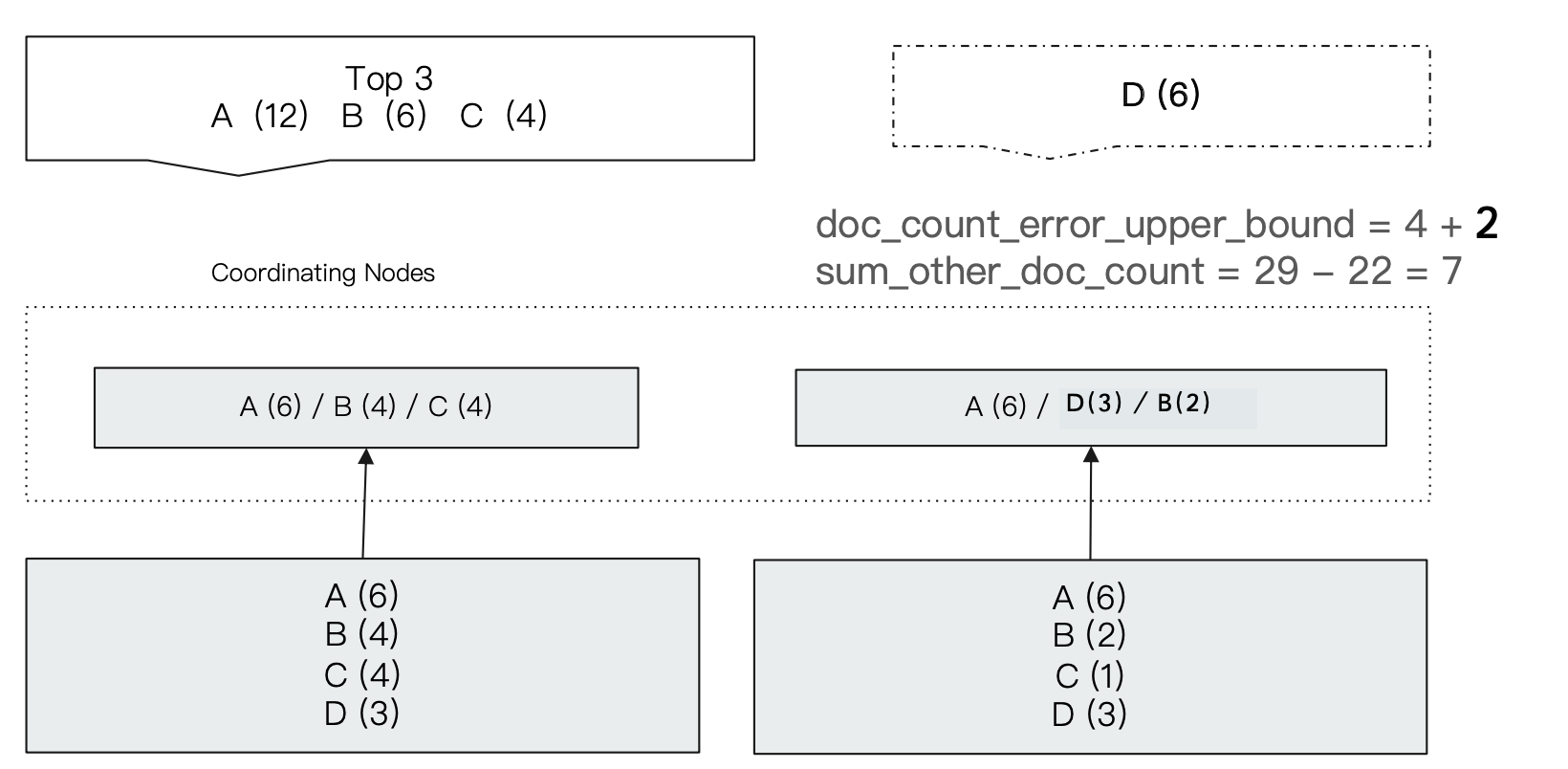
我们以下面例子来分析 term agg 可能会出现不准确的情况:
coordinating 收到一个求前三个桶的请求,发现数据分布在两个数据节点上,然后发送求前三个桶的请求到这两个分片上:
- 分片1对数据进行分组之后有 A、B、C、D 4个桶,桶内数据分别是6、4、4、3,所以分片1会返回 A、B、C 3个桶;
- 分片2对数据进行分组之后刚好也有A、B、C、D 3个桶,桶内数据分别是 6、2、1、3,所以分片2会返回 A、B、D3个桶。
此时 coordinating 收到两个分片的返回数据之后会对返回数据进行汇总。得到 A(6+6=12)、B(4+2=6)、C(4+0=3>D(0+3=3)) 三个桶作为前三个桶进行返回。但是我们发现其实 D分组中的文档总数其实是6,是比 C 要大的,但是因为在分片1中的排序之后的第3个桶的文档数已经比 D 要大,而分片1收到的请求是返回前3个桶,所以 D 并没有被返回,导致其在分片1中的文档数"丢失"了。
我们看到,此时:
-
总的doc_count_error_upper_bound 的数量就是分片1返回的最后一个桶的文档数4(ES 找到第3个桶就返回了,并不会再去看第4个桶的文档数是多少,所以这里指的是第4个桶的可能最大文档数,按照降序不可能超过桶 C 的文档数4,所以是4) 加上分片2返回的最后一个桶的文档数2等于6。
而桶 A 的doc_count_error_upper_bound就是0(两个分片都返回了桶 A和它的文档数)、桶 B 也是0、桶 C 是2(分片2没有返回桶 C ,而返回的桶中最小的桶 B 的数量是2,所以没有返回的桶最大文档数按照降序只能是2)、桶 D 是4(分片1没有返回桶 D,返回的最少分文档数的桶文档数是4)。
-
而 sum_other_doc_count 的数量就是两份片文档数之和17+12减去返回的总文档数12+6+4得到7。
¶解决 Terms agg 不准的问题
Terms 聚合分析不准的根本原因是数据分散在多个分片上,负责最终汇总的 coordinating node 无法获取数据全貌。所以有以下两个角度对这个问题进行解决:
-
当数据量不大的时候,设置 Primary Shard 为1,实现准确性。
-
通过调整 terms agg 对象的一个属性"shard_size"字段参数,提高精准度:
shard_size 字段的意义就是设定在进行 terms agg 的时候从各个分片上返回的桶的数量,在上面的例子中 shard_size 就是3,我们通过设置为4,就可以解决这个问题。
但是虽然调高了 shard_size,降低了 doc_count_error_upper_bound 数值,但是带来的就是整体计算量的增加,提高了准确度,但是也会导致计算时间变长。
所以调整准确率可以通过这样来实现:在进行 terms agg 的时候打开
show_term_doc_count_error来计算各个桶的 doc_count_error_upper_bound 并返回,通过不断调高 shard_size 来降低各个doc_count_error_upper_bound值为0。此时coordinating 获得的各个分片返回的桶就是准确的,汇总并返回给我们的就是准确的数据。默认的情况下,shard_size = size(要求返回的桶的数量) * 1.5 + 10。
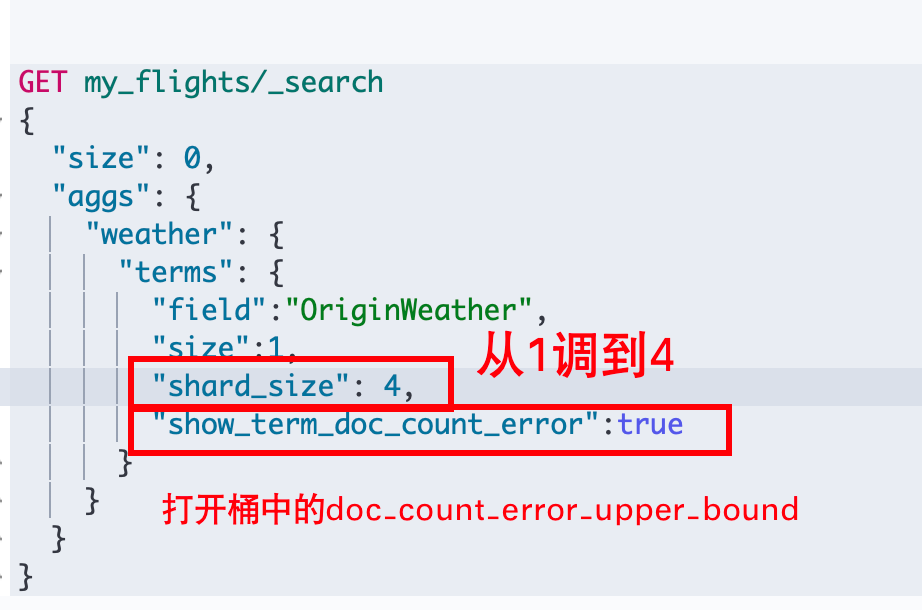
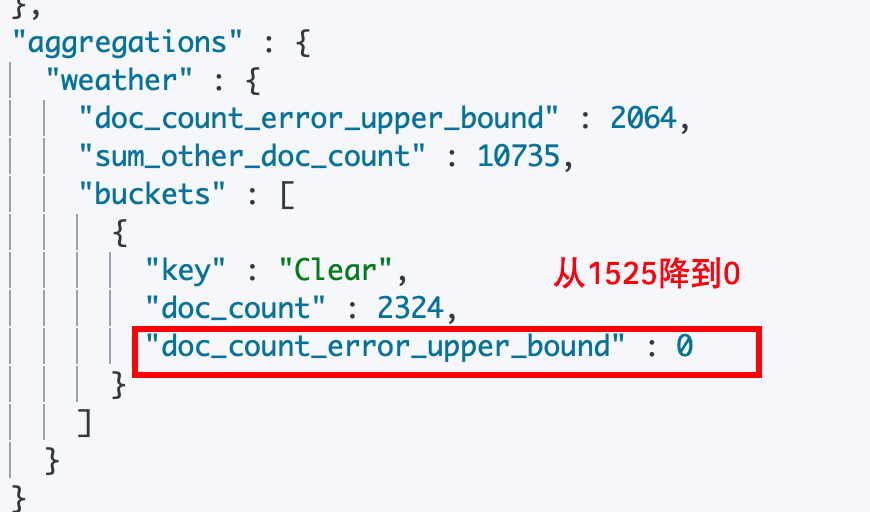
为什么当各个桶中的 doc_count_error_upper_bound 都是0的时候,计算返回的桶就是完全准确的呢?计算返回的桶完全准确的意思是,coordinating node 收到的所有分片返回的桶中包含了实际上应该准确返回给用户的前 N 个桶。我们用反证法来推导:
- 前提:各个桶中的 doc_count_error_upper_bound 都是0
- 只有一个分片中包含了一个实际上排在前 N 的桶 Z,但是没有返回到 coordiinating node,导致计算不准:如果存在这种情况,那么 doc_count_error_upper_bound 就不可能都是0。因为其他分片返回了桶Z,就会将没有返回桶Z的分片返回的最少文档数量的桶的文档数作为 桶 Z 的 doc_count_error_upper_bound。
- 部分分片包含了某些实际上排在前 N 的桶 Z 但是没有返回到 coordinating node:证明同上。
- 所有分片都没有返回一个实际上排在前 N 的桶 Z:回到我们的大前提,各个桶中的 doc_count_error_upper_bound 都是0,说明所有的分片返回的桶都是一样的,不可能存在这个分片返回的某个桶在那个分片中没有的情况,这点前两条证明已经回答。那么为什么桶 Z 没有返回呢,因为它在所有分片中都排在返回的这些桶的后面。所以即使将基于我们设置了 shard_size 之后各个分片返回的各个桶的文档数汇总起来,也都会超过从各个分片中汇总的桶 Z 的总数。
- 前提:各个桶中的 doc_count_error_upper_bound 都是0
¶Kibana 测试请求
DELETE my_flights
PUT my_flights
{
"settings": {
"number_of_shards": 20
},
"mappings" : {
"properties" : {
"AvgTicketPrice" : {
"type" : "float"
},
"Cancelled" : {
"type" : "boolean"
},
"Carrier" : {
"type" : "keyword"
},
"Dest" : {
"type" : "keyword"
},
"DestAirportID" : {
"type" : "keyword"
},
"DestCityName" : {
"type" : "keyword"
},
"DestCountry" : {
"type" : "keyword"
},
"DestLocation" : {
"type" : "geo_point"
},
"DestRegion" : {
"type" : "keyword"
},
"DestWeather" : {
"type" : "keyword"
},
"DistanceKilometers" : {
"type" : "float"
},
"DistanceMiles" : {
"type" : "float"
},
"FlightDelay" : {
"type" : "boolean"
},
"FlightDelayMin" : {
"type" : "integer"
},
"FlightDelayType" : {
"type" : "keyword"
},
"FlightNum" : {
"type" : "keyword"
},
"FlightTimeHour" : {
"type" : "keyword"
},
"FlightTimeMin" : {
"type" : "float"
},
"Origin" : {
"type" : "keyword"
},
"OriginAirportID" : {
"type" : "keyword"
},
"OriginCityName" : {
"type" : "keyword"
},
"OriginCountry" : {
"type" : "keyword"
},
"OriginLocation" : {
"type" : "geo_point"
},
"OriginRegion" : {
"type" : "keyword"
},
"OriginWeather" : {
"type" : "keyword"
},
"dayOfWeek" : {
"type" : "integer"
},
"timestamp" : {
"type" : "date"
}
}
}
}
POST _reindex
{
"source": {
"index": "kibana_sample_data_flights"
},
"dest": {
"index": "my_flights"
}
}
GET kibana_sample_data_flights/_count
GET my_flights/_count
get kibana_sample_data_flights/_search
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"weather": {
"terms": {
"field":"OriginWeather",
"size":5,
"show_term_doc_count_error":true
}
}
}
}
GET my_flights/_search
{
"size": 0,
"aggs": {
"weather": {
"terms": {
"field":"OriginWeather",
"size":1,
"shard_size": 4,
"show_term_doc_count_error":true
}
}
}
}




