一、使用 Index Pattern 配置数据
在 Kibana 中,对于索引数据的操作基本都围绕着 Index Pattern 展开,下面我们来做个演示。
¶初始化数据
我们先初始化三个索引数据,因为这三个 index 里面都含有一个类型为地理位置类型的字段,所以需要手动设置,如果使用 dynamic mapping 会被识别为 text。
PUT /logstash-2015.05.18
{
"mappings": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
PUT /logstash-2015.05.19
{
"mappings": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
PUT /logstash-2015.05.20
{
"mappings": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
然后我们分别从本地请求导入一些测试文档数据到 ES
curl -H 'Content-Type: application/x-ndjson' -XPOST 'myecs.com:9200/_bulk?pretty' --data-binary @logs.json
curl -H 'Content-Type: application/x-ndjson' -XPOST 'myecs.com:9200/bank/account/_bulk?pretty' --data-binary @accounts.json
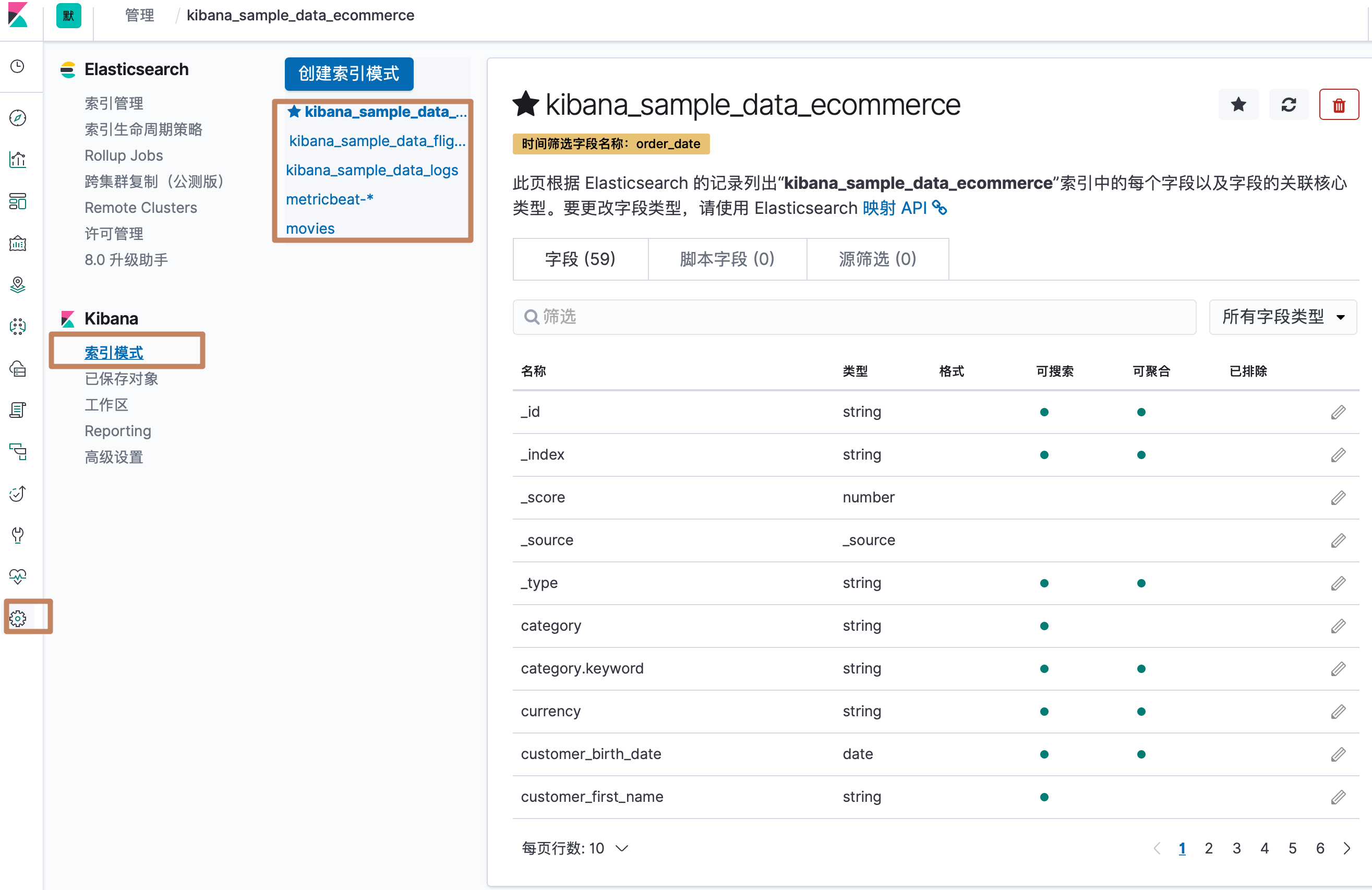
¶创建 index pattern
¶logs 数据的 index pattern
我们来到 Index Pattern 的界面,可以看到已经有一些 index pattern 已经创建好了。
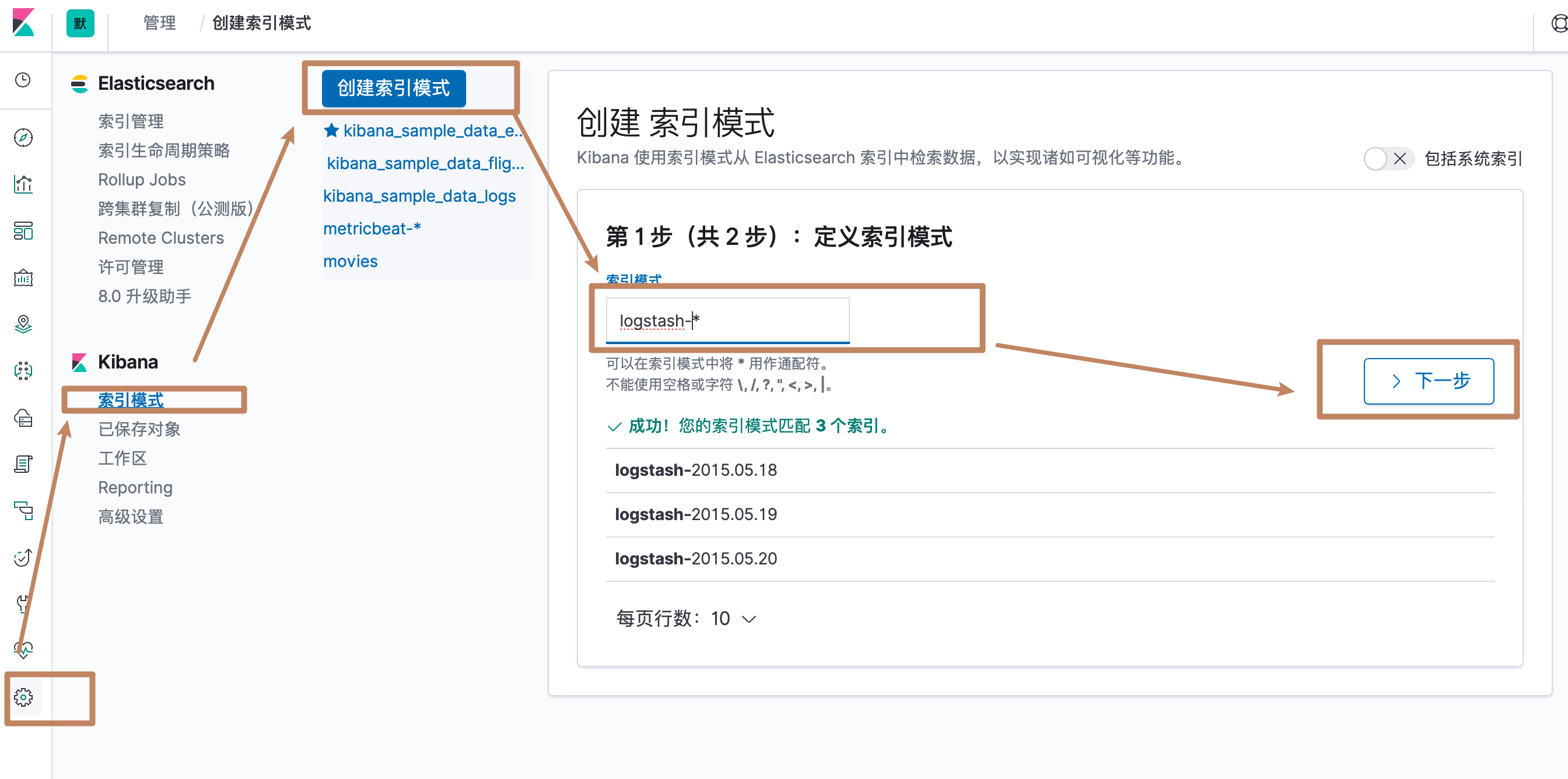
然后我们为我们刚刚创建的三个索引创建一个 Index pattern,我们通过一个通配符命名的方式将我们刚刚创建的三个索引都匹配到我们准备创建的 Index Pattern 中,点击 next
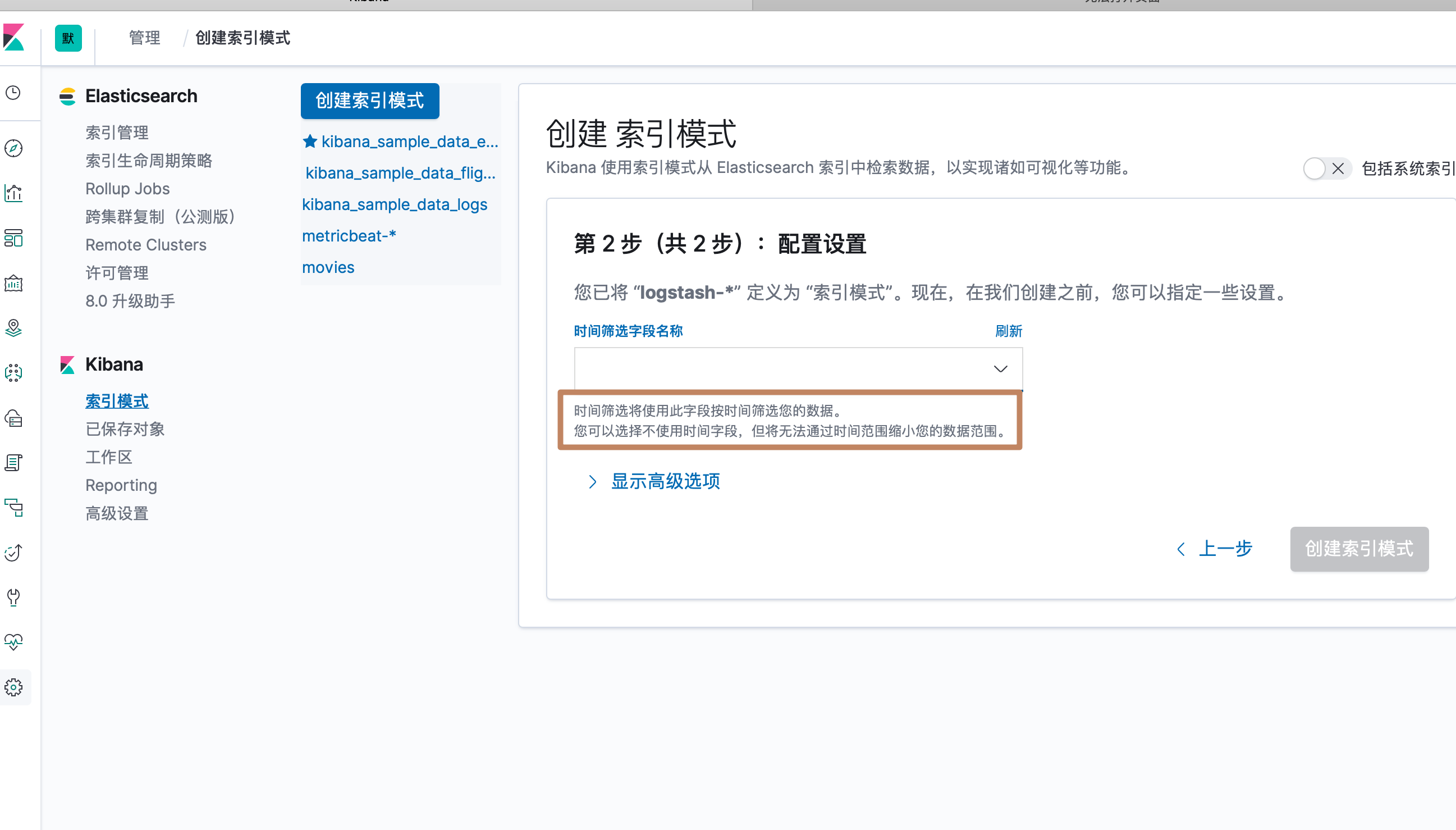
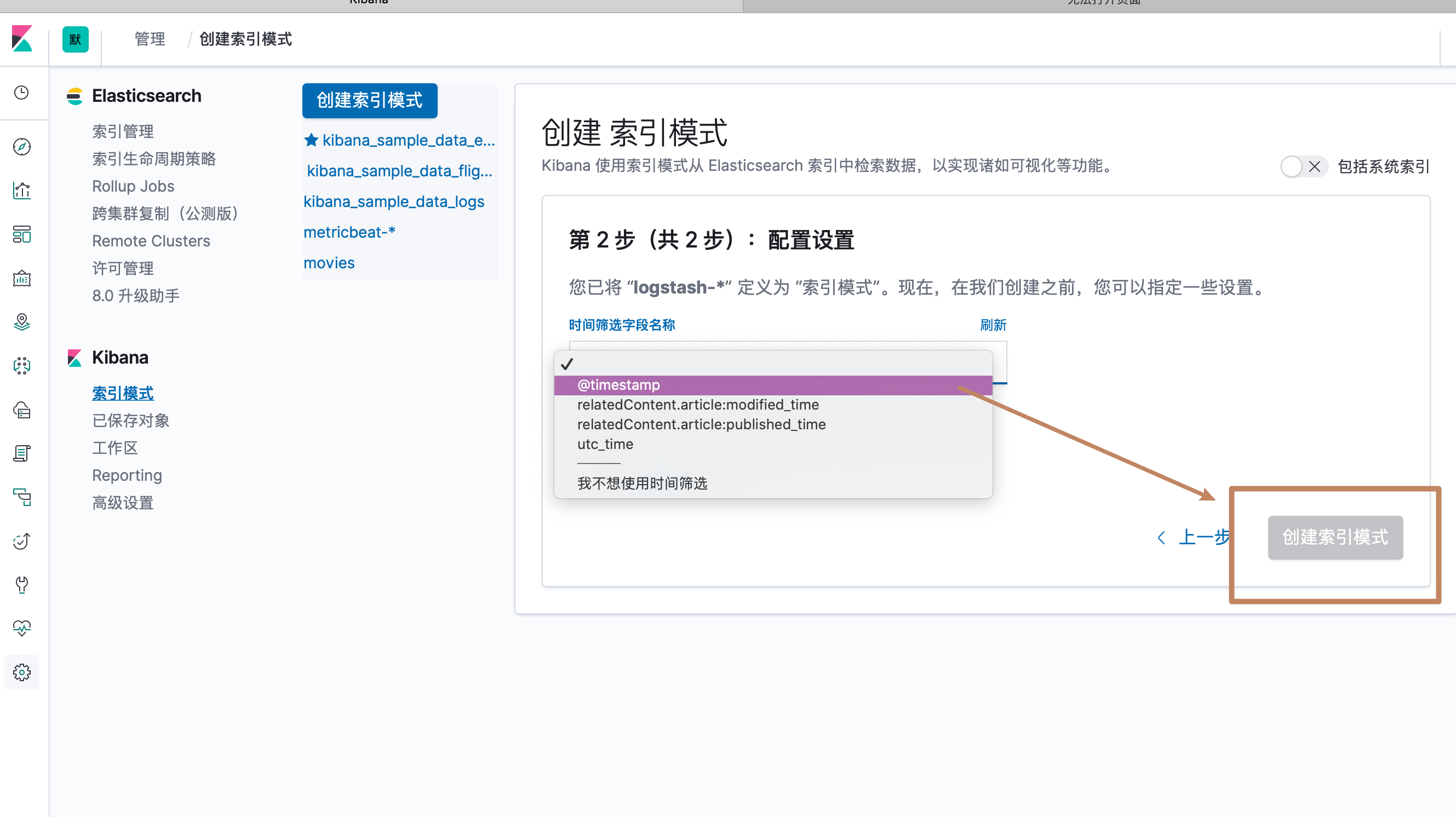
然后 ES 会要求我们选择一个字段作为数据的一个时间戳(因为我们的索引中定义了多个时间戳类型的字段,所以要指定一个,点击下拉框会下拉出所有时间戳字段,其中也有一个选项是不选用时间戳字段),然后点击 create
可以看到我们的 index pattern 就被创建出来了,下图是界面中一些按钮的介绍
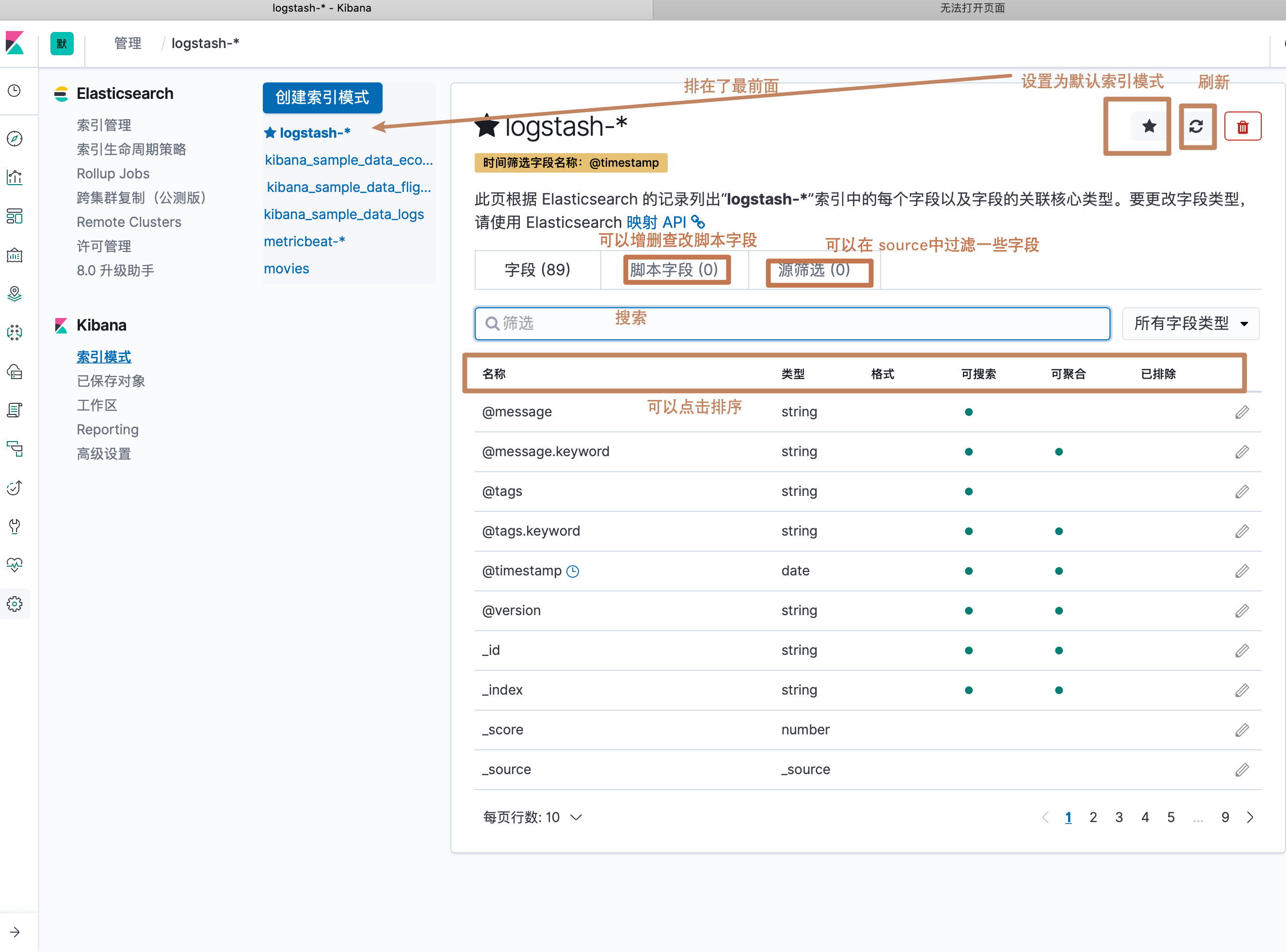
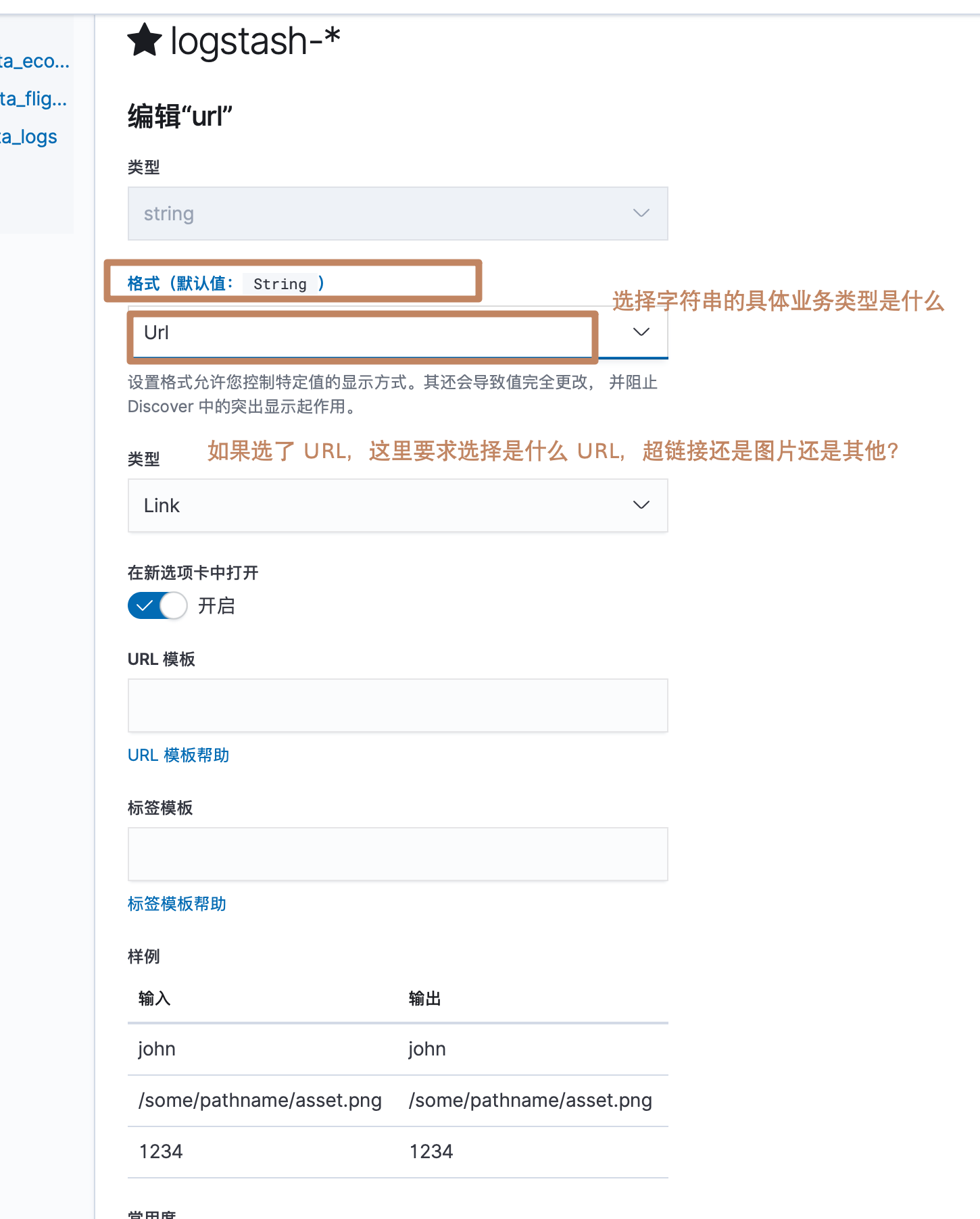
其中我们还看到一个"格式"一列,它定义了Kibana 会以什么样的格式来显示这个字段,点击编辑按钮可以对格式进行编辑。

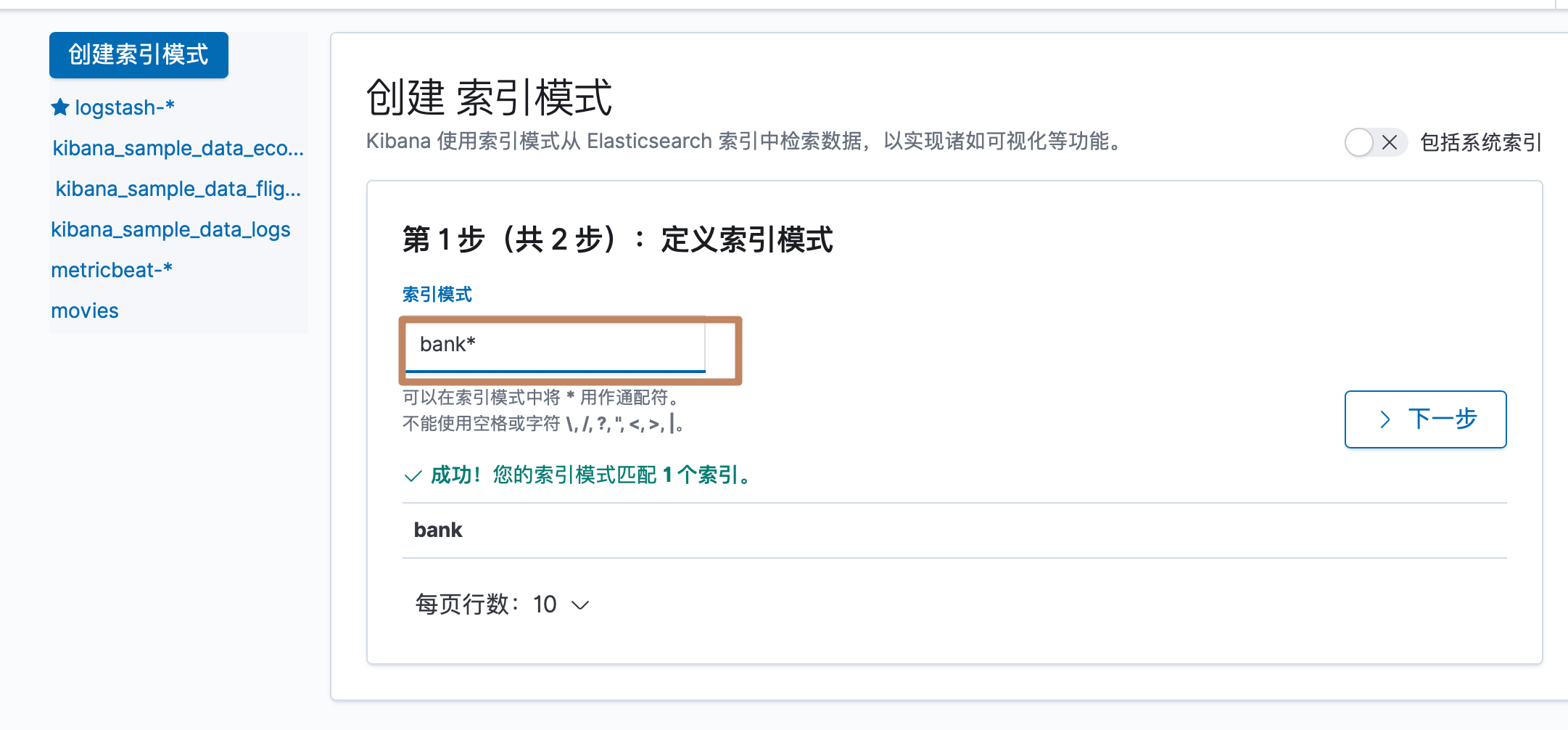
¶银行数据的 index pattern
然后我们再对导入的另外一个银行文档数据创建 index pattern
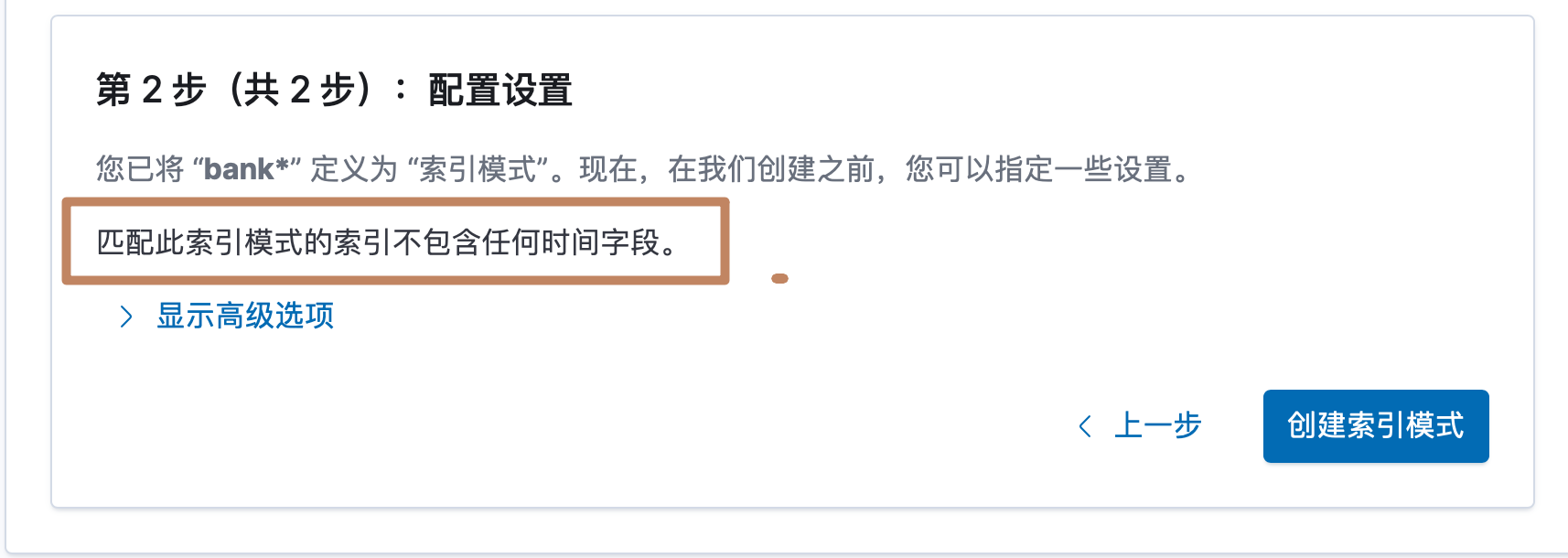
因为银行数据中不包含任何时间戳类型字段,所以Kibana 没有显示需要我们选择一个作为时间排序过滤数据的字段
二、使用 Kibana Discover 探索数据
首先我们选择左边面板的 discovery 按钮进入 discovery 的模块。然后选择我们前面创建的"logstash-*"的 index pattern,默认显示的是最近15分钟的数据,而这些数据都是很久之前的了,所以没有数据显示。
选择10年以前的数据
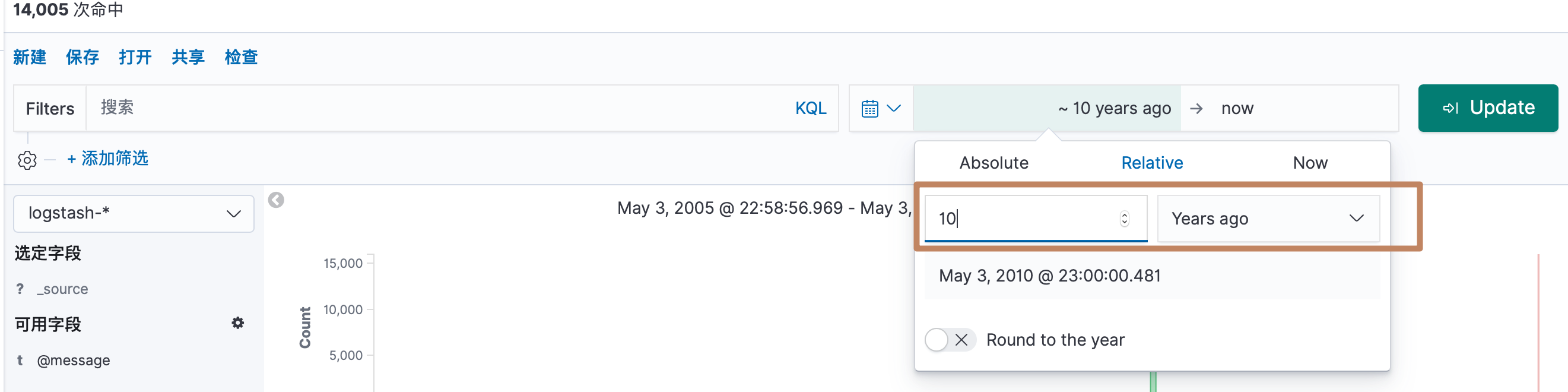
可以看到出来了一些数据,但是柱子区间太大
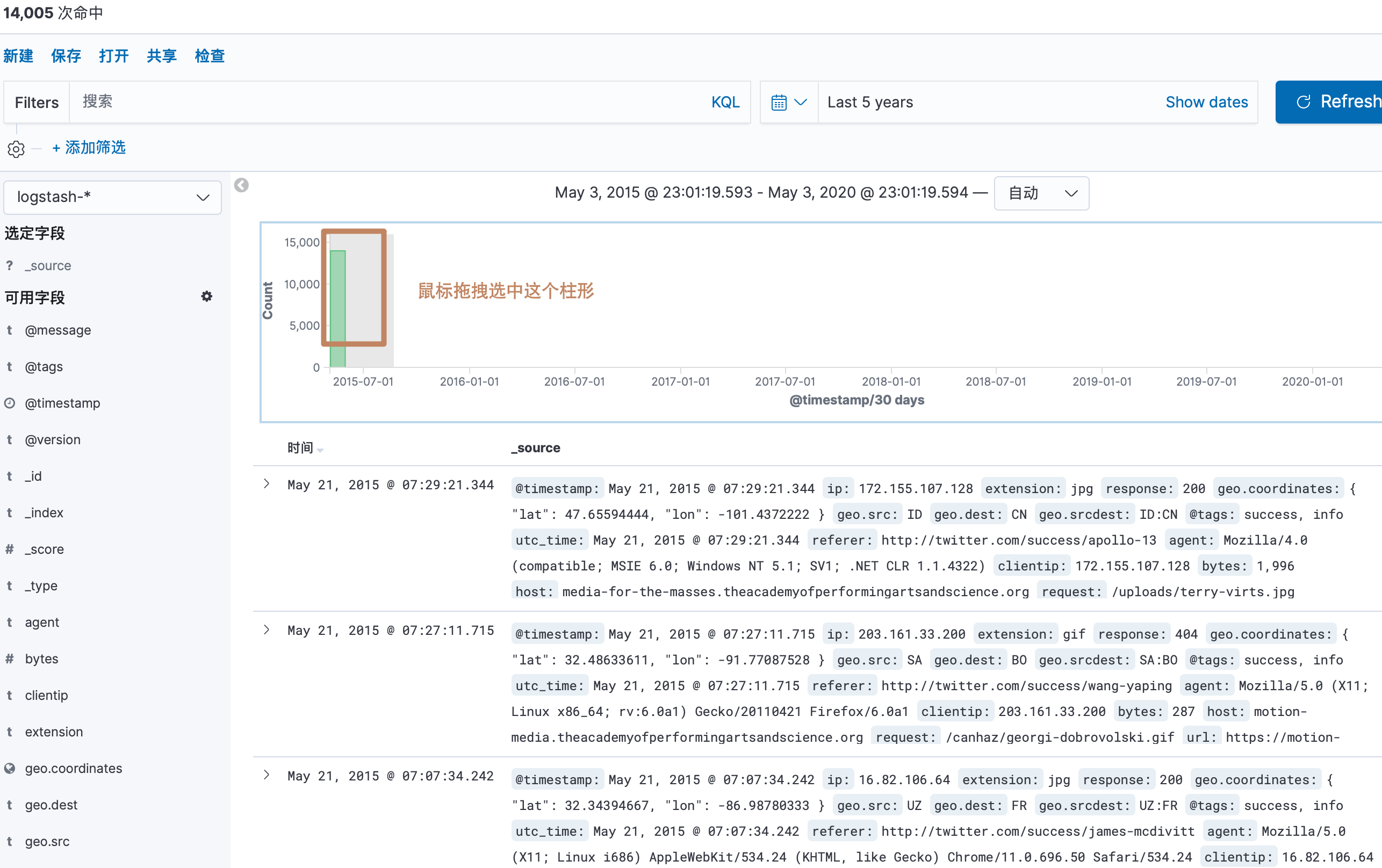
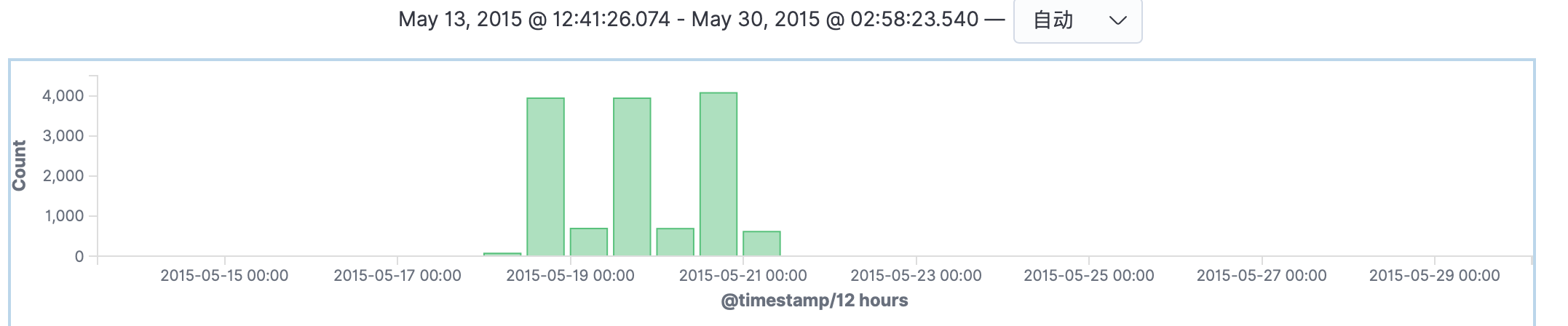
通过选中这个柱子对他放大,可以看到这些数据都是几种在2015-05-19到05-21这三天
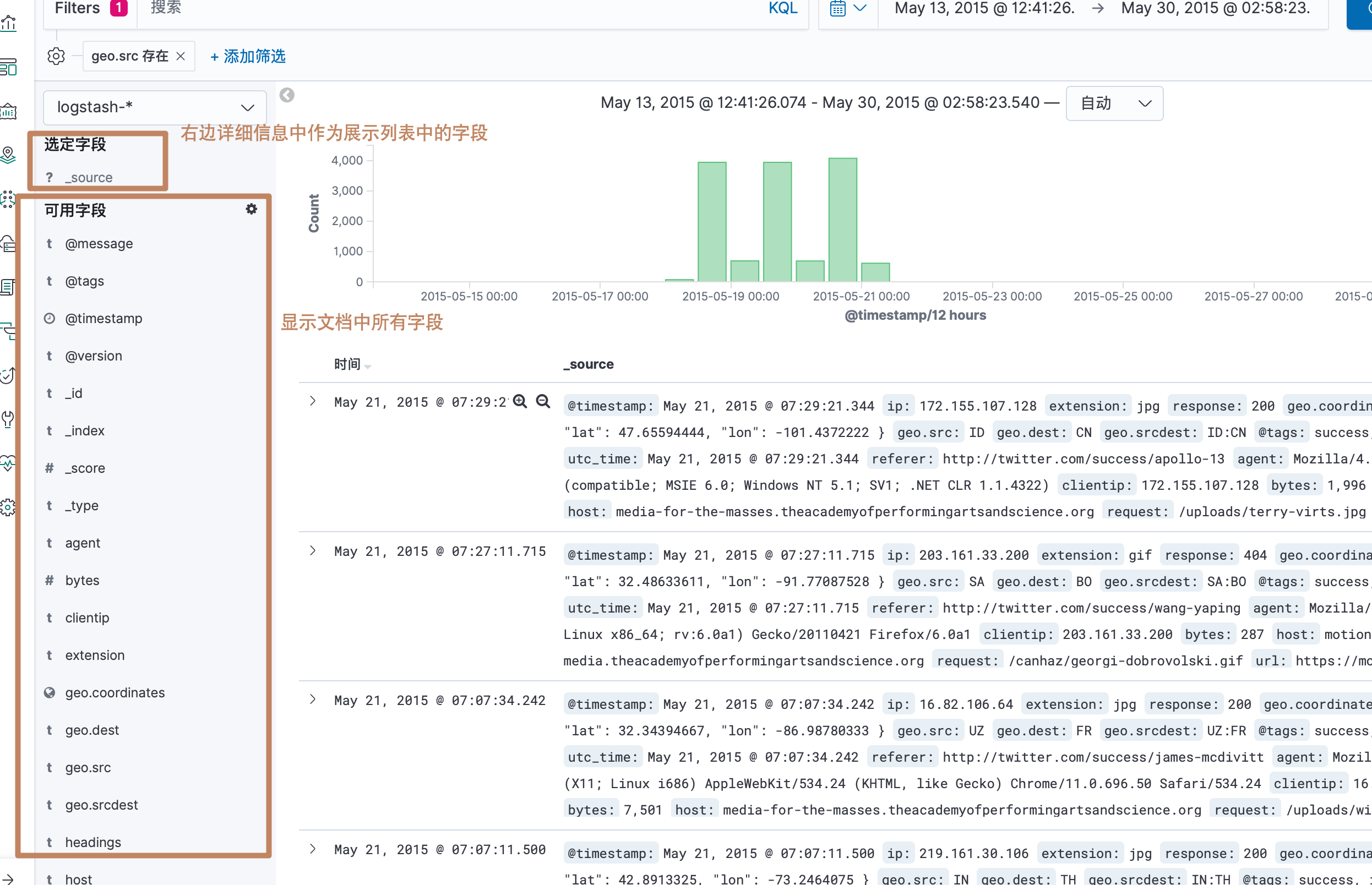
直方图下面显示的就是我们选中的直方图范围中的详细文档数据
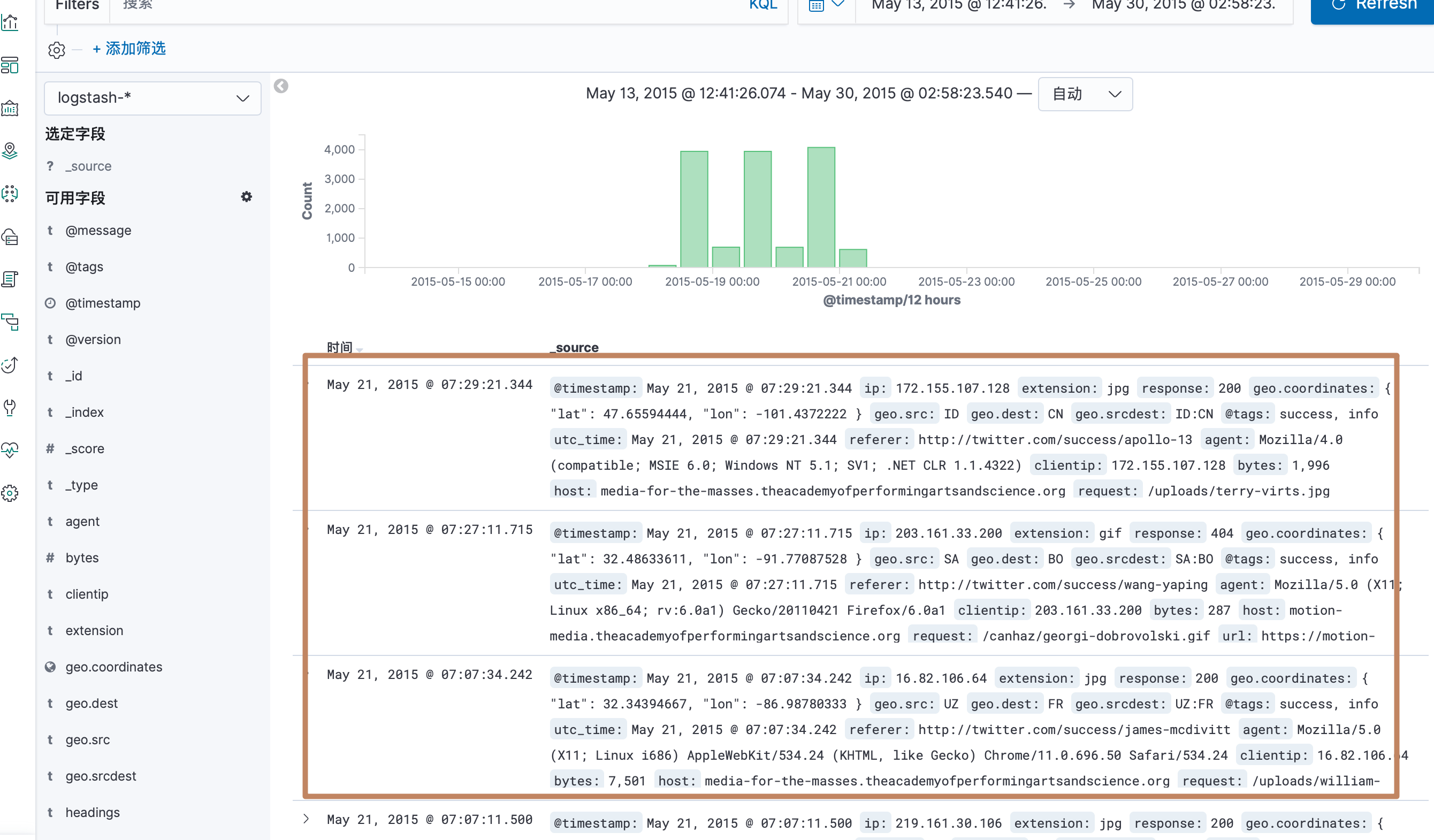
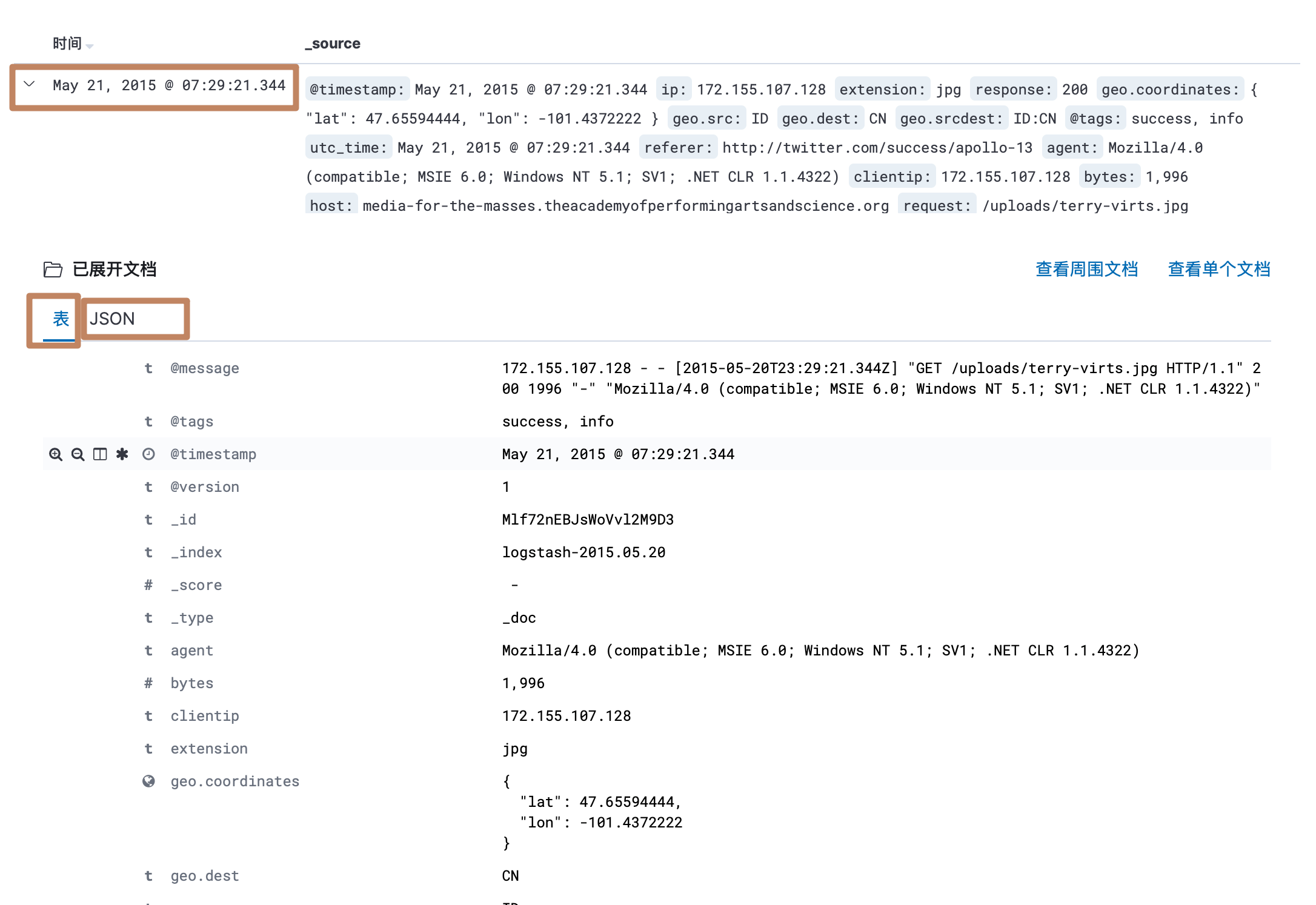
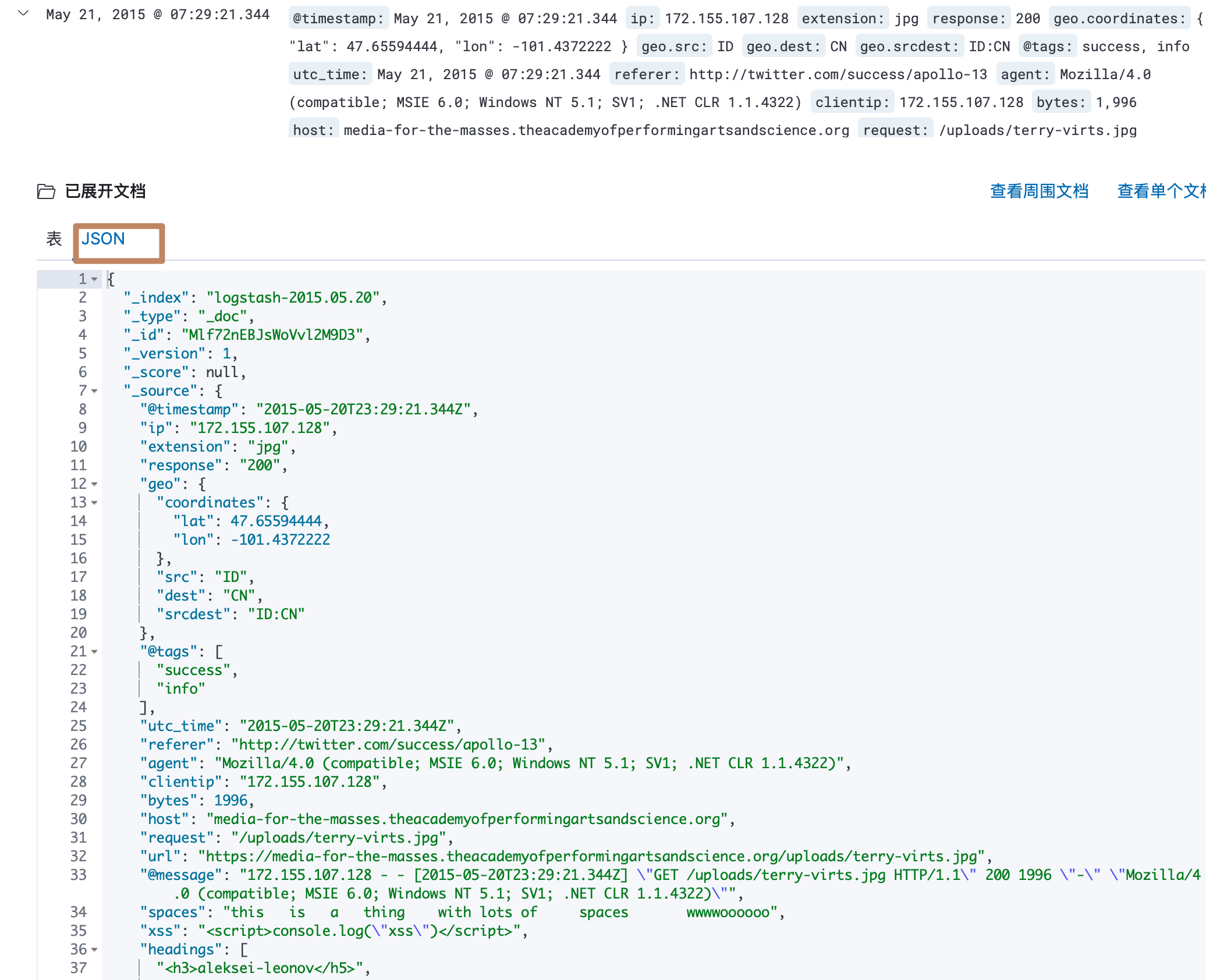
另外我们点开每一条文档数据就可以看到它的详细内容,其中它分为了表格的显示方式和 JSON 的显示方式
其中以表格形式显示的时候,每个字段前面都会有4个功能按钮
-
第一个按钮:将当前字段匹配当前值作为筛选条件,过滤出满足的数据

-
第二个按钮:将当前字段不匹配当前值作为筛选条件,过滤出满足的文档

-
第三个按钮:将当前字段作为显示列字段
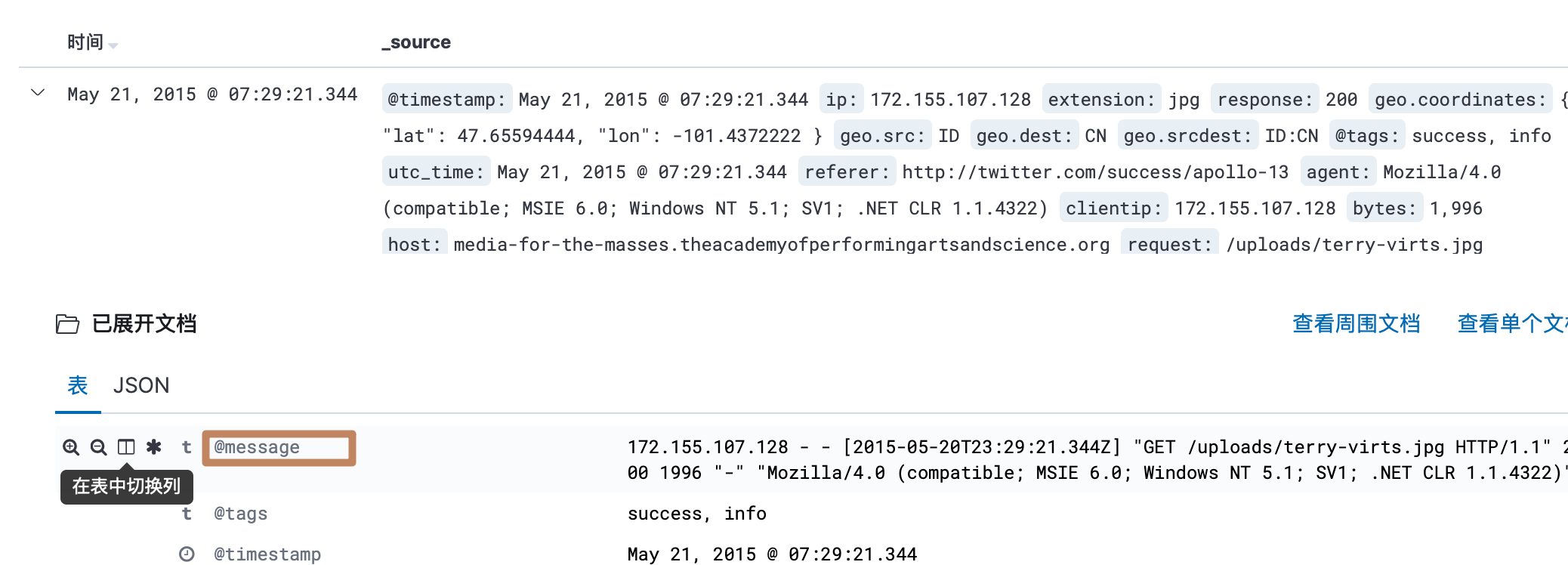
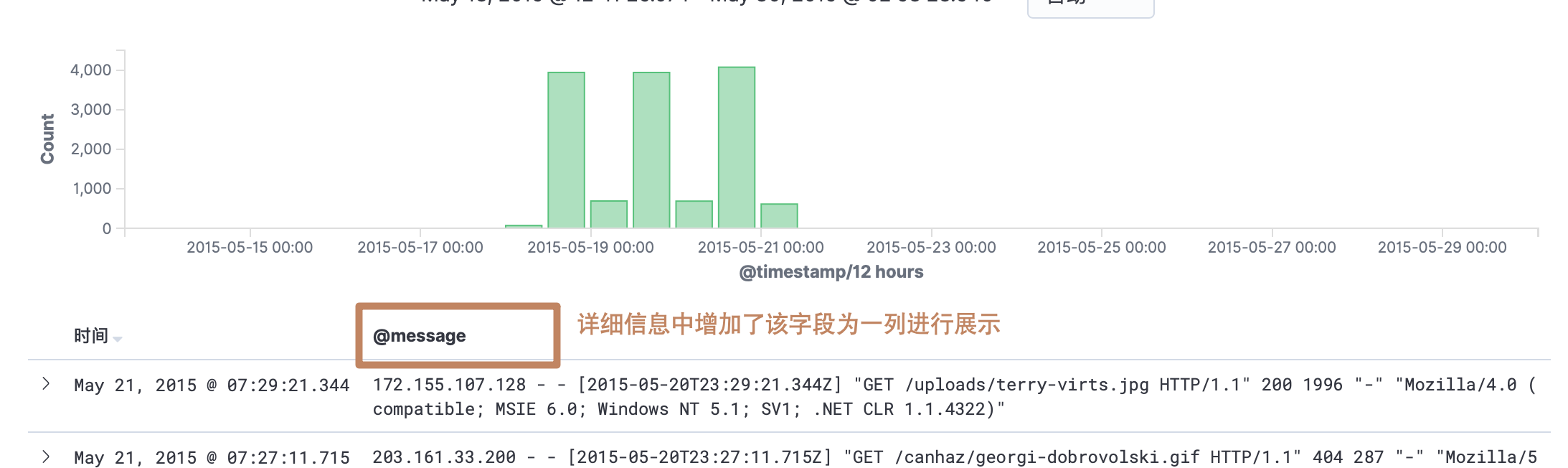
-
第四个按钮:过滤出当前字段必须有值的文档

另外我们可以直接添加一个 filter 进行文档数据的筛选
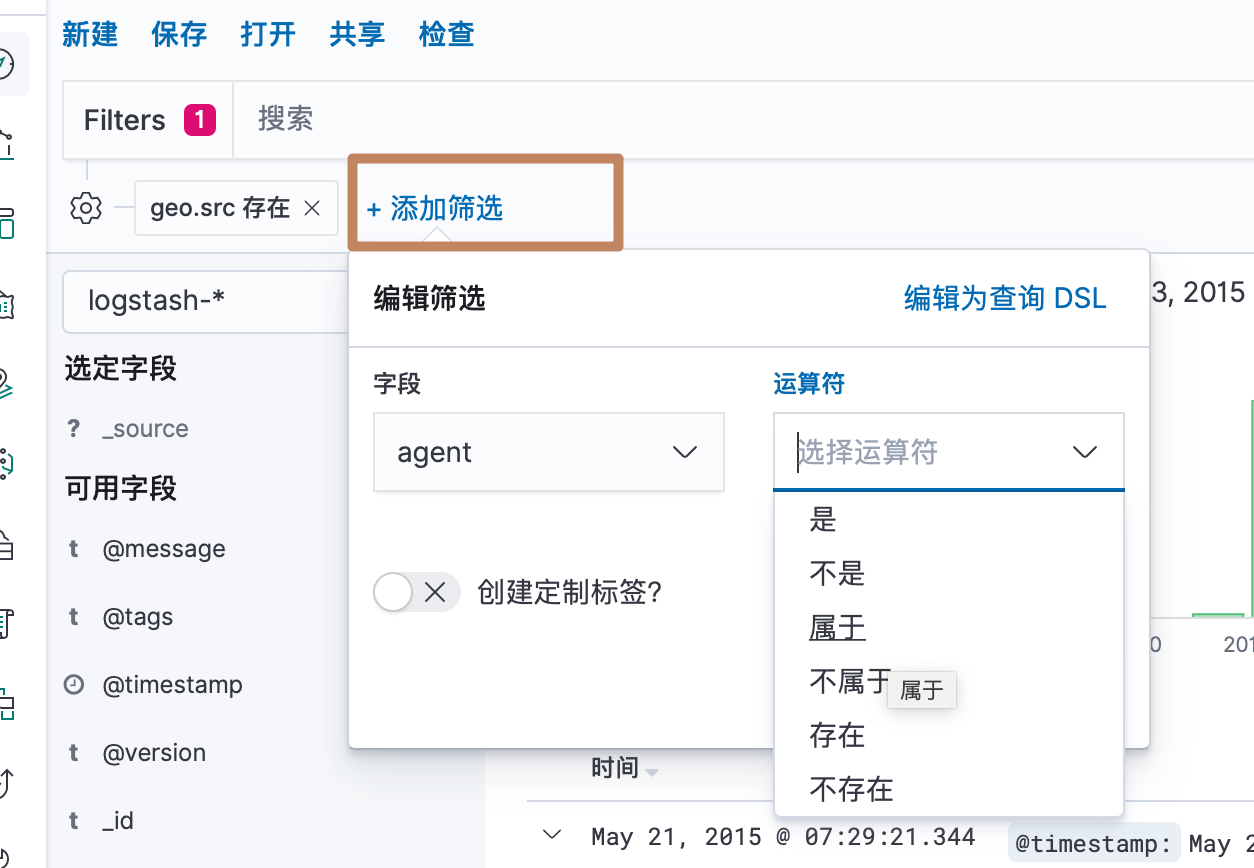
我们再来看一下左边的菜单栏
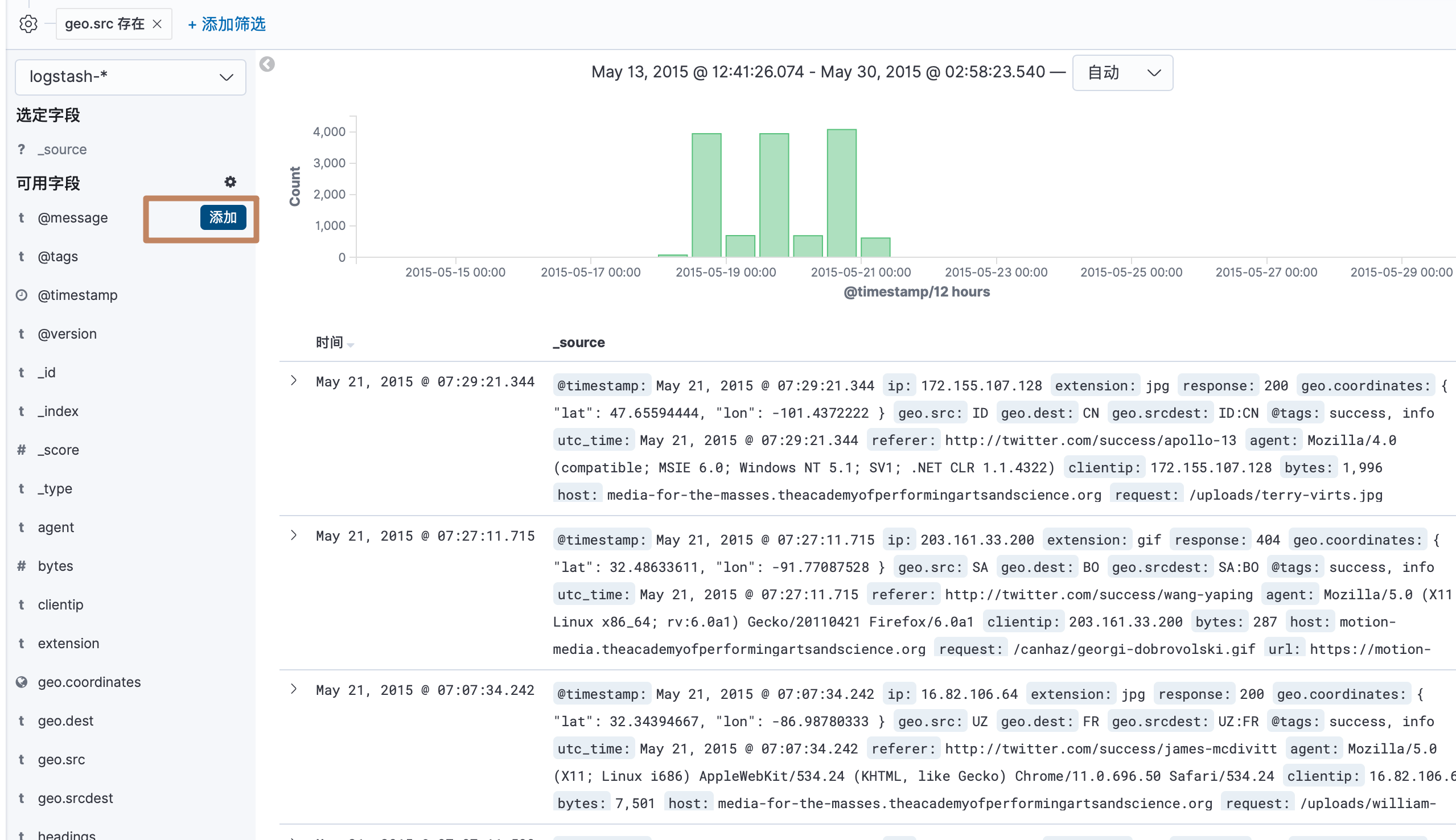
当我们鼠标悬浮到某个可用字段上会出现一个"添加"的按钮,点击添加也会将这个字段添加到展示列表的字段
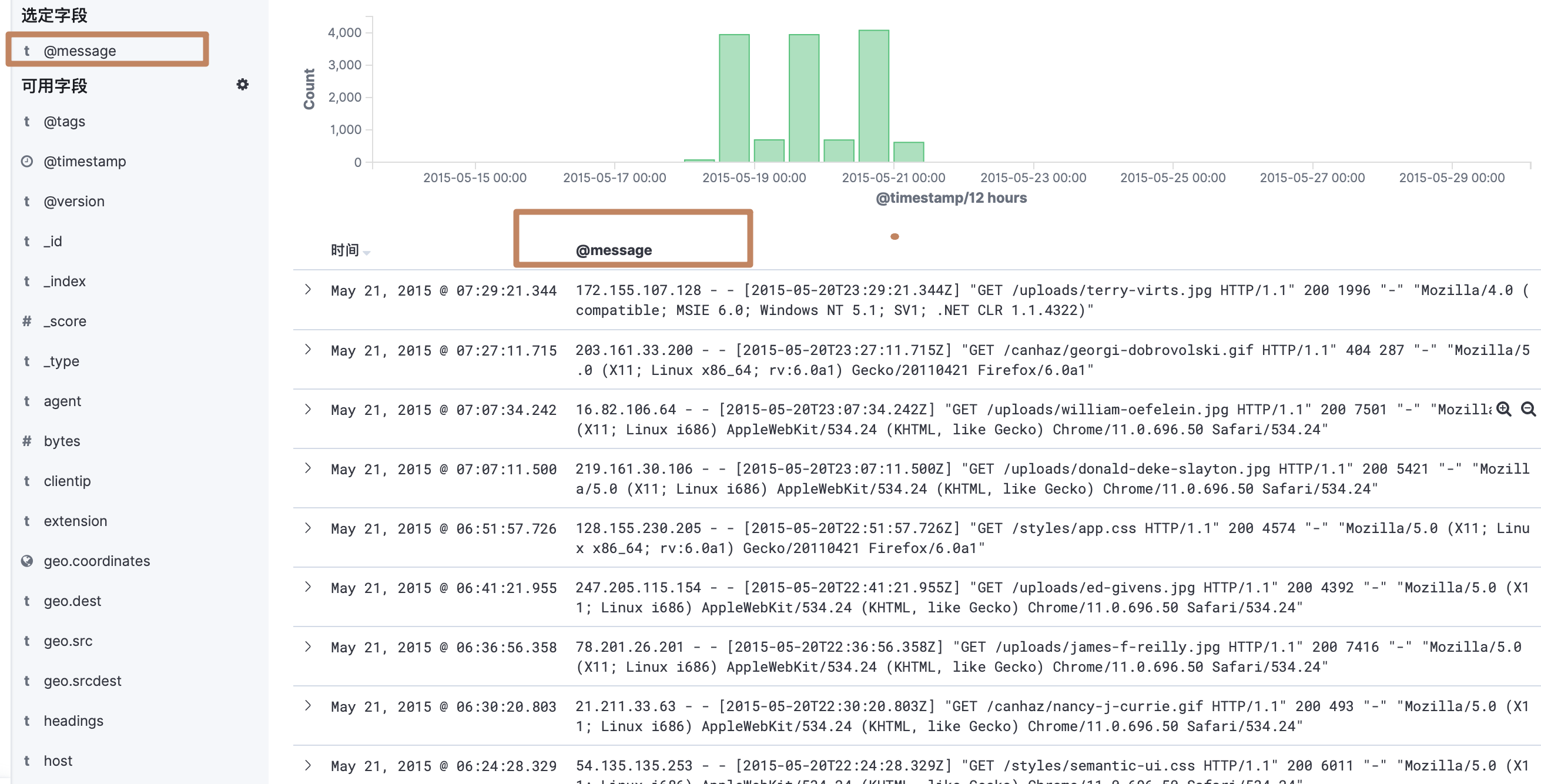
现在我们选择查看一个 memory 字段,发现显示的数值不是那么友好,这时候我们就可以使用前面介绍的 index pattern 中的字段的格式了
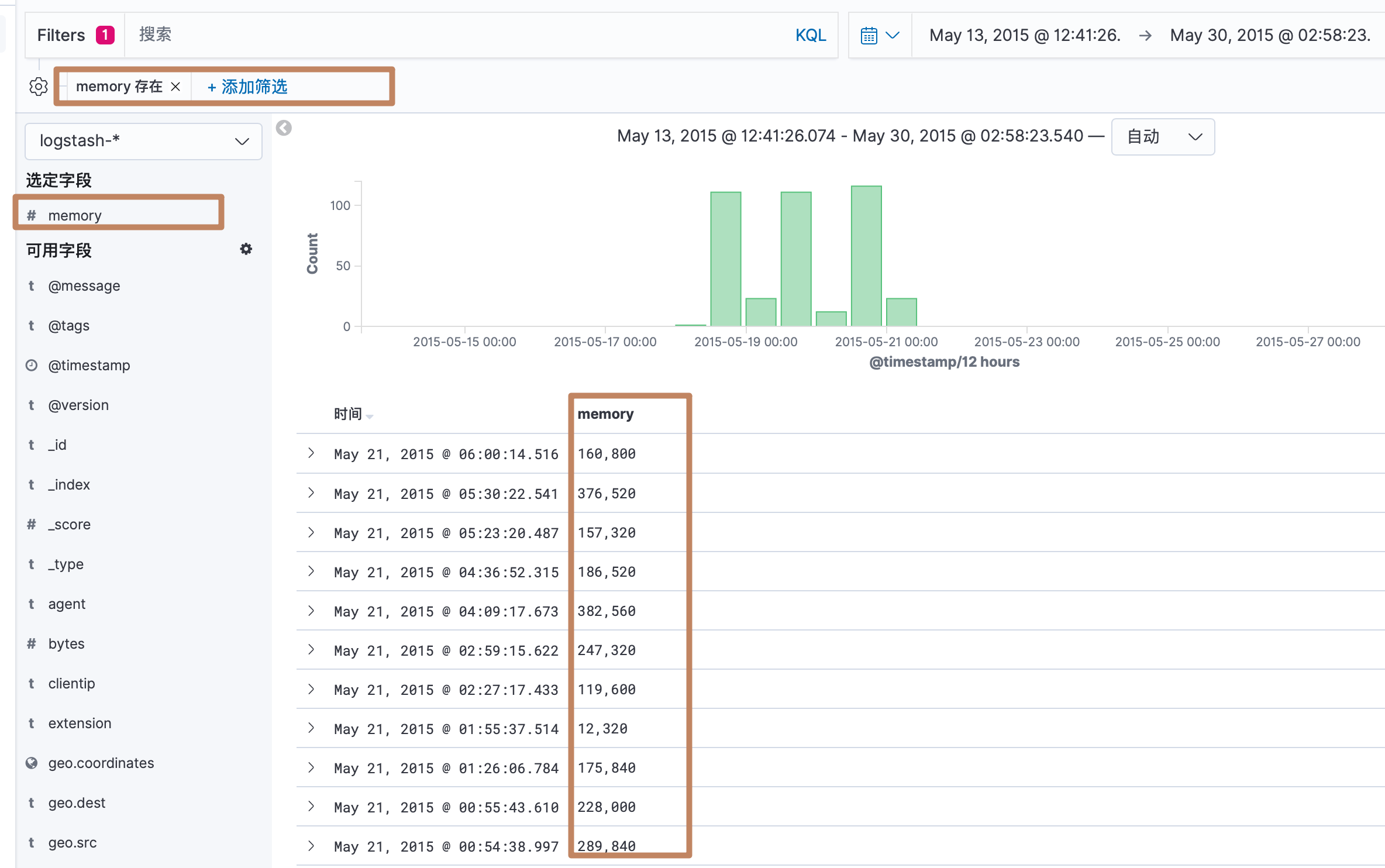
来到字段编辑页面,进行编辑
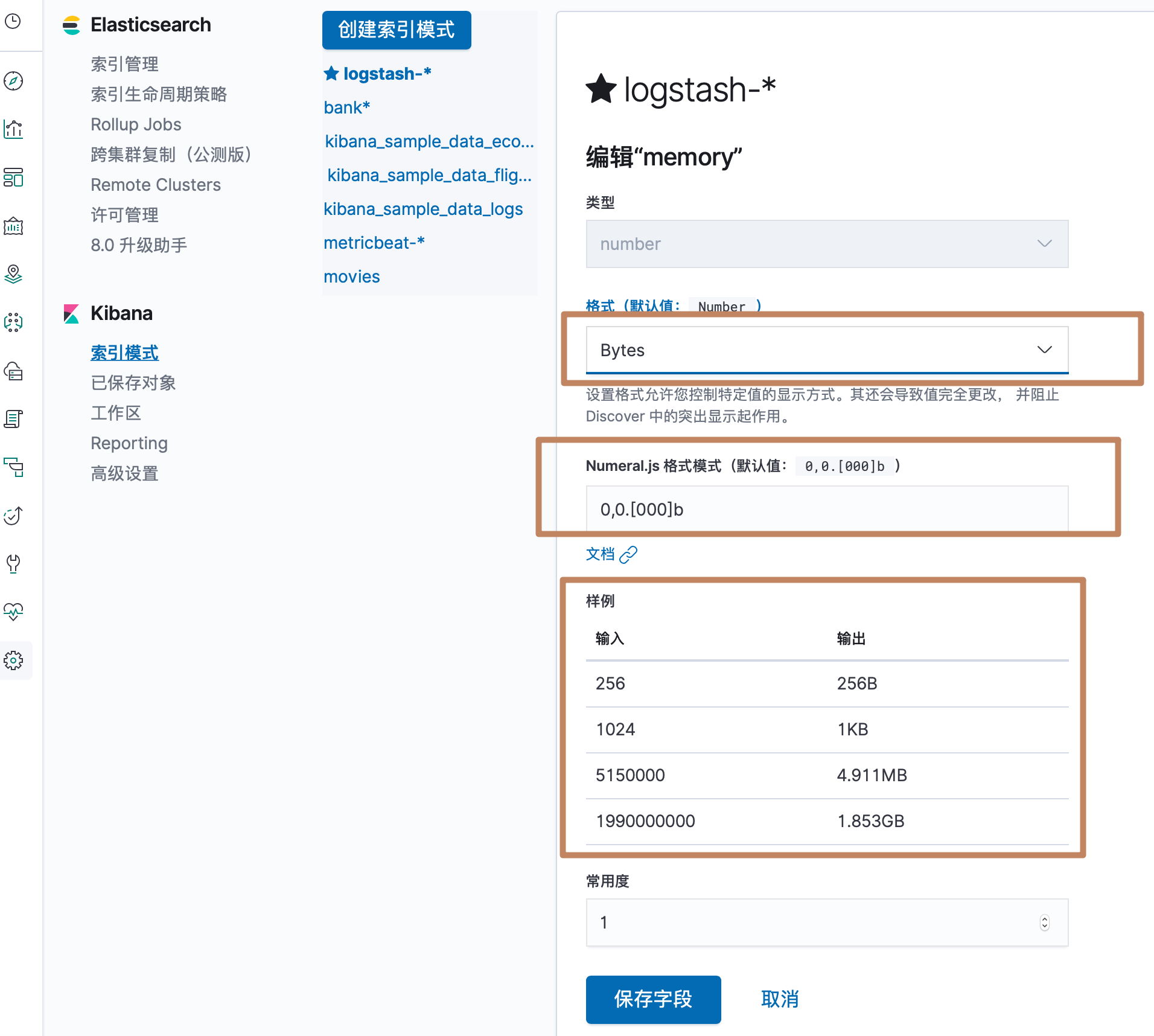
再回到 discovery 的界面,可以看到为我们显示了单位

另外我们还可以直接点击左边菜单栏的字段,就会显示这个字段的一些文档的聚合分析信息
三、基本可视化组件
可视化其实就是对一下数据的聚合分析形成一个直观可视的图表。
我们先点击面板左边的可视化。
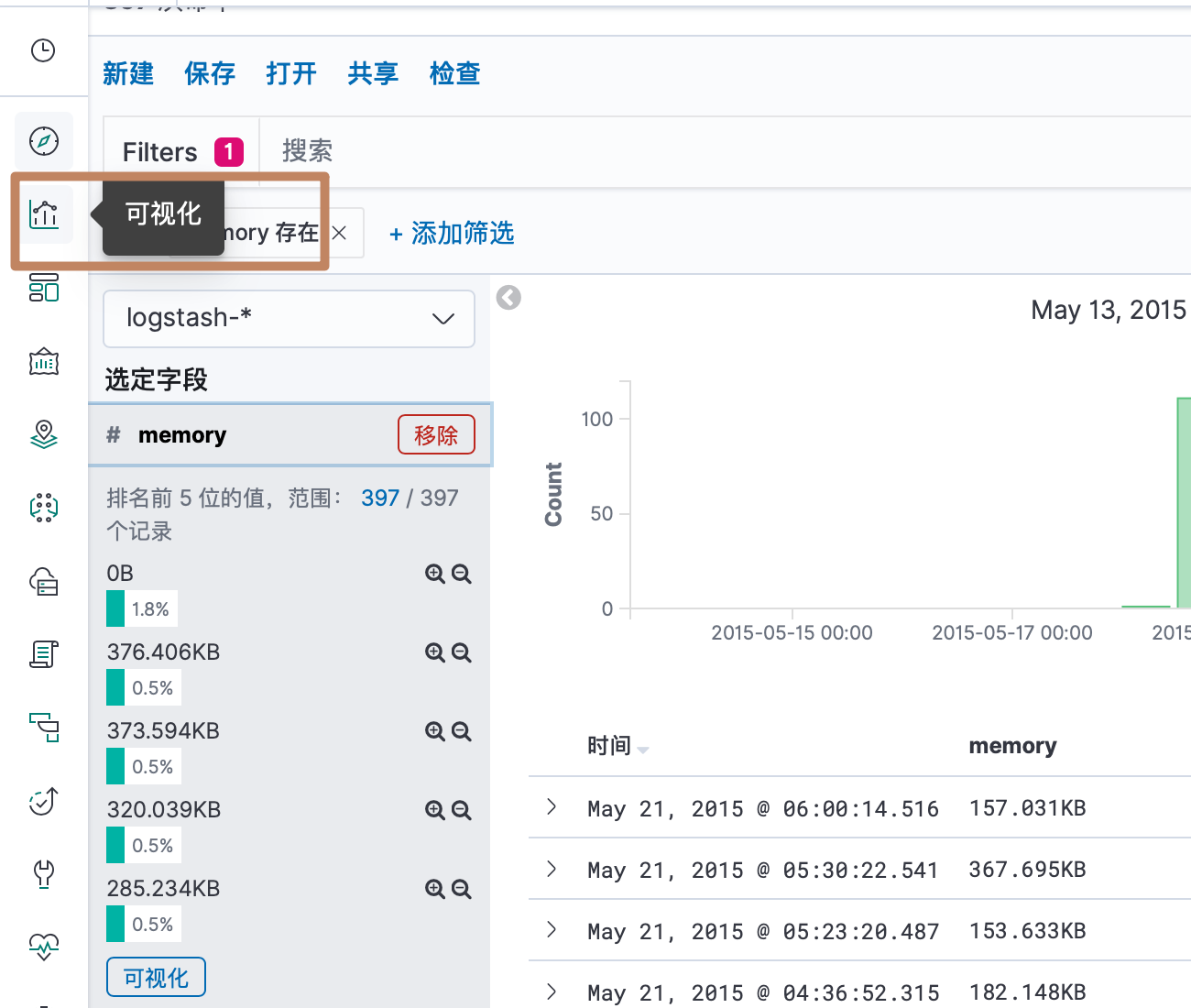
可以看到 kibana 中已经生成了一些可视化的图表,包括它自带的三个样例测试数据集以及我们之前导进去的 metricbeat 的 dashboard。
我们基于我们刚刚导入的两份数据来分别创建一些可视化图表,下面先来创建一个饼图:
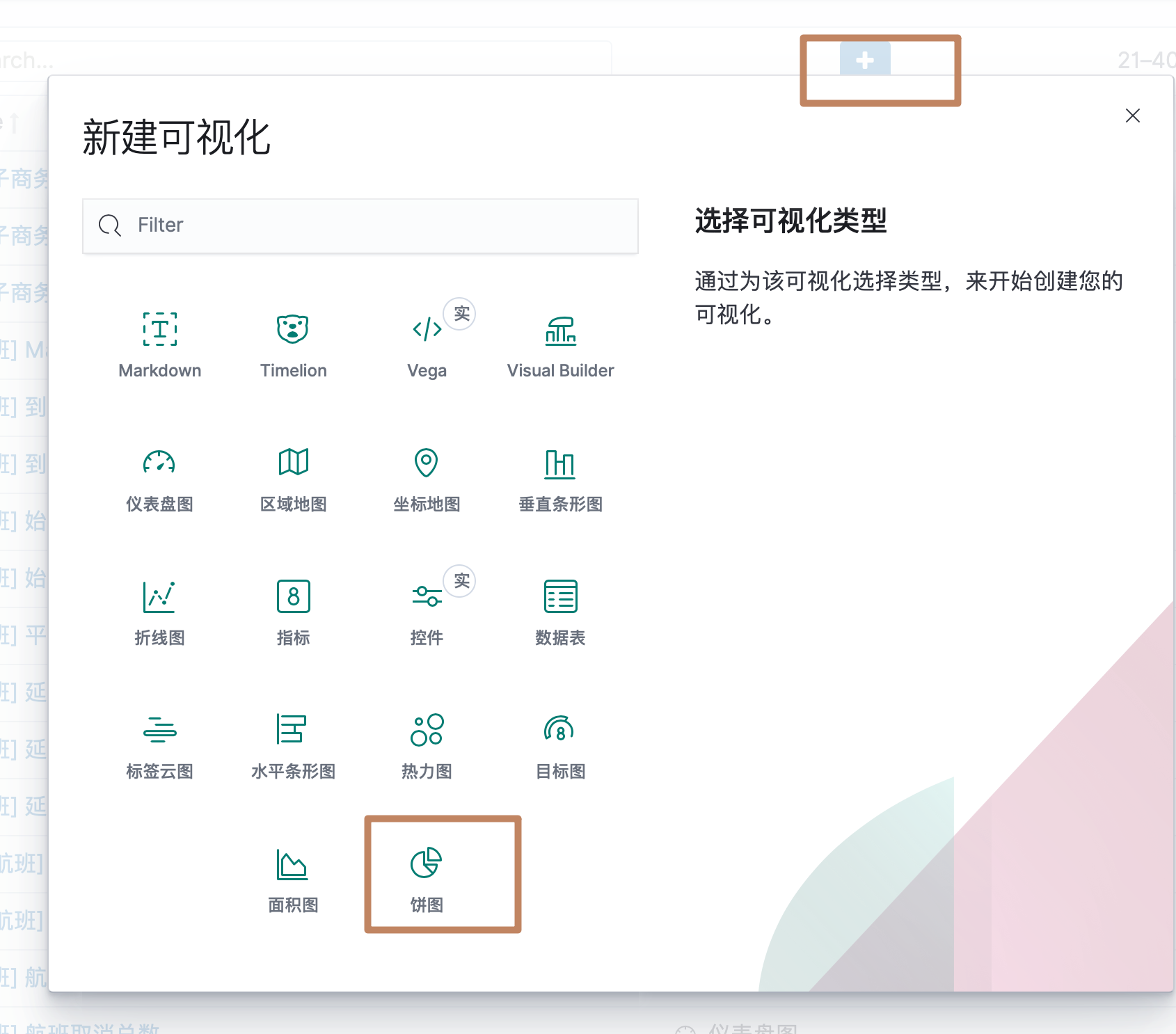
点击后会让我们选择 index pattern,我们搜索选择我们之前导入的"bank*":
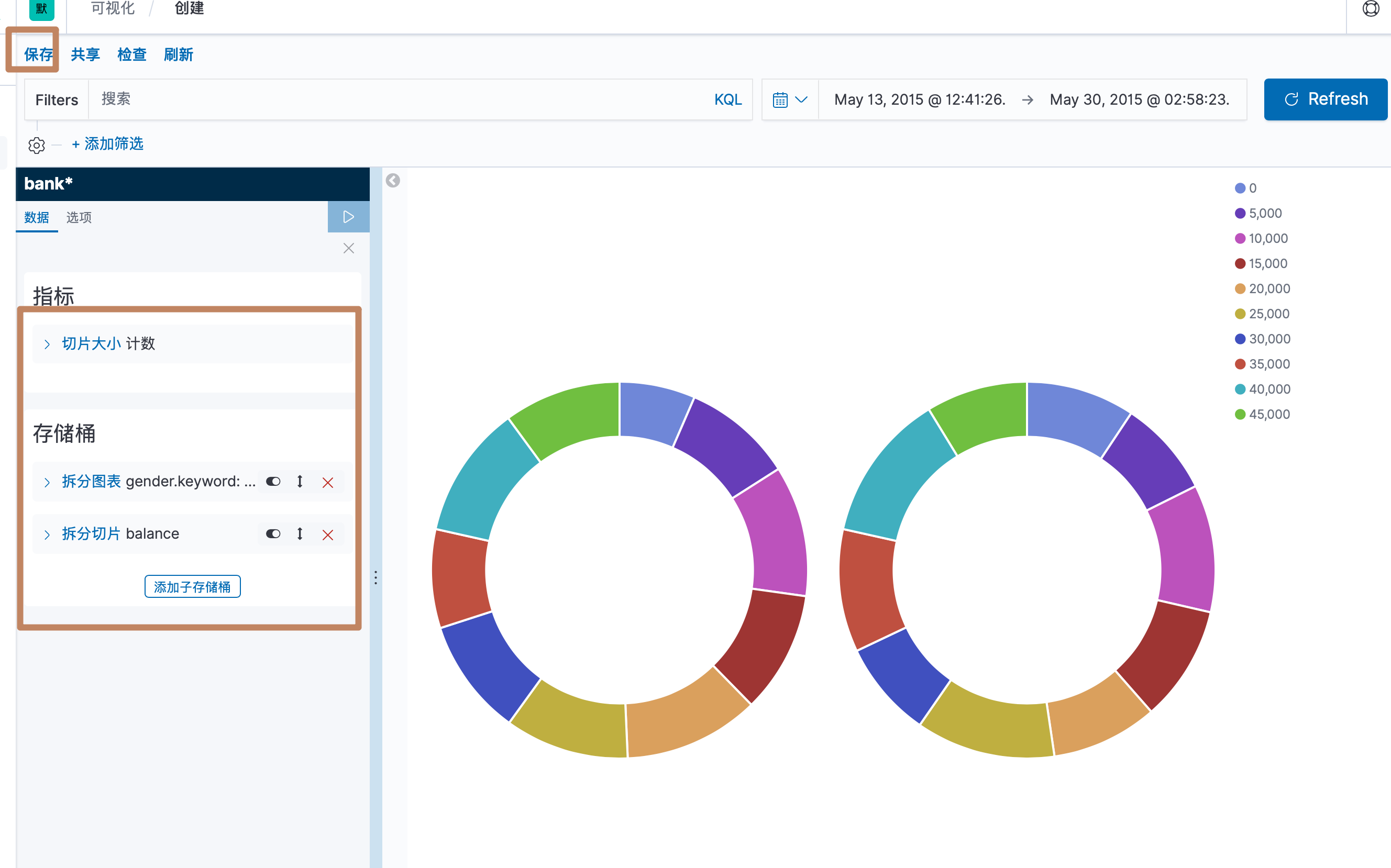
创建好后就进来了一个可视化界面,可以看到,左边比较显眼的有"指标"和"存储桶"两个模块,它们分别就是 Metric 和 Bucket,右边就是一个默认的饼图,没有分桶下的所有数据条数。
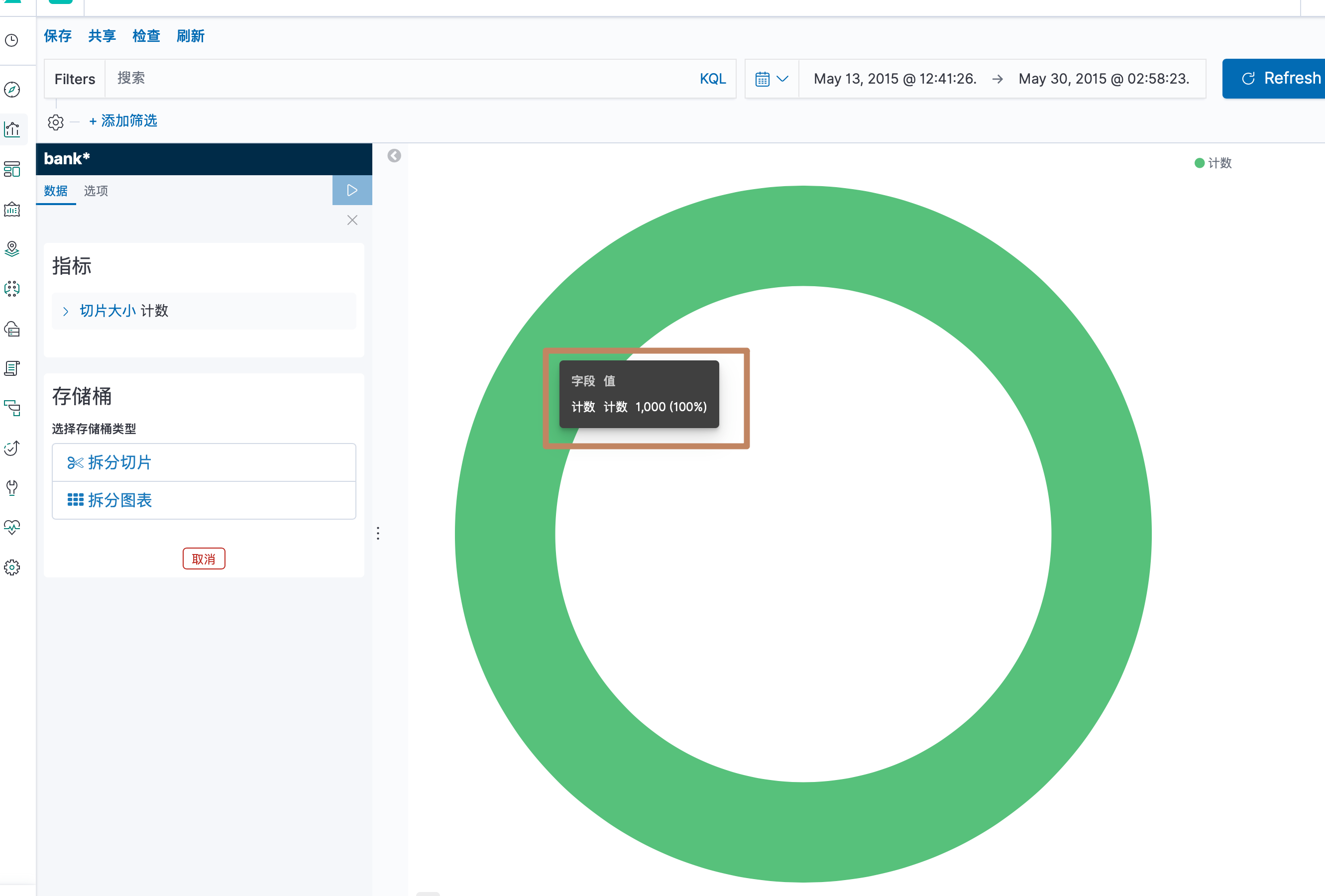
先选择metric,选择计数
bucket分了两种类型:
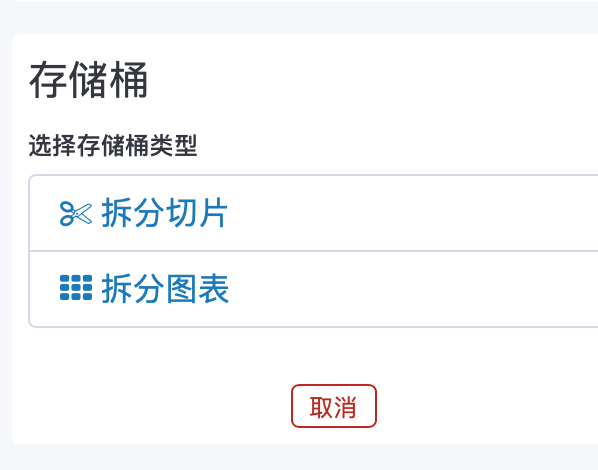
我们先看第一种:
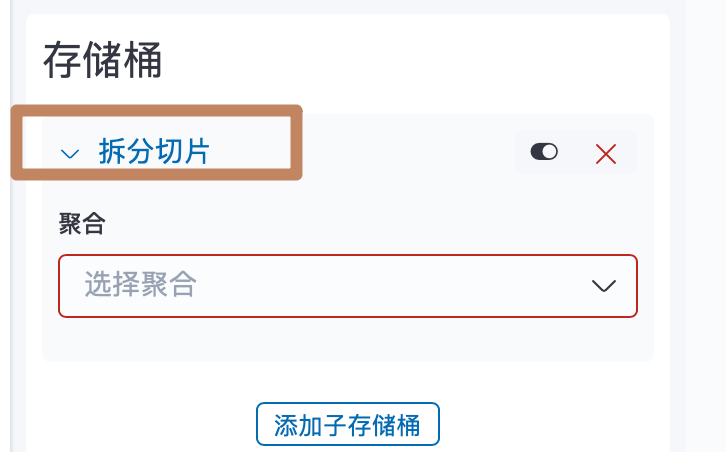
选择直方图
选择字段和直方图的间隔,点击上面的执行后就能看到根据我们的分桶逻辑对一个饼图进行了数据划分。
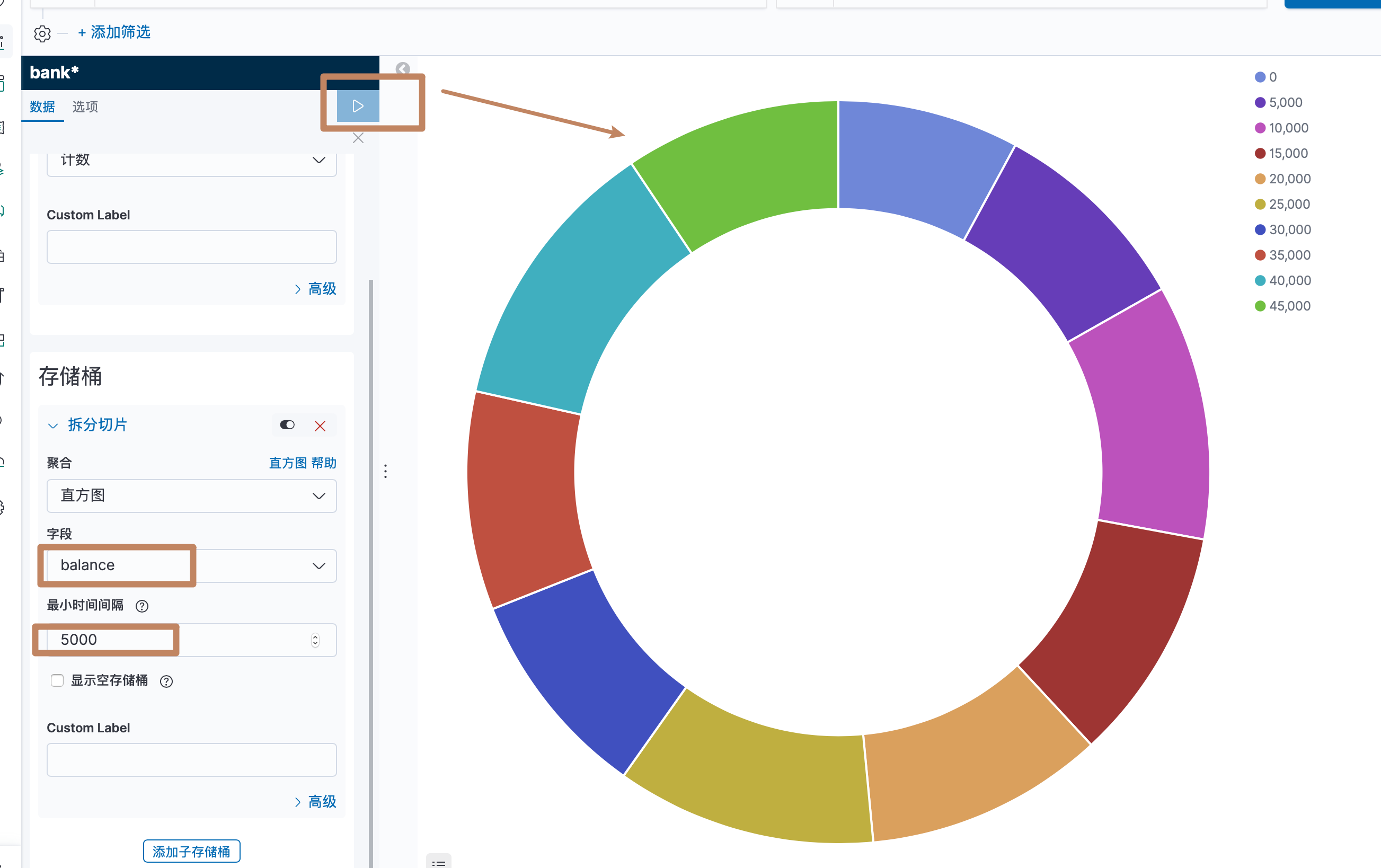
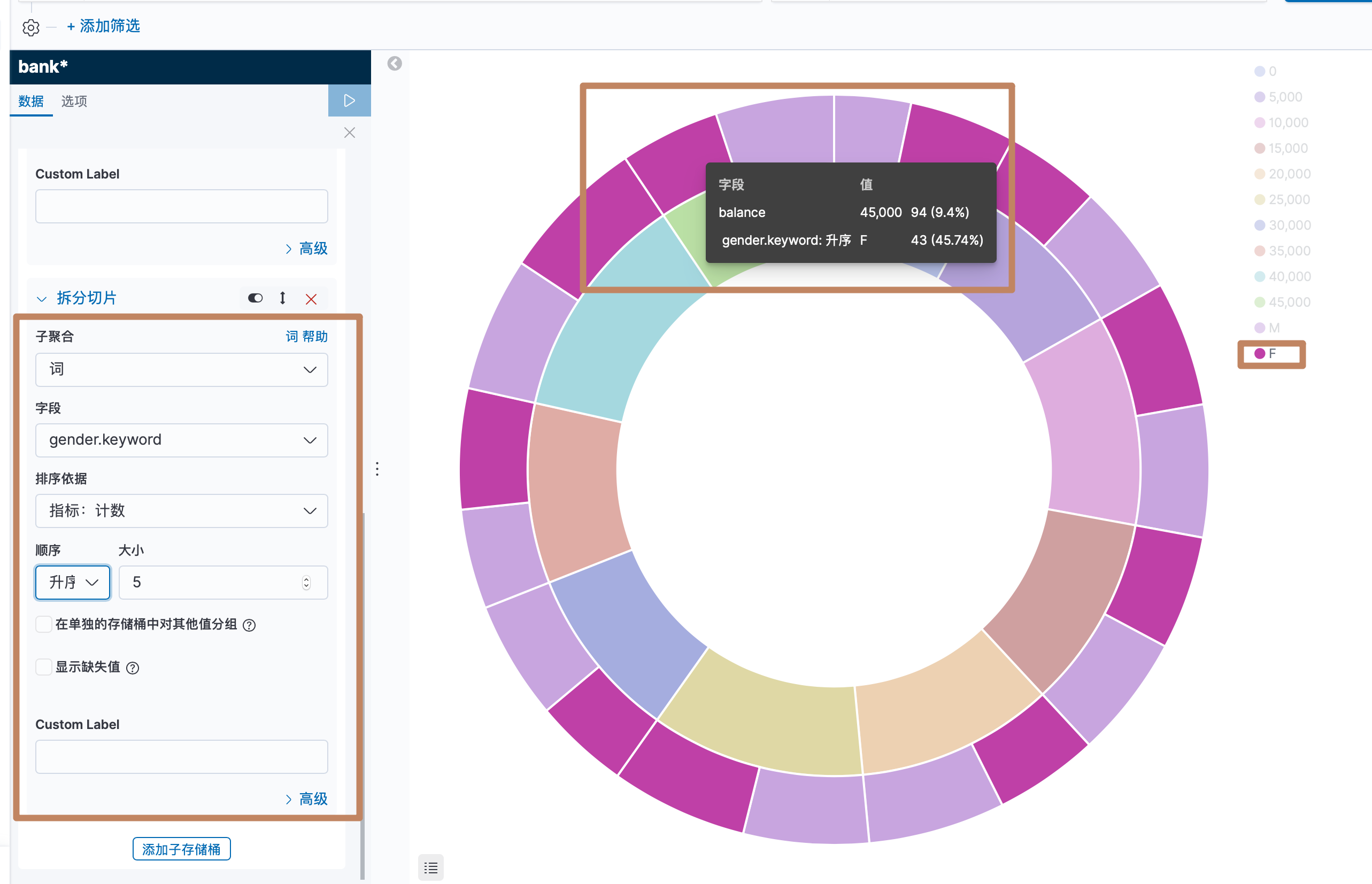
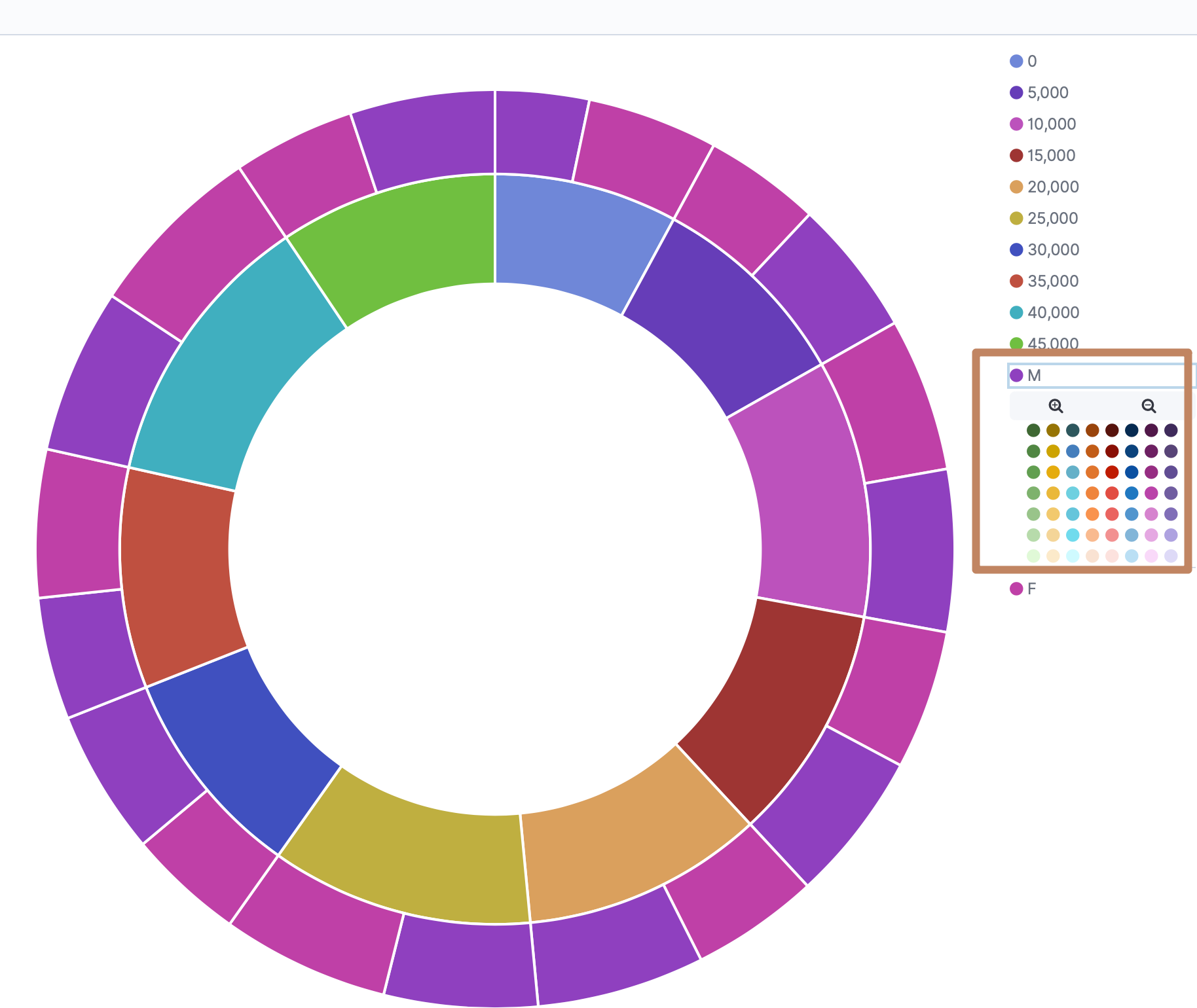
我们上面是对人们的余额的多少做了一个直方图,我们还能进行嵌套,例如35000到40000的区间下男和女分别是多少人。
先选择添加子存储桶:
可以看到外面又出来了一层
这个按钮是可以暂时禁用聚合的
这个是拖拽修改优先级
右边的饼图还能通过点击进行颜色自定义
下面是左边 bucket 中第二种桶的具体逻辑,可以看到它们是按照我们的分桶逻辑对图表进行了分桶,上面是在一个图表种对数据进行分桶:
上面一栏搜索栏可以对我们需要聚合的数据范围进行筛选:

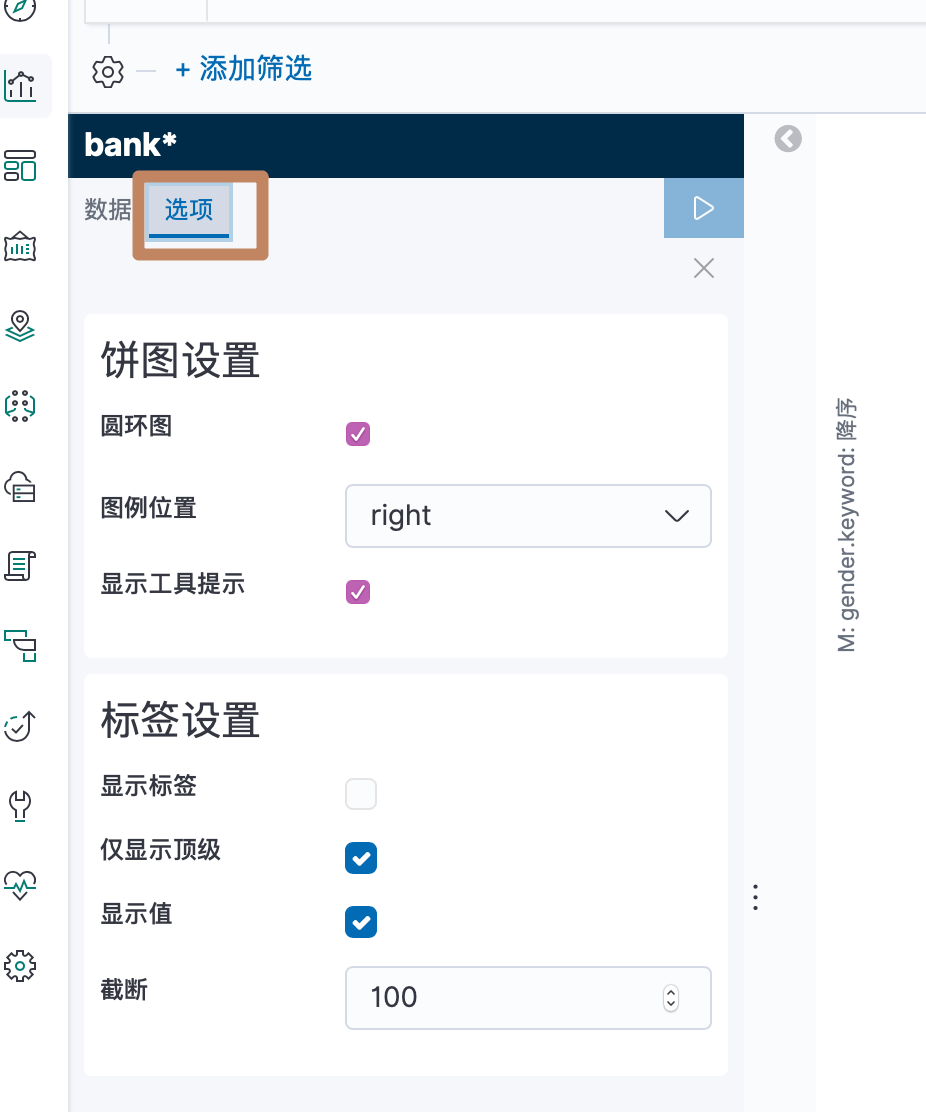
这里的选项可以对图表的一些属性进行设置:
另外我们知道这些数据都是通过请求一个 api 获取的,我们可以通过上面的检查按钮来查看我们的 request、response 等等的数据:

最后我们配置了一个 count 的 metric 和一个基于性别的拆分图表的桶和一个子的基于银行余额的拆分数据的直方图的桶,点击保存:
 Markdown: Open Preview to the Side
Markdown: Open Preview to the Side
输入名称
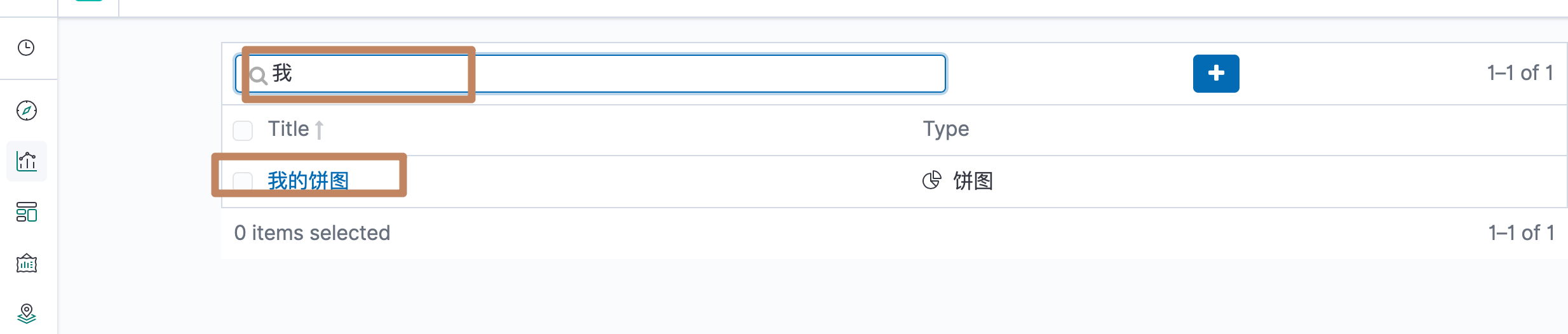
再次来到可视化的列表页,就能搜索到我们保存的"我的饼图"拉
其他的组件大同小异,有时间再看。
四、构建 Dashboard
dashboard 中其实就是一组可视化组件的集合。我们可以用我们前面介绍的可视化构建出多个可视化图表并全部整合到一个 dashboard 中。
选择左边面板的仪表板,进到 dashboard 界面:
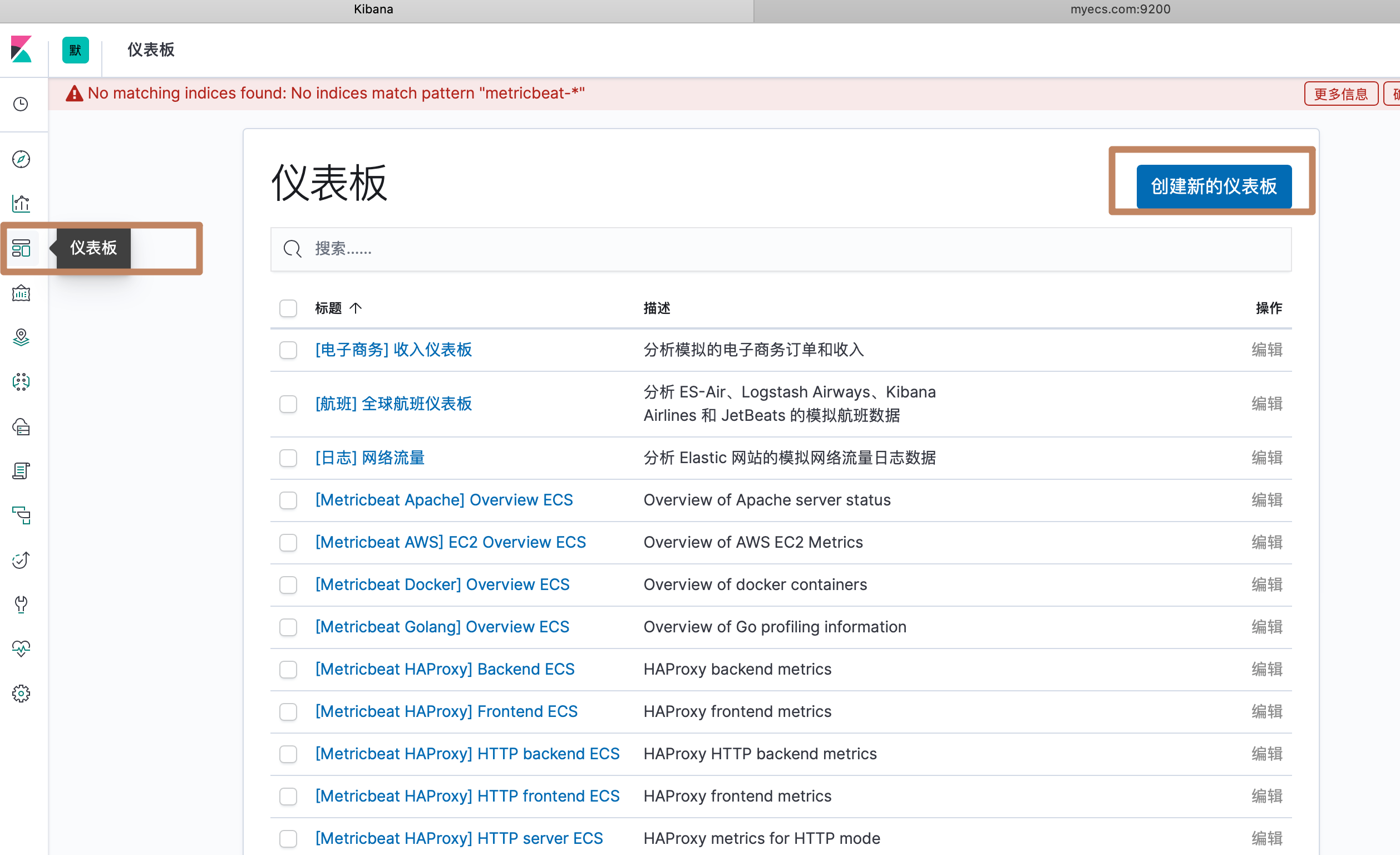
添加我们刚刚创建的饼图,另外还可以通过中间的超链接点击到可视化组件界面进行可视化图表创建
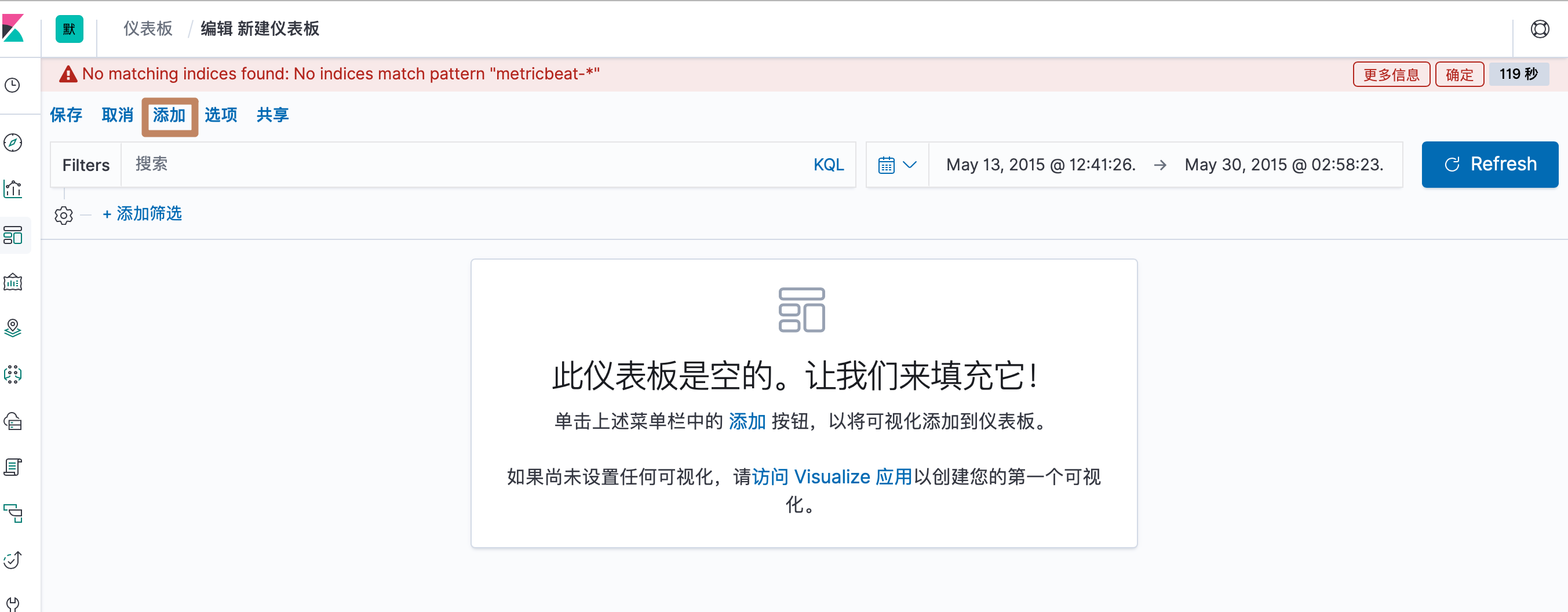
右边弹出一个弹窗,点击我们保存的可视化组件的名字即可添加到了 dashboard
我们还能对这个图表做以下操作
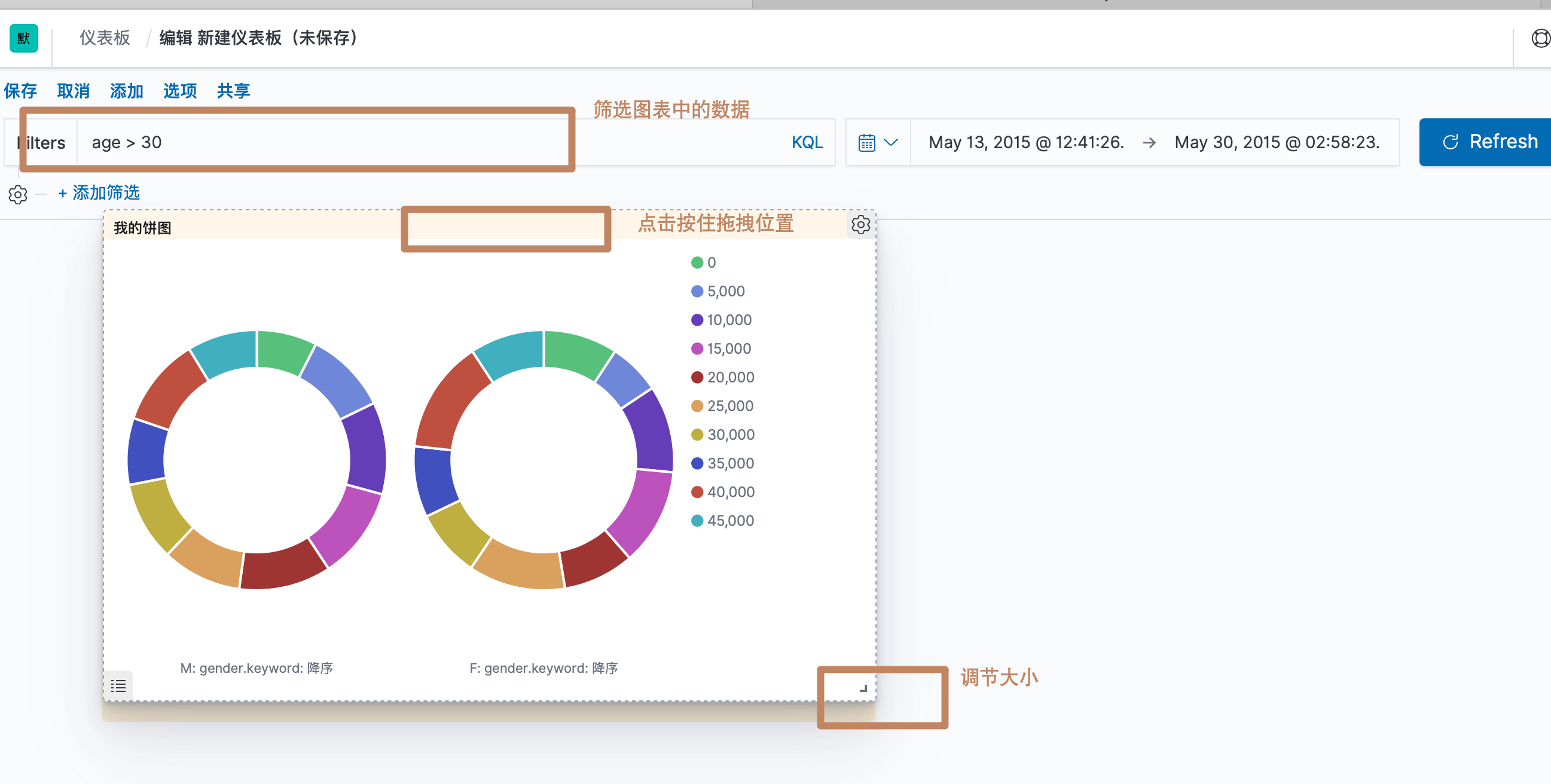
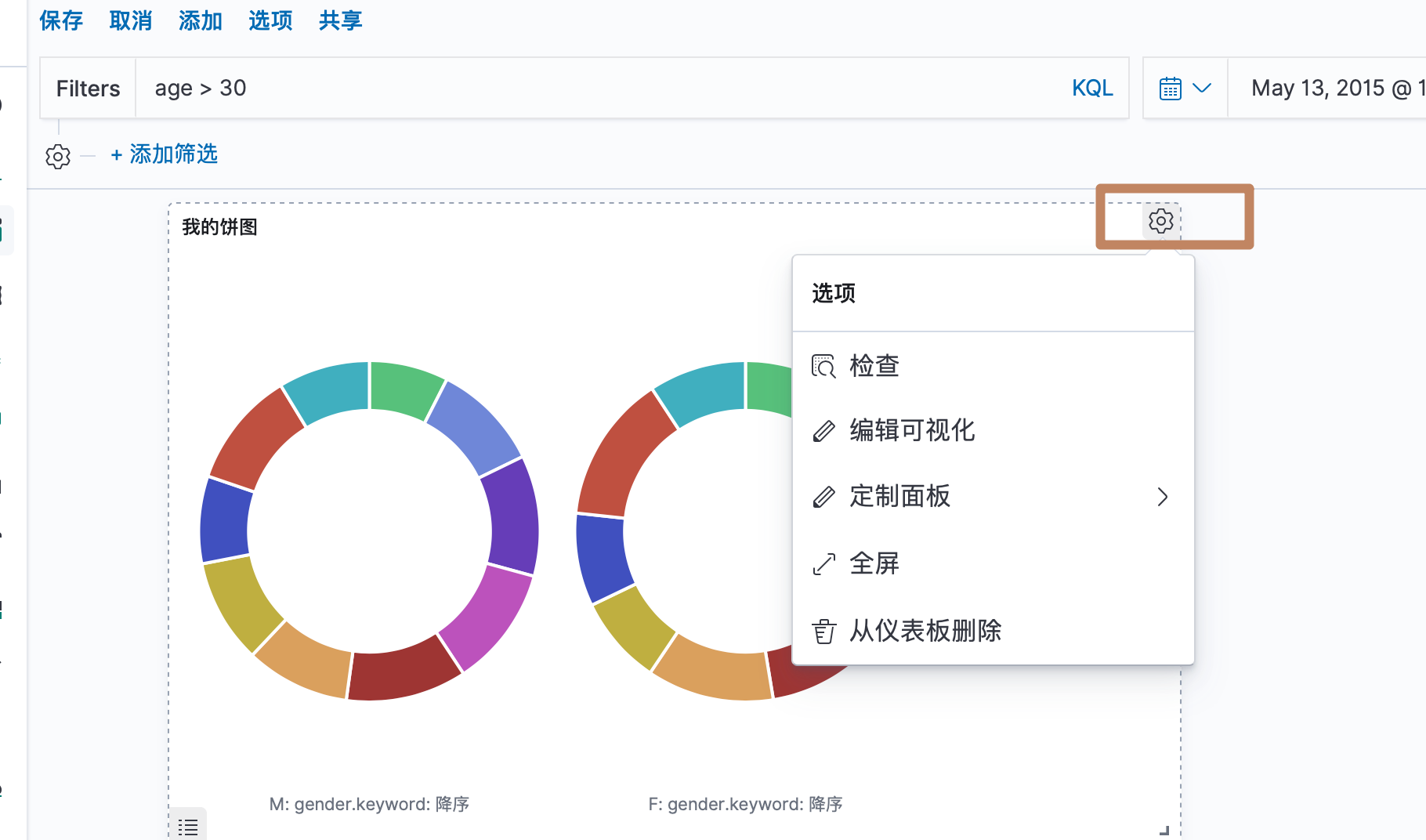
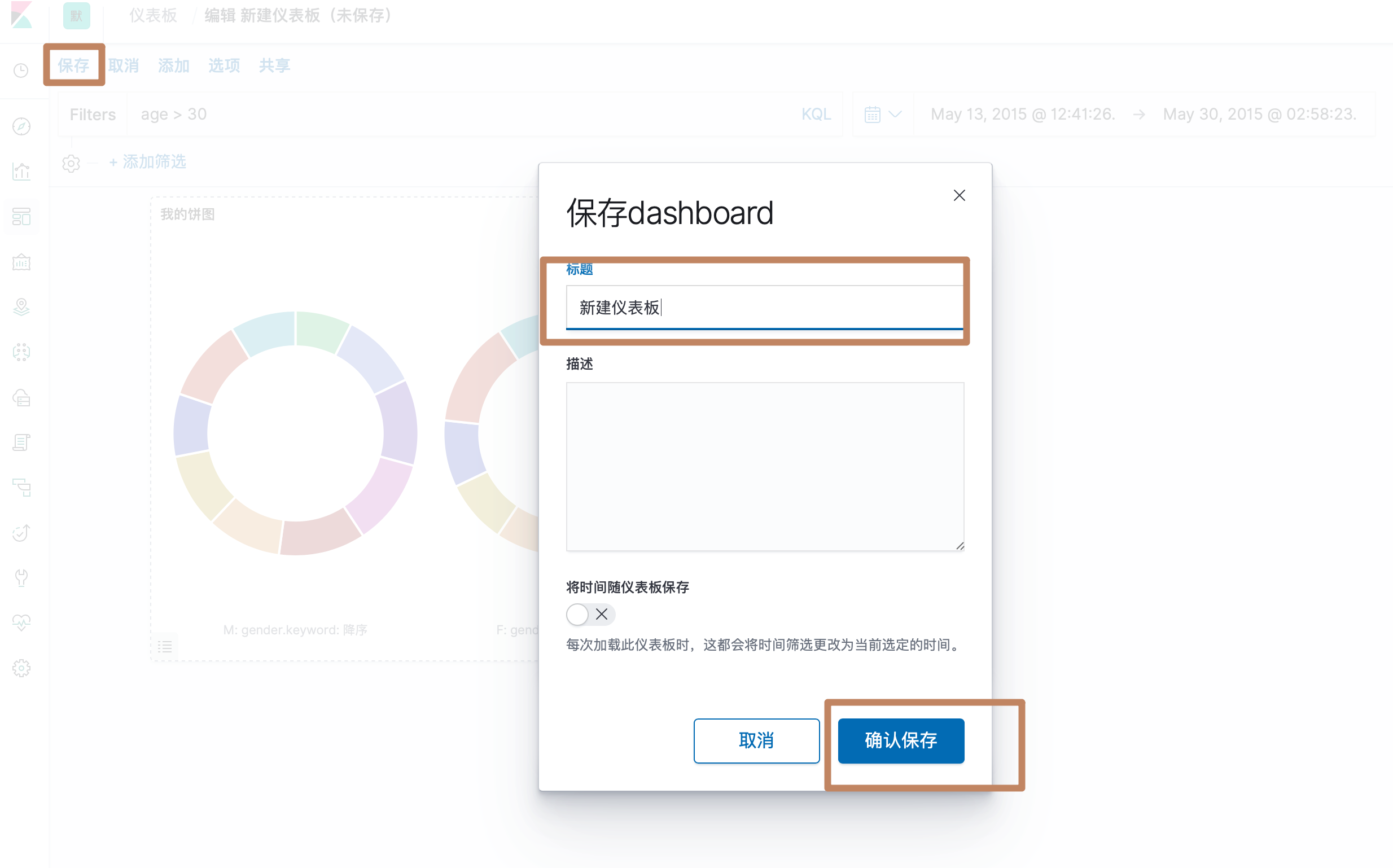
点击保存,即可对我们的dashboard 进行保存。
¶官方自带的测试样例
另外我们还可以参考官方开箱即用的3个测试数据集:

其中一个 dashboard
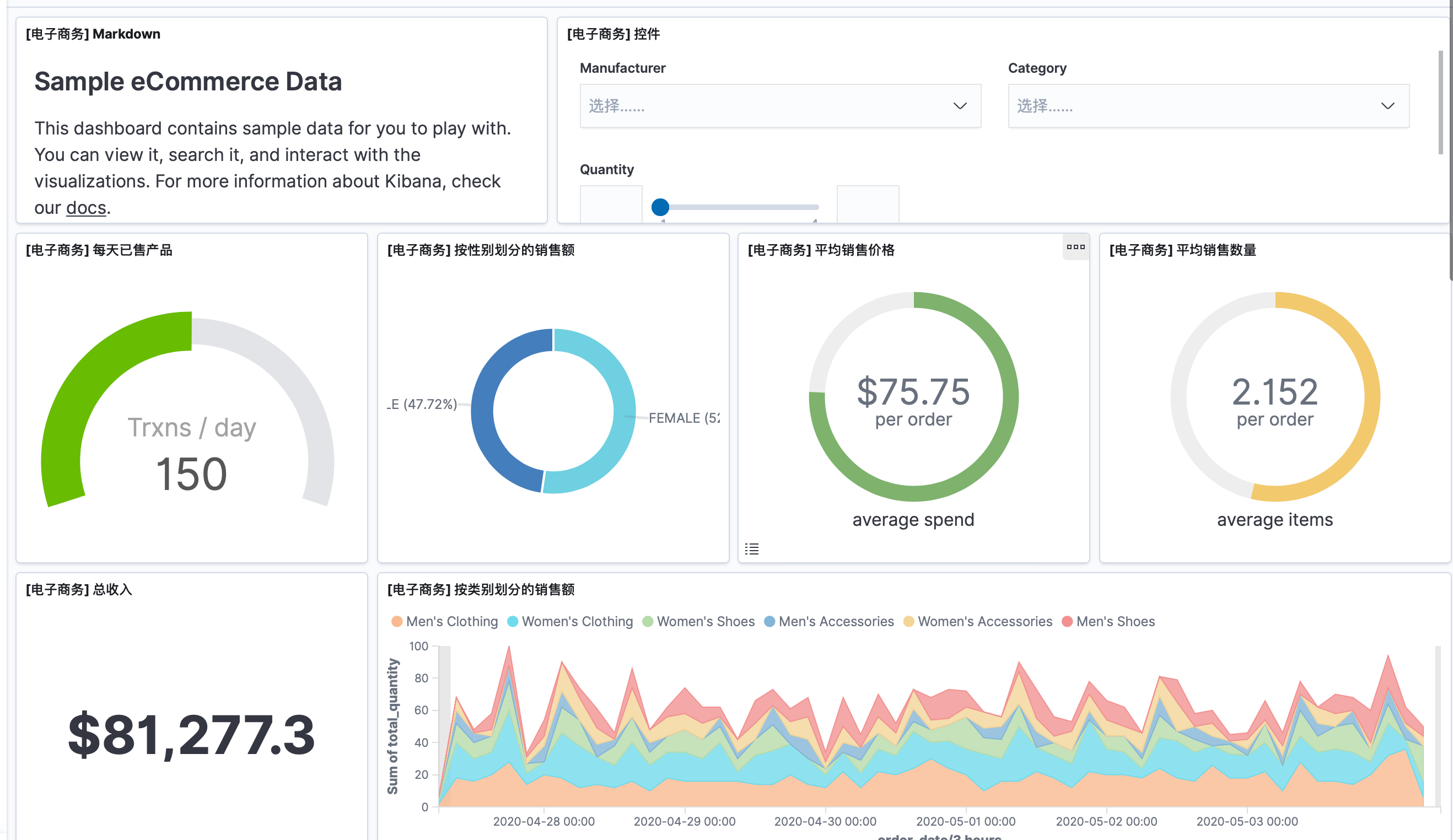
这些都是很专业的图表,我们可以进行参考,同时我们还能直接修改这些图表。
五、在 Kibana 中探索 X-Pack 套件
¶<1>用 Monitoring 和 Alerting 监控 Elasticsearch 集群
X-pack 提供了免费的监控 Elasticsearch 集群和 Kibana 的功能。默认的定时检查时间间隔是10秒,可以通过Xpack.monitoring.collection.interval来配置。
下面是 Monitoring的一些配置
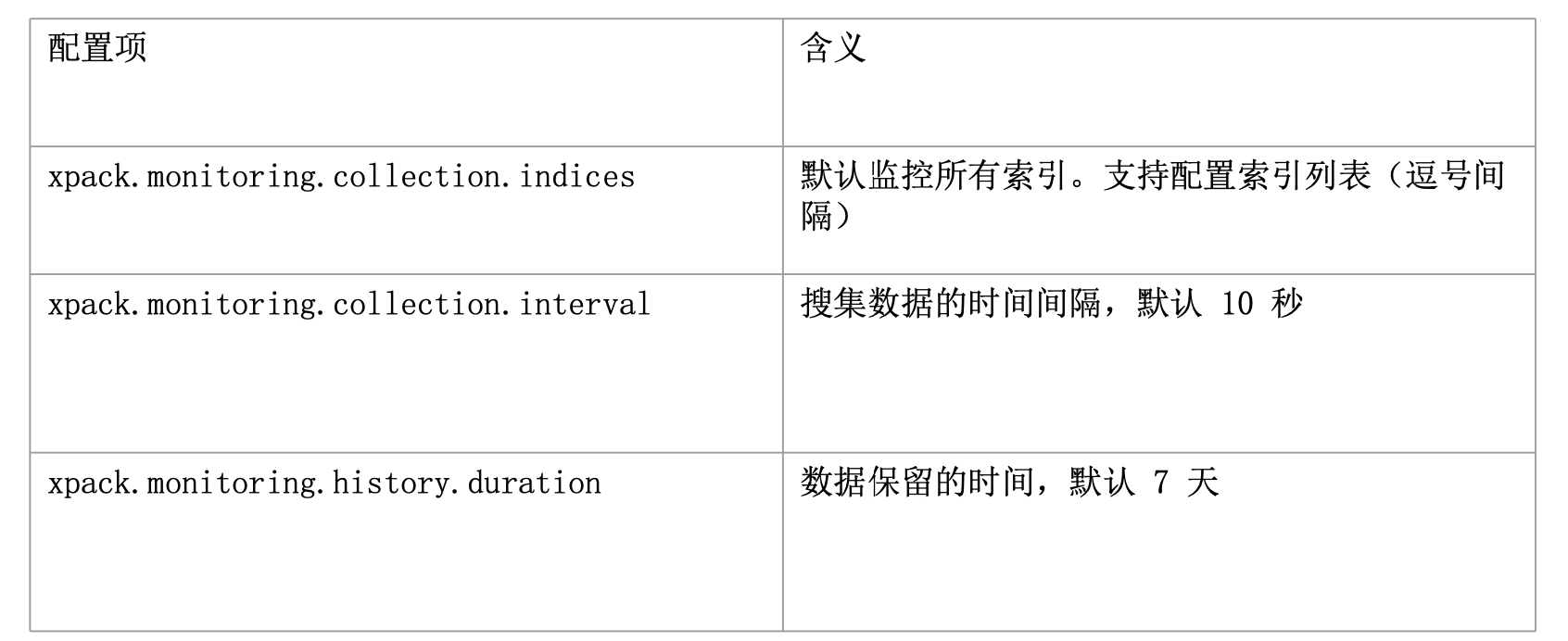
详细可以参考:https://www.elastic.co/guide/en/x-pack/current/monitoring-settings.html
在生产环境中,建议搭建 dedicated 集群用于 ES 集群的监控。有以下好处:
- 减少负载和数据
- 当被监控集群出现问题,还能看到监控相关的数据
另外,X-pack 中还有报警的功能,但是这个是需要 Gold 账户的。这个功能叫 Watcher for Alerting,一个 Watcher 由5个部分组成:
- Trigger:多久被触发一次(例如:5分钟触发一次)
- Input:查询条件(在所有日志索引中查看"ERROR"相关)
- condition:查询是否满足条件(例如:大于1000条返回)
- Actions:执行相关操作(例如:发送邮件)
¶Demo
我们点击左边面板中的"堆栈检测",可以看到默认情况下 X-Pack 的 monitoring 功能是关闭的,我们打开它:
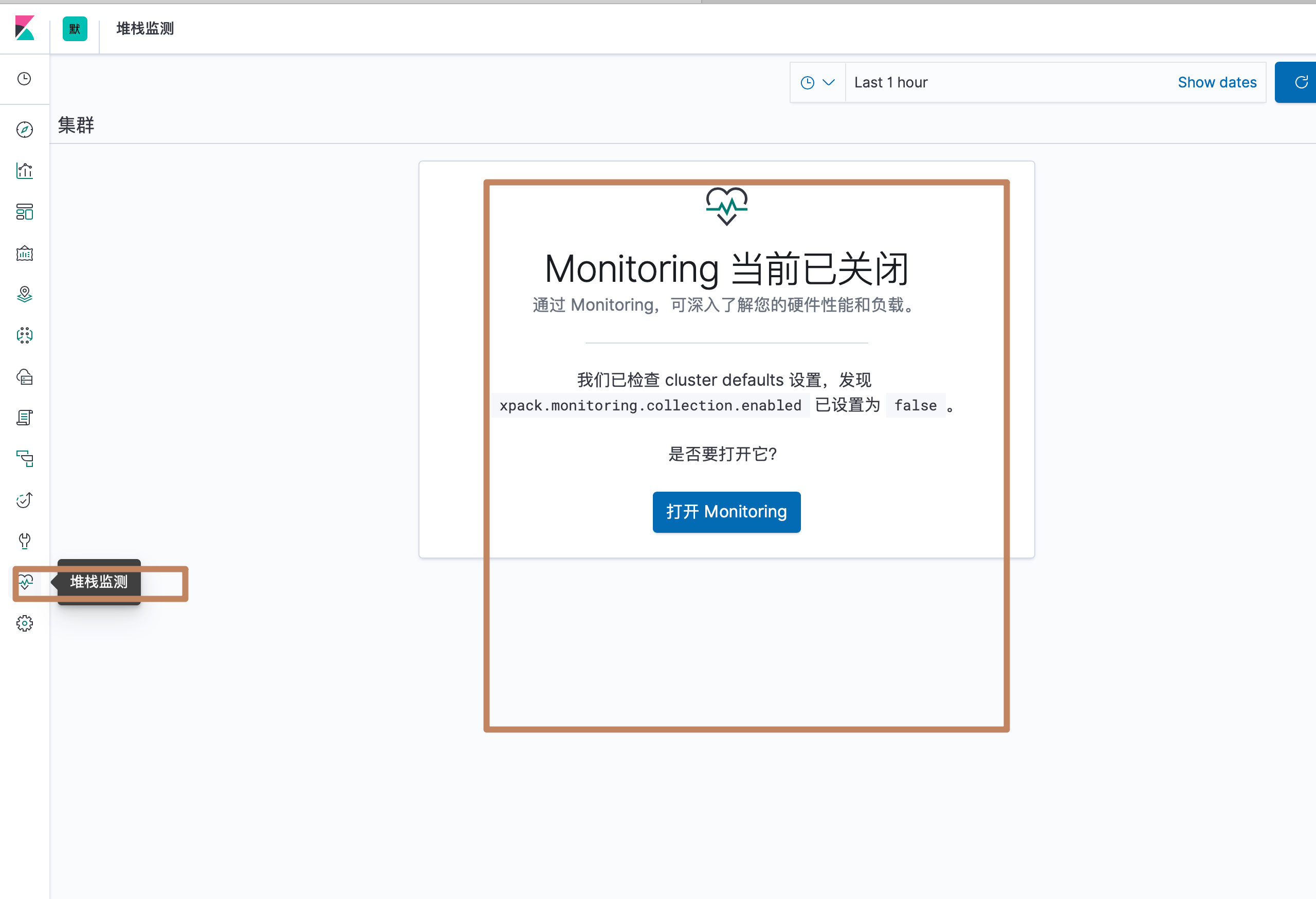
几秒的搜集数据之后,就进入了一个总览界面,分别有 ES 的总览级别的监测、节点级别的监测、索引级别的监测以及 Kibana 的总览级别的监测和实例级别的监测,我们分别进入查看一下:
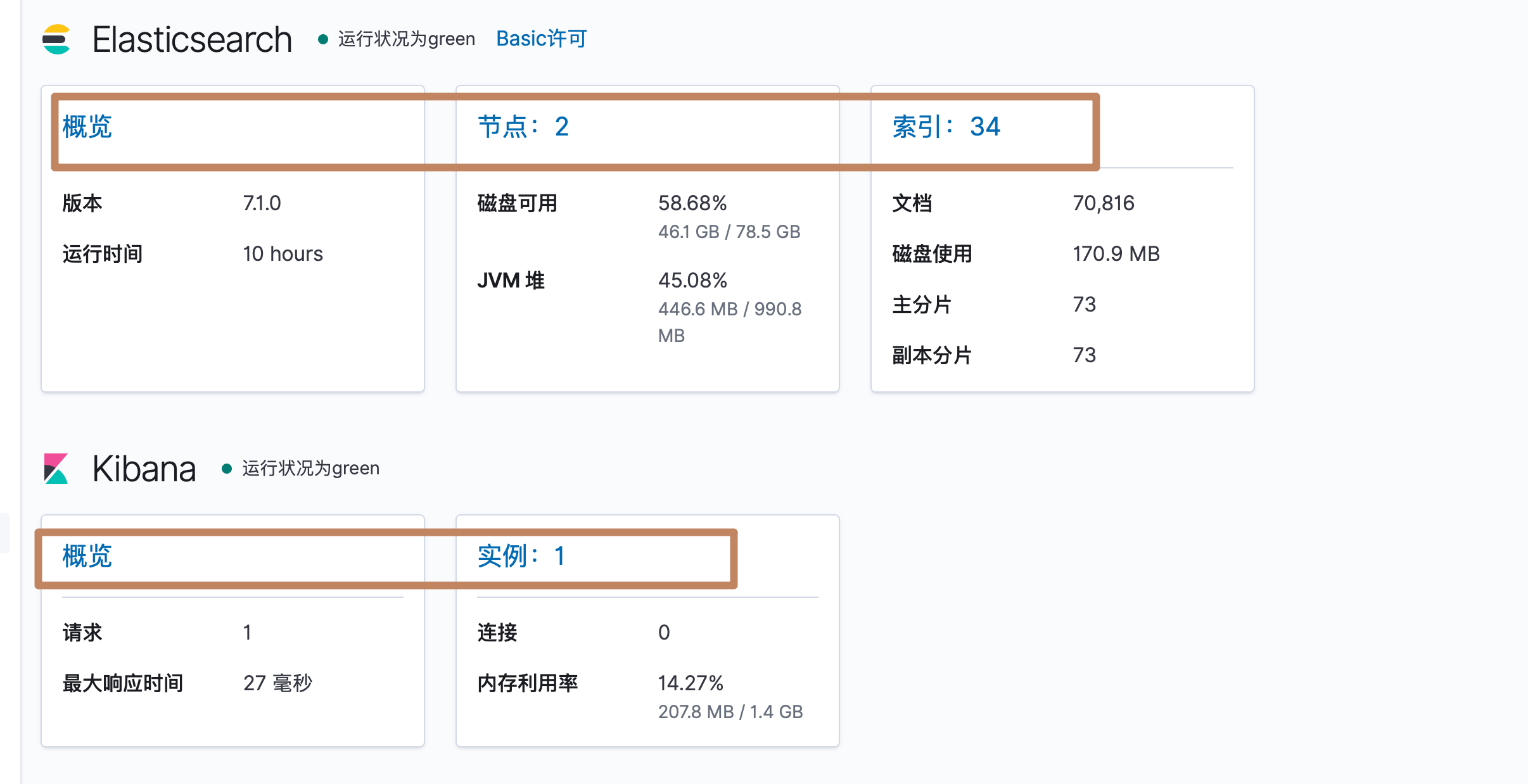
-
ES 的总览监测
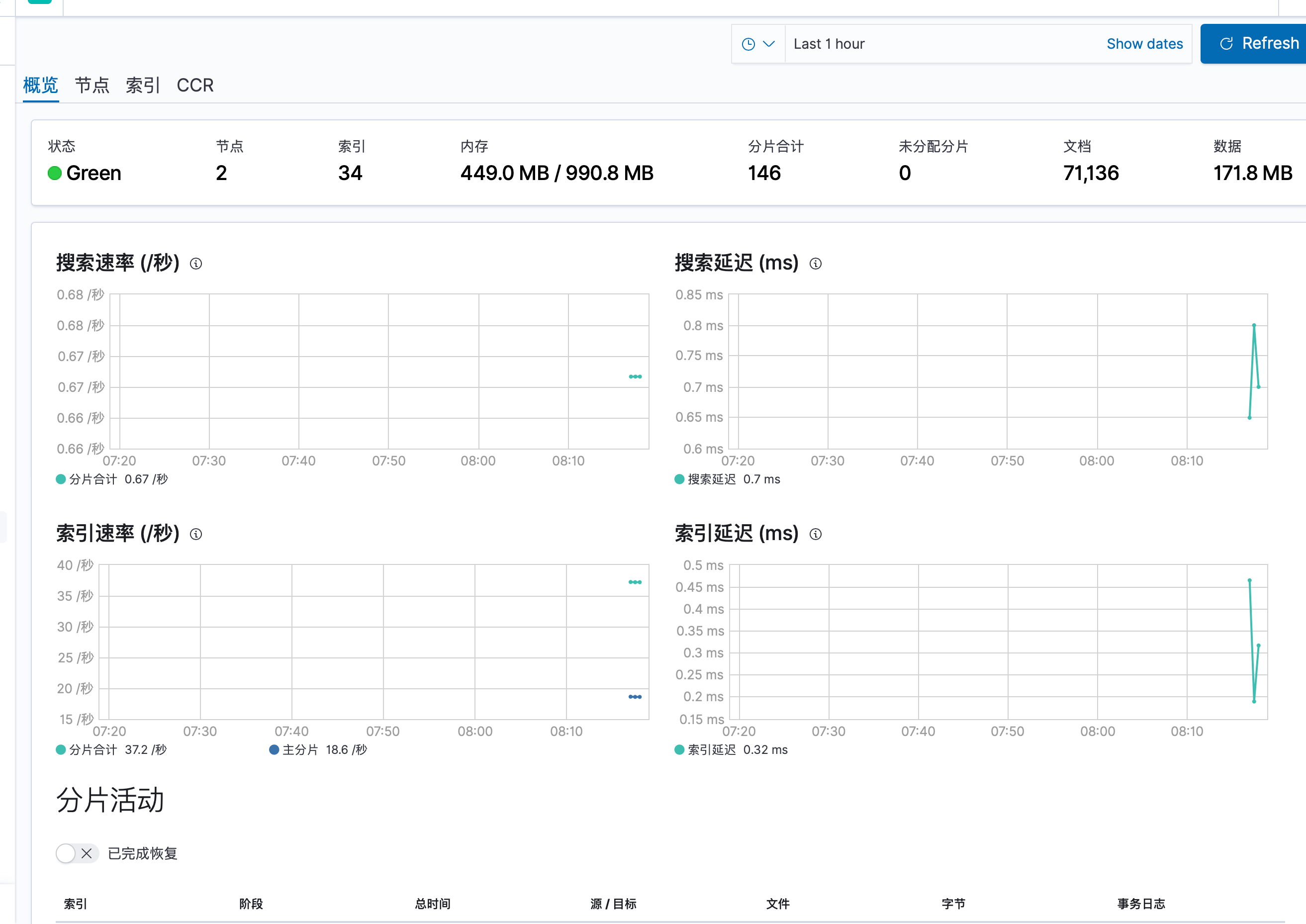
-
ES 的节点监测
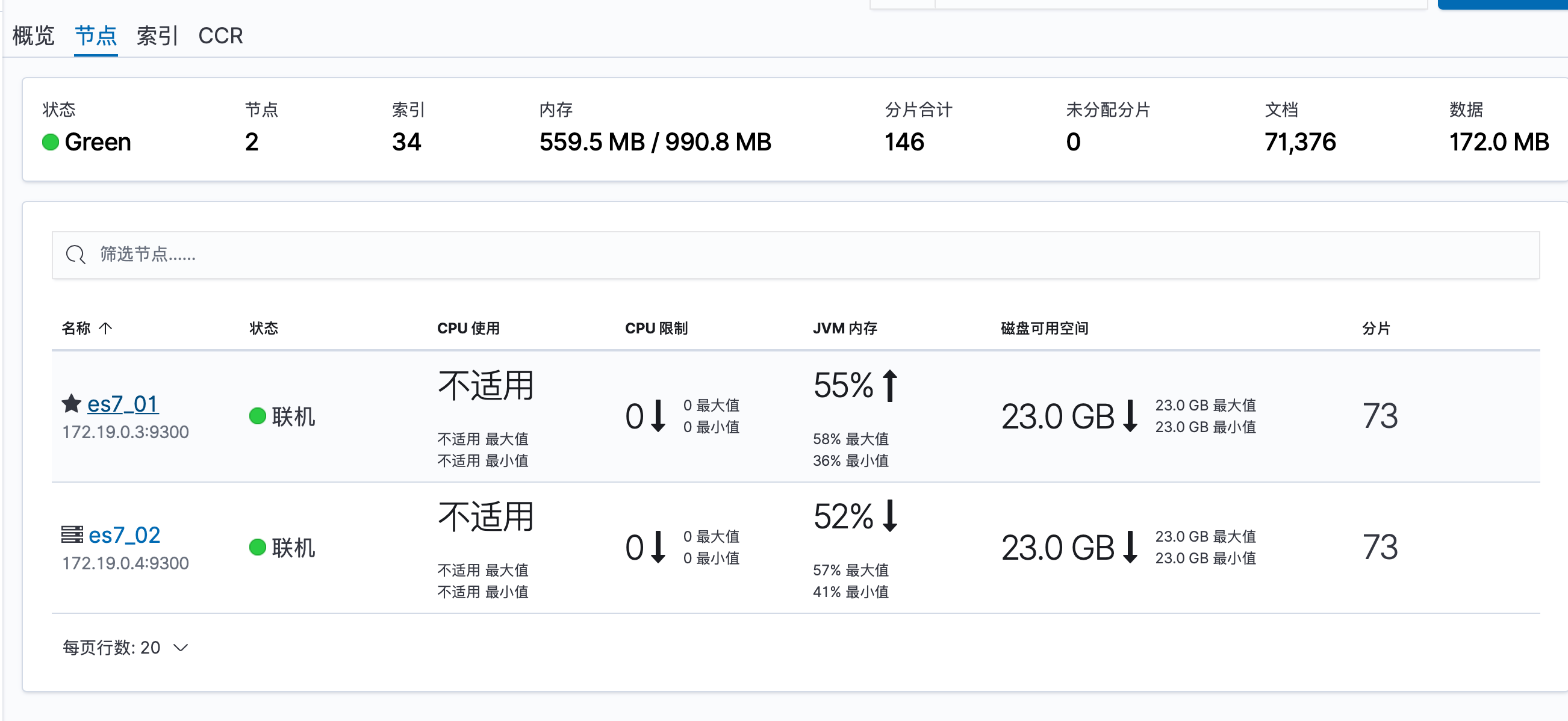
点击节点名称进入详细监控界面,下面是详细界面的概览部分
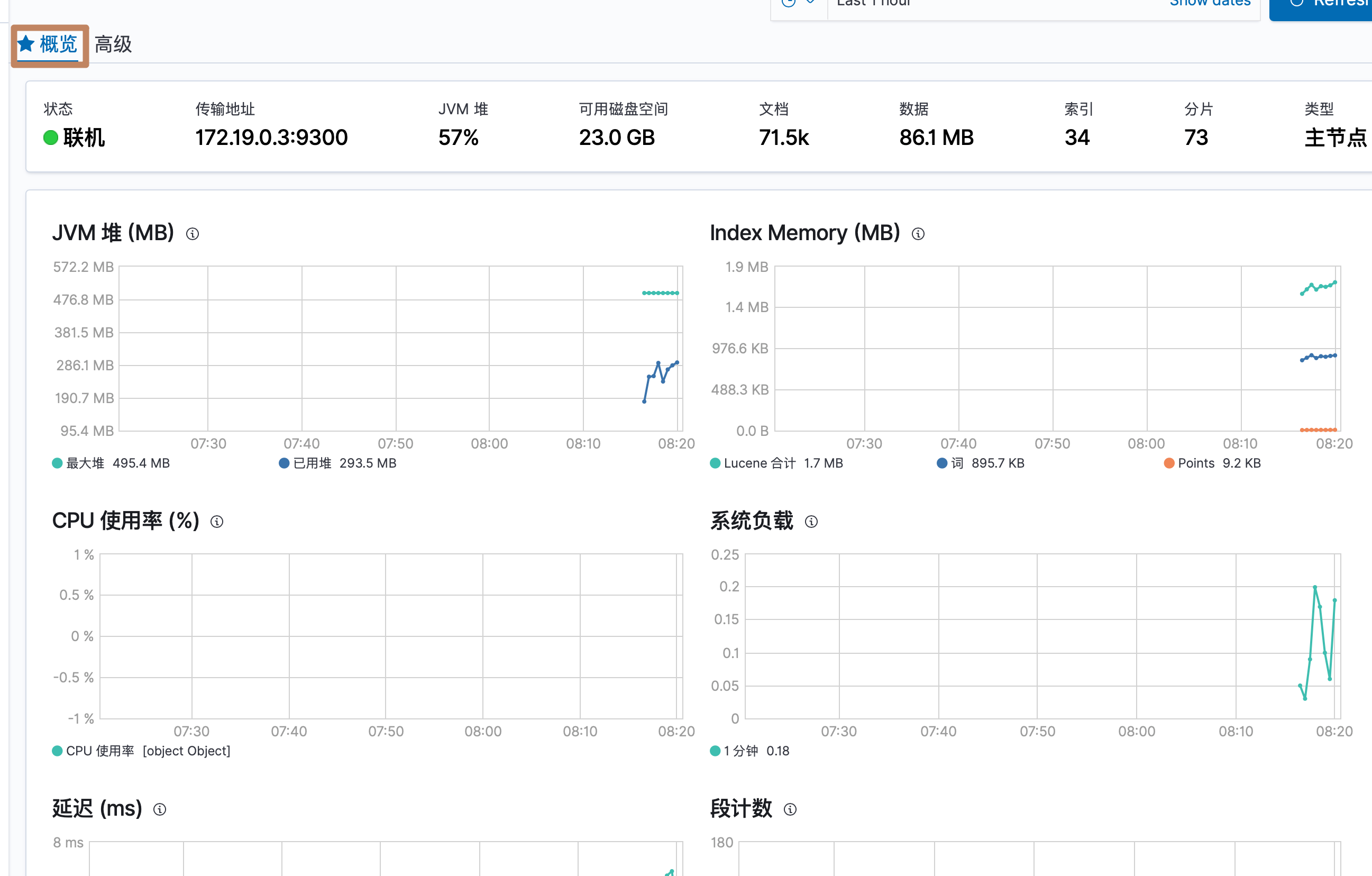
下面是高级部分
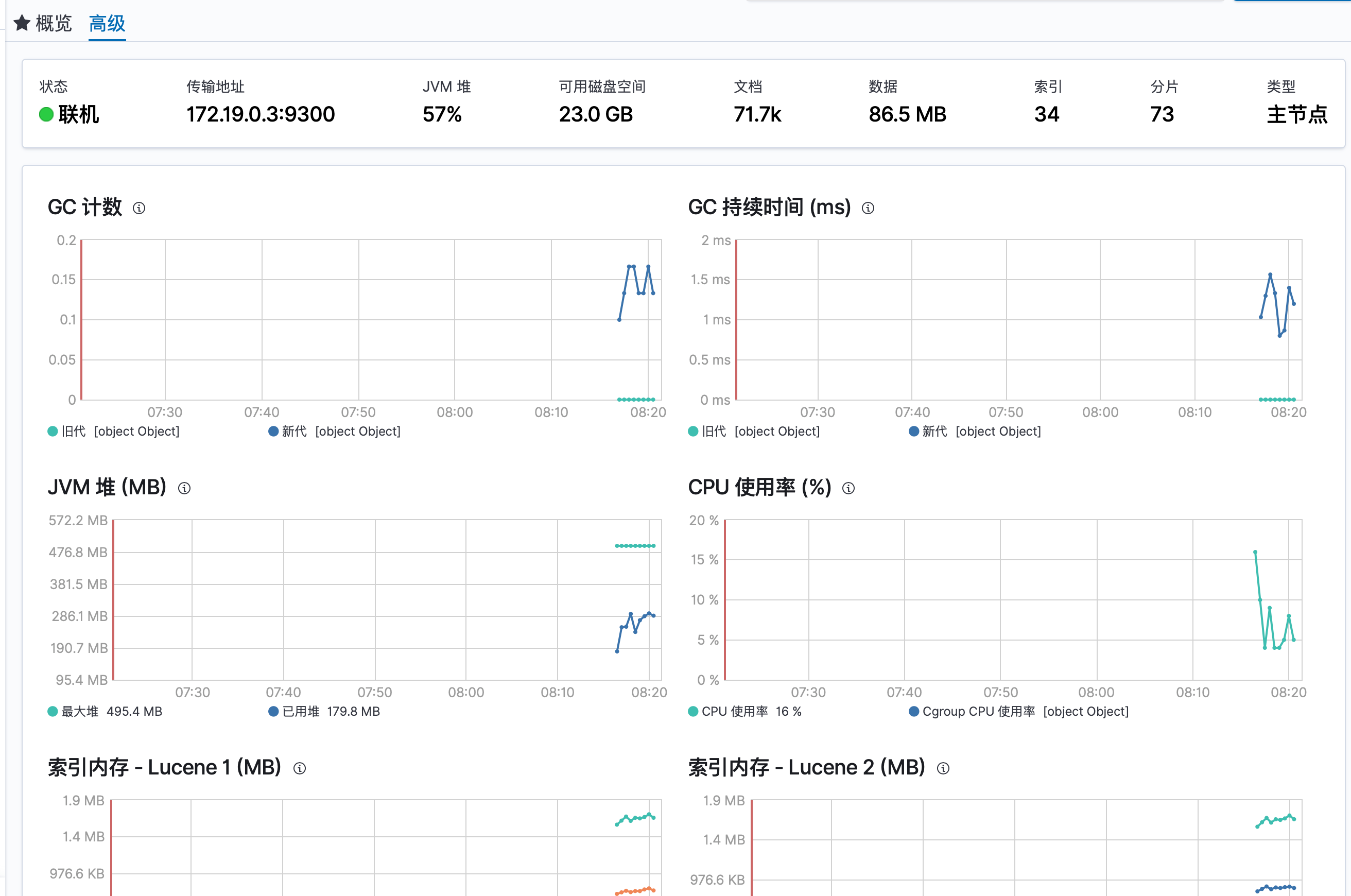
-
ES 索引级别监控
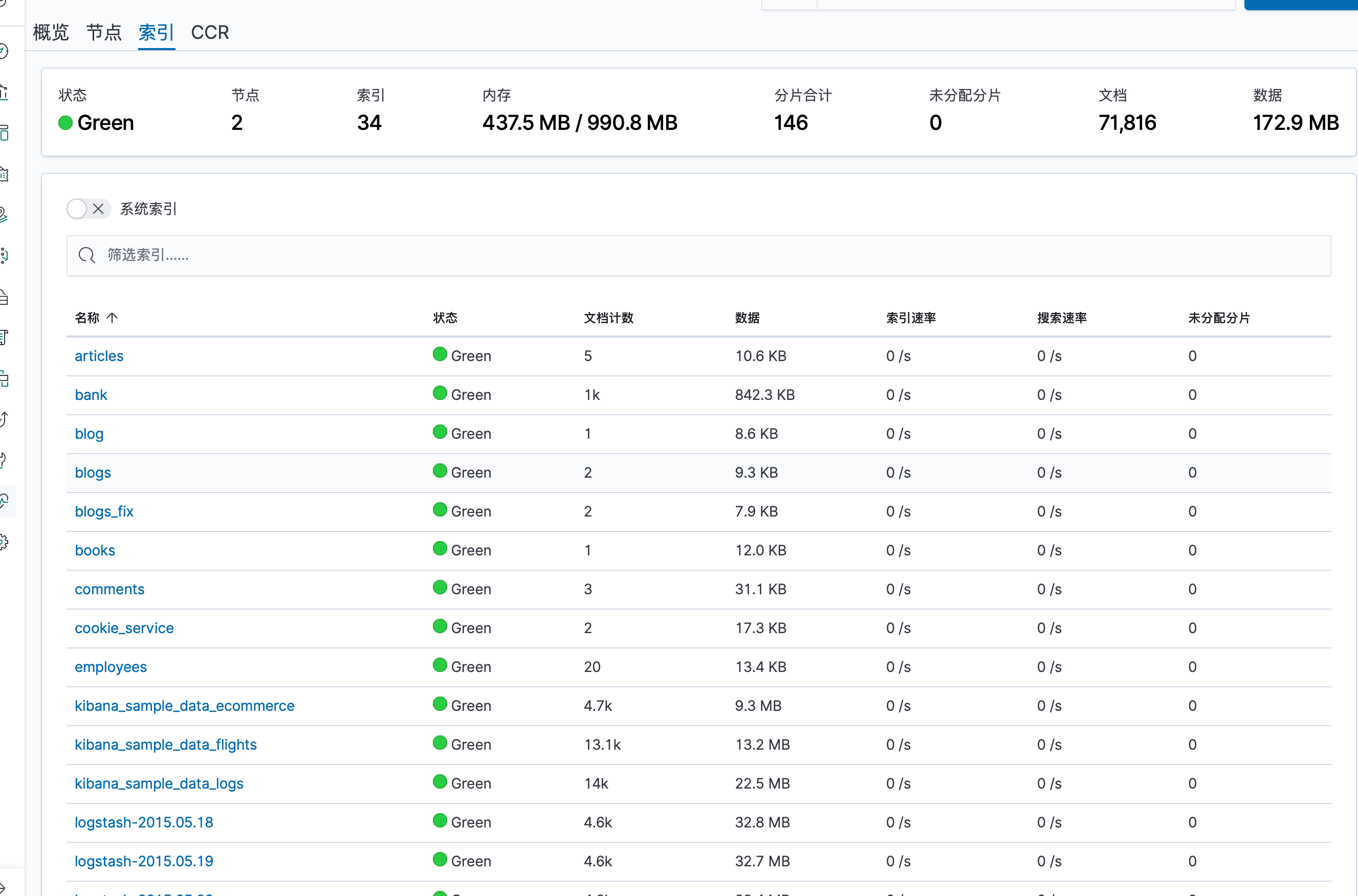
点击具体的索引名称进入详细监控界面,同样分了概览和高级
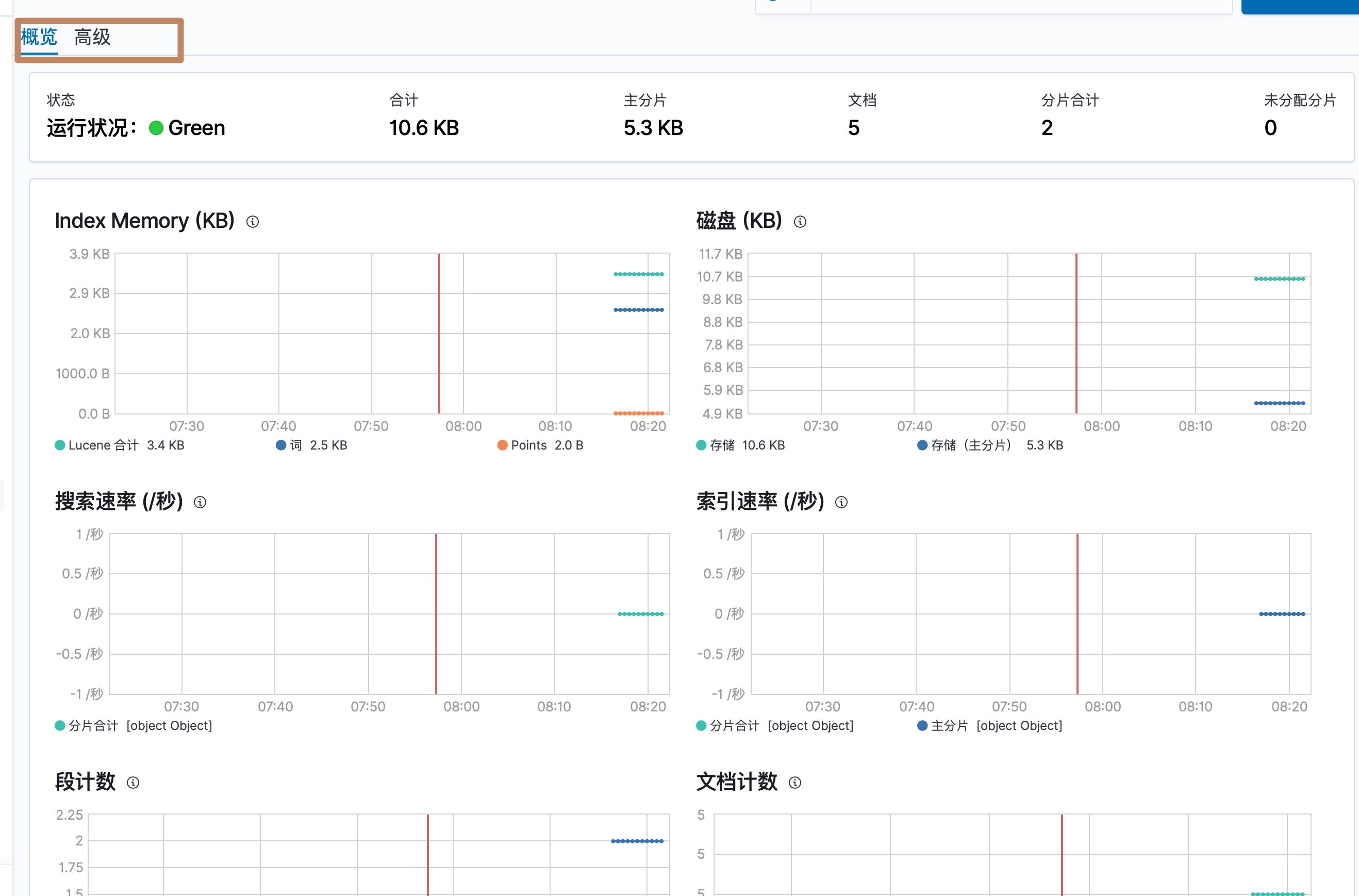
-
这里还有一个 CCR(Cross Cluster Replitaion) 跨集群备份的监控

-
Kibana 概览级别监控
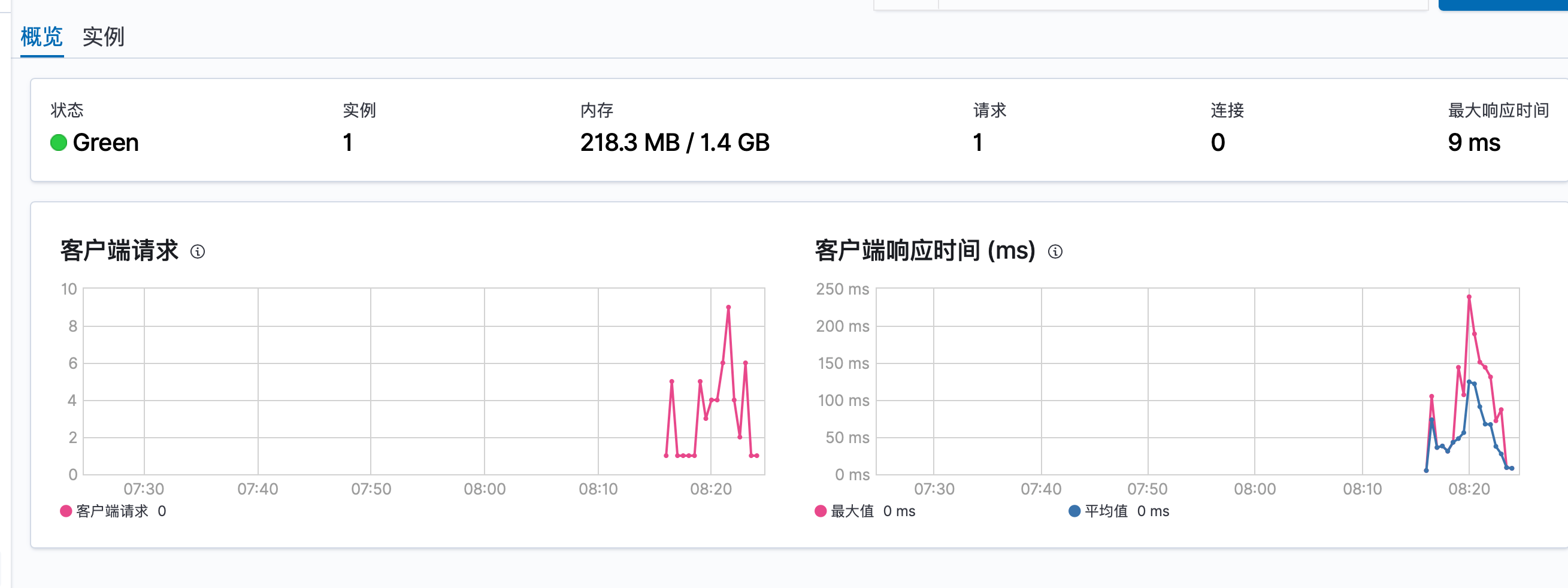
-
Kibana 实例级别监控
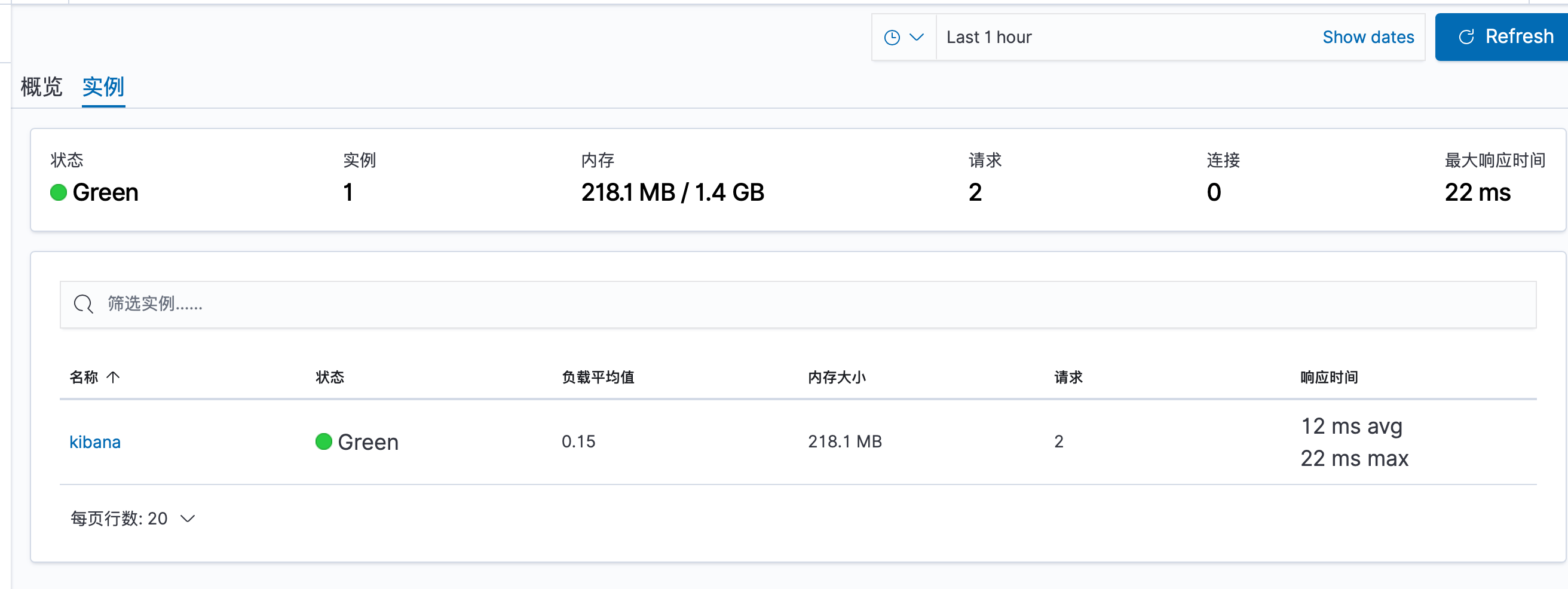
同样点击实例名称进入详细界面
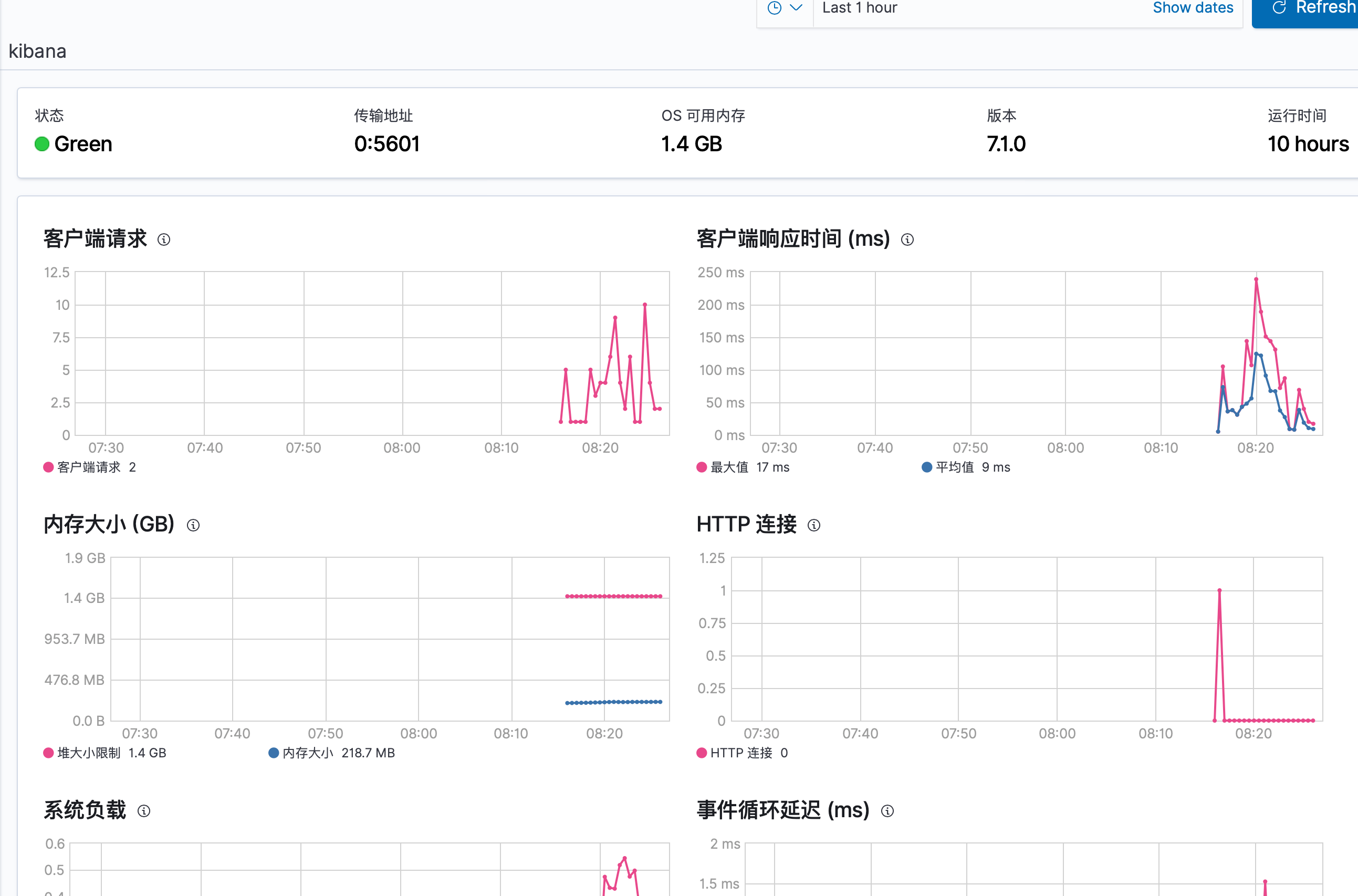
上面是关于 monitoring 的介绍,下面介绍 alerting 的功能,因为 alerting 是收费的,所有我们要先开启试用:
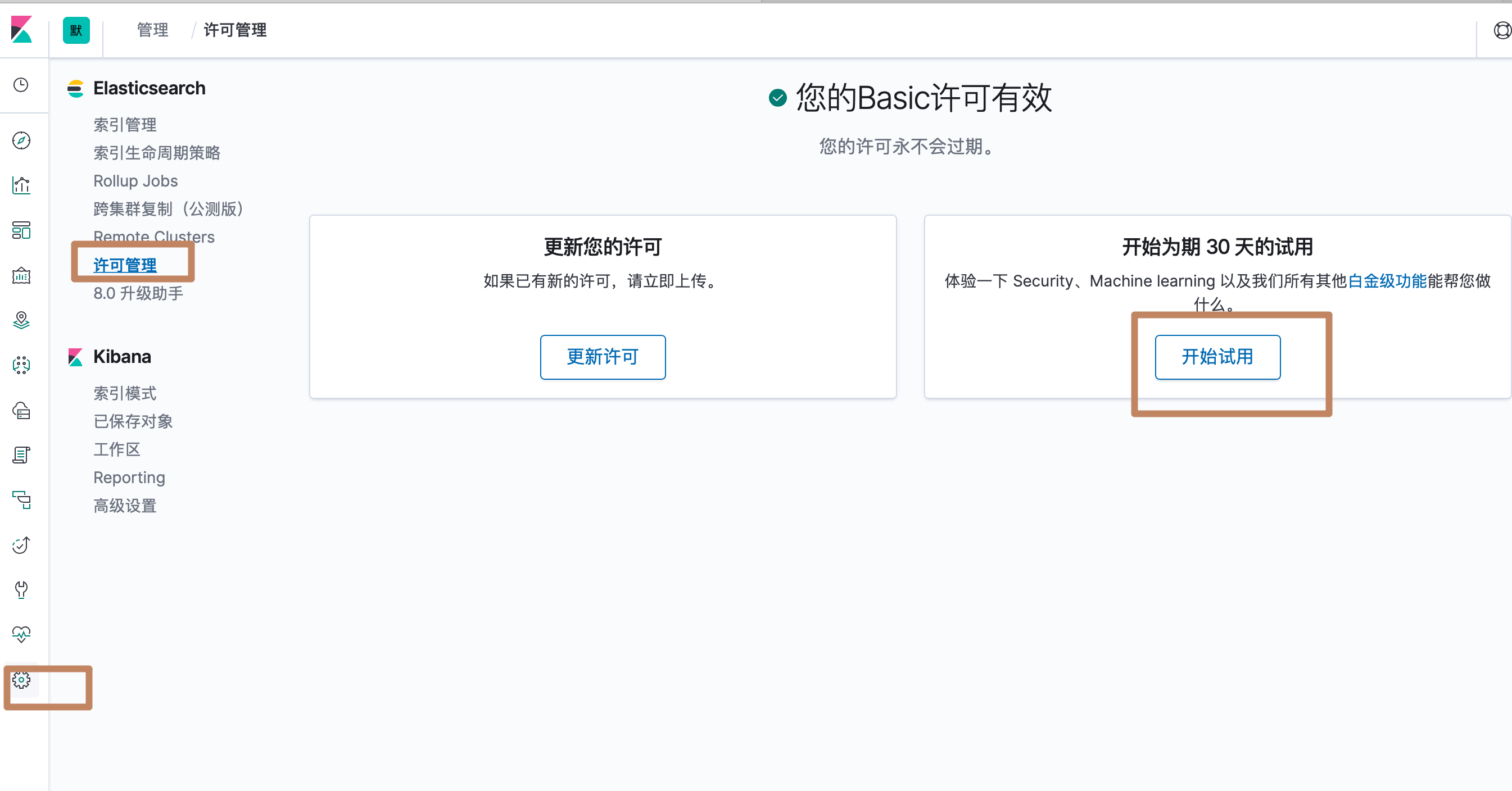
可以看到这里多了一个 watcher 的选项,我们点击:
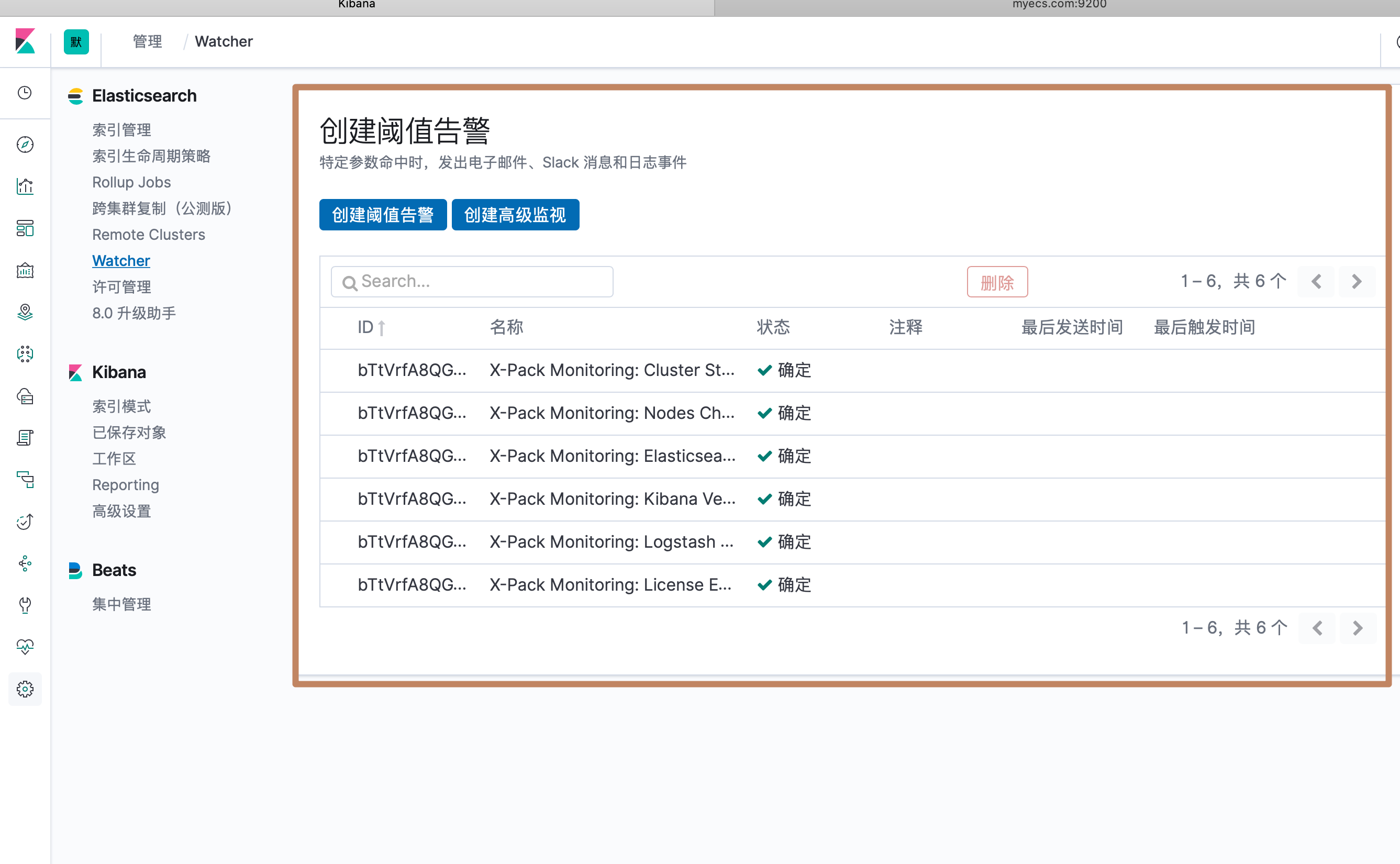
我们尝试创建一个"阈值告警":
当我们选择一个"bank*"索引进行监听的时候,发现提示索引没有关联的时间字段,因为我们这个索引里面确实没有时间戳类型字段,而我们在kibana创建index pattern 的时候也就没有指定时间字段,而这里的"阈值告警"是指定一个过去的时间区间内如果文档数量超过了多少的数值就会发出一个怎样的告警。所以对于"bank*"这个索引,"阈值告警"就做不了了。
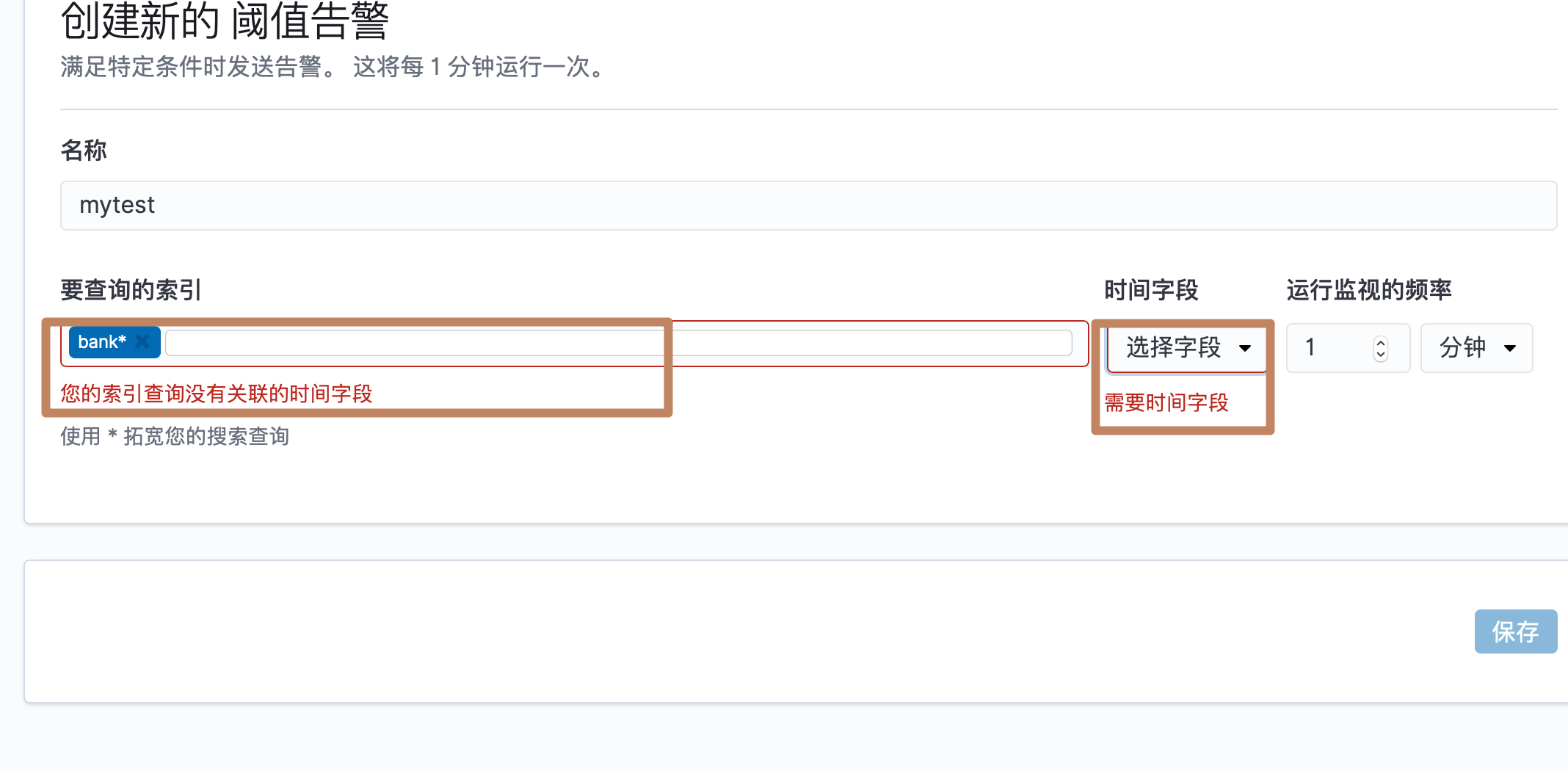
我们选择一个有时间戳的索引
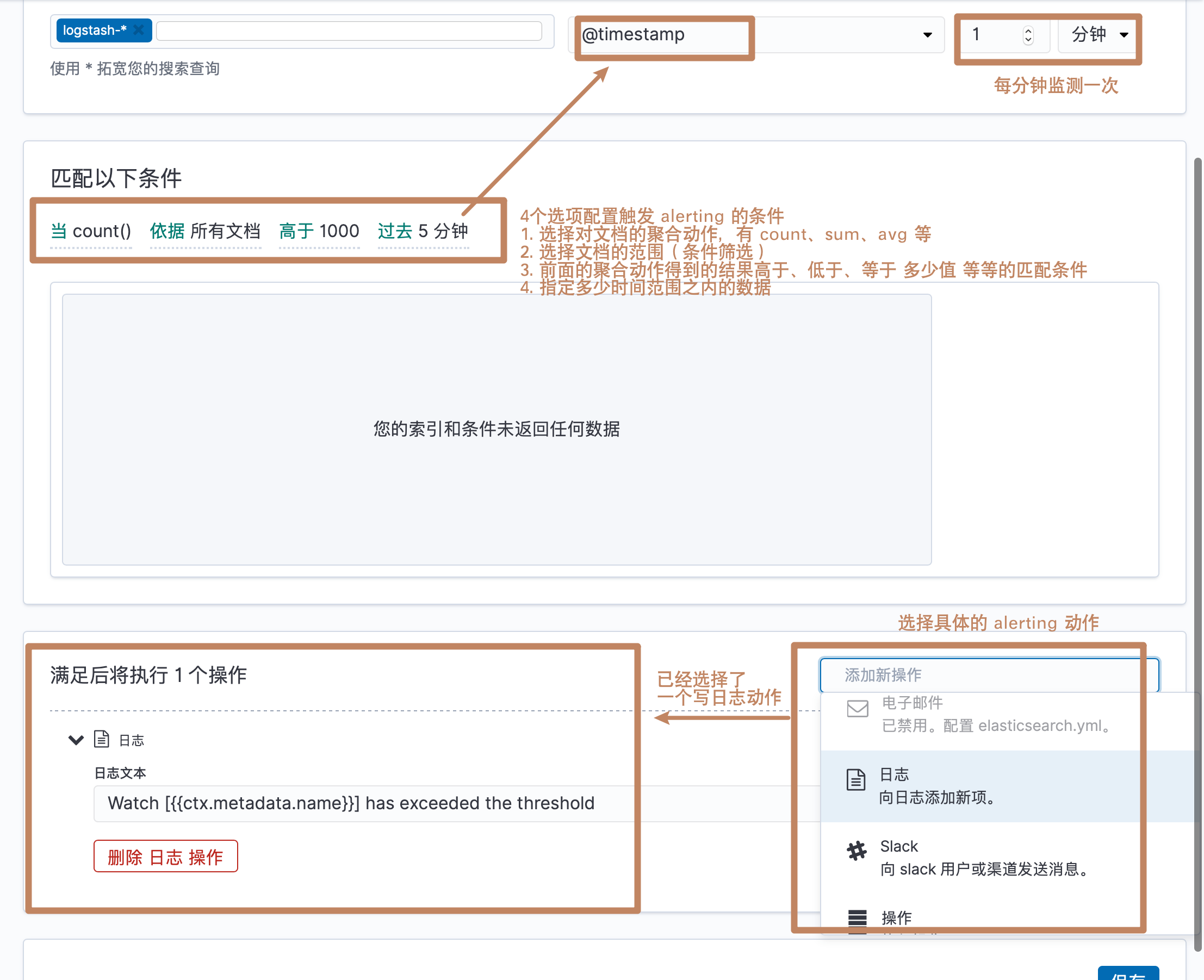
另外我们还能创建一个高级的 alerting,通过一个 JSON 配置,还能点击"语法"来查看具体的参数等等。
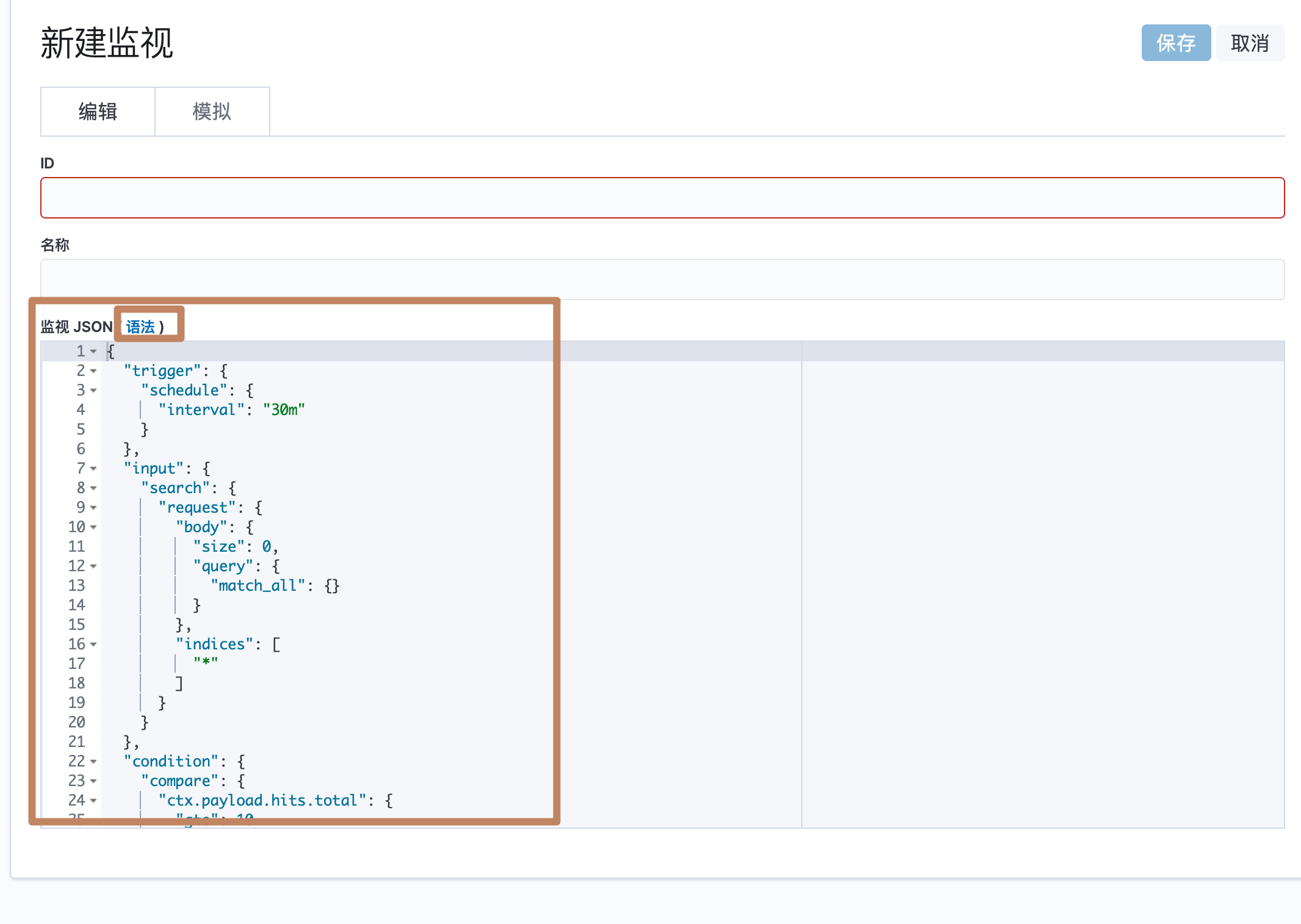
¶<2>用 APM 进行程序性能监控
APM 顾名思义就是 Application Performance Monitoring,是 Elastic 公司开发的一个用来监控应用程序的工具。它提供了以下的监控能力:
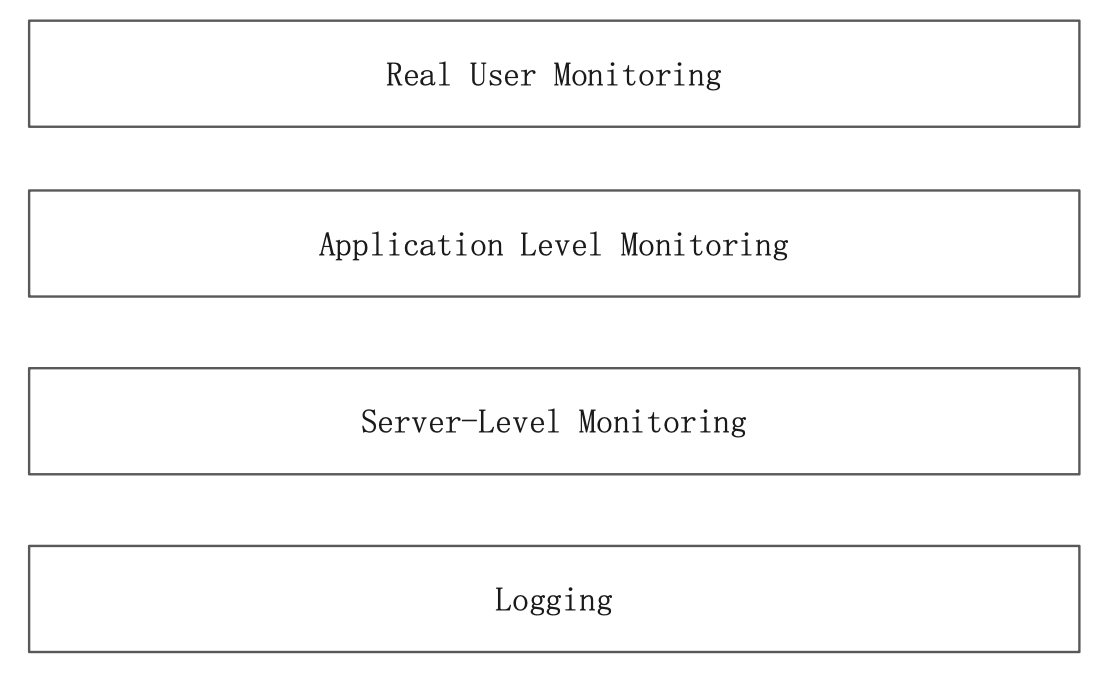
包括用户行为监控、程序级别的监控、服务器级别的监控以及日志监控。
APM 核心功能:请求响应时间监控、未处理的错误及异常监控、可视化调用关系、帮助用户发现性能瓶颈、代码下钻等。
官方网址:https://www.elastic.co/cn/apm
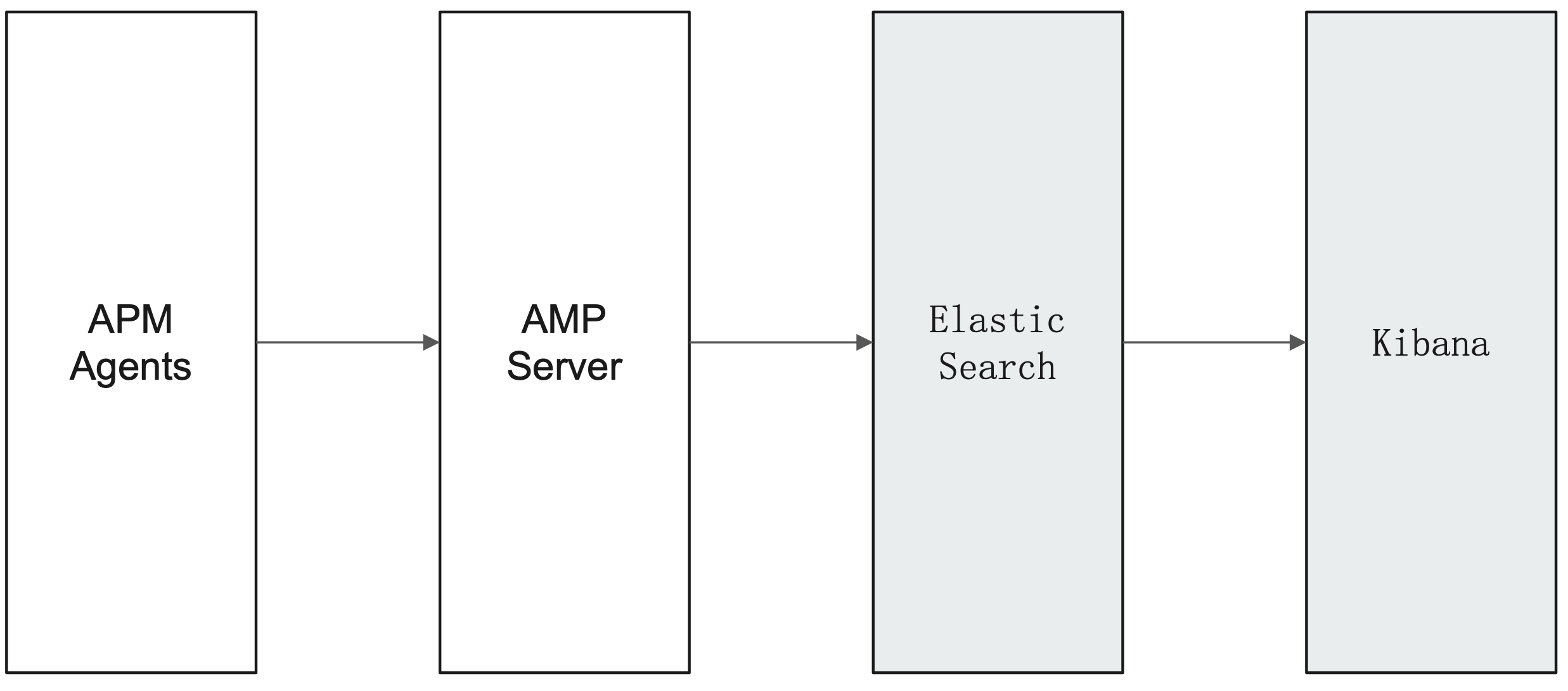
我们可以可以到官网上去查看 APM 的一些详细的信息。它主要是通过一个 APM Agent 内嵌到应用程序中,然后配置 APM Agent的服务端连接信息,APM Agent 就会定时地收集应用程序的一些指标发送到 APM Server,APM Server 负责将收到地数据写入到 Elasticsearch,我们就可以试用 Kibana 来分析这些数据了。
而在 Kibana 中我们可以对应用程序构建出一个很好地可视化组件,并构建自己的专有的 dashboard,另外还可以试用机器学习来监测异常响应时间,还可以通过 Alerting 功能对监测到的异常进行告警。
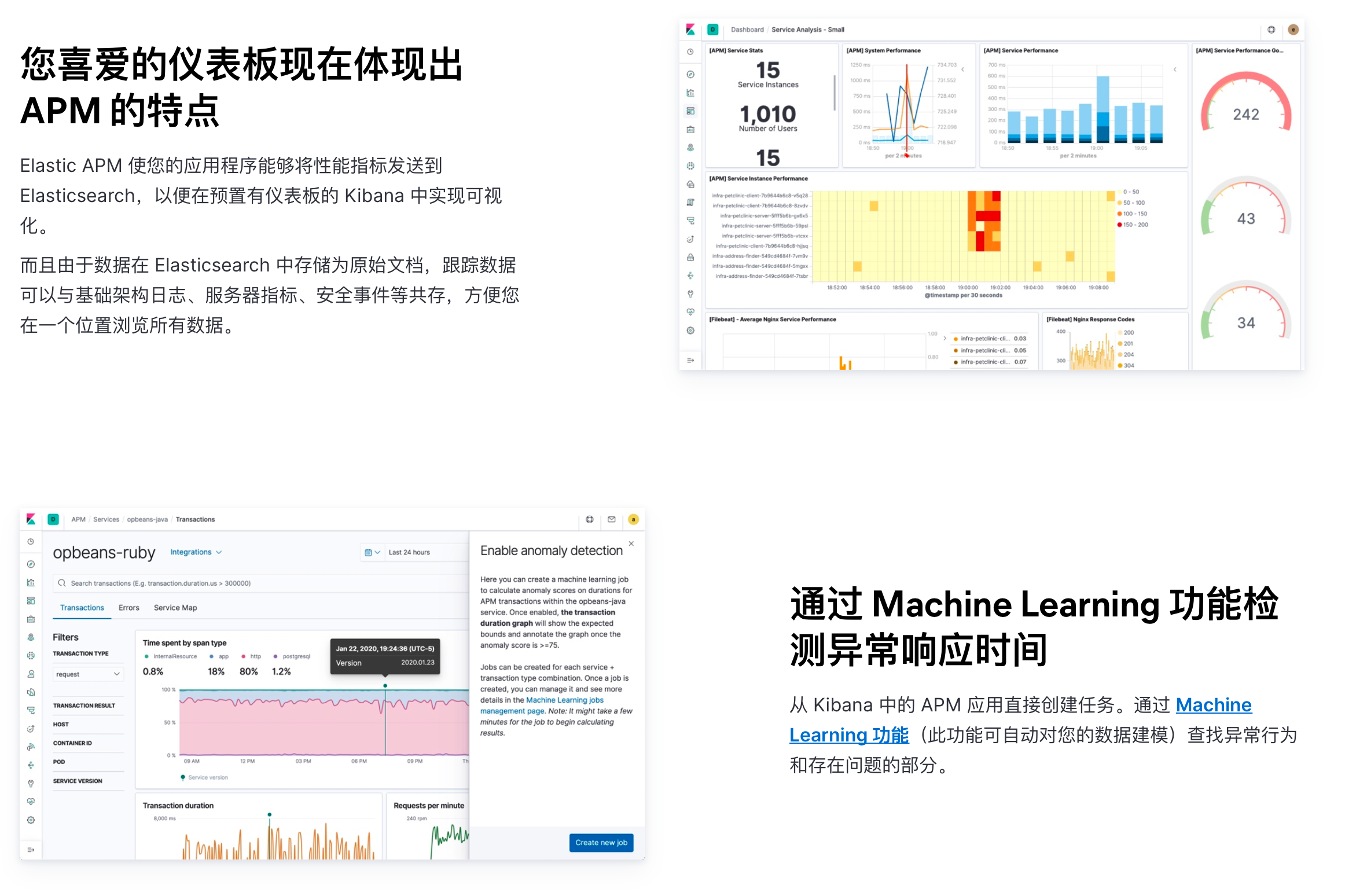

¶APM 的使用
现在我们来看下具体怎么构建一个 Java 程序的 APM 的环境。(详细步骤参考官网的最下面)
¶1、Elasticsearch & Kibana
首先我们在构建 APM 之前保障 Elasticsearch 和 Kibana 服务都已经构建好了。官网中提供了 Hosted 和 Download 的两种不同方案:Hosted 其实指的是我们的 ELasticsearch 和 Kibana 是基于 ELastic cloud 方案构建的;Download 其实指的是我们自己下载了 Elasticsearch 和 Kibana 在自己的服务器中进行了构建。我们选择后者,因为我们已经安转部署好 ES 集群和 Kibana 实例了。
¶2、下载 APM Server 并安装
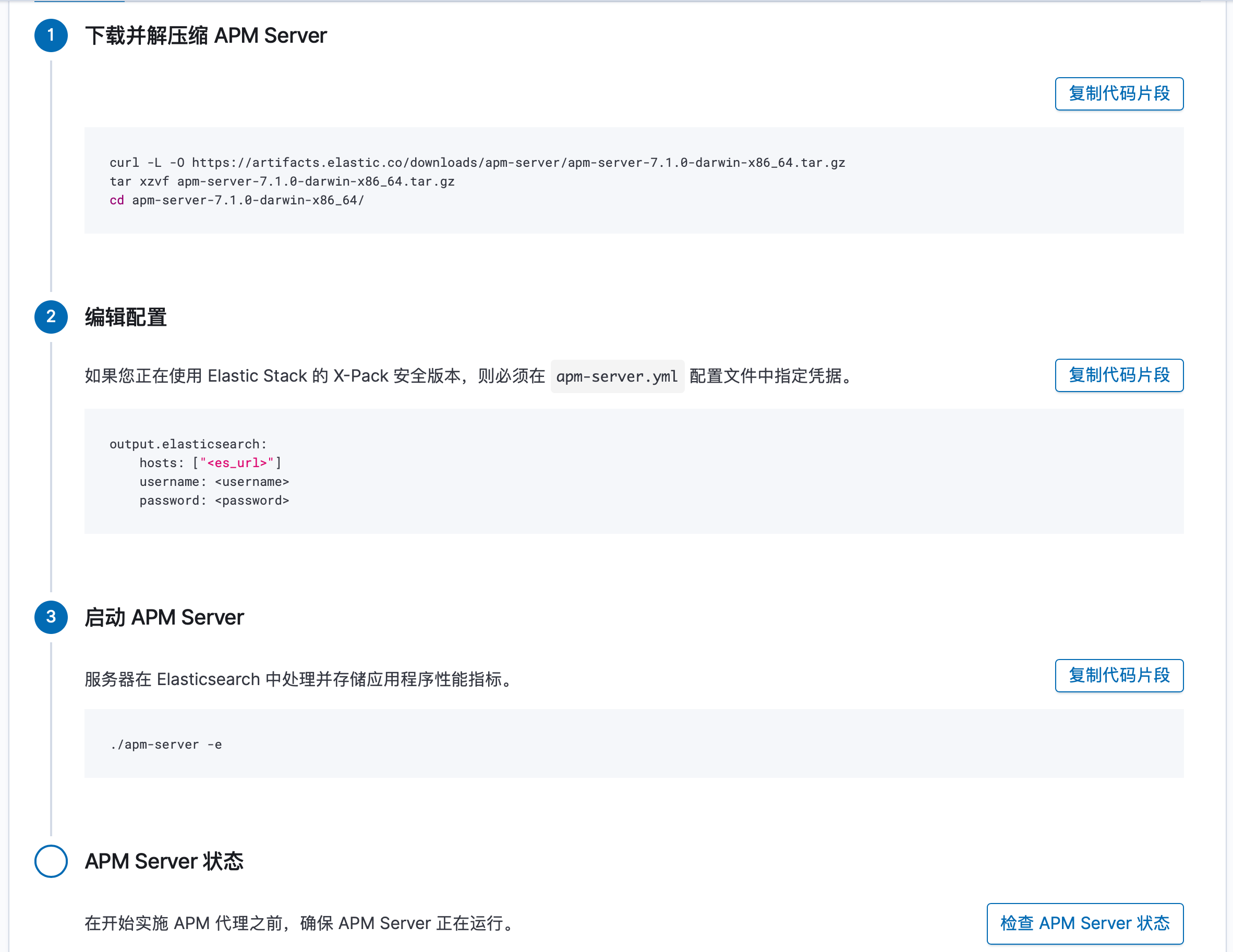
到 链接 中下载对应版本的 APM Server。然后上传到指定服务器,并解压下载下来的压缩包。
[root@izwz920kp0myp15p982vp4z elasticsearch]# cd apm-server-7.1.0-linux-x86_64
如果你的ES 集群(localhost:9200)和 Kibana (localhost:5601)都是是运行在默认的 hosts 上的,那么就无需在apm-server.yml中进行相关配置了,直接启动 apm sever
[root@izwz920kp0myp15p982vp4z apm-server-7.1.0-linux-x86_64]# ./apm-server
然后我们进入 Kibana,点击左边面板中的 APM,进入到 APM 的管理面板,可以看到面板中还没有任何数据,我们点击右上角的"设置说明":
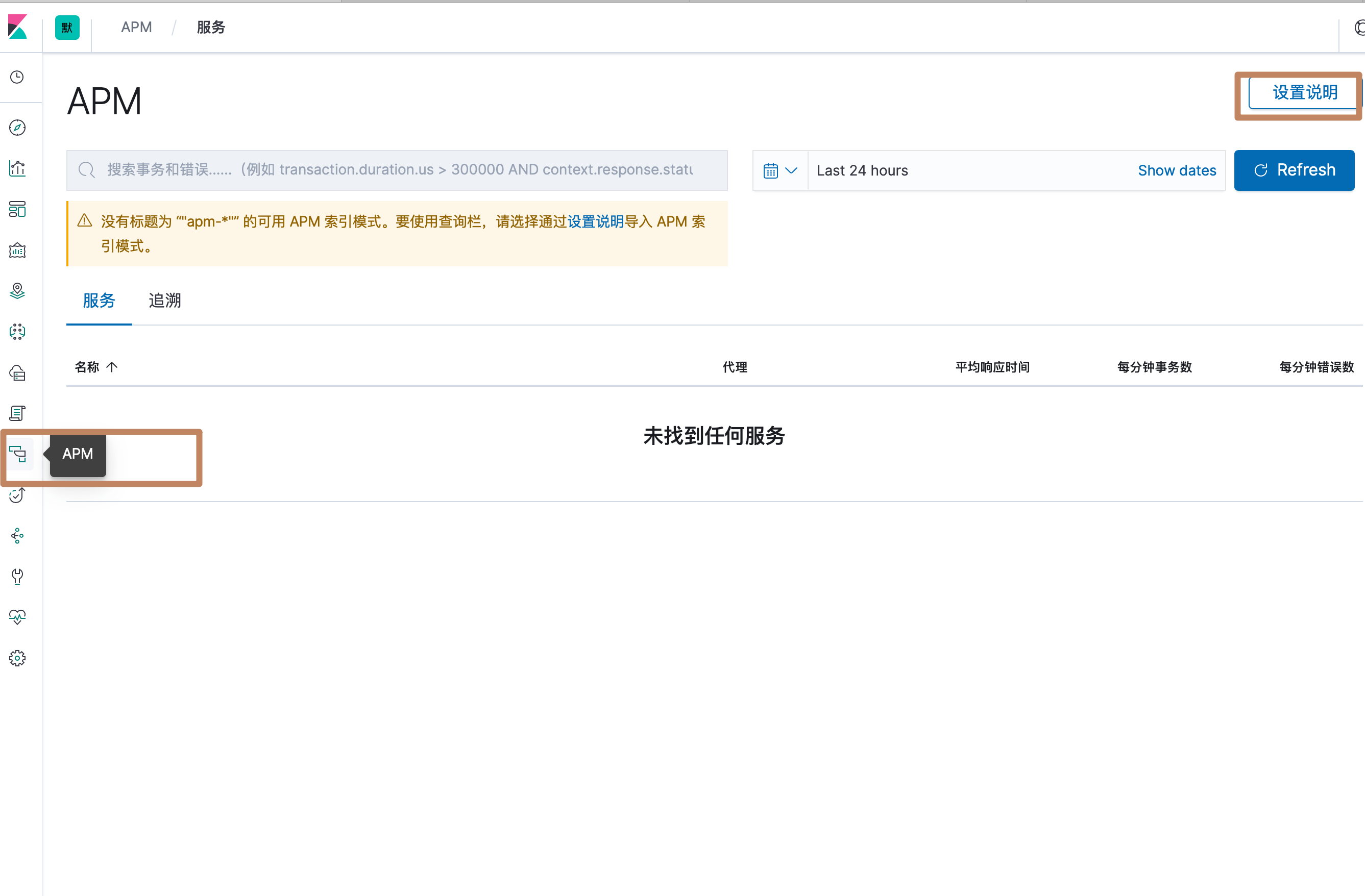
进入到设置说明界面后,可以看到在这里也有关于 APM 服务构建的详细说明,包括我们要先下载 APM Server 并配置后启动,并通过点击"检查 APM Server 状态"来确认 APM Server 是否运行。我们点击检查,可以看到我们的 APM Server 是正常启动的了。

¶3、在应用程序中配置 APM 代理
在上述的 APM Server 正确启动之后,我们下一步就是设置我们的应用程序中的 APM Agent 了,这个在 Kibana 的"设置说明"也是有介绍的:
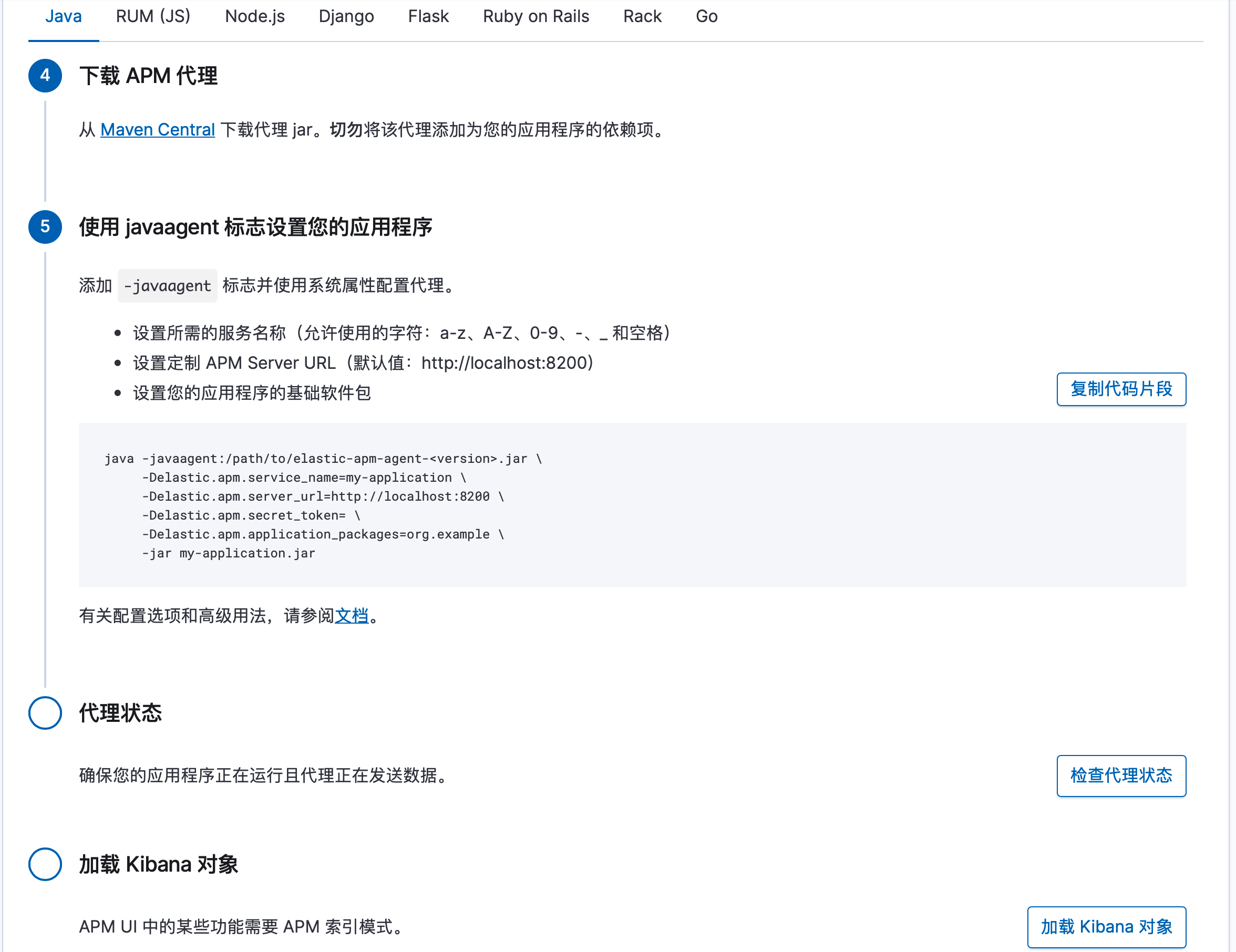
-
首先我们需要从 Maven Central 中下载 APM 的 Java Agent 的 jar 包。
-
启动自己的 Java 应用程序(现在一般都是 spring boot 应用),并添加以下 JVM 参数来分别指定我们下载的 APM Agent jar 包路径、apm的服务名称(应该是在 apm 显示界面中当前启动应用程序的显示名称)、apm服务的连接(就是我们启动的apm 服务)、apm 服务的 token、apm 服务需要监测的Java 程序的包路径:
java -javaagent:/path/to/elastic-apm-agent-.jar \ -Delastic.apm.service_name=my-application \ -Delastic.apm.server_url=http://localhost:8200 \ -Delastic.apm.secret_token= \ -Delastic.apm.application_packages=org.example \ -jar my-application.jar
其他的详细参数可以参考文档。
-
在启动我们的 Java 程序之后,点击"检查代理状态"来查看我们的应用程序是否正常运行并且agent 也正常地工作了(有时候是需要应用程序产生了一次具体地调用才能被监测到代理状态正常)。

-
在监测到代理对象正常工作之后,我们可以试用一些压测工具或者一些测试脚本使得应用程序在产生持续地调用,此时我们再回到 Kibana 的 APM 的界面
 可以看到,在 Services 一栏下面已经有了一个"my_application"的 service,它就是我们刚刚启动的 Java 应用中通过
可以看到,在 Services 一栏下面已经有了一个"my_application"的 service,它就是我们刚刚启动的 Java 应用中通过-Delastic.apm.service_name指定的名称。
我们对其进行点击,就可以进入到这个应用程序监测的详情页面了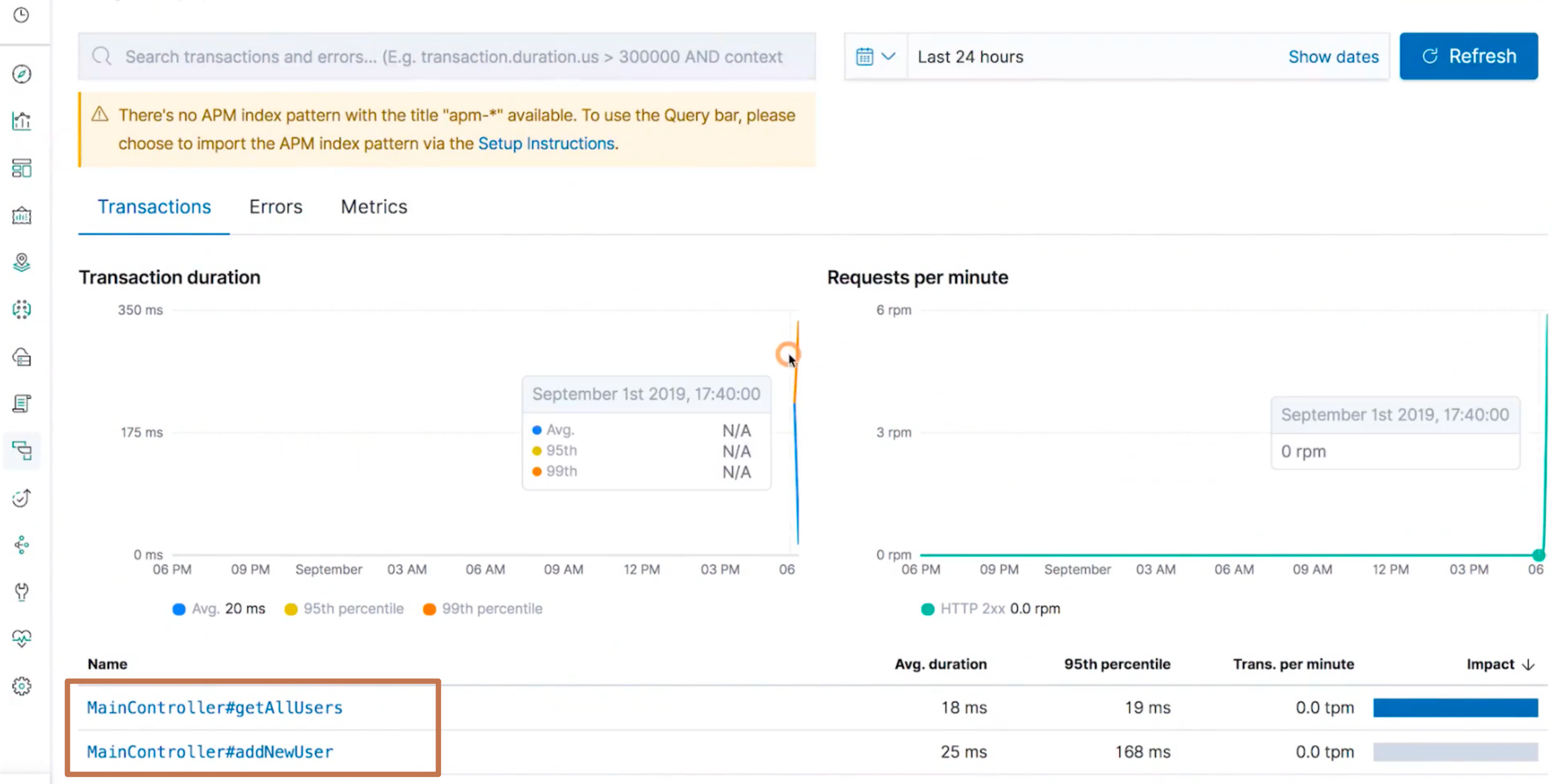 我们可以看到在下面有两个
我们可以看到在下面有两个MainCotroller#getAllUsers和MainController#addNewUser的方法。我们分别点入这两个方法,就可以看到对于这个方法调用的具体监测信息了:
包括一些 transaction 的信息,还有一些请求响应的时间消耗
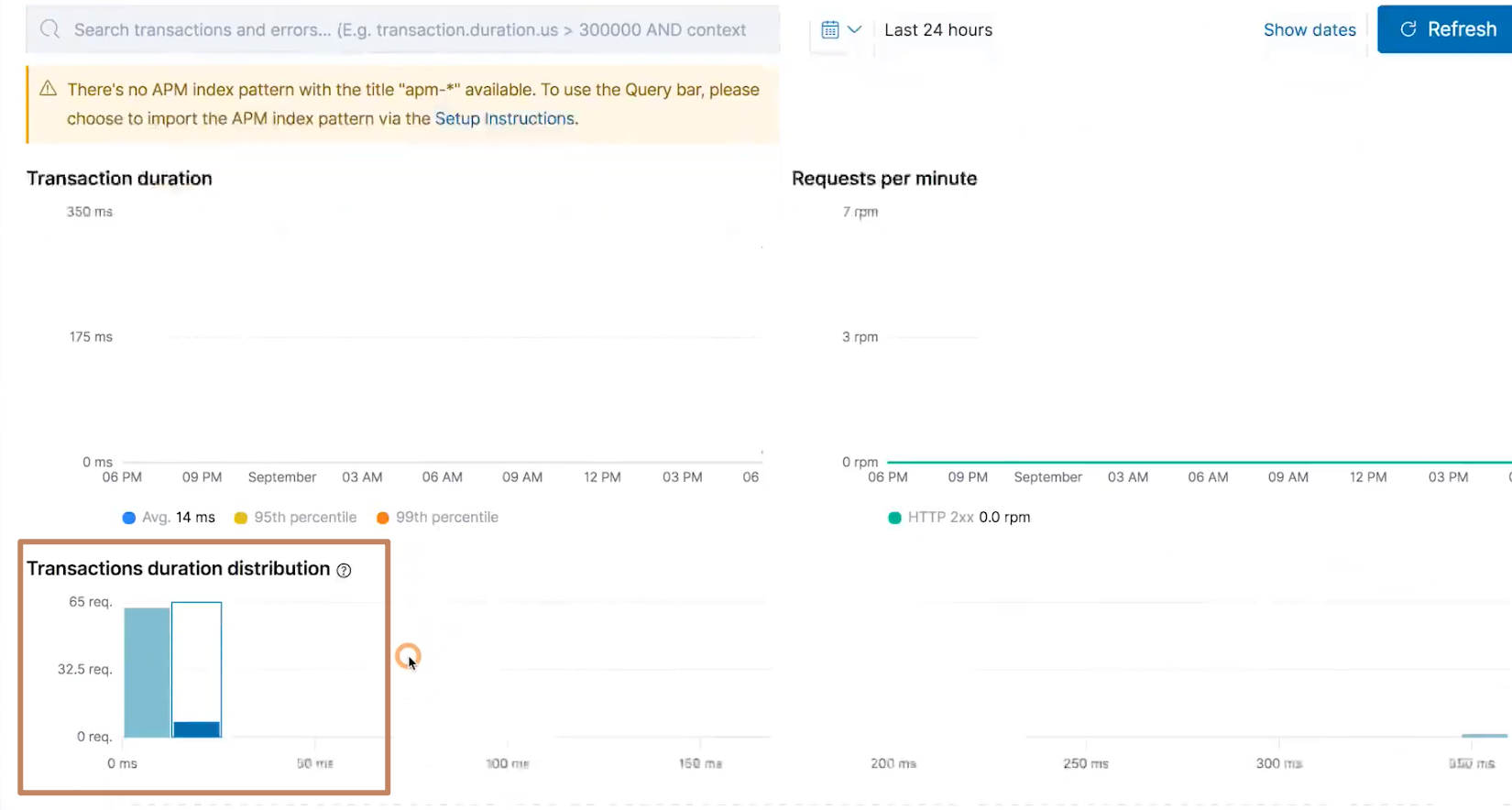
我们看到下面还提供了关于 Transaction 的详细信息,包括整个调用链各阶段的消耗时间以及数据库的一些调用的操作
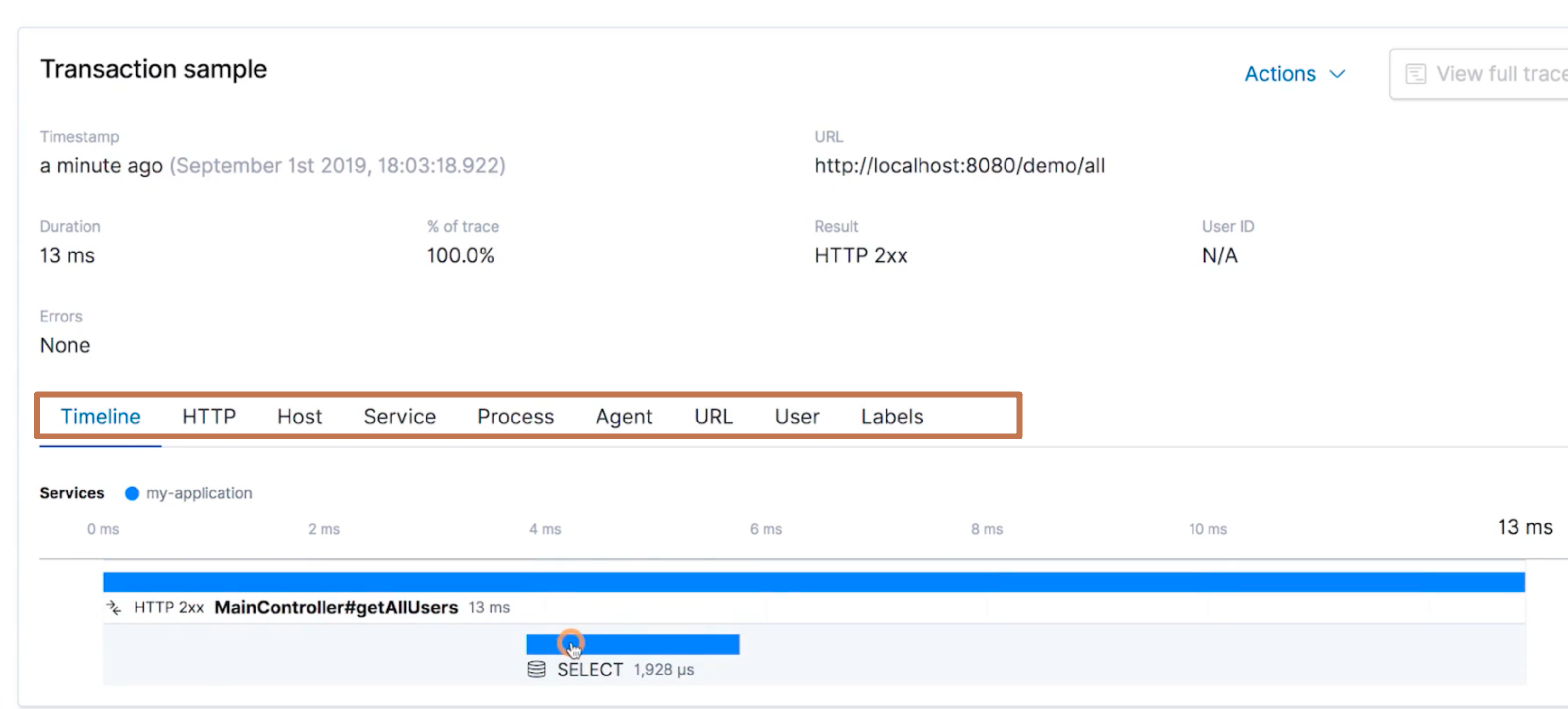
还能查看操作数据库的时候的一些详细的 sql 以及其他信息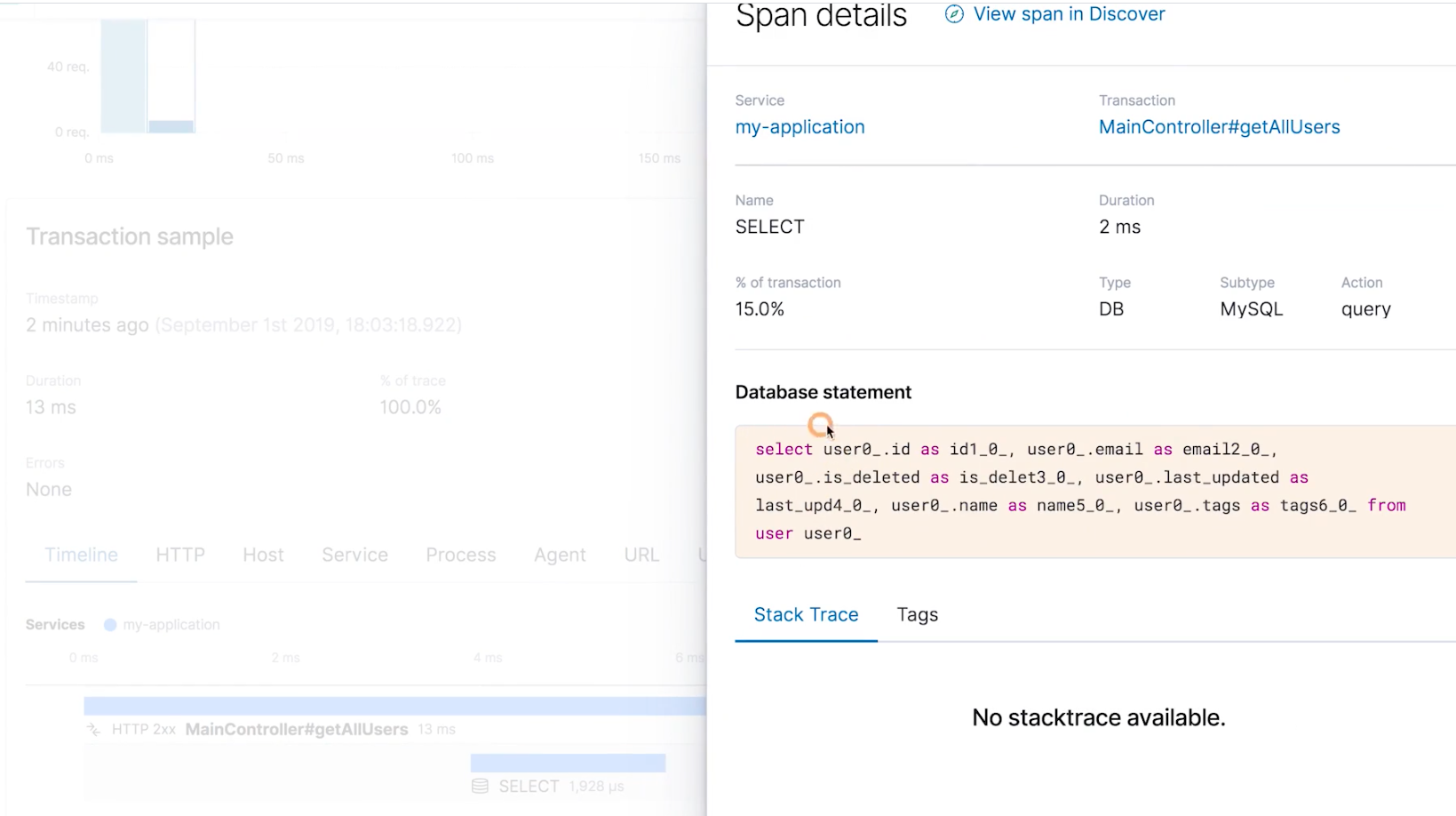
我们还能查看一些 HTTP 的详细信息(包含请求连接、请求头、请求体等)、还有 Service 的一些信息,Process 的信息等等。 -
另外我们还可以在 Kibana 的 APM 面板的最后一行"加载 Kibana 对象"来设置该 APM 相关的 Kibana 对象(可视化组件、dashboard 等)从而构建更好的监测结果展示。
¶4、小结
可以看到,APM 的功能还是很强大的,我们在实际应用中结合一些压测工具就可以很好地对我们的程序进行一个压力测试的操作。另外,对于 Java 应用程序来说,最近比较火的一个链路跟踪组件是 SkyWalking,以后有机会可以比较一下。
¶<3>用机器学习实现时序数据的异常检测
X-Pack 中的收费功能。它的应用场景就是去解决一些基于规则或者使用 Dashboard 难以实时发现的问题。
- 在 IT 运维领域,如何知道系统正常运行、如何自动调节阈值触发合适的报警、当问题发生的时候如何进行归因分析。
- 在信息安全领域,我们也想及时地知道哪些用户构成了威胁、系统是否感染了病毒。
- 在物联网领域,很多时候我们需要管理很多的设备,我们怎么得知工厂和设备是否正常运营,如何发现设备中的潜在问题。
以上场景当中,机器学习都能帮助我们实现我们的工作,及时发现一些问题。
我们先看两个基础概念:正常和异常。
¶正常
正常主要分下面两种情况:
- 随着时间的推移,某个个体一直表现出一致的行为
- 某个个体和他的同类比较,一致表现出和其他个体一致的行为
¶异常
异常主要分为下面两种情况:
- 和自己比:个体的行为发生了急剧变化
- 和他人比:个体明显区别于其他的个体
下面是两个异常的例子:

上面的两个异常的例子都是很好的识别的,但是有一些异常的例子却需要一定的指导才能发现:

参考上图,如果没有给出具体的指标我们是很难得出哪条狗是不正常的,如果我们说不吐舌头是正常,吐舌头是异常,那么就可以得出一个结果;如果我们说站着是正常的,坐着是异常的,那么也可以得出一个结果。
¶相关术语
机器学习是可以被运用到非常多的领域的,包括人脸识别等等,而Elastic 平台的机器学习功能主要针对时序数据的异常检测和预测。
Elastic 平台的机器学习是非监督机器学习,即不需要使用人工标签的数据来学习,仅仅依靠历史数据自动学习;同时它使用的还是贝叶斯统计方法,这是一种概率计算方法,使用先验结果来计算现值或者预测未来的数值。
在异常检测方面,异常代表的是不同的,但未必代表的是坏的(例如在双十一大促的时候订单量暴增,这在业务上是一件好事,但是此时系统和之前的状态是有着明显的不同的);另外定义异常需要一些指导,从哪个方面去看(例如上面狗的例子)。
¶如何学习"正常"
我们观察正常可以从两个方面进行,一个是将现在的自己和过去的自己进行比较,另一个是将自己和群体中的其他个体进行比较。
举个例子,观察不同的人每天走路的步数,由此预测明天他会走多少步,但是观察不同的人,我们需要定义一个观察的时间,是一天、一周、一个月、一年还是十年,这个根据具体的业务情况来定。当然观察的数据越多,预测理论上是越准的。
这时候我们使用这些观察来创建一个模型,它其实是一个概率分布的函数,通过这个模型找出一些低概率出现的事件,其实它就是一个异常。
而机器学习就是帮助我们自动挑选模型,使用成熟的机器学习技术,挑选适合数据的更好的、更正确的统计模型。更好的模型等于更好的异常检测等于更少的误报和漏报。
¶模型与学习周期
我们在选择学习周期的时候需要尽量选择合适的周期,不然如果时间太长,会涉及到一些不需要的影响因素加入进来,导致结果的不准确;如果学习时间太短,结果也是过于"随机",不准确。
¶ES 机器学习Demo
ES 提供了以下机器学习:

¶single metric
-
来到 Kibana,点击左边面板中的 Machine Learning,然后点击右边的"创建新作业"按钮
-
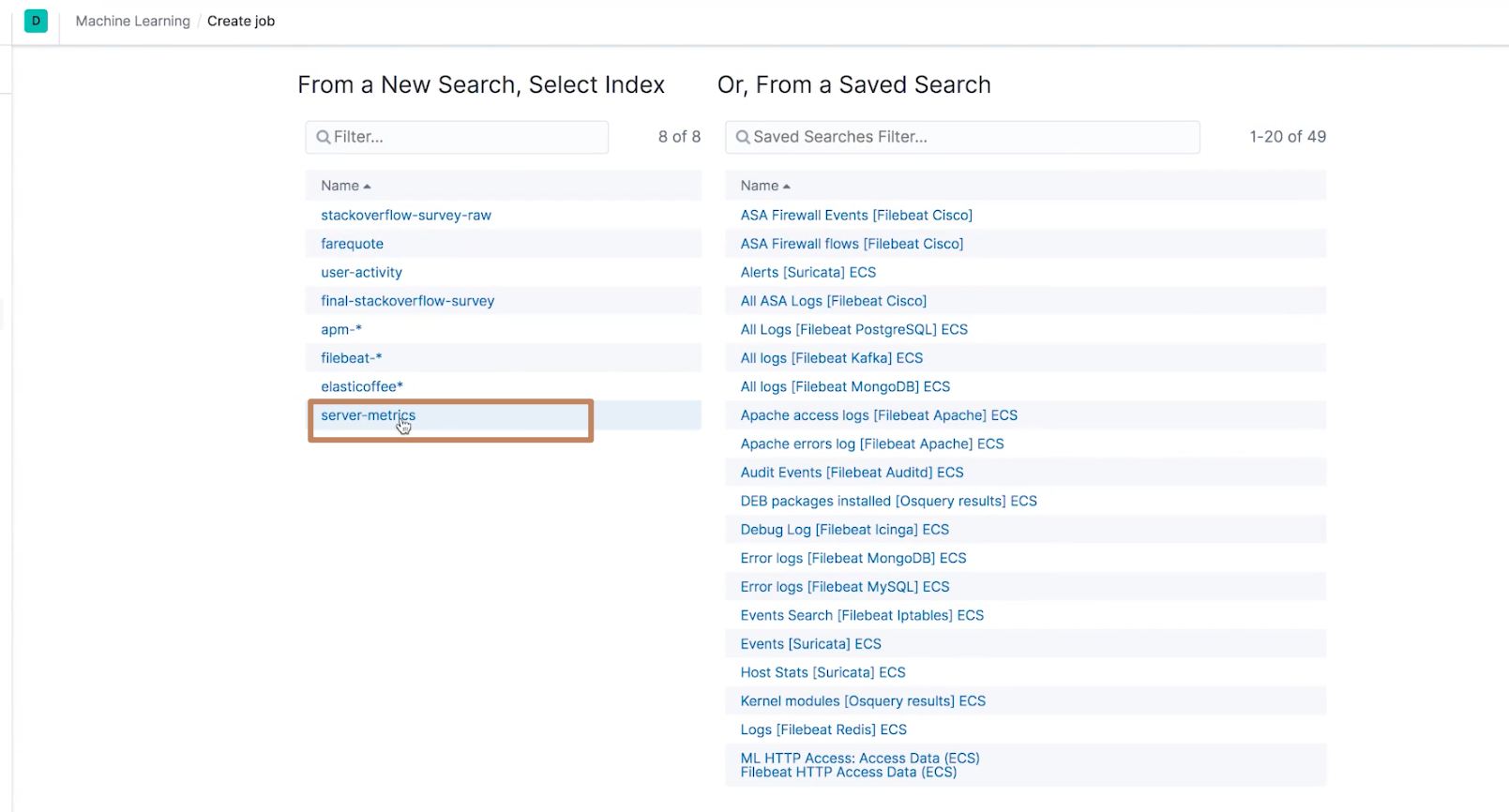
选择我们要进行机器学习的 index pattern,我们选择"server-metrics"
然后再选择 single metric

进入到以下界面之后,我们进行如界面中的设置
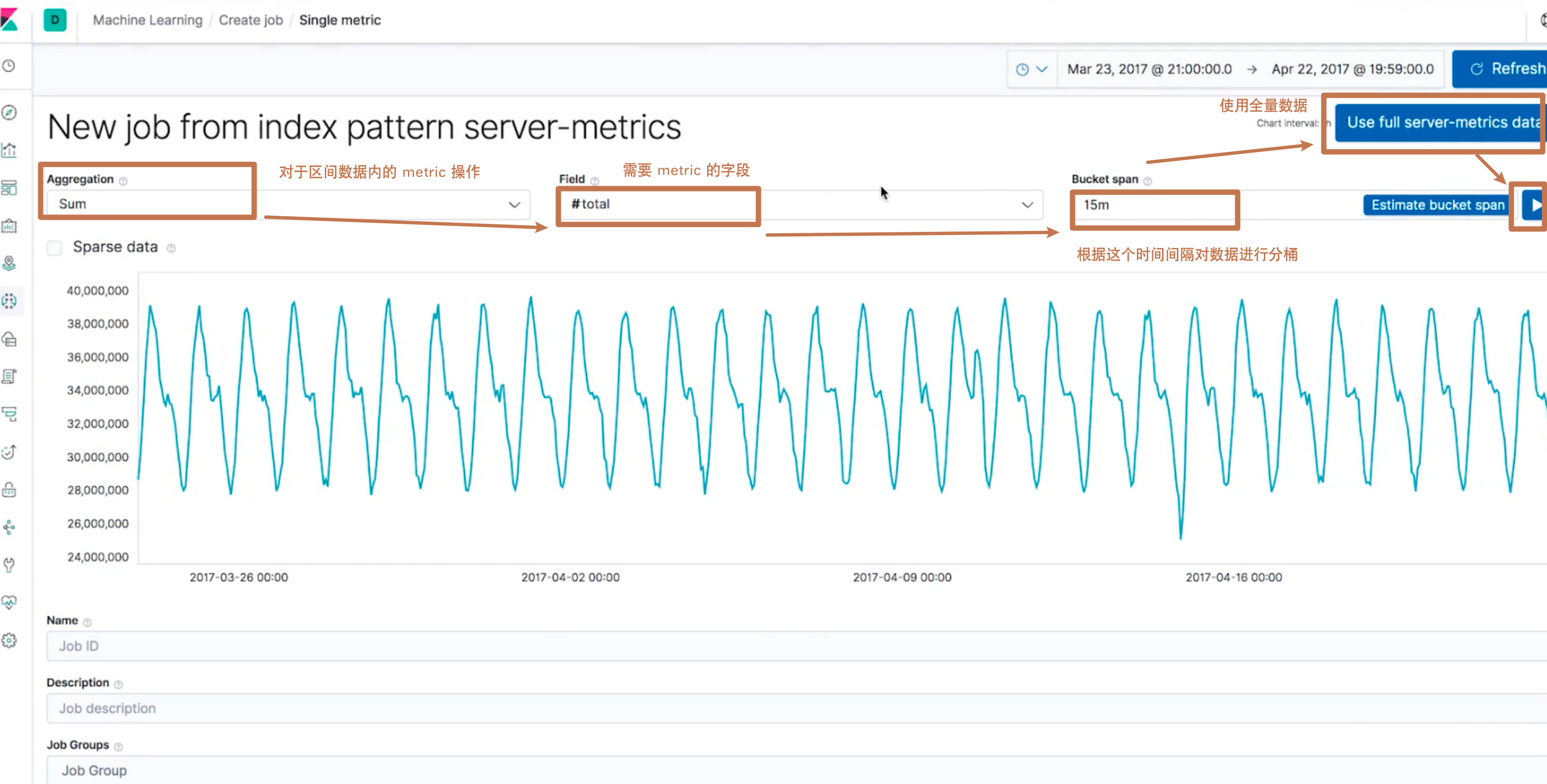
这几个字段的意思是,该机器学习算法会对索引"server-metrics"全量数据做以下操作:每隔15分钟之内的数据取出来然后对 total 字段进行求和,然后将所有的间隔内数据的该字段之和来求出一个我们前面提到的概率分布函数模型,得出概率低的值,那么这些概率低的值对应的区间以及区间的数据就会被认为是"异常"的。 -
然后我们输入作业的名称,并选择创建作业
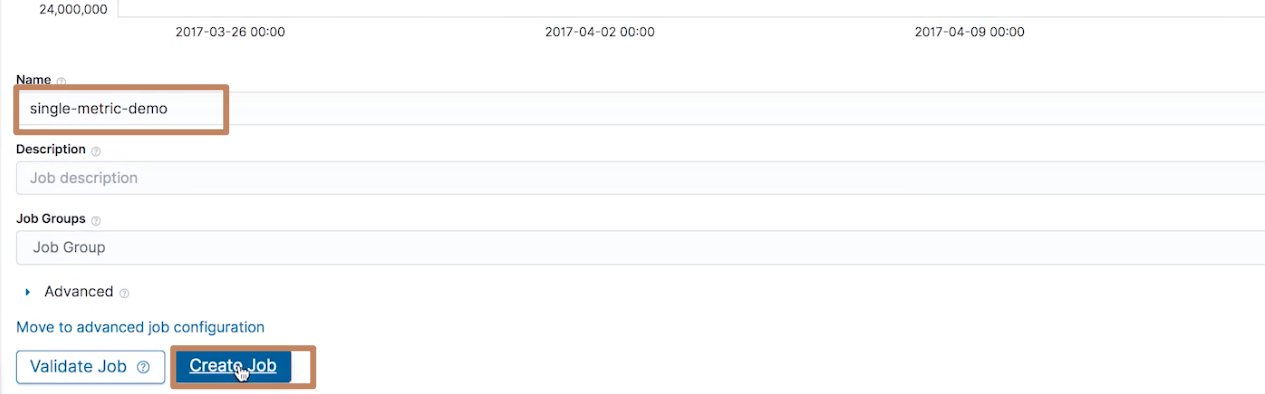
这时候我们就可以看到 Elasticsearch 就会在后台帮助我们在计算了
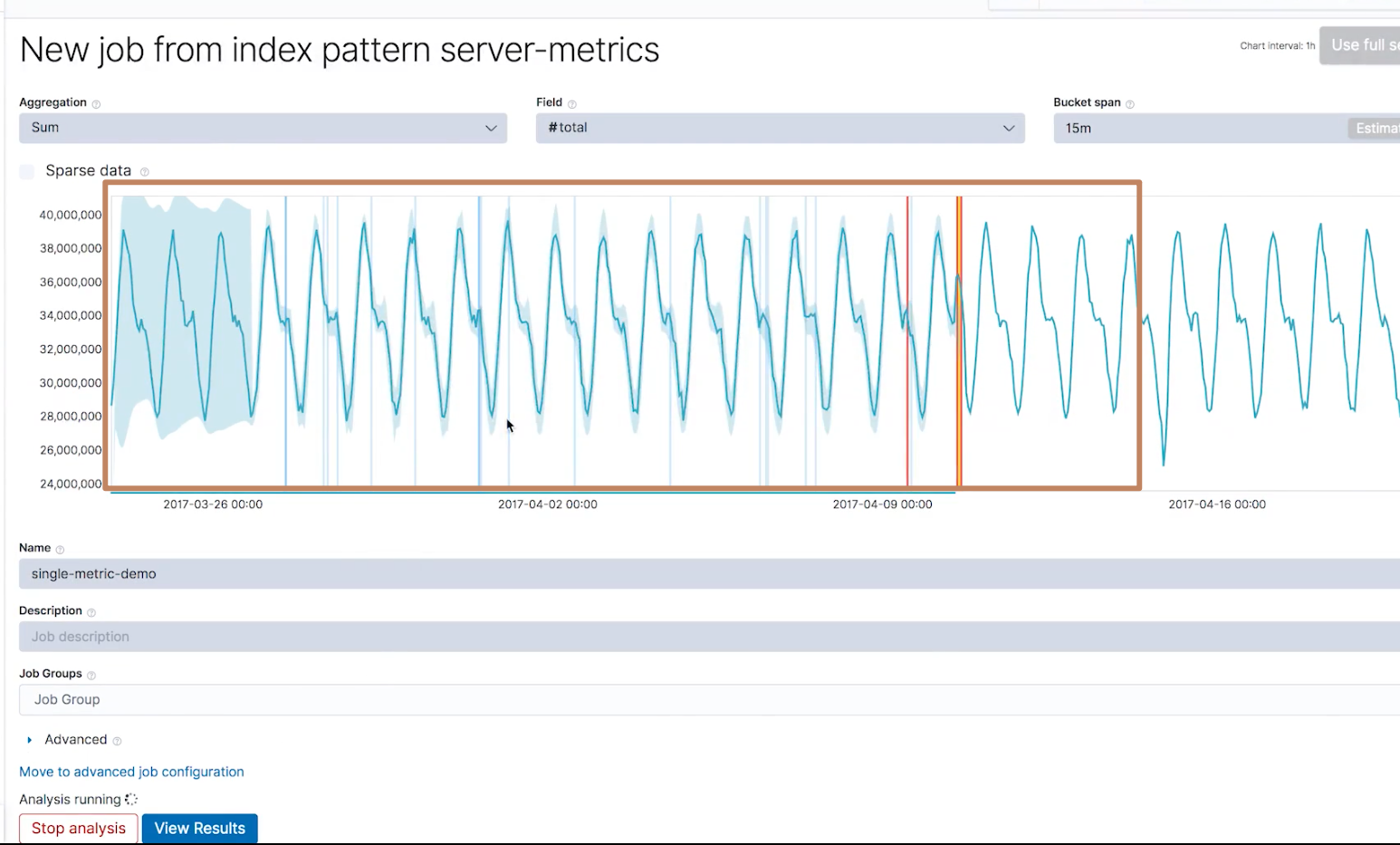
很快我们就能得到一个结果,点击 view result
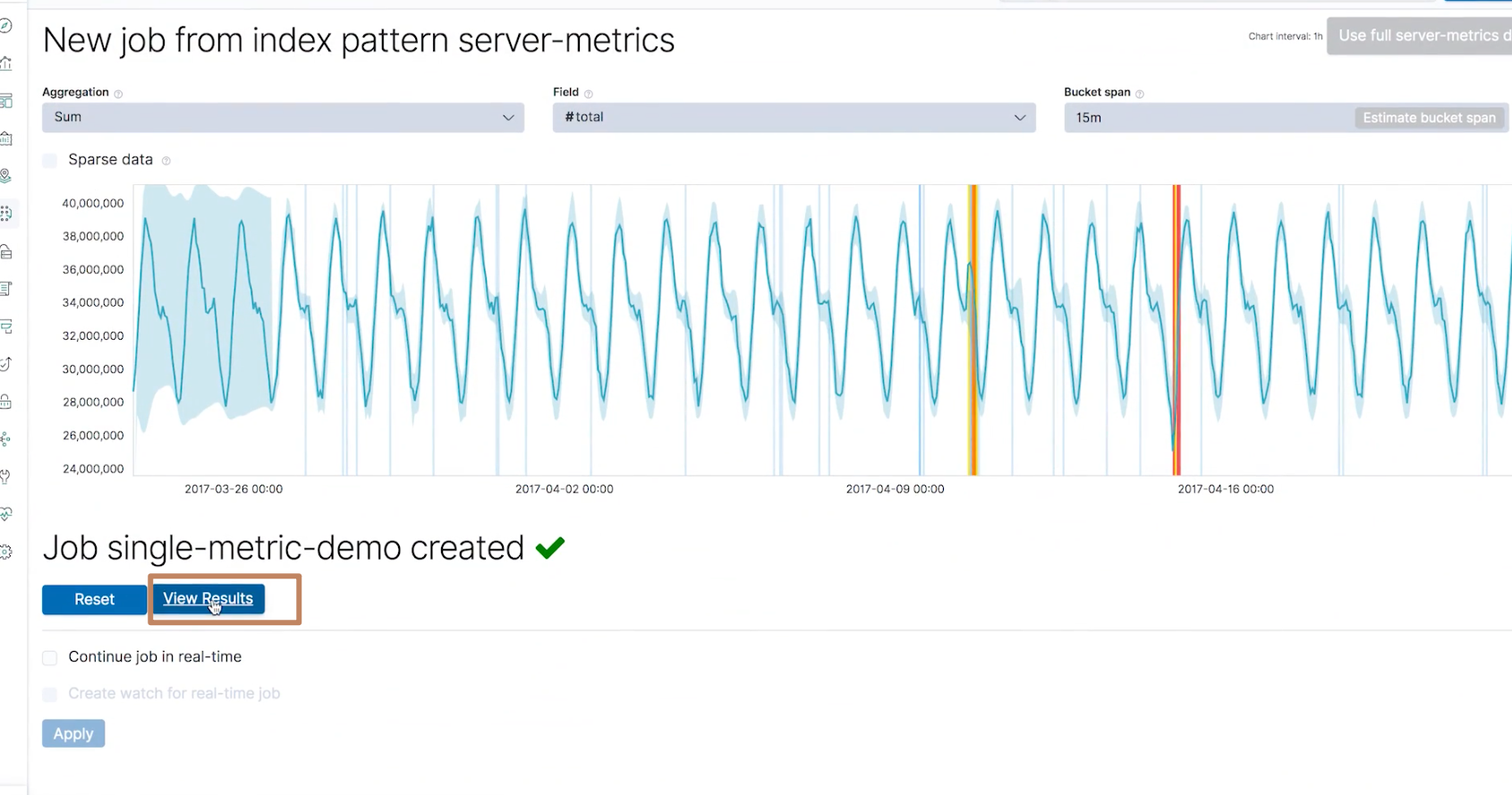
这时候我们就能得到一个时序图,时序图分为了两部分,上面较宽的部分显示的是"放大图",下面较窄的显示的是"缩略图",我们可以通过扩大缩小"缩略图"中的一个窗口来确定"放大图"中的内容。
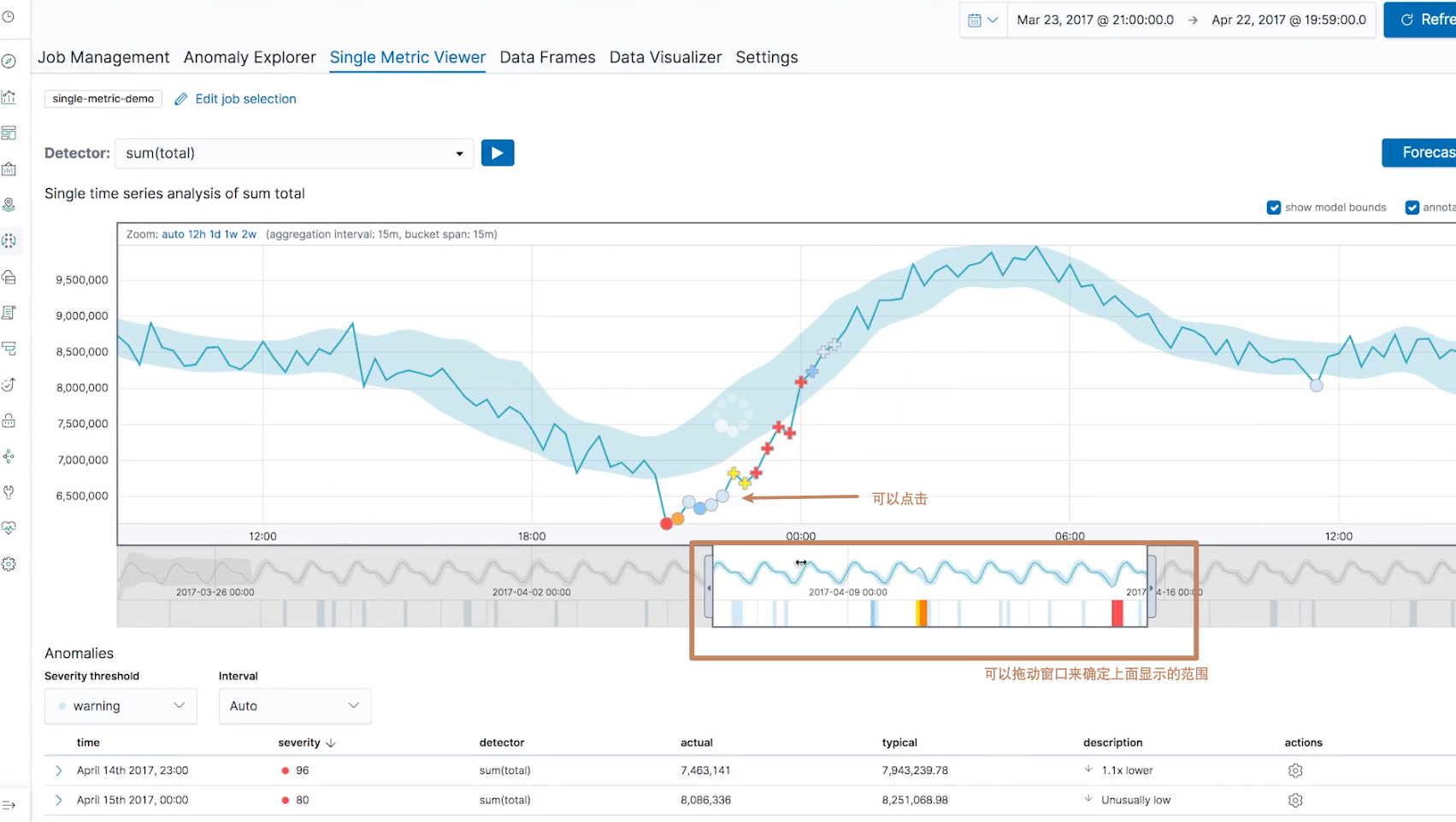
我们也可以点击界面上的每一个点,它们都代表一个异常的点
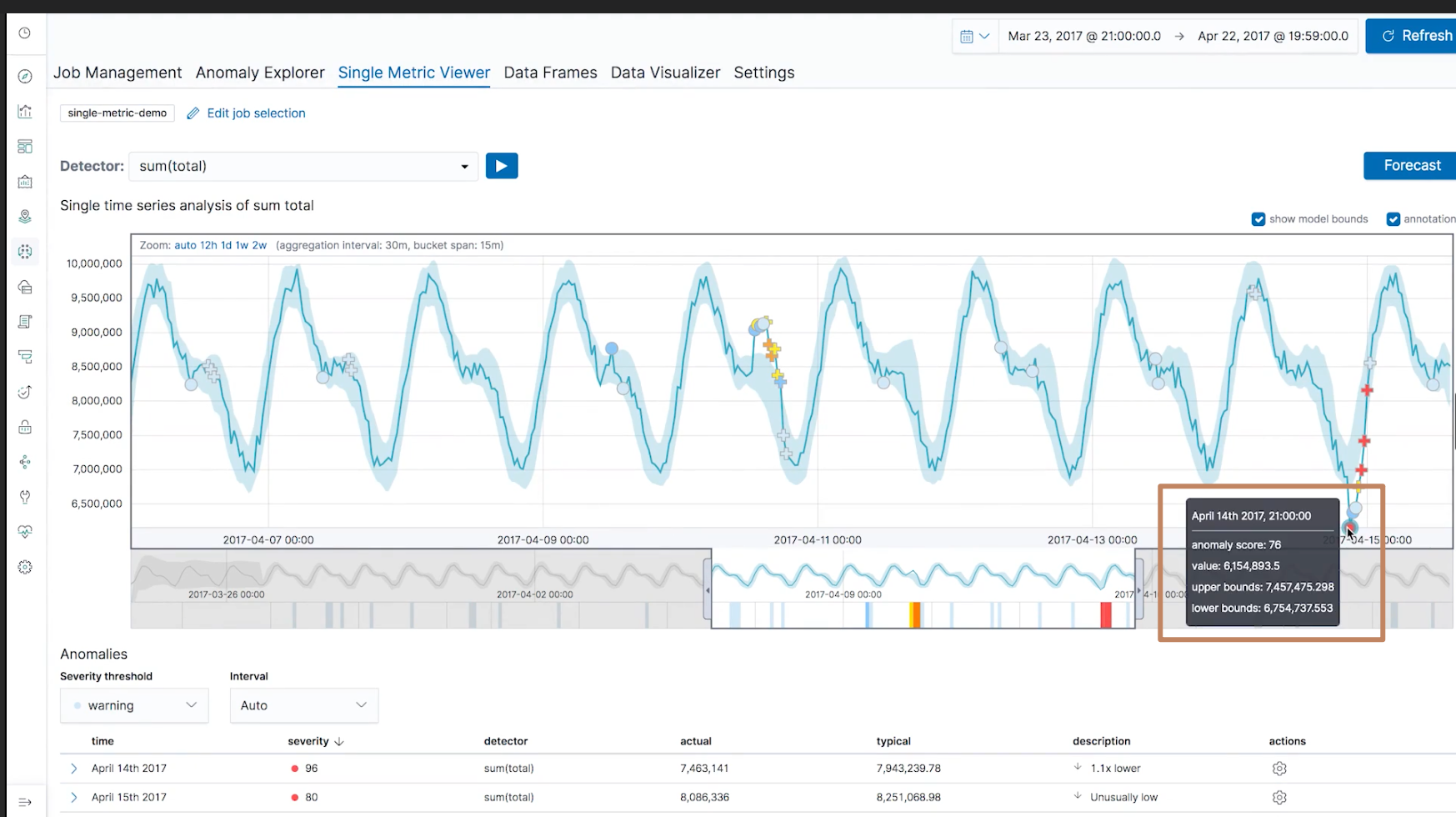
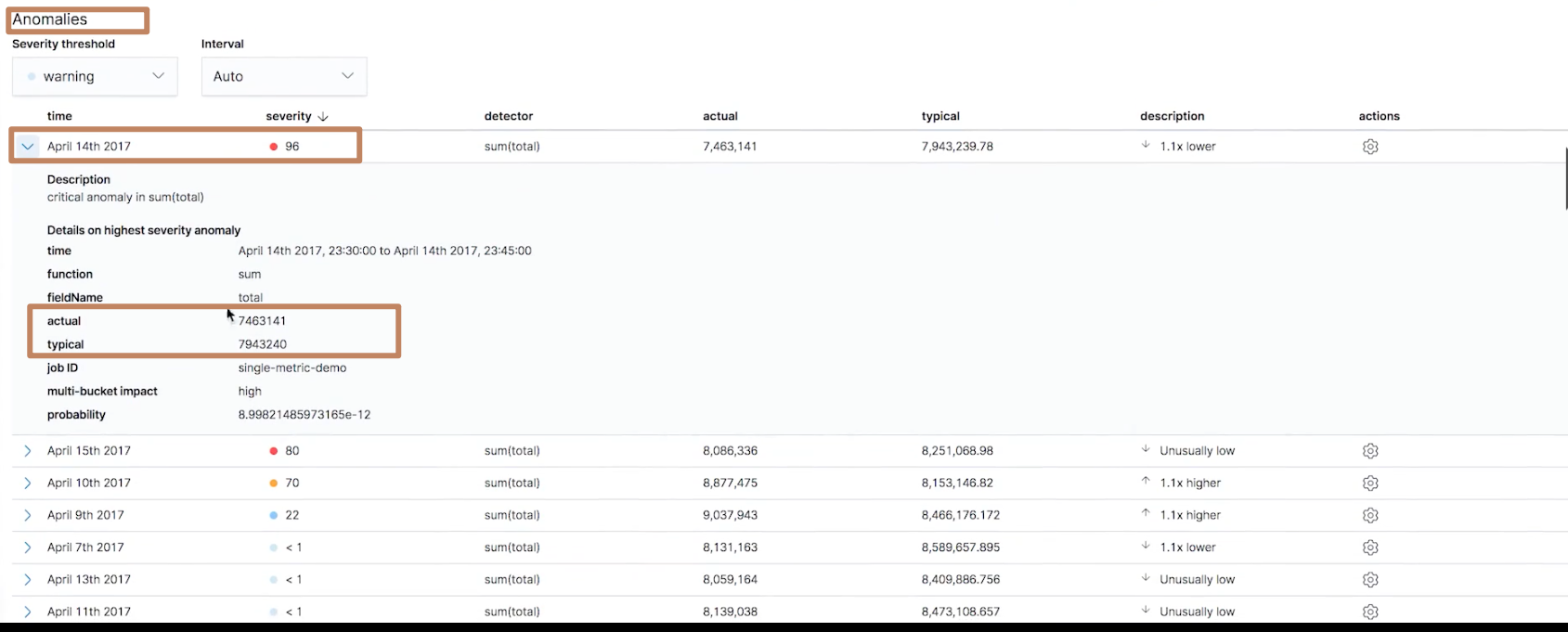
同时在下面的 Anomalies 的模块中也显示了所有异常的点,按照异常的"程度"进行优先排序。我们点开其中一个点的详细信息,可以看到这个区间数据的具体情况,包括它和"正常"的值(total 字段的求和)的差距
-
另外在右上角还有一个 forecast 的按钮,我们可以点击它使得 ES 的 ML 对于现有模型对未来的数据进行预测,我们预测2天的数据:
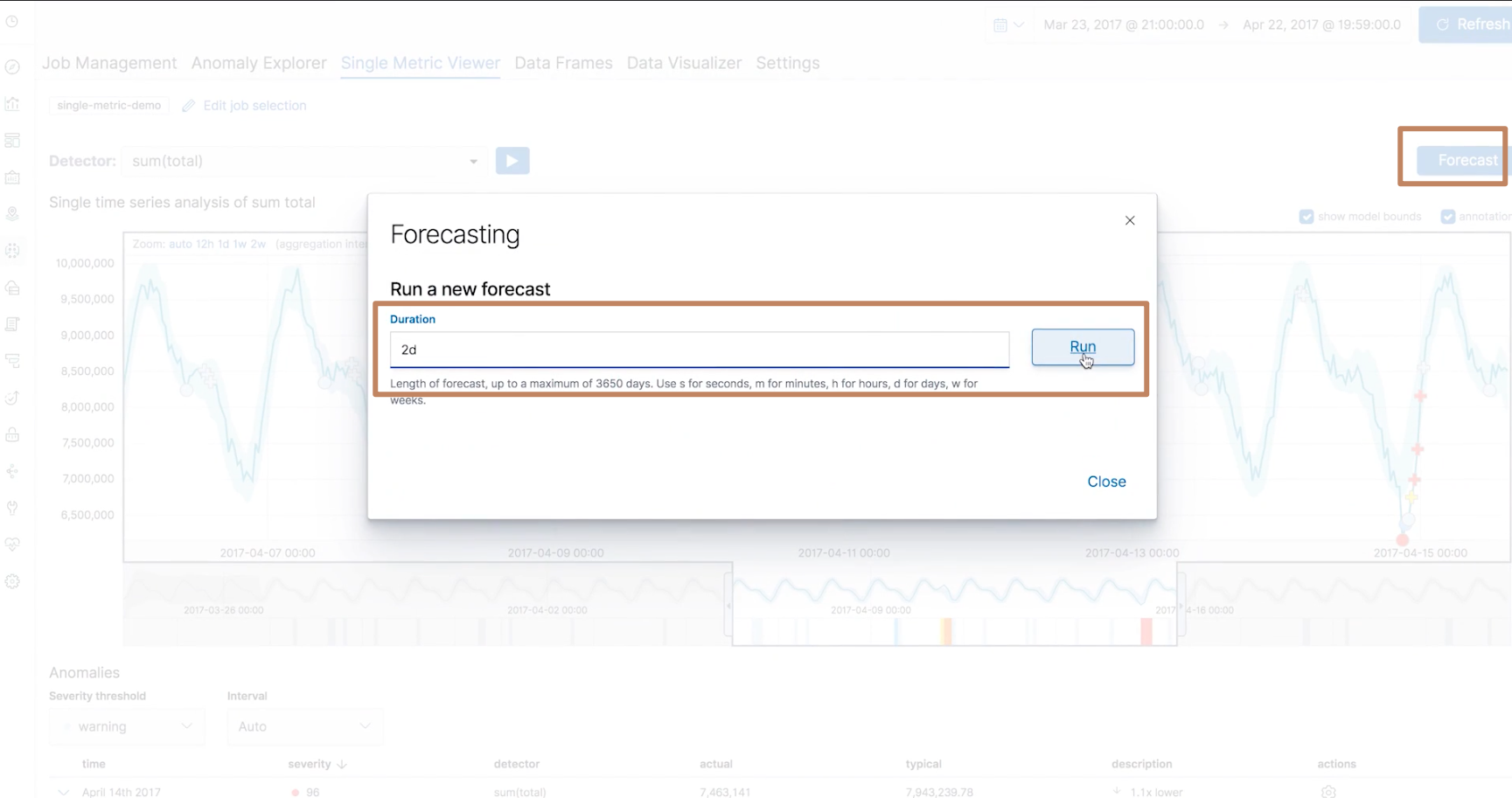
可以看到,ES 给我们算出了未来2天的曲线(另外我们还可以通过勾选上面的3个 checkbox 取消或者显示其对应的内容的显示)
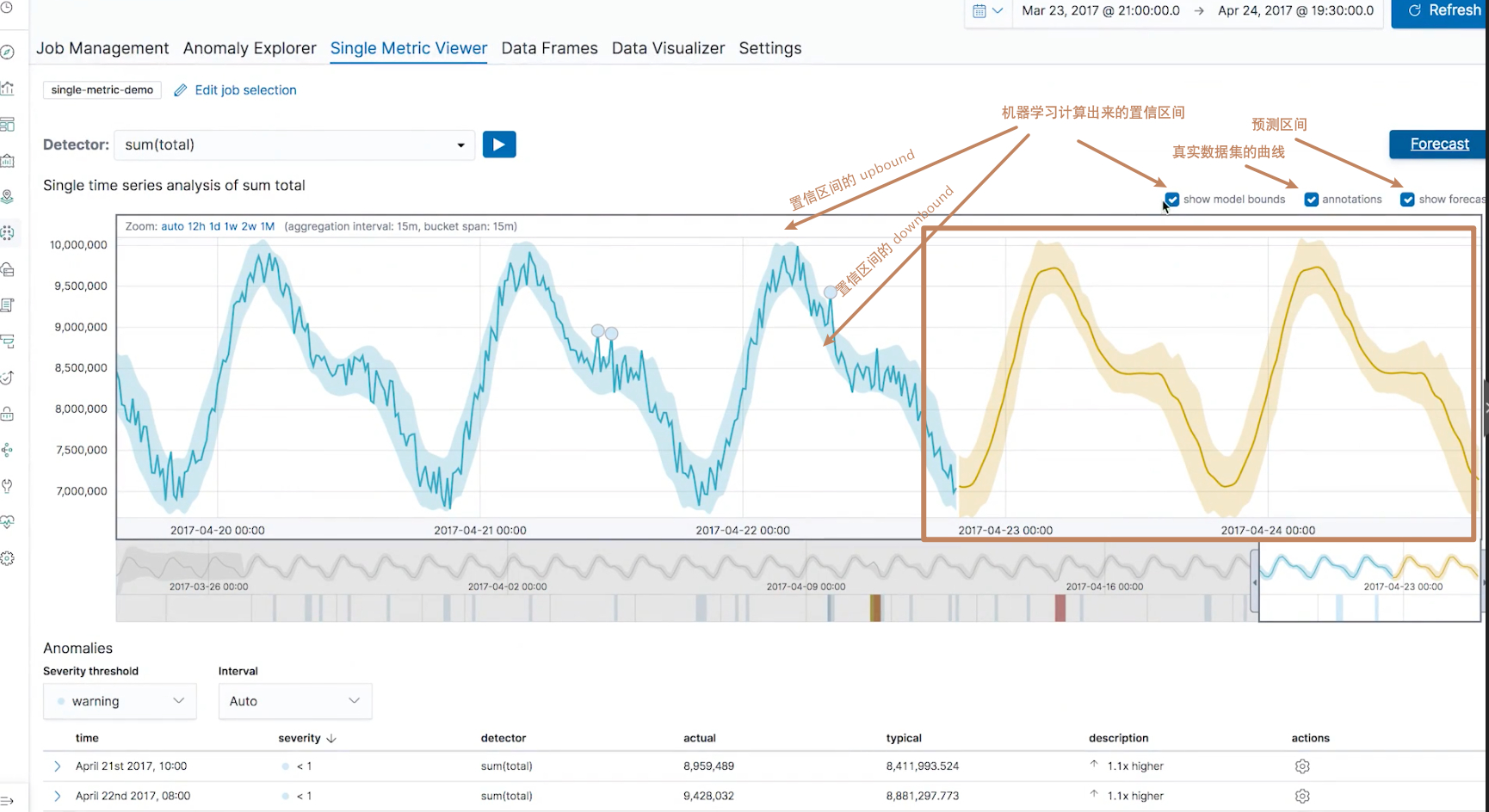
-
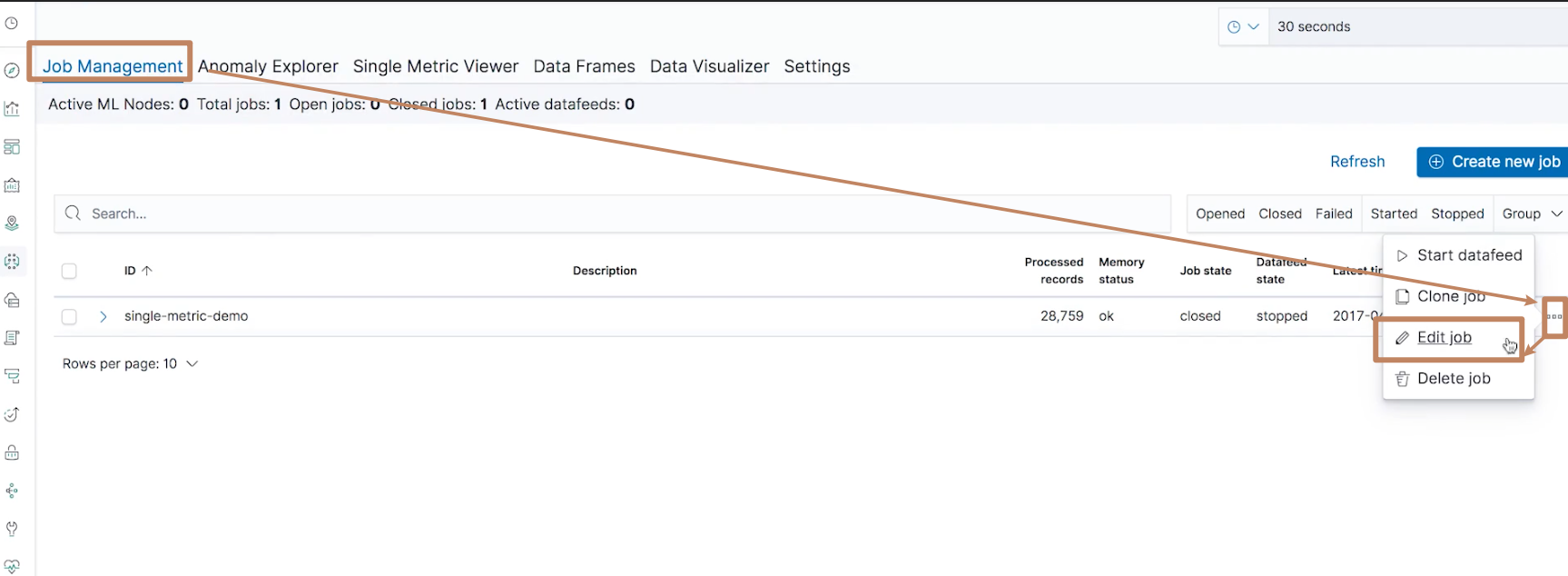
点击"Job Management"回到 ML 的界面,我们通过以下动作进入到 job 的定制界面
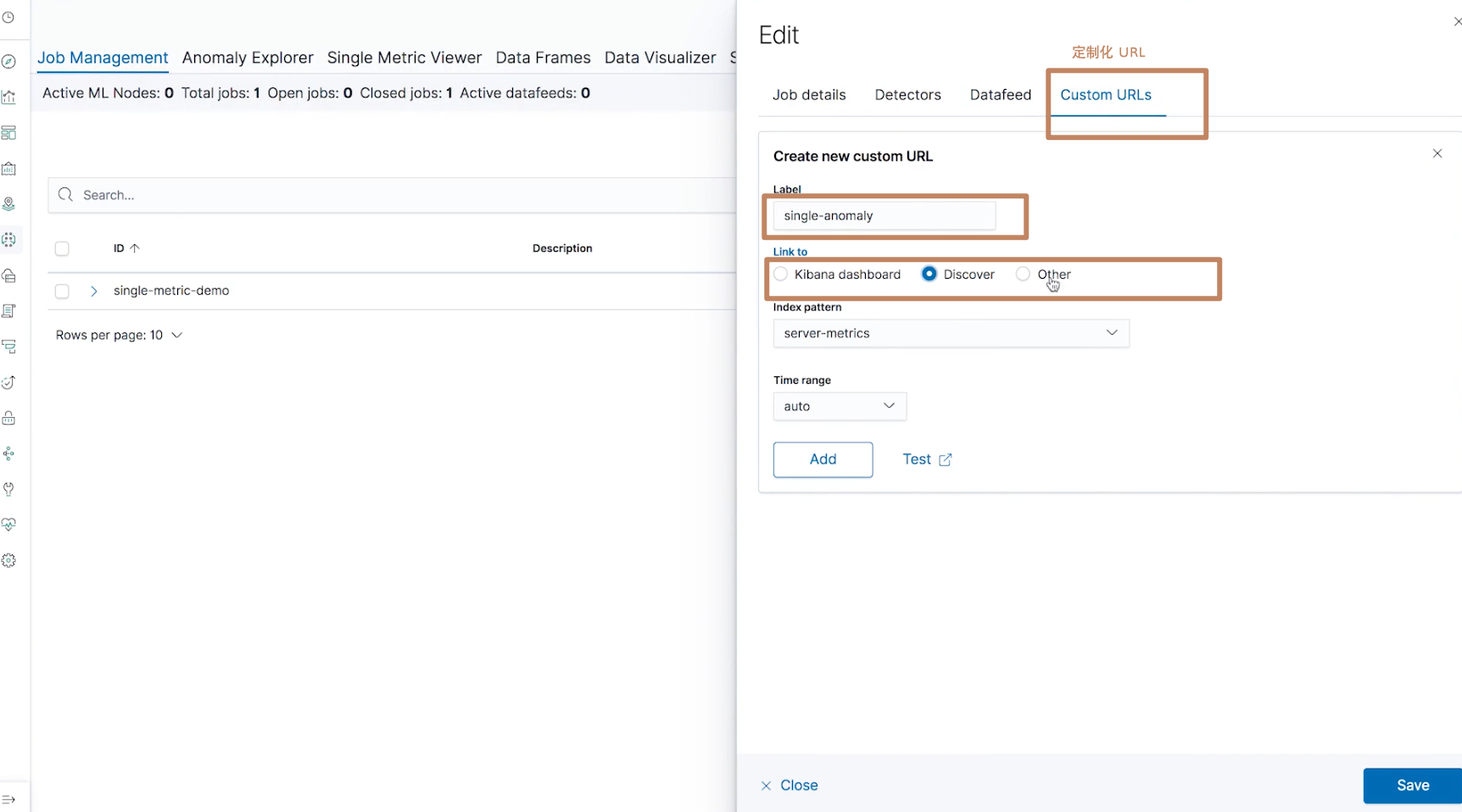
我们可以将这个 job 做一个链接,链接到 Dashboard 或者 Discover 的界面
我们再回到 job management 的界面,然后点击 single metric viewer 再回到刚刚的"single metric"的计算结果界面:
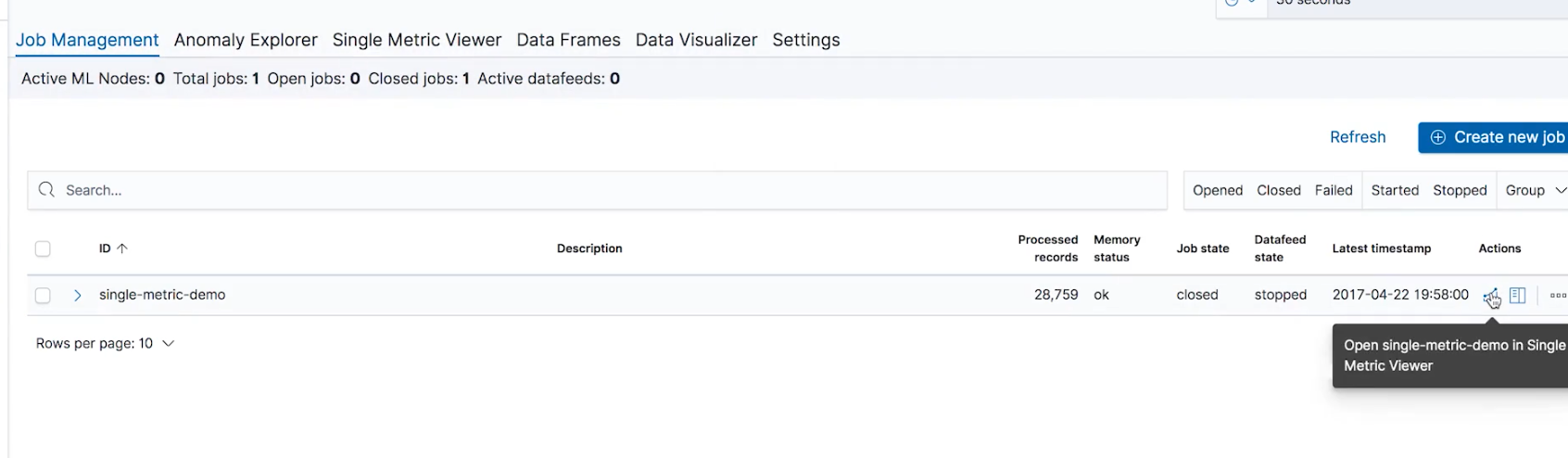
选择一个异常点,这时候我们发现多了一个我们前面定制的链接的名称"single-anomaly",我们点击这个链接
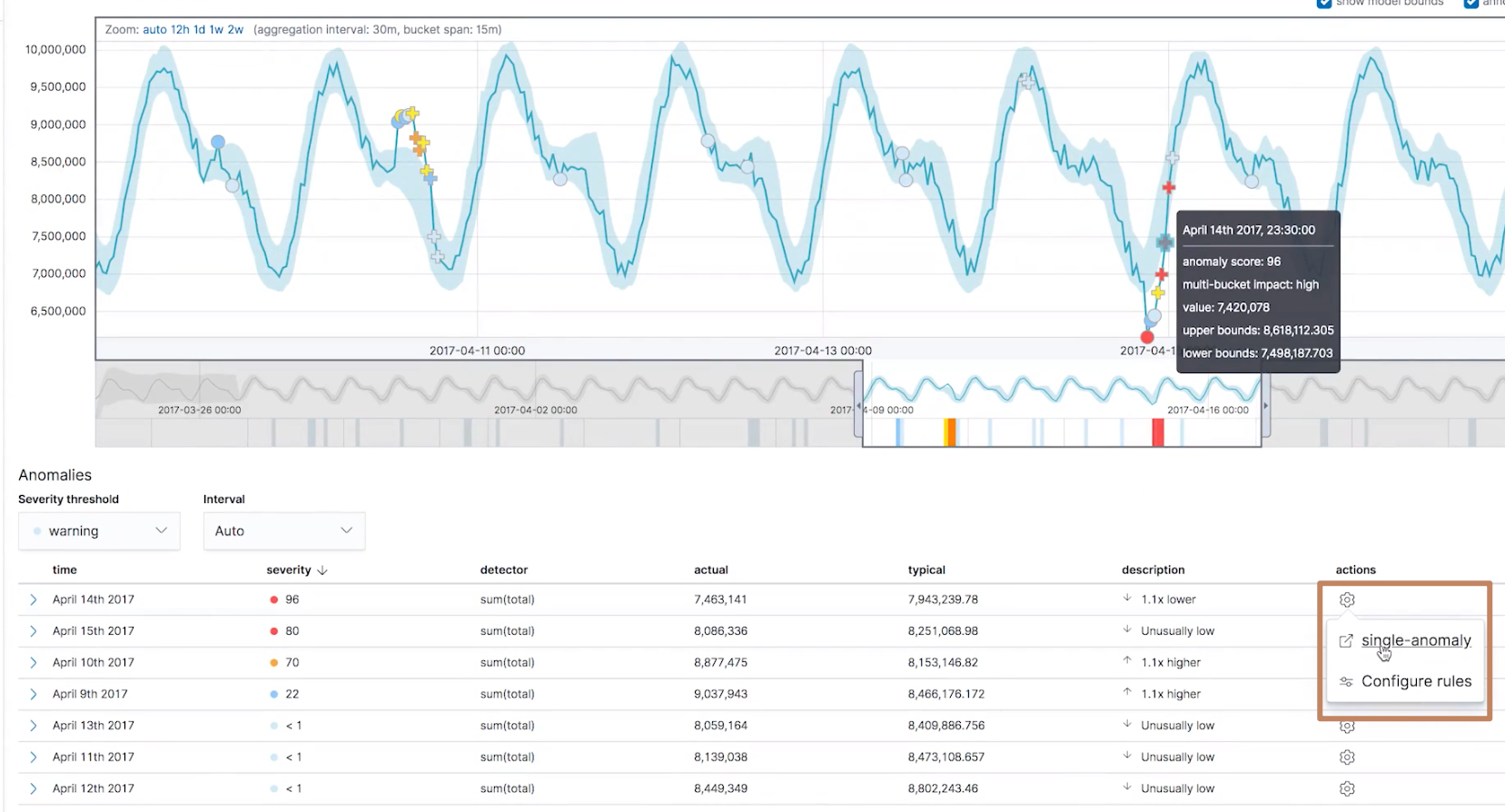
我们就可以直接跳转到 discovery 的界面了
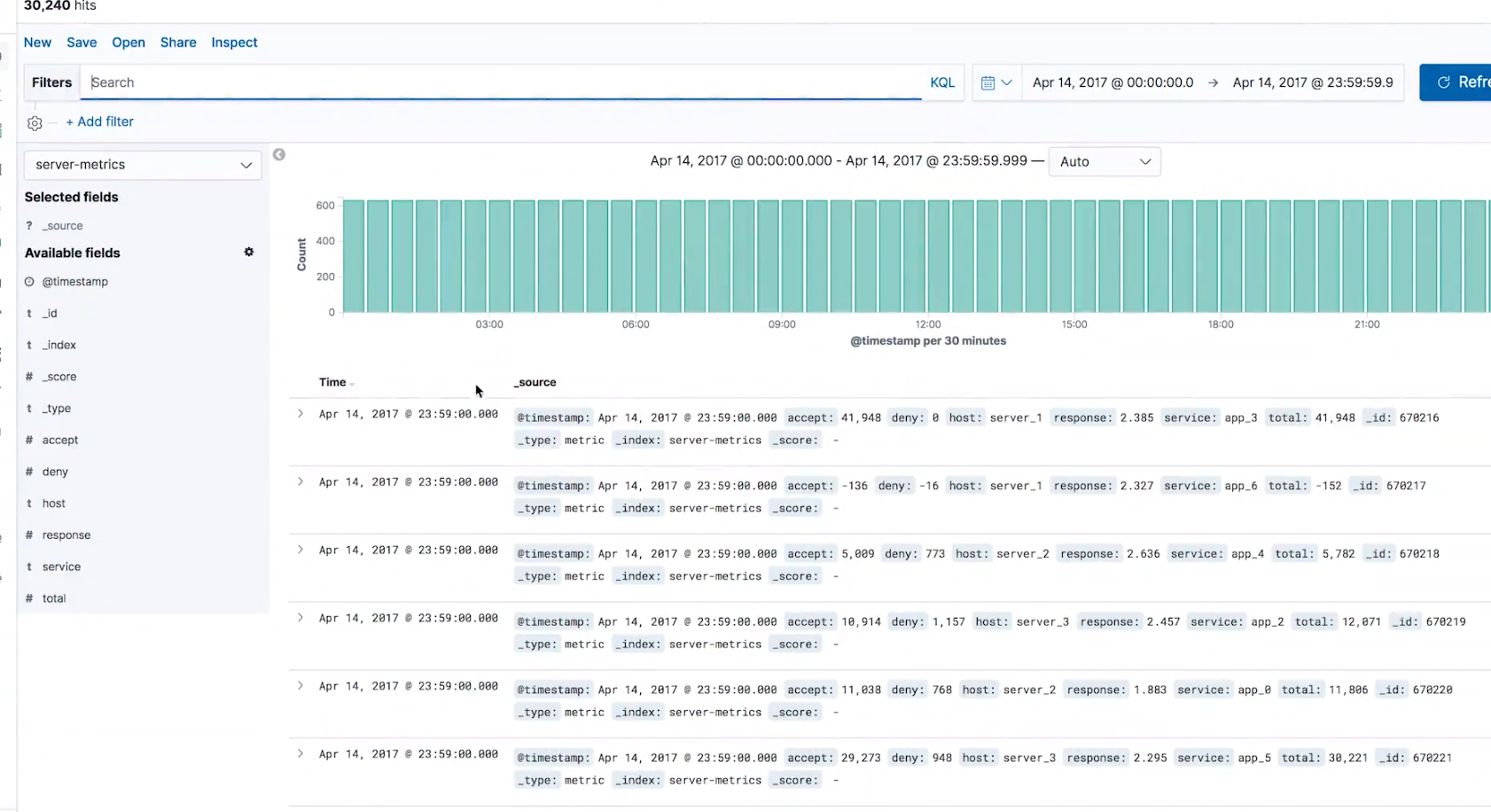
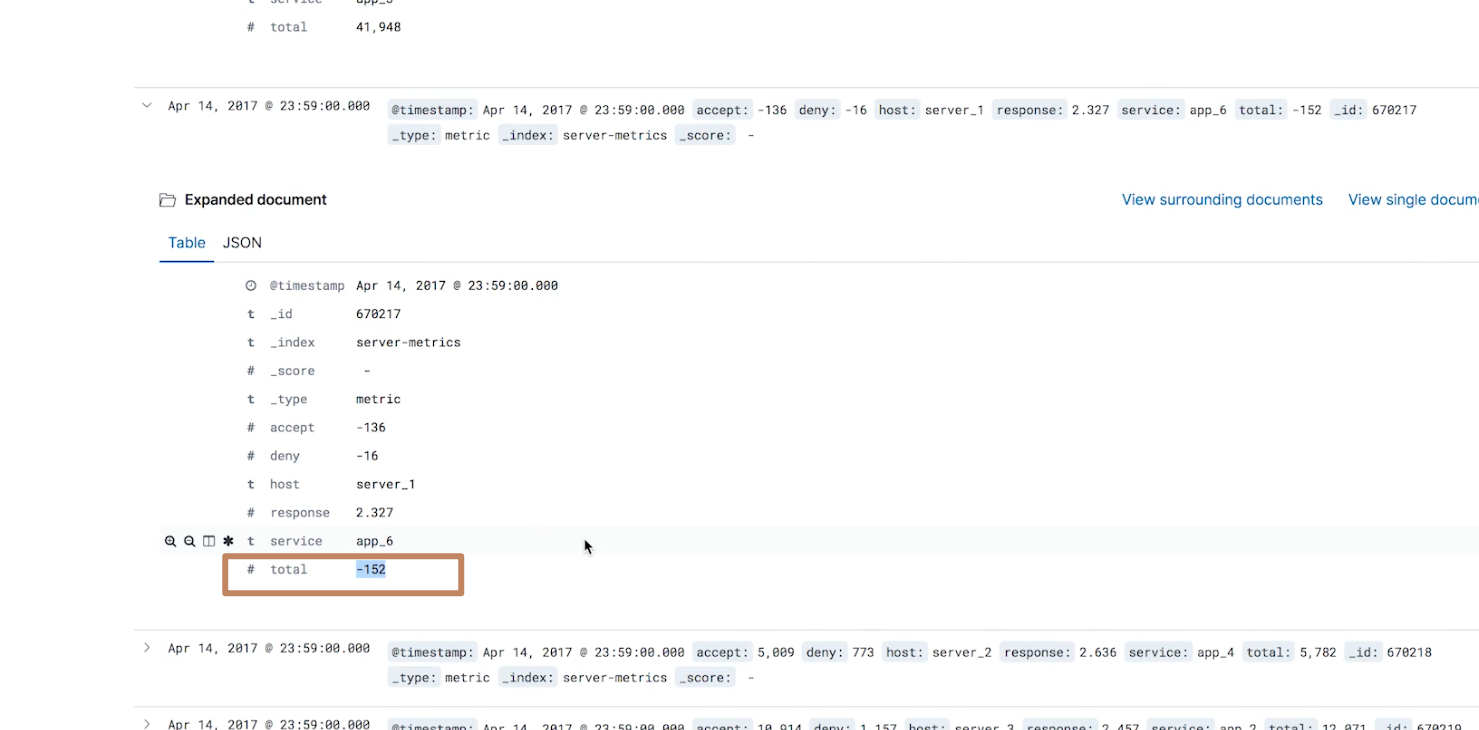
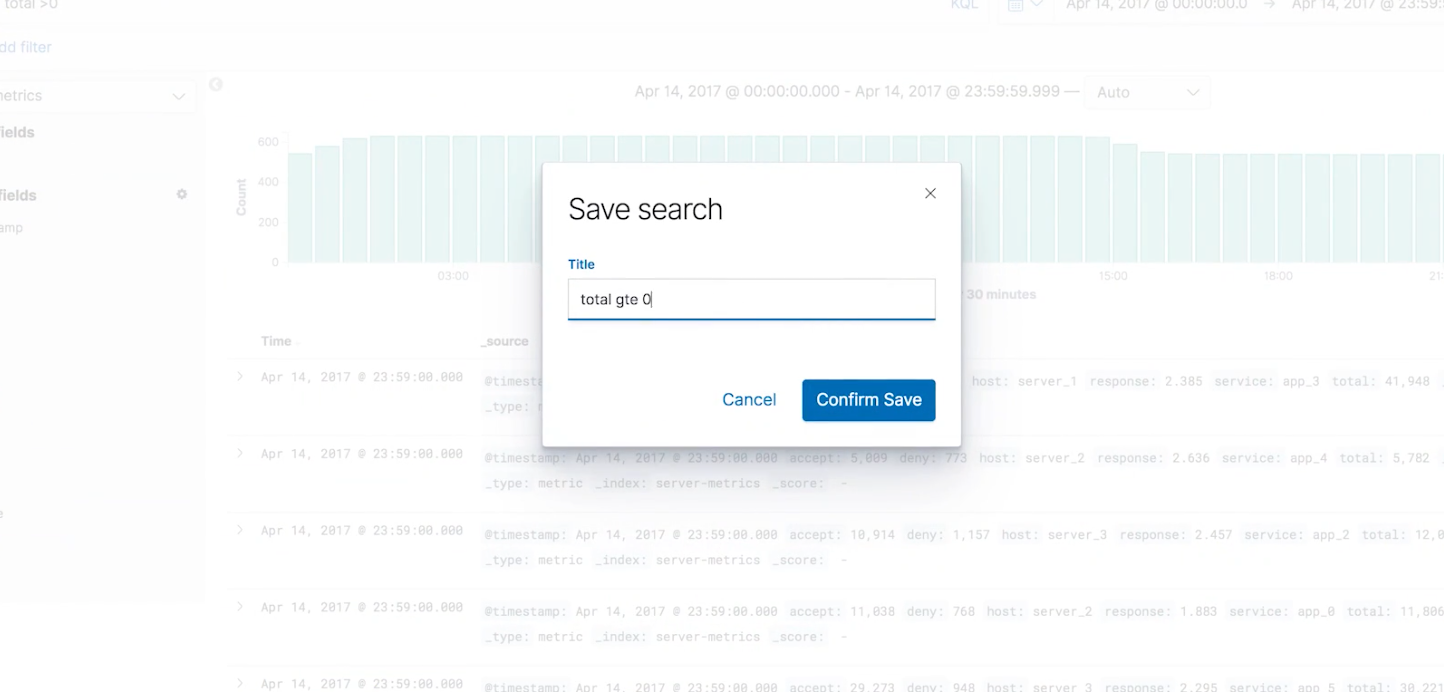
然后我们在这个界面查看该异常点的具体的一些数据,例如我们看到以下的一个数据的 total 是负数,我们认为负数数据应该被忽略,它也不属于异常数据,所以我们应该要过滤出大于0的数据进行检查
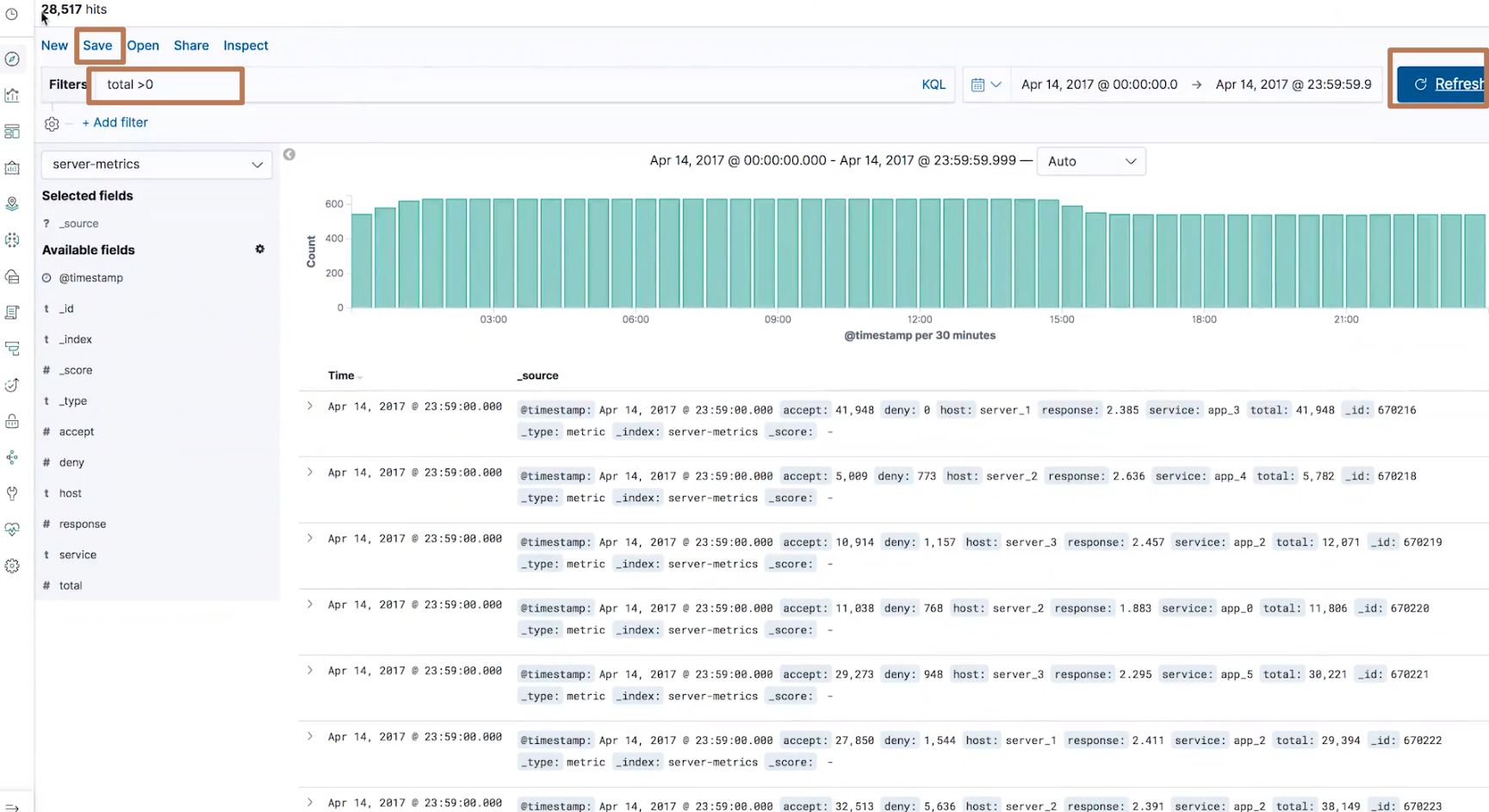
我们在 discovery 的条件搜索里加上"total>0"的条件,并点击 update 按钮,然后保存为一个名为"total gte 0"的 query,然后不再选择 “server-metrics” index pattern 而是基于这个 query 重新创建一个 ML Single Metric Job 进行一个学习,这样我们就可以基于一个新的准确的数据集进行异常检测。
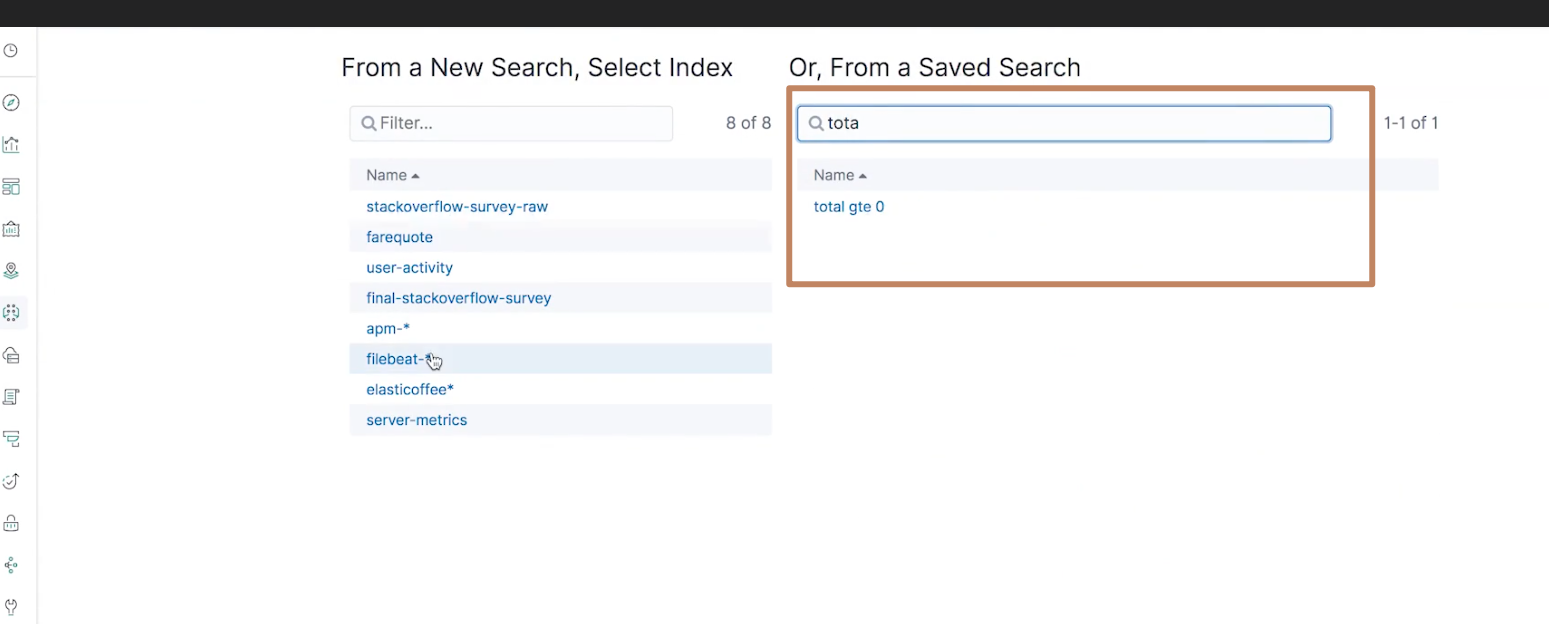
¶multi metric & populate metric
https://time.geekbang.org/course/detail/100030501-142415
- 讲了 multi metric 的案例,多个指标(字段)数据的机器学习来实现异常检测,就是比 single metric 支持更多字段的学习
- populate metric 和 single metric、multi metric 的区别在于后两者的区间数据是由一个时间区间来划分的,例如以15分钟为一个间隔的数据作为一个分析单元,而 populate metric 则是通过我们来指定一个具体的区间划分条件(其实就是数据分桶的条件),例如根据字段"username.keyword"的值进行分桶,同时 populate metric 也是可以进行多指标(字段)学习的。视频中就是举了一个通过用户名来对用户数据进行分桶并分析用户行为来进行用户的异常检测
- 前面提到我们的学习区间"bucket span"要是适合的,不能太长也不能太短,ES 在定义学习期间(分桶逻辑)的输入框都提供了一个"estimate bucket span"的按钮,点击它可以获得一个 ES 推荐的学习区间值,当然我们也可以自己手动设置一个。
- 通过 Calendar 组件控制机器学习 job 的执行时间(避开业务高峰期进行机器学习)
- 机器学习是在一些拥有机器学习角色的节点上进行的,如果我们的机器学习节点很多,可以设置一些 dedicated 的节点。
¶<4> 用Canvas 做数据演示
https://time.geekbang.org/course/detail/100030501-142434
Canvas 是 X-Pack 中的功能,但是它是可以免费使用的。它一般用于实时展示数据,并且达到完美像素级要求,用更加酷炫的方式,演绎你的数据。它和之前介绍的可视化组件和 dashboard 不一样,整个界面都是可以高度定制的(向一个画板一样,为每一个像素关联上一个具体的索引或者文档或者字段,随着数据的变化,画板上的像素也随着变化,实现一个动态的大屏)。
所以我们可以用 Canvas 来做那些放在公共场合展示的大图(例如向客户展示我们的公司数据、在大促的时候的秒杀的流量大图等等)。
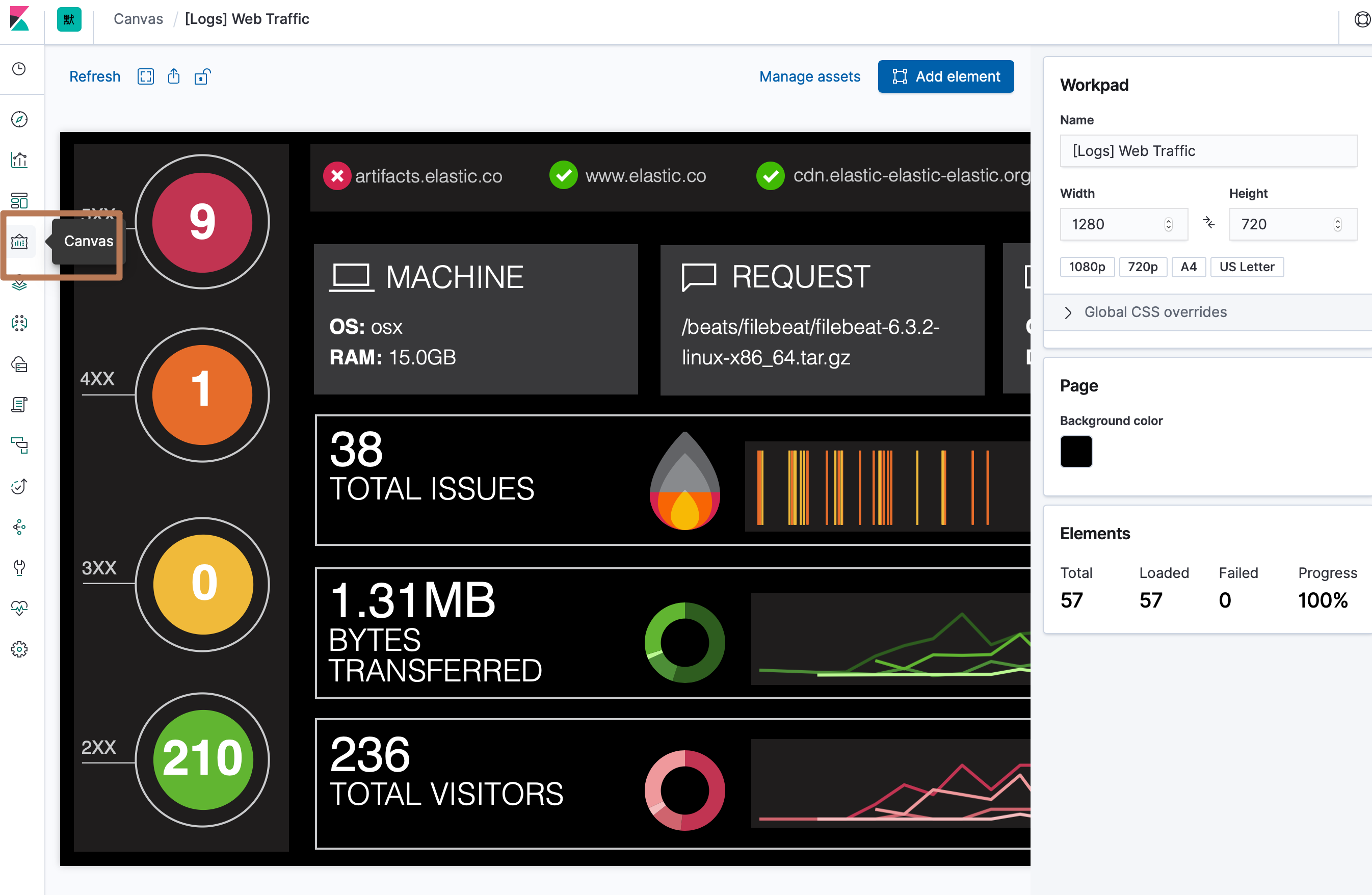
下面是 Kibana 开箱即用的三个数据集中包含的三个 Canvas 对象:
- 网站流量数据集
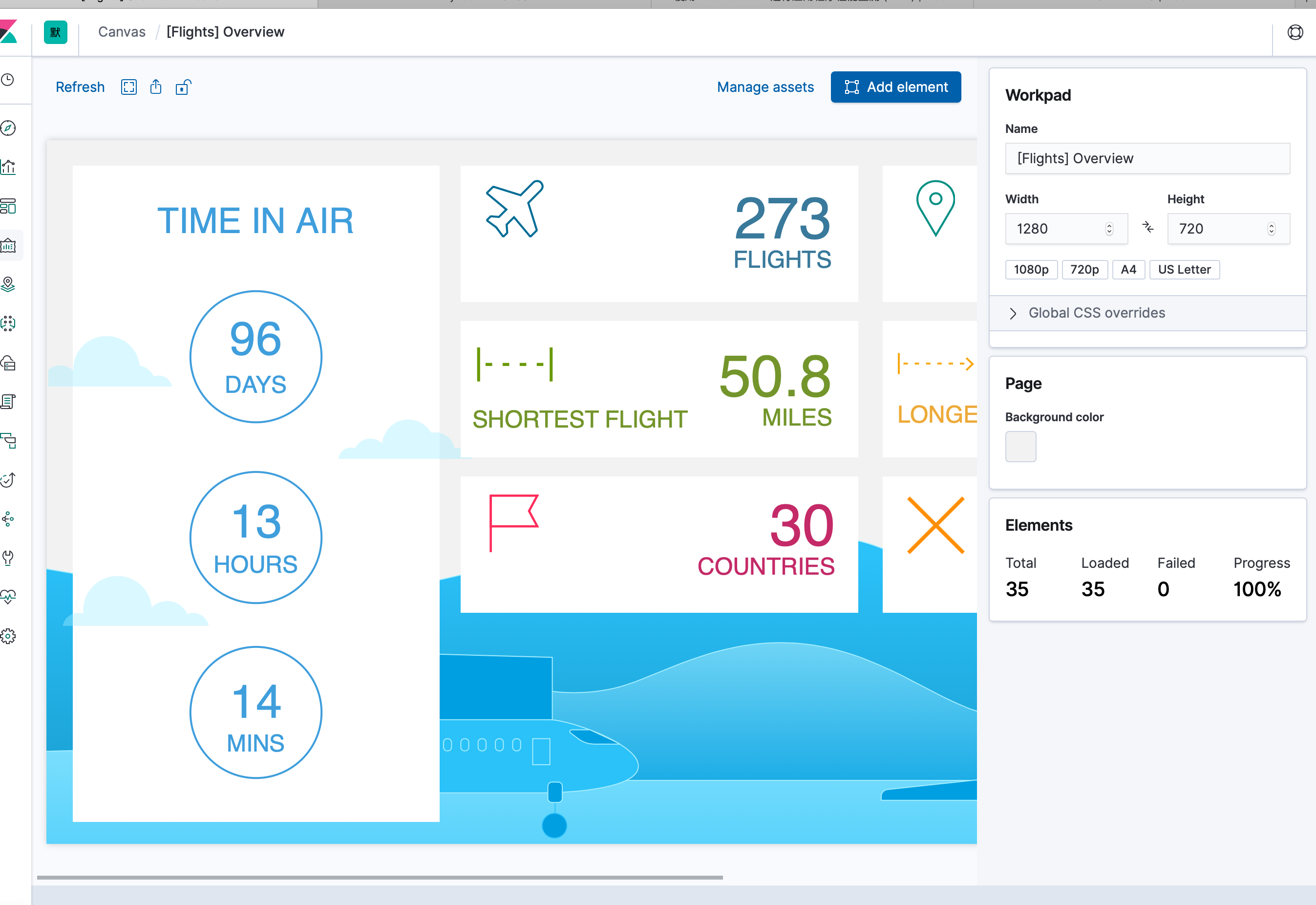
- 飞行航班的航班信息大屏(类似机场那种)
- 电商销量大屏
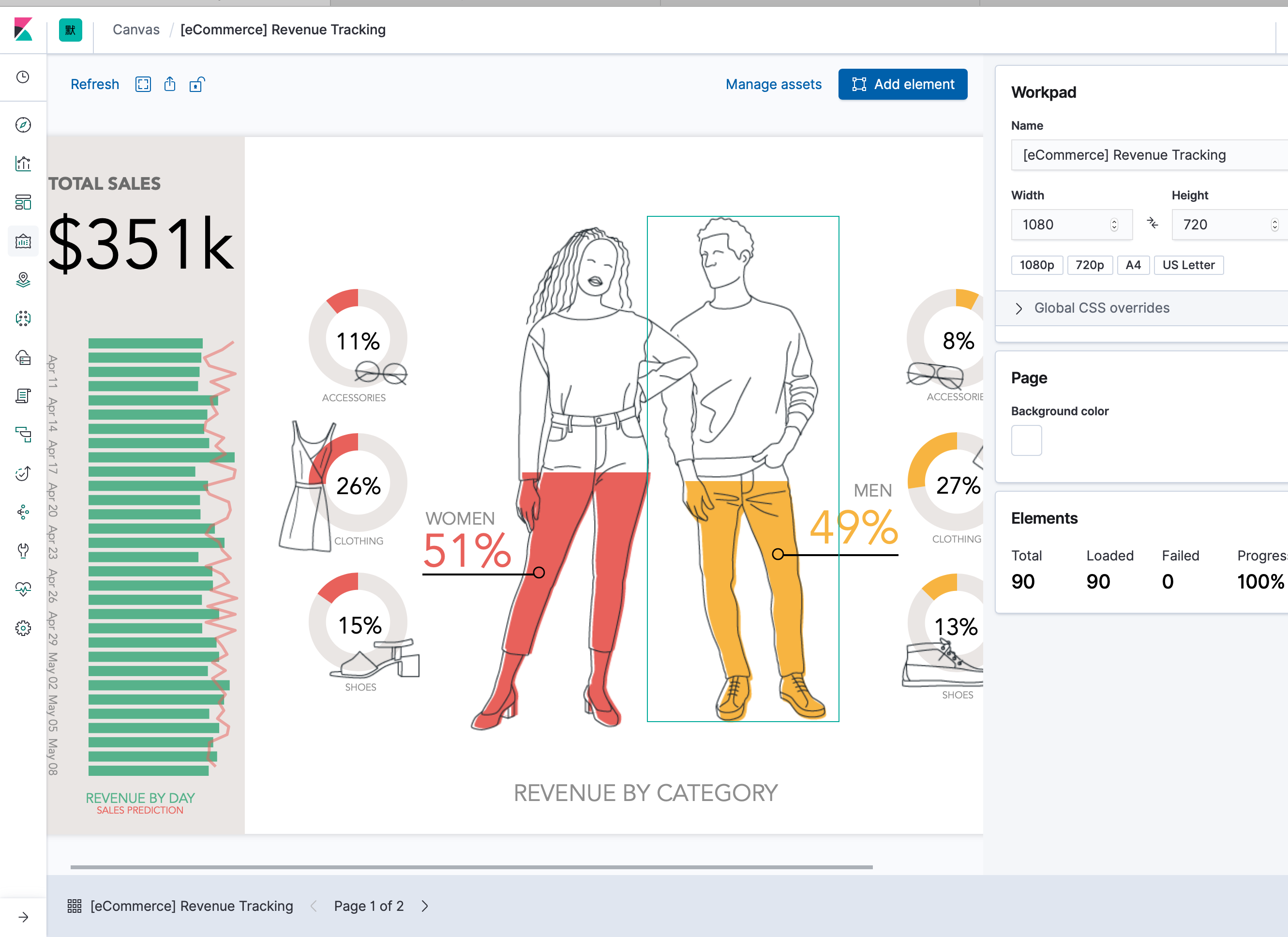
这些大屏都是在一个画布中编辑的,我们可以编辑任意一个像素点。




