一、编译原理
如今,基于物理机、Java虚拟机,或者是非Java的其他高级语言虚拟机(HLLVM)的代码执行过程,大体上都会遵循这种符合现代经典编译原理的思路,在执行前先对程序源码进行词法分析和语法分析处理,把源码转化为抽象语法树(Abstract Syntax Tree,AST)。对于一门具体语言的实现来说, 词法、语法分析以至后面的优化器和目标代码生成器都可以选择独立于执行引擎,形成一个完整意义的编译器去实现,这类代表是C/C++语言。也可以选择把其中一部分步骤(如生成抽象语法树之前的步骤)实现为一个半独立的编译器,这类代表是Java语言。又或者把这些步骤和执行引擎全部集中封装在一个封闭的黑匣子之中,如大多数的JavaScript执行引擎。
在Java语言中,Javac编译器完成了程序代码经过词法分析、语法分析到抽象语法树,再遍历语法树生成线性的字节码指令流的过程。因为这一部分动作是在Java虚拟机之外进行的,而解释器在虚拟机的内部,所以Java程序的编译就是半独立的实现。
二、执行引擎概述
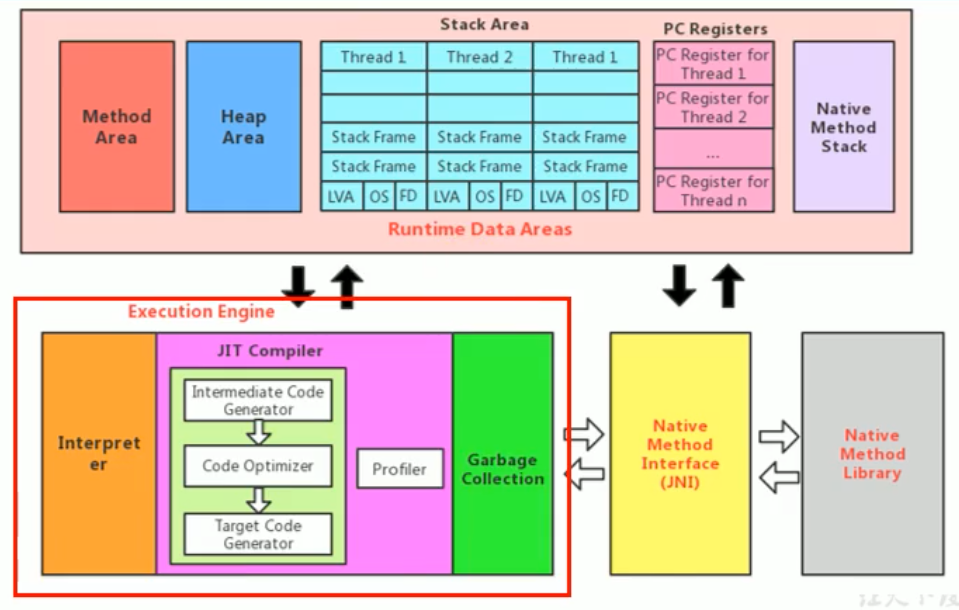
虚拟机是一个相对于物理机的概念,这两种机器都有代码执行能力,其区别是物理机的执行引擎是直接建立在处理器、缓存、指令集和操作系统层面上的,而虚拟机的执行引擎则是由软件自行实现的,因此可以不受物理条件制约地定制指令集与执行引擎的结构体系,能够执行那些不被硬件直接支持的指令集格式。
JVM的主要任务是负责装载字节码到其内部,但字节码并不能够直接运行在操作系统之上,因为字节码指令并非等价于本地机器指令,它内部包含的仅仅只是一些能够被JVM所识别的字节码指令、符号表、以及其他辅助信息。
那么,如果想要让一个Java程序运行起来,执行引擎(Execution Engine)的任务就是将字节码指令解释/编译为对应平台上的本地机器指令才可以。简单来说,JVM中的执行引擎充当了将高级语言翻译为机器语言的译者。
¶执行引擎工作
- 执行引擎在执行的过程中究竟需要执行什么样的字节码指令完全依赖于PC寄存器。
- 每当执行完一项指令操作后,PC寄存器就会更新下一条需要被执行的指令地址。
- 当然方法在执行的过程中,执行引擎有可能会通过存储在局部变量表中的对象引用准确定位到存储在Java堆区中的对象实例信息,以及通过对象头中的元数据指针定位到目标对象的类型信息。
三、Java代码编译和执行过程
Java是半编译半解释型语言。JDK1.0时代,将Java语言定位为"解释执行"还是比较准确的。再后来,Java也发展出可以直接生成本地代码的编译器。现在JVM在执行Java代码的时候,通常都会将解释执行与编译执行二者结合起来进行。
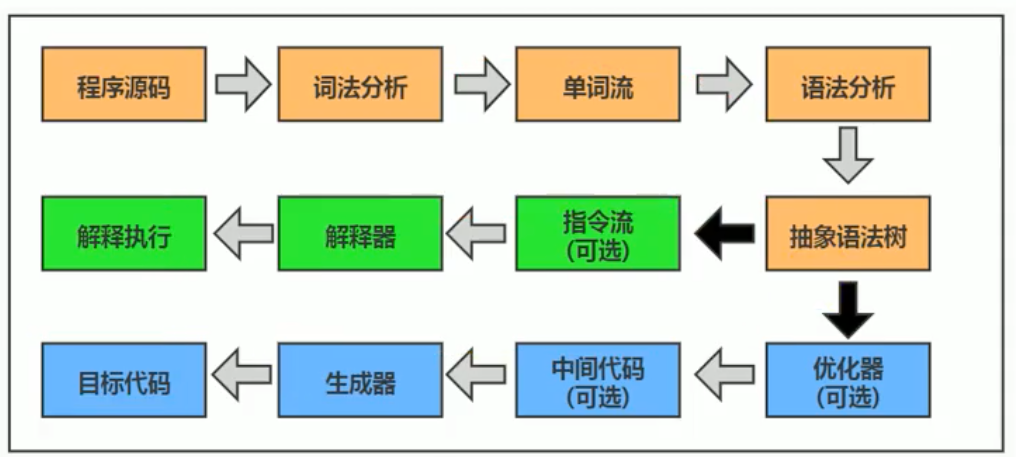
大部分的程序代码转换成物理机的目标代码或虚拟机能执行的指令集之前,都需要经过以上步骤。
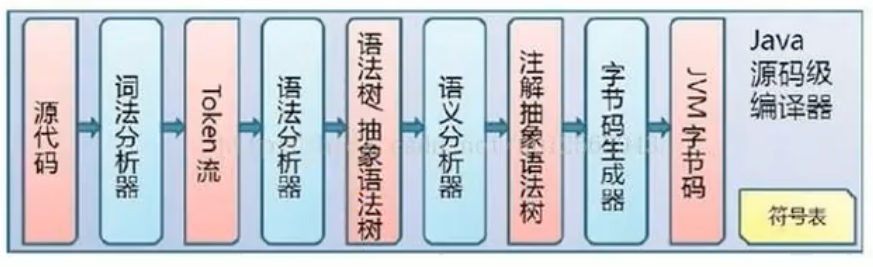
¶前端编译
Java代码编译由Java源码编译器(javac)来完成:
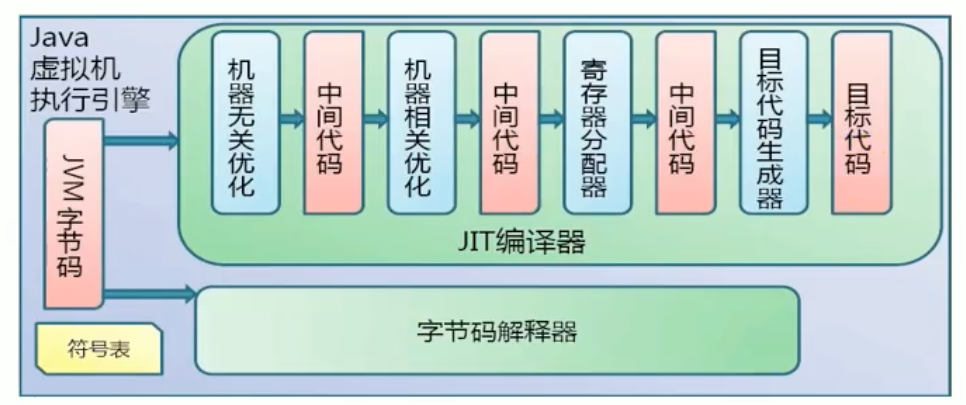
¶后端编译
Java字节码的执行是由JVM执行引擎来完成:
四、机器码、指令、汇编语言
¶机器码
各种用二进制编码方式表示的指令,叫做机器指令码。开始,人们就用它编写程序,这就是机器语言。机器语言虽然能够被计算机理解和接受,但和人们的语言差别太大,不易被人们理解和记忆,并且用它编程容易出错。用它编写的程序一经输入计算机,CPU直接读取运行,因此和其他语言编写的程序相比,执行速度最快。机器指令和CPU紧密相关,所以不同种类的CPU所对应的机器指令也就不同。
¶指令
表达不同的操作行为和操作数的一条原子机器码即为一条指令,另外不同硬件平台都定义了一些指令助记标准,方便描述和阅读。
¶指令集
不同的硬件平台,各自支持的指令是有差别的。因此每个平台所支持的指令,称之为对应平台的指令集。如常见的:
- x86指令集,对应的是x86架构的平台
- ARM指令集,对应的是ARM架构的平台
¶汇编语言
在汇编语言中,使用汇编助记符来替代机器指令的操作码,用地址符号(symbol)或标号(Label)代替指令或操作数的地址。相较于机器指令,汇编指令中的操作码都是字面量,操作数都是符号引用;而机器指令都是二进制位。
在不同的硬件平台,汇编语言对应着不同的机器语言指令集,通过汇编过程转换成机器指令。
- 由于计算机只认识指令码,所以用汇编语言写的程序还必须翻译成机器指令码,计算机才能识别和执行。
¶高级语言
高级语言比机器语言、汇编语言更接近人的语言。当计算机执行高级语言编写的程序时,仍然需要把程序解释和编译成机器的指令码。完成这个过程的程序就叫做解释程序或编译程序。
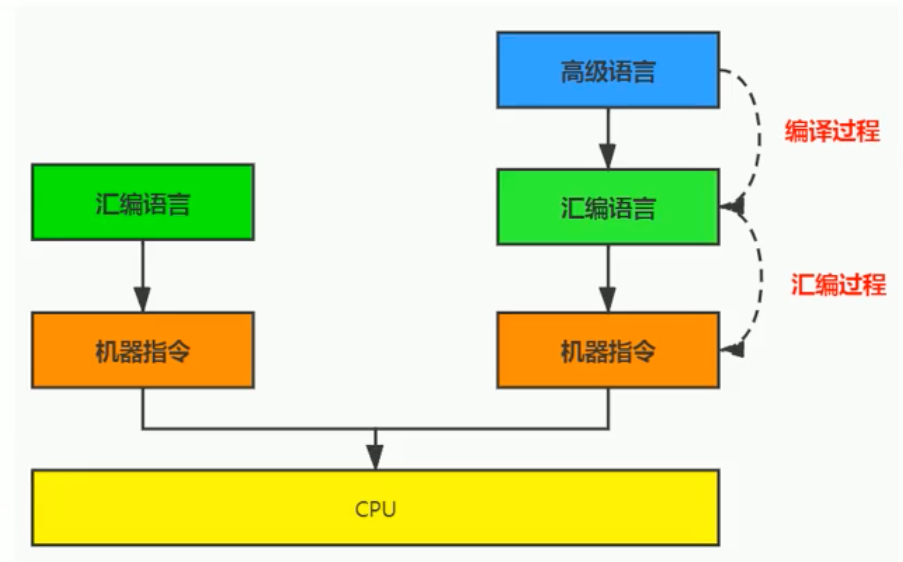
¶C/C++源程序执行过程
编译过程又可以分成两个阶段:编译和汇编
- 编译过程:读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换成功能等效的汇编代码。
- 汇编过程:实际上指把汇编语言代码翻译成目标机器指令的过程。
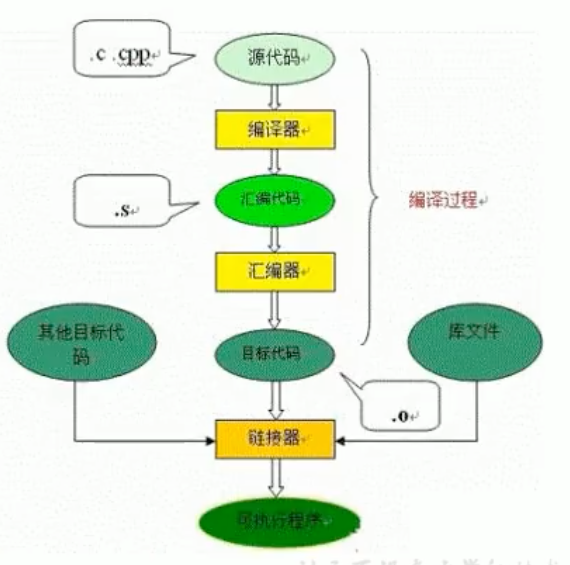
¶字节码
字节码是一种中间状态(中间码)的二进制代码(文件),它比机器码更抽象,需要直译器转译后才能称为机器码。字节码主要为了实现特定软件运行和软件环境有关、与硬件环境无关。
字节码的实现方式是通过编译器和虚拟机器。编译器将源码编译成字节码,特定平台上的虚拟机器将字节码转译为可以直接执行的指令。
- 字节码的典型应用为Java bytecode
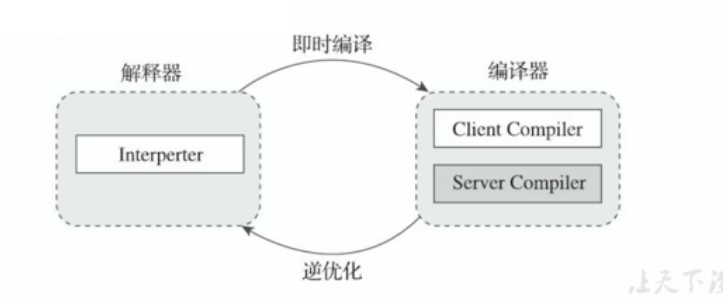
五、解释器
当Java虚拟机启动时会根据预定义的规范对字节码采用逐行解释的方式执行,将每条字节码文件中的内容"翻译"为对应平台的本地机器指令执行。当一条字节码指令被解释执行完成后,接着再根据PC寄存器中记录的下一条需要被执行的字节码指令执行解释操作。
在Java的发展历史中,一共有两套解释执行器,即古老的字节码解释器、现在普遍使用的模板解释器。
- 字节码解释器在执行时通过纯软件代码模拟字节码的执行,效率非常低下。
- 而模板解释器将每一条字节码和一个模板函数相关联,模板函数中直接产生这条字节码执行时的机器码,从而很大程度上提高了解释器的性能。
- 在HotSpot VM中,解释器主要由Interpreter模块和Code模块构成。
- Interpreter模块:实现了解释器的核心功能。
- Code模块:用于管理HotSpot VM在运行时生成的本地机器指令。
- 在HotSpot VM中,解释器主要由Interpreter模块和Code模块构成。
¶现状
由于解释器在设计和实现上非常简单,因此除了Java语言之外,还有许多高级语言同样也是基于解释器执行的,比如Python、Perl、Ruby等。但是在今天,基于解释器执行已经沦落为低效的代名词,并且时常被一些C/C++程序员所调侃。
为了解决这个问题,JVM平台支持一种叫做即时编译的技术。即时编译的目的是避免函数被解释执行,而是将整个函数体编译称为机器码,每次函数执行时,只执行编译后的机器码即可,这种方式可以使执行效率大幅度提升。
不过无论如何,基于解释器的执行模式仍然为中间语言的发展做出了不可磨灭的贡献。
六、编译器
¶6.1、Java中的编译
Java语言的“编译期”其实是一段“不确定”的操作过程,因为它可能是指:
- 一个前端编译器(其实叫“编译器的前端”更准确一些)把java文件转变成 class文件的过程
- 也可能是指虚拟机的后端运行期编译器(编译器, Just In Time Compiler)把字节码转变成机器码的过程
- 还可能是指使用静态提前编译器(AOT编译器, Ahead of Time Compiler)直接把.java文件编译成本地机器代码的过程
前端编译器:JDK的 Javac、 Eclipse JDT中的增量式编译器(ECJ)
JIT编译器::HotSpot VM的C1、C2编译器、Graal编译器。
AOT编译器:GNU Compiler for the Java(GCJ)、 Excelsior JET
¶Java中的JIT编译器
HotSpot中内嵌有两个(或者三个)JIT编译器,分别为 Client Compiler 和 Server compiler ,但大多数情况下我们简称为C1编译器和C2编译器。第三个是在JDK 10时才出现的、长期目标是代替C2的Graal编译器。Graal编译器目前还处于实验状态。
开发人员可以通过如下命令显式指定Java虚拟机在运行时到底使用哪一种即时编译器,如下所示:
-client:指定Java虚拟机 client运行在模式下,并使用C1编译器;- Client VM初始化堆空间会小一些,使用串行垃圾回收器。
- C1编译器会对字节码进行简单和可靠的优化,耗时短。以达到更快的编译速度。
-server:指定Java虚拟机 Server运行在模式下,并使用C2编译器。- Server VM的初始化堆空间会大一些,默认使用的是并行垃圾回收器。
- C2进行耗时较长的优化,以及激进优化。但优化的代码执行效率更高。
如果不指定参数,JVM在启动的时候会根据硬件和操作系统自动选择使用Server还是Client类型的JVM。
- 32位操作系统
- 如果是Windows系统,不论硬件配置如何,都默认使用Client类型的JVM。
- 如果是其他操作系统上,机器配置有2GB以上的内存同时有2个以上CPU的话默认使用server 模式,否则使用client模式
- 64位操作系统 只有Server类型,不支持Client类型。
一般来讲,JIT编译出来的机器码性能比解释器高。C2编译器启动时长比C1编译器慢,系统稳定执行以后,C2编译器执行速度远远快于C1编译器。
¶6.2、前端编译
Java中即时编译器在运行期的优化过程,支撑了程序执行效率的不断提升;而前端编译器在编译期的优化过程(新生的Java语法特性,都是靠前端编译器的“语法糖”),则是支撑着程序员的编码效率和语言使用者的幸福感的提高。
Javac编译器不像HotSpot虚拟机那样使用C++语言(包含少量C语言)实现,它本身就是一个由Java语言编写的程序。
从Javac代码的总体结构来看,编译过程大致可以分为1个准备过程和3个处理过程,它们分别如下所示。
《Java虚拟机规范》中严格定义了Class文件格式的各种细节,可是对如何把Java源码编译为Class 文件却描述得相当宽松。规范里尽管有专门的一章名为“Compiling for the Java Virtual Machine”,但这章也仅仅是以举例的形式来介绍怎样的Java代码应该被转换为怎样的字节码,并没有使用编译原理中常用的描述工具(如文法、生成式等)来对Java源码编译过程加以约束。这是给了Java前端编译器较大的实现灵活性,但也导致Class文件编译过程在某种程度上是与具体的JDK或编译器实现相关的,譬如在一些极端情况下,可能会出现某些代码在Javac编译器可以编译,但是ECJ编译器就不可以编译的问题(反过来也有可能,后文中将会给出一些这样的例子)
从Javac代码的总体结构来看,编译过程大致可以分为1个准备过程和3个处理过程,它们分别如下所示。
- 准备过程:初始化插入式注解处理器。
- 解析与填充符号表过程,包括:
- 词法、语法分析。将源代码的字符流转变为标记集合,构造出抽象语法树。
- 填充符号表。产生符号地址和符号信息。
- 插入式注解处理器的注解处理过程:插入式注解处理器的执行阶段
- 分析与字节码生成过程,包括:
- 标注检查。对语法的静态信息进行检查。
- 数据流及控制流分析。对程序动态运行过程进行检查。
- 解语法糖。将简化代码编写的语法糖还原为原有的形式。
- 字节码生成。将前面各个步骤所生成的信息转化成字节码。
上述前3个处理过程里,执行插入式注解时又可能会产生新的符号,如果有新的符号产生,就必须转回到之前的解析、填充符号表的过程中重新处理这些新符号,从总体来看,三者之间的关系与交互顺序如图

上述处理过程对应到代码中,Javac编译动作的入口是com.sun.tools.javac.main.JavaCompiler类,上述3个过程的代码逻辑集中在这个类的compile()和compile2()方法里,其中主体代码如下图。下面步骤围绕这个图中方法展开描述

¶6.2.1、解析与填充符号表
解析过程由parseFiles()方法来完成,解析过程包括了经典程序编译原理中的词法分析和语法分析两个步骤。
¶1>词法、语法分析
法分析是将源代码的字符流转变为标记(Token)集合的过程,单个字符是程序编写时的最小元素,但标记才是编译时的最小元素。关键字、变量名、字面量、运算符都可以作为标记,如“int a=b+2”这句代码中就包含了6个标记,分别是int、a、=、b、+、2,虽然关键字int由3个字符构成,但是它只是一个独立的标记,不可以再拆分。在Javac的源码中,词法分析过程由com.sun.tools.javac.parser.Scanner类来实现。
语法分析是根据标记序列构造抽象语法树的过程,抽象语法树(Abstract Syntax Tree,AST)是一种用来描述程序代码语法结构的树形表示方式,抽象语法树的每一个节点都代表着程序代码中的一个语法结构(Syntax Construct),例如包、类型、修饰符、运算符、接口、返回值甚至连代码注释等都可以是一种特定的语法结构。
下面是Eclipse AST View插件分析出来的某段代码的抽象语法树视图,
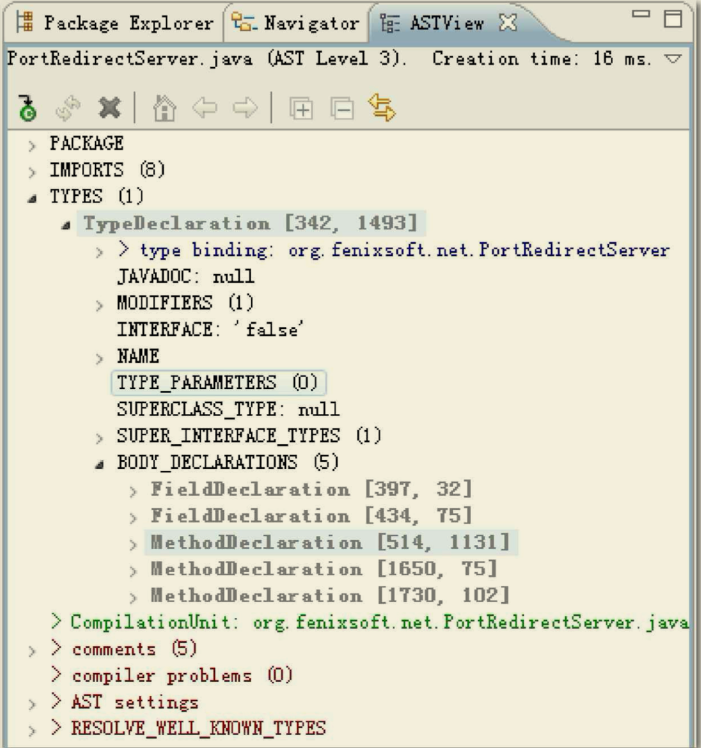
在Javac的源码中,语法分析过程由com.sun.tools.javac.parser.Parser类实现,这个阶段产出的抽象语法树是以com.sun.tools.javac.tree.JCTree 类表示的。
经过词法和语法分析生成语法树以后,编译器就不会再对源码字符流进行操作了,后续的操作都建立在抽象语法树之上。
¶2>填充符号表
完成了语法分析和词法分析之后,下一个阶段是对符号表进行填充的过程,也就是enterTrees()方法要做的事情。符号表(Symbol Table)是由一组符号地址和符号信息构成的数据结构,读者可以把它类比想象成哈希表中键值对的存储形式(实际上符号表不一定是哈希表实现,可以是有序符号表、树状符号表、栈结构符号表等各种形式)。符号表中所登记的信息在编译的不同阶段都要被用到。譬如在语义分析的过程中,符号表所登记的内容将用于语义检查(如检查一个名字的使用和原先的声明是否一致)和产生中间代码,在目标代码生成阶段,当对符号名进行地址分配时,符号表是地址分配的直接依据。
在Javac源代码中,填充符号表的过程由com.sun.tools.javac.comp.Enter类实现,该过程的产出物是一个待处理列表,其中包含了每一个编译单元的抽象语法树的顶级节点,以及package-info.java(如果存在的话)的顶级节点。
¶6.2.2、注解处理器
JDK 5之后,Java语言提供了对注解(Annotations)的支持,注解在设计上原本是与普通的Java代码一样,都只会在程序运行期间发挥作用的。但在JDK 6中又提出并通过了JSR-269提案,该提案设计了一组被称为“插入式注解处理器”的标准API,可以提前至编译期对代码中的特定注解进行处理, 从而影响到前端编译器的工作过程。我们可以把插入式注解处理器看作是一组编译器的插件,当这些插件工作时,允许读取、修改、添加抽象语法树中的任意元素。如果这些插件在处理注解期间对语法树进行过修改,编译器将回到解析及填充符号表的过程重新处理,直到所有插入式注解处理器都没有再对语法树进行修改为止,每一次循环过程称为一个轮次(Round)。
有了编译器注解处理的标准API后,程序员的代码才有可能干涉编译器的行为,由于语法树中的任意元素,甚至包括代码注释都可以在插件中被访问到,所以通过插入式注解处理器实现的插件在功能上有很大的发挥空间。只要有足够的创意,程序员能使用插入式注解处理器来实现许多原本只能在编码中由人工完成的事情。譬如Java著名的编码效率工具Lombok,它可以通过注解来实现自动产生getter/setter方法、进行空置检查、生成受查异常表、产生equals()和hashCode()方法,等等。
Javac源码中,插入式注解处理器的初始化过程是在initPorcessAnnotations()方法中完成的,而它的执行过程则是在processAnnotations()方法中完成。这个方法会判断是否还有新的注解处理器需要执行,如果有的话,通过com.sun.tools.javac.processing.JavacProcessing-Environment类的doProcessing()方法来生成一个新的JavaCompiler对象,对编译的后续步骤进行处理。
¶6.2.3、语义分析与字节码生成
经过语法分析之后,编译器获得了程序代码的抽象语法树表示,抽象语法树能够表示一个结构正确的源程序,但无法保证源程序的语义是符合逻辑的。而语义分析的主要任务则是对结构上正确的源程序进行上下文相关性质的检查,譬如进行类型检查、控制流检查、数据流检查,等等。
¶1>标注检查
Javac在编译过程中,语义分析过程可分为标注检查和数据及控制流分析两个步骤,分别由attribute()和flow()方法完成。
标注检查步骤要检查的内容包括诸如变量使用前是否已被声明、变量与赋值之间的数据类型是否能够匹配,等等。在标注检查中,还会顺便进行一个称为常量折叠(Constant Folding)的代码优化,这是Javac编译器会对源代码做的极少量优化措施之一(代码优化几乎都在即时编译器中进行)。如果我们在Java代码中写下如下所示的变量定义
int a = 1 + 2;
则在抽象语法树上仍然能看到字面量“1”“2”和操作符“+”号,但是在经过常量折叠优化之后,它们将会被折叠为字面量“3”,这插入式表达式(InfixExpression)的值已经在语法树上标注出来了(ConstantExpressionValue:3)。由于编译期间进行了常量折叠,所以在代码里面定义“a=1+2”比起直接定义“a=3”来,并不会增加程序运行期哪怕仅仅一个处理器时钟周期的处理工作量。
标注检查步骤在Javac源码中的实现类是com.sun.tools.javac.comp.Attr类和com.sun.tools.javac.comp.Check类。
¶2>数据及控制流分析
数据流分析和控制流分析是对程序上下文逻辑更进一步的验证,它可以检查出诸如程序局部变量在使用前是否有赋值、方法的每条路径是否都有返回值、是否所有的受查异常都被正确处理了等问题。编译时期的数据及控制流分析与类加载时的数据及控制流分析的目的基本上可以看作是一致的, 但校验范围会有所区别,有一些校验项只有在编译期或运行期才能进行。下面举一个关于final修饰符的数据及控制流分析的例子
// 方法一带有final修饰
public void foo(final int arg) {
final int var = 0;
// do something
}
// 方法二没有final修饰
public void foo(int arg) {
int var = 0;
// do something
}
在这两个foo()方法中,一个方法的参数和局部变量定义使用了final修饰符,另外一个则没有,在代码编写时程序肯定会受到final修饰符的影响,不能再改变arg和var变量的值,但是如果观察这两段代码编译出来的字节码,会发现它们是没有任何一点区别的,每条指令,甚至每个字节都一模一样。局部变量与类的字段(实例变量、类变量)的存储是有显著差别的,局部变量在常量池中并没有CONSTANT_Fieldref_info的符号引用,自然就不可能存储有访问标志(access_flags)的信息,甚至可能连变量名称都不一定会被保留下来(这取决于编译时的编译器的参数选项),自然在Class文件中就不可能知道一个局部变量是不是被声明为final了。因此, 可以肯定地推断出把局部变量声明为final,对运行期是完全没有影响的,变量的不变性仅仅由Javac编译器在编译期间来保障,这就是一个只能在编译期而不能在运行期中检查的例子。在Javac的源码中, 数据及控制流分析的入口flow()方法,具体操作由com.sun.tools.javac.comp.Flow类来完成。
¶3>解语法糖
语法糖(Syntactic Sugar),也称糖衣语法,是由英国计算机科学家Peter J.Landin发明的一种编程术语,指的是在计算机语言中添加的某种语法,这种语法对语言的编译结果和功能并没有实际影响, 但是却能更方便程序员使用该语言。通常来说使用语法糖能够减少代码量、增加程序的可读性,从而减少程序代码出错的机会。
Java在现代编程语言之中已经属于“低糖语言”(相对于C#及许多其他Java虚拟机语言来说),尤其是JDK 5之前的Java。“低糖”的语法让Java程序实现相同功能的代码量往往高于其他语言,通俗地说就是会显得比较“啰嗦”,这也是Java语言一直被质疑是否已经“落后”了的一个浮于表面的理由。
Java中最常见的语法糖包括了前面提到过的泛型(其他语言中泛型并不一定都是语法糖实现,如C#的泛型就是直接由CLR支持的)、变长参数、自动装箱拆箱,等等,Java虚拟机运行时并不直接支持这些语法,它们在编译阶段被还原回原始的基础语法结构,这个过程就称为解语法糖。在Javac的源码中,解语法糖的过程由desugar()方法触发,在com.sun.tools.javac.comp.TransTypes类和com.sun.tools.javac.comp.Lower类中完成。
¶4>字节码生成
字节码生成是Javac编译过程的最后一个阶段,在Javac源码里面由com.sun.tools.javac.jvm.Gen类来完成。字节码生成阶段不仅仅是把前面各个步骤所生成的信息(语法树、符号表)转化成字节码指令写到磁盘中,编译器还进行了少量的代码添加和转换工作。
例如前文多次登场的实例构造器<init>()方法和类构造器<clinit>()方法就是在这个阶段被添加到语法树之中的。请注意这里的实例构造器并不等同于默认构造函数,如果用户代码中没有提供任何构造函数,那编译器将会添加一个没有参数的、可访问性(public、protected、private或<package>)与当前类型一致的默认构造函数,这个工作在填充符号表阶段中就已经完成。<init>()和<clinit>()这两个构造器的产生实际上是一种代码收敛的过程,编译器会把语句块(对于实例构造器而言是“{}”块,对于类构造器而言是“static{}”块)、变量初始化(实例变量和类变量)、调用父类的实例构造器(仅仅是实例构造器,<clinit>()方法中无须调用父类的<clinit>()方法,Java虚拟机会自动保证父类构造器的正确执行,但在<clinit>()方法中经常会生成调用java.lang.Object的<init>()方法的代码)等操作收敛到<init>()和<clinit>()方法之中,并且保证无论源码中出现的顺序如何,都一定是按先执行父类的实例构造器,然后初始化变量,最后执行语句块的顺序进行,上面所述的动作由Gen::normalizeDefs()方法来实现。除了生成构造器以外,还有其他的一些代码替换工作用于优化程序某些逻辑的实现方式,如把字符串的加操作替换为StringBuffer或StringBuilder(取决于目标代码的版本是否大于或等于JDK 5)的append()操作,等等。
完成了对语法树的遍历和调整之后,就会把填充了所有所需信息的符号表交到com.sun.tools.javac.jvm.ClassWriter类手上,由这个类的writeClass()方法输出字节码,生成最终的Class 文件,到此,整个编译过程宣告结束。
¶6.2.4、Java语法糖的味道
¶1>泛型
泛型的本质是参数化类型(Parameterized Type)或者参数化多态(Parametric Polymorphism)的应用,即可以将操作的数据类型指定为方法签名中的一种特殊参数,这种参数类型能够用在类、接口和方法的创建中,分别构成泛型类、泛型接口和泛型方法。泛型让程序员能够针对泛化的数据类型编写相同的算法,这极大地增强了编程语言的类型系统及抽象能力。
¶Java与C#的泛型
Java选择的泛型实现方式叫作“类型擦除式泛型”(Type Erasure Generics),而C#选择的泛型实现方式是“具现化式泛型”(Reified Generics)。
- C#里面泛型无论在程序源码里面、编译后的中间语言表示(Intermediate Language,这时候泛型是一个占位符)里面,抑或是运行期的CLR里面都是切实存在的,
List<int>与List<string>就是两个不同的类型,它们由系统在运行期生成,有着自己独立的虚方法表和类型数据。 - 而Java语言中的泛型则不同,它只在程序源码中存在,在编译后的字节码文件中,全部泛型都被替换为原来的裸类型(Raw Type)了,并且在相应的地方插入了强制转型代码,因此对于运行期的Java语言来说,
ArrayList<int>与ArrayList<String>其实是同一个类型
以下是C#支持而Java不支持的泛型用法
public class TypeErasureGenerics {
public void doSomething(Object item) {
if (item instanceof E) { // 不合法,无法对泛型进行实例判断
...
}
E newItem = new E(); // 不合法,无法使用泛型创建对象
E[] itemArray = new E[10]; // 不合法,无法使用泛型创建数组
}
}
上面这些是Java泛型在编码阶段产生的不良影响,如果说这种使用层次上的差别还可以通过多写几行代码、方法中多加一两个类型参数来解决的话,性能上的差距则是难以用编码弥补的。C#2.0引入了泛型之后,带来的显著优势之一便是对比起Java在执行性能上的提高,因为在使用平台提供的容器类型(如List<T>,Dictionary<TKey,TV alue>)时,无须像Java里那样不厌其烦地拆箱和装箱,如果在Java中要避免这种损失,就必须构造一个与数据类型相关的容器类(譬如IntFloatHashMap这样的容器)。显然,这除了引入更多代码造成复杂度提高、复用性降低之外,更是丧失了泛型本身的存在价值。
Java的类型擦除式泛型无论在使用效果上还是运行效率上,几乎是全面落后于C#的具现化式泛型,而它的唯一优势是在于实现这种泛型的影响范围上:擦除式泛型的实现几乎只需要在Javac编译器上做出改进即可,不需要改动字节码、不需要改动Java虚拟机,也保证了以前没有使用泛型的库可以直接运行在Java 5.0之上。但这种听起来节省工作量甚至可以说是有偷工减料嫌疑的优势就显得非常短视,真的能在当年Java实现泛型的利弊权衡中胜出吗?答案的确是它胜出了,但我们必须在那时的泛型历史背景中去考虑不同实现方式带来的代价。
¶泛型的历史背景
为了保证这些编译出来的Class文件可以在Java 5.0引入泛型之后继续运行,设计者面前大体上有两条路可以选择:
- 需要泛型化的类型(主要是容器类型),以前有的就保持不变,然后平行地加一套泛型化版本的新类型。
- 直接把已有的类型泛型化,即让所有需要泛型化的已有类型都原地泛型化,不添加任何平行于已有类型的泛型版。
在这个分叉路口,C#走了第一条路,添加了一组System.Collections.Generic的新容器,以前的System.Collections以及System.Collections.Specialized容器类型继续存在。C#的开发人员很快就接受了新的容器,倒也没出现过什么不适应的问题,唯一的不适大概是许多.NET自身的标准库已经把老容器类型当作方法的返回值或者参数使用,这些方法至今还保持着原来的老样子。
但如果相同的选择出现在Java中就很可能不会是相同的结果了,要知道当时.NET才问世两年,而Java已经有快十年的历史了,再加上各自流行程度的不同,两者遗留代码的规模根本不在同一个数量级上。而且更大的问题是Java并不是没有做过第一条路那样的技术决策,在JDK 1.2时,遗留代码规模尚小,Java就引入过新的集合类,并且保留了旧集合类不动。这导致了直到现在标准类库中还有Vector(老)和ArrayList(新)、有Hashtable(老)和HashMap(新)等两套容器代码并存,如果当时再摆弄出像Vector(老)、ArrayList(新)、VectorArrayList
所以Java只能选择第二条路了。但第二条路也并不意味着一定只能使用类型擦除来实现,如果当时有足够的时间好好设计和实现,是完全有可能做出更好的泛型系统的,否则也不会有今天的V alhalla项目来还以前泛型偷懒留下的技术债了。
¶类型擦除
由于Java选择了第二条路,直接把已有的类型泛型化。要让所有需要泛型化的已有类型,譬如ArrayList,原地泛型化后变成了ArrayList<T>,而且保证以前直接用ArrayList的代码在泛型新版本里必须还能继续用这同一个容器,这就必须让所有泛型化的实例类型,譬如ArrayList<Integer>、ArrayList<String>这些全部自动成为ArrayList的子类型才能可以,否则类型转换就是不安全的。由此就引出了“裸类型”(Raw Type)的概念,裸类型应被视为所有该类型泛型化实例的共同父类型(Super Type),只有这样,以下代码中的赋值才是被系统允许的从子类到父类的安全转型。
ArrayList ilist = new ArrayList();
ArrayList slist = new ArrayList();
ArrayList list; // 裸类型
list = ilist;
list = slist
接下来的问题是该如何实现裸类型。这里又有了两种选择:
- 一种是在运行期由Java虚拟机来自动地、真实地构造出
ArrayList<Integer>这样的类型,并且自动实现从ArrayList<Integer>派生自ArrayList的继承关系来满足裸类型的定义; - 另外一种是索性简单粗暴地直接在编译时把
ArrayList<Integer>还原回ArrayList,只在元素访问、修改时自动插入一些强制类型转换和检查指令
Java选择了第二种:
public static void main(String[] args) {
Map map = new HashMap();
map.put("hello", "你好");
map.put("how are you?", "吃了没?");
System.out.println(map.get("hello"));
System.out.println(map.get("how are you?"));
}
上面代码反编译后:
public static void main(String[] args) {
Map map = new HashMap();
map.put("hello", "你好");
map.put("how are you?", "吃了没?");
System.out.println((String) map.get("hello"));
System.out.println((String) map.get("how are you?"));
}
类型擦除的缺点:
-
使用擦除法实现泛型直接导致了对原始类型(Primitive Types)数据的支持又成了新的麻烦
ArrayListilist = new ArrayList (); ArrayList llist = new ArrayList (); ArrayList list; list = ilist; list = llist; 这种情况下,一旦把泛型信息擦除后,到要插入强制转型代码的地方就没办法往下做了,因为不支持
int、long与Object之间的强制转型。当时Java给出的解决方案一如既往的简单粗暴:既然没法转换那就索性别支持原生类型的泛型了吧,你们都用ArrayList<Integer>、ArrayList<Long>,反正都做了自动的强制类型转换,遇到原生类型时把装箱、拆箱也自动做了得了。这个决定后面导致了无数构造包装类和装箱、拆箱的开销,成为Java泛型慢的重要原因,也成为今天Valhalla项目要重点解决的问题之一。 -
运行期无法取到泛型类型信息,会让一些代码变得相当啰嗦, 需要写更多的代码通过其它方式获取, 有的地方甚至无法获取。如以下代码,我们去写一个泛型版本的从List到数组的转换方法,由于不能从List中取得参数化类型T,所以不得不从一个额外参数中再传入一个数组的组件类型进去,实属无奈。
public staticT[] convert(List list, Class componentType) { T[] array = (T[])Array.newInstance(componentType, list.size()); //... } -
最后,笔者认为通过擦除法来实现泛型,还丧失了一些面向对象思想应有的优雅,带来了一些模棱两可的模糊状况
public class GenericTypes { public static void method(Listlist) { System.out.println("invoke method(List list)"); } public static void method(List list) { System.out.println("invoke method(List list)"); } } 这段代码是不能被编译的,因为参数
List<Integer>和List<String>编译之后都被擦除了,变成了同一种的裸类型List, 类型擦除导致这两个方法的特征签名变得一模一样。但是下面的例子在JDK 6的Javac编译器中又能通过并执行成功。
public class GenericTypes { public static String method(Listlist) { System.out.println("invoke method(List list)"); return ""; } public static int method(List list) { System.out.println("invoke method(List list)"); return 1; } public static void main(String[] args) { method(new ArrayList ()); method(new ArrayList ()); } } 重载当然不是根据返回值来确定的,之所以这次能编译和执行成功,是因为两个
method()方法加入了不同的返回值后才能共存在一个Class文件之中。在Class文件方法表(method_info)的数据结构中,方法重载要求方法具备不同的特征签名,返回值并不包含在方法的特征签名中,所以返回值不参与重载选择,这一点如果前端编译器不保证,即可编译通过。而对于Class文件格式来说,只要描述符不是完全一致的两个方法就可以共存,所以编译通过后的代码也是可以执行的。
由于Java泛型的引入,各种场景(虚拟机解析、反射等)下的方法调用都可能对原有的基础产生影响并带来新的需求,如在泛型类中如何获取传入的参数化类型等。所以JCP组织对《Java虚拟机规范》做出了相应的修改,引入了诸如Signature、LocalV ariableTypeTable等新的属性用于解决伴随泛型而来的参数类型的识别问题,Signature是其中最重要的一项属性,它的作用就是存储一个方法在字节码层面的特征签名,这个属性中保存的参数类型并不是原生类型,而是包括了参数化类型的信息。修改后的虚拟机规范要求所有能识别49.0以上版本的Class文件的虚拟机都要能正确地识别Signature参数。
从上面的例子中可以看到擦除法对实际编码带来的不良影响,由于List<String>和List<Integer>擦除后是同一个类型,我们只能添加两个并不需要实际使用到的返回值才能完成重载,这是一种毫无优雅和美感可言的解决方案,并且存在一定语意上的混乱,譬如上面脚注中提到的,必须用JDK 6的Javac才能编译成功,其他版本或者是ECJ编译器都有可能拒绝编译。
另外,从Signature属性的出现我们还可以得出结论,擦除法所谓的擦除,仅仅是对方法的Code属性中的字节码进行擦除,实际上元数据中还是保留了泛型信息,这也是我们在编码时能通过反射手段取得参数化类型的根本依据。
¶值类型与未来的泛型
在2014年,刚好是Java泛型出现的十年之后,Oracle建立了一个名为Valhalla的语言改进项目[10], 希望改进Java语言留下的各种缺陷(解决泛型的缺陷就是项目主要目标其中之一)。
在V alhalla项目中规划了几种不同的新泛型实现方案,被称为Model 1到Model 3,在这些新的泛型设计中,泛型类型有可能被具现化,也有可能继续维持类型擦除以保持兼容(取决于采用哪种实现方案),即使是继续采用类型擦除的方案,泛型的参数化类型也可以选择不被完全地擦除掉,而是相对完整地记录在Class文件中,能够在运行期被使用,也可以指定编译器默认要擦除哪些类型。相对于使用不同方式实现泛型,目前比较明确的是未来的Java应该会提供“值类型”(Value Type)的语言层面的支持。
说起值类型,这点也是C#用户攻讦Java语言的常用武器之一,C#并没有Java意义上的原生数据类型,在C#中使用的int、bool、double关键字其实是对应了一系列在.NET框架中预定义好的结构体(Struct),如Int32、Boolean、Double等。在C#中开发人员也可以定义自己值类型,只要继承于ValueType类型即可,而ValueType也是统一基类Object的子类,所以并不会遇到Java那样int不自动装箱就无法转型为Object的尴尬。
值类型可以与引用类型一样,具有构造函数、方法或是属性字段,等等,而它与引用类型的区别在于它在赋值的时候通常是整体复制,而不是像引用类型那样传递引用的。更为关键的是,值类型的实例很容易实现分配在方法的调用栈上的,这意味着值类型会随着当前方法的退出而自动释放,不会给垃圾收集子系统带来任何压力。
在Valhalla项目中,Java的值类型方案被称为“内联类型”,计划通过一个新的关键字inline来定义, 字节码层面也有专门与原生类型对应的以Q开头的新的操作码(譬如iload对应qload)来支撑。
¶2>自动装箱、拆箱与遍历循环
public static void main(String[] args) {
List list = Arrays.asList(1, 2, 3, 4);
int sum = 0;
for (int i : list) {
sum += i;
}
System.out.println(sum);
}
public static void main(String[] args) {
List list = Arrays.asList(new Integer[]{Integer.valueOf(1), Integer.valueOf(2), Integer.valueOf(3), Integer.valueOf(4)});
int sum = 0;
for (Iterator localIterator = list.iterator(); localIterator.hasNext(); ) {
int i = ((Integer) localIterator.next()).intValue();
sum += i;
}
System.out.println(sum);
}
以上代码一共包含了泛型、自动装箱、自动拆箱、遍历循环与变长参数5种语法糖,分别展示了它们在编译前后发生的变化。泛型就不必说了,自动装箱、拆箱在编译之后被转化成了对应的包装和还原方法,如Integer.valueOf()与Integer.intValue()方法,而遍历循环则是把代码还原成了迭代器的实现,这也是为何遍历循环需要被遍历的类实现Iterable接口的原因。最后再看看变长参数,它在调用的时候变成了一个数组类型的参数,在变长参数出现之前,程序员的确也就是使用数组来完成类似功能的。
以下是一些自动拆箱的不正确用法。
Integer a = 1;
Integer b = 2;
Integer c = 3;
Integer d = 3;
Integer e = 321;
Integer f = 321;
Long g = 3L;
System.out.println(c == d); //true:发现对象是同一个,貌似是因为数值较小,所以会共用一个对象(常量池?)
System.out.println(e == f); //false:"=="没有遇到运算符不会自动拆箱,且数值较大,不会共用对象
System.out.println(c == (a + b)); //true:"=="遇到运算符会自动拆箱
System.out.println(c.equals(a + b)); //true:"=="遇到运算符会自动拆箱
System.out.println(g == (a + b)); //true:"=="遇到运算符会自动拆箱
System.out.println(g.equals(a + b)); //false:equals会做类型判断且不会处理类型转换
¶3>条件编译
许多程序设计语言都提供了条件编译的途径,如C、C中使用预处理器指示符(#ifdef)来完成条件编译。C、C的预处理器最初的任务是解决编译时的代码依赖关系(如极为常用的#include预处理命令)。
-
C/C++在预处理阶段通过对源文件中宏的判断条件进行预处理,对满足条件的一些宏定义进行展开。之后在编译阶段再对展开后的源文件进行整体编译。
-
而在Java语言之中并没有使用预处理器,因为Java语言天然的编译方式(编译器并非一个个地编译Java文件,而是将所有编译单元的语法树顶级节点输入到待处理列表后再进行编译,因此各个文件之间能够互相提供符号信息)就无须使用到预处理器。
Java语言当然也可以进行条件编译,方法就是使用条件为常量的if语句。如下:
public static void main(String[] args) {
if (true) {
System.out.println("block 1");
} else {
System.out.println("block 2");
}
}
反编译后得到
public static void main(String[] args) {
System.out.println("block 1");
}
该代码中的if语句不同于其他Java代码,它在编译阶段就会被“运行”,生成的字节码之中只包括System.out.println("block 1");一条语句,并不会包含if语句及另外一个分子中的System.out.println("block 2");。
只能使用条件为常量的if语句才能达到上述效果,如果使用常量与其他带有条件判断能力的语句搭配,则可能在控制流分析中提示错误,被拒绝编译:
public static void main(String[] args) {
while (false) {
System.out.println(""); // 编译器将会提示“Unreachable code”
}
}
¶6.2.5、修改字节码的方式
- 手动编辑.class文件或者自己编写代码直接基于二进制流修改字节码
- 基于一些字节码框架如ASM
- 动态代理框架如JDK的动态代理、CGLIB
- Javac提供的注解处理器机制
¶6.3、后端编译:JIT编译器
JIT(Just In Time Compiler)编译器:就是虚拟机将字节码直接编译成和本地机器平台相关的机器语言。
HotSpot VM是目前市面上高性能虚拟机的代表作之一。它采用解释器与即时编译器并存的架构。在Java虚拟机运行时,解释器和即时编译器能够相互协作,各自取长补短,尽力去选择最合适的方式来权衡编译本地代码的时间和直接解释执行代码的时间。
在今天,Java程序的运行性能早已脱胎换骨,已经达到了可以和C/C++程序一较高下的地步。
¶6.3.1、和解释器并存
当程序启动后,解释器可以马上发挥作用,省去编译的时间,立即执行。编译器要想发挥作用,把代码编译成本地代码,需要一定的执行时间。但编译为本地代码后,执行效率高。
所以尽管JRocket VM程序因为不包含解释器,在启动过程将字节码完全编译后才开始运行带来了很高的性能,但这个编译过程可能花费了很长时间。对于服务端应用来说,启动时间并非是关注重点,但对于那些看重启动时间的应用场景而言,或许就需要采用解释器与即时编译器并存的架构来换取一个平衡点。在此模式下,当Java虚拟机启动时,解释器可以首先发挥作用,而不必等待即时编译器全部编译完成后再执行,这样可以省去许多不必要的编译时间。随着时间的推移,编译器发挥作用,把越来越多的代码编译成本地代码,获取更高的执行效率。
当程序运行环境中内存资源限制较大,可以使用解释执行节约内存(如部分嵌入式系统中和大部分的JavaCard应用中就只有解释器的存在),反之可以使用编译执行来提升效率。同时,解释执行在编译器进行激进优化不成立的时候,作为编译器的"逃生门"。
¶案例
注意解释执行与编译执行在线上环境微妙的辩证关系。机器在热机状态可以承受的负载要大于冷机状态。如果以热机状态时的流量进行切流,可能使处于冷机状态的服务器因无法承载流量而假死。在生产环境发布过程中,以分批的方式进行发布,根据机器数量划分成多个批次,每个批次的机器数至多占到整个集群的1/8。曾经有这样的故障案例:某程序员在发布平台进行分批发布,在输入发布总批数时,误填写成分为两批发布。如果是热机状态,在正常情况下一半的机器可以勉强承载流量,但由于刚启动的JVM均是解释执行,还没有进行热点代码统计和JIT动态编译,导致机器启动之后,当前1/2发布成功的服务器马上全部宕机,此故障说明了JIT的存在。—阿里团队
¶6.3.2、热点代码及探测方式触发编译及优化
当然是否需要启动JIT编译器将字节码直接编译为对应平台的本地机器指令则需要根据代码被调用执行的频率而定。关于那些需要被编译为本地代码的字节码,也被称之为“热点代码”,JIT编译器在运行时会针对那些频繁被调用的“热点代码”做出深度优化,将其直接编译为对应平台的本地机器指令,以此提升Java程序的执行性能。
一个被多次调用的方法或者是一个方法体内部循环次数较多的循环体都可以被称之为“热点代码”,因此都可以通过JIT编译器编译为本地机器指令, 对于这两种情况,编译的目标对象都是整个方法体,而不会是单独的循环体。
- 第一种情况,由于是依靠方法调用触发的编译,那编译器理所当然地会以整个方法作为编译对象,这种编译也是虚拟机中标准的即时编译方式。
- 而对于后一种情况,尽管编译动作是由循环体所触发的,热点只是方法的一部分,但编译器依然必须以整个方法作为编译对象,只是执行入口(从方法第几条字节码指令开始执行)会稍有不同,编译时会传入执行入口点字节码序号(Byte Code Index,BCI)。这种编译方式因为编译发生在方法执行的过程中,因此被很形象地称为“栈上替换”(On Stack Replacement,OSR),即方法的栈帧还在栈上,方法就被替换了。
一个方法究竟要被调用多少次,或者一个循环体究竟需要执行多少次循环才可以达到这个标准?必然需要一个明确的阈值JIT编译器才会将这些“热点代码”编译为本地机器指令执行。这里主要依靠热点探测功能。
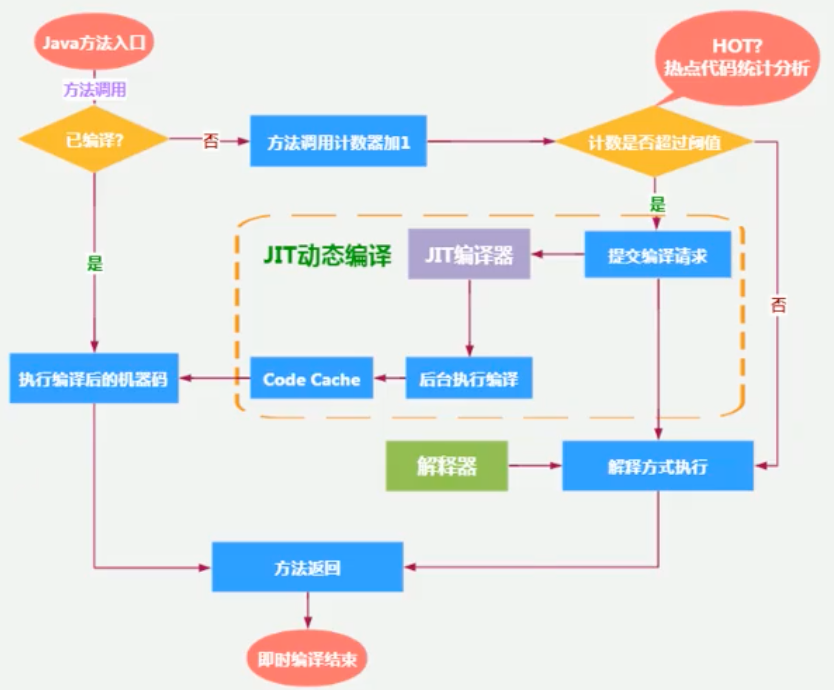
¶1>基于计数器探测
目前HotSpot VM所采用的热点探测方式是基于计数器的热点探测。HotSpot VM将会为每一个方法都建立2个不同类型的计数器,分别为方法调用计数器(Invocation Counter)和回边计数器(back Edge Counter).当虚拟机运行参数确定的前提下,这两个计数器都有一个明确的阈值,计数器阈值一旦溢出,就会触发即时编译。
这种统计方法实现起来要麻烦一些,需要为每个方法建立并维护计数器,而且不能直接获取到方法的调用关系。但是它的统计结果相对来说更加精确严谨。
-
方法调用计数器用于统计方法的调用次数
-
这个计数器就用于统计方法被调用的次数,它的默认阈值在 client模式下是1500次,在 Server模式下是10000次。超过这个阈值,就会触发JIT编译。这个阈值可以通过虚拟机参数
-xx: CompileThreshold来人为设定。 -
当一个方法被调用时,会先检查该方法是否存在被JIT编译过的版本:
-
如果存在,则优先使用编译后的本地代码来执行。
-
如果不存在已被编译过的版本,则将此方法的调用计数器值加1,然后判断方法调用计数器与回边计数器值之和是否超过方法调用计数器的阈值。如果已超过阈值,那么将会向即时编译器提交一个该方法的代码编译请求。
如果没有做过任何设置,执行引擎默认不会同步等待编译请求完成,而是继续进入解释器按照解释方式执行字节码,直到提交的请求被即时编译器编译完成。当编译工作完成后,这个方法的调用入口地址就会被系统自动改写成新值,下一次调用该方法时就会使用已编译的版本了。
-
-
热度衰减
如果不做任何设置,方法调用计数器统计的并不是方法被调用的绝对次数,而是一个相对的执行频率,即一段时间之内方法被调用的次数。当超过一定的时间限度,如果方法的调用次数仍然不足以让它提交给即时编译器编译,那这个方法的调用计数器就会被减少一半,这个过程称为方法调用计数器热度的衰减(Counter Decay),而这段时间就称为此方法统计的半衰周期(Counter Half Life Time)。
进行热度衰减的动作是在虚拟机进行垃圾收集时顺便进行的,可以使用虚拟机参数-XX:-UseCounterDecay来关闭热度衰减,让方法计数器统计方法调用的绝对次数,这样,只要系统运行时间足够长,绝大部分方法都会被编译成本地代码。
另外,可以使用-XX:CounterHalfLife=<N>参数设置半衰周期的时间,单位是秒。
-
-
回边计数器则用于统计循环体执行的循环次数
它的作用是统计一个方法中循环体代码执行的次数[1],在字节码中遇到控制流向后跳转的指令就称为“回边(Back Edge)”,很显然建立回边计数器统计的目的是为了触发栈上的替换编译。
关于回边计数器的阈值,虽然HotSpot虚拟机也提供了一个类似于方法调用计数器阈值
-XX: CompileThreshold的参数-XX:BackEdgeThreshold供用户设置,但是当前的HotSpot虚拟机实际上并未使用此参数,我们必须设置另外一个参数-XX:OnStackReplacePercentage来间接调整回边计数器的阈值,其计算公式有如下两种。- 虚拟机运行在客户端模式下,回边计数器阈值计算公式为:方法调用计数器阈值(
-XX: CompileThreshold)乘以OSR比率(-XX:OnStackReplacePercentage)除以100。其中-XX: OnStackReplacePercentage默认值为933,如果都取默认值,那客户端模式虚拟机的回边计数器的阈值为13995。 - 虚拟机运行在服务端模式下,回边计数器阈值的计算公式为:方法调用计数器阈值(
-XX: CompileThreshold)乘以(OSR比率(-XX:OnStackReplacePercentage)减去解释器监控比率(-XX: InterpreterProfilePercentage)的差值)除以100。其中-XX:OnStack ReplacePercentage默认值为140,-XX:InterpreterProfilePercentage默认值为33,如果都取默认值,那服务端模式虚拟机回边计数器的阈值为10700。
当解释器遇到一条回边指令时,会先查找将要执行的代码片段是否有已经编译好的版本,如果有的话,它将会优先执行已编译的代码,否则就把回边计数器的值加一,然后判断方法调用计数器与回边计数器值之和是否超过回边计数器的阈值。当超过阈值的时候,将会提交一个栈上替换编译请求, 并且把回边计数器的值稍微降低一些,以便继续在解释器中执行循环,等待编译器输出编译结果

与方法计数器不同,回边计数器没有计数热度衰减的过程,因此这个计数器统计的就是该方法循环执行的绝对次数。当计数器溢出的时候,它还会把方法计数器的值也调整到溢出状态,这样下次再进入该方法的时候就会执行标准编译过程。
- 虚拟机运行在客户端模式下,回边计数器阈值计算公式为:方法调用计数器阈值(
¶2>基于采样的热点探测
除了HotSpot采用的计数器探测法,另外还有一种方法是基于采样的热点探测(Sample Based Hot Spot Code Detection)。采用这种方法的虚拟机会周期性地检查各个线程的调用栈顶,如果发现某个(或某些)方法经常出现在栈顶,那这个方法就是“热点方法”。
基于采样的热点探测的好处是实现简单高效,还可以很容易地获取方法调用关系(将调用堆栈展开即可),缺点是很难精确地确认一个方法的热度,容易因为受到线程阻塞或别的外界因素的影响而扰乱热点探测。
¶6.3.3、编译过程
在默认条件下,无论是方法调用产生的标准编译请求,还是栈上替换编译请求,虚拟机在编译器还未完成编译之前,都仍然将按照解释方式继续执行代码,而编译动作则在后台的编译线程中进行。
用户可以通过参数-XX:-BackgroundCompilation来禁止后台编译,后台编译被禁止后,当达到触发即时编译的条件时,执行线程向虚拟机提交编译请求以后将会一直阻塞等待,直到编译过程完成再开始执行编译器输出的本地代码。
那在后台执行编译的过程中,编译器具体会做什么事情呢?服务端编译器和客户端编译器的编译过程是有所差别的。
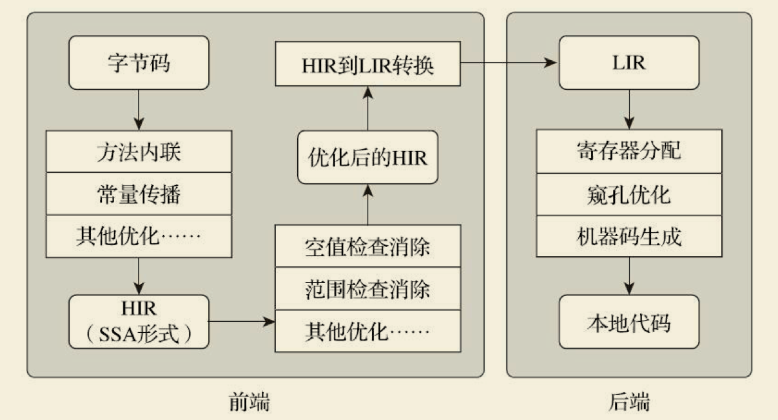
¶客户端编译期
对于客户端编译器来说,它是一个相对简单快速的三段式编译器,主要的关注点在于局部性的优化,而放弃了许多耗时较长的全局优化手段。
- 在第一个阶段,一个平台独立的前端将字节码构造成一种高级中间代码表示(High-Level Intermediate Representation,HIR,即与目标机器指令集无关的中间表示)。HIR使用静态单分配(Static Single Assignment,SSA)的形式来代表代码值,这可以使得一些在HIR的构造过程之中和之后进行的优化动作更容易实现。在此之前编译器已经会在字节码上完成一部分基础优化,如方法内联、常量传播等优化将会在字节码被构造成HIR之前完成。
- 在第二个阶段,一个平台相关的后端从HIR中产生低级中间代码表示(Low-Level Intermediate Representation,LIR,即与目标机器指令集相关的中间表示),而在此之前会在HIR上完成另外一些优化,如空值检查消除、范围检查消除等,以便让HIR达到更高效的代码表示形式。
- 最后的阶段是在平台相关的后端使用线性扫描算法(Linear Scan Register Allocation)在LIR上分配寄存器,并在LIR上做窥孔(Peephole)优化,然后产生机器代码。客户端编译器大致的执行过程如图
¶服务端编译期
而服务端编译器则是专门面向服务端的典型应用场景,并为服务端的性能配置针对性调整过的编译器,也是一个能容忍很高优化复杂度的高级编译器,几乎能达到GNU C++编译器使用-O2参数时的优化强度。它会执行大部分经典的优化动作,如:无用代码消除(Dead Code Elimination)、循环展开(Loop Unrolling)、循环表达式外提(Loop Expression Hoisting)、消除公共子表达式(Common Subexpression Elimination)、常量传播(Constant Propagation)、基本块重排序(Basic Block Reordering)等,还会实施一些与Java语言特性密切相关的优化技术,如范围检查消除(Range Check Elimination)、空值检查消除(Null Check Elimination,不过并非所有的空值检查消除都是依赖编译器优化的,有一些是代码运行过程中自动优化了)等。另外,还可能根据解释器或客户端编译器提供的性能监控信息,进行一些不稳定的预测性激进优化,如守护内联(Guarded Inlining)、分支频率预测(Branch Frequency Prediction)等。
服务端编译采用的寄存器分配器是一个全局图着色分配器,它可以充分利用某些处理器架构(如RISC)上的大寄存器集合。以即时编译的标准来看,服务端编译器无疑是比较缓慢的,但它的编译速度依然远远超过传统的静态优化编译器,而且它相对于客户端编译器编译输出的代码质量有很大提高,可以大幅减少本地代码的执行时间,从而抵消掉额外的编译时间开销,所以也有很多非服务端的应用选择使用服务端模式的HotSpot虚拟机来运行。
¶6.3.4、如何查看JIT编译情况
¶使用JVM参数打印编译信息
¶查看方法编译情况和方法内联情况
FastDebug或SlowDebug优化级别的HotSpot虚拟机, 需要自己编译将“–with-debug-level”参数设置为“fastdebug”或者“slowdebug”。
public static final int NUM = 15000;
public static int doubleValue(int i) { // 这个空循环用于后面演示JIT代码优化过程
for (int j = 0; j < 100000; j++) {
;
}
return i * 2;
}
public static long calcSum() {
long sum = 0;
for (int i = 1; i <= 100; i++) {
sum += doubleValue(i);
}
return sum;
}
public static void main(String[] args) {
for (int i = 0; i < NUM; i++) {
calcSum();
}
}
-XX:+PrintCompilation要求虚拟机打印编译信息,其中带有“%”的输出说明是由回边计数器触发的栈上替换编译,输出的信息中可以确认,main()、calcSum()和doubleV alue()方法已经被编译
310 1 java.lang.String::charAt (33 bytes)
329 2 org.fenixsoft.jit.Test::calcSum (26 bytes)
329 3 org.fenixsoft.jit.Test::doubleValue (4 bytes)
332 1% org.fenixsoft.jit.Test::main @ 5 (20 bytes)
加上-XX:+PrintInlining要求虚拟机打印方法内联信息,doubleV alue()方法已被内联编译到calcSum()方法中,而calcSum()方法又被内联编译到main()方法里面,所以虚拟机再次执行main()方法的时候(举例而已, main()方法当然不会运行两次),calcSum()和doubleV alue()方法是不会再被实际调用的,没有任何方法分派的开销,它们的代码逻辑都被直接内联到main()方法里面了。
273 1 java.lang.String::charAt (33 bytes)
291 2 org.fenixsoft.jit.Test::calcSum (26 bytes)
@ 9 org.fenixsoft.jit.Test::doubleValue inline (hot)
294 3 org.fenixsoft.jit.Test::doubleValue (4 bytes)
295 1% org.fenixsoft.jit.Test::main @ 5 (20 bytes)
@ 5 org.fenixsoft.jit.Test::calcSum inline (hot)
@ 9 org.fenixsoft.jit.Test::doubleValue inline (hot)
¶查看反汇编代码
自己编译或者在网上下载反汇编适配器HSDIS插件配合使用-XX: +PrintAssembly参数要求虚拟机打印编译方法的汇编代码。另外FastDebug或SlowDebug优化级别的HotSpot虚拟机才能直接支持,如果使用Product版的虚拟机,则需要在最前面加入参数-XX: +UnlockDiagnosticVMOptions打开虚拟机诊断模式。
如果没有HSDIS插件支持,也可以使用-XX:+PrintOptoAssembly(用于服务端模式的虚拟机) 或-XX:+PrintLIR(用于客户端模式的虚拟机)来输出比较接近最终结果的中间代码表示,上面代码被编译后部分反汇编(使用-XX:+PrintOptoAssembly)的输出结果如下所示。对于阅读来说,使用-XX:+PrintOptoAssembly参数输出的伪汇编结果包含了更多的信息(主要是注释),有利于人们阅读、理解虚拟机即时编译器的优化结果。
…… ……
000 B1: # N1 <- BLOCK HEAD IS JUNK Freq: 1
000 pushq rbp
subq rsp, #16 # Create frame
nop # nop for patch_verified_entry
006 movl RAX, RDX # spill
008 sall RAX, #1
00a addq rsp, 16 # Destroy frame
popq rbp
testl rax, [rip + #offset_to_poll_page] # Safepoint: poll for GC
…… ……
¶查看本地代码具体生成过程
如果除了本地代码的生成结果外,还想再进一步跟踪本地代码生成的具体过程,那可以使用参数-XX:+PrintCFGToFile(用于客户端编译器)或-XX:PrintIdealGraphFile(用于服务端编译器)要求Java虚拟机将编译过程中各个阶段的数据(譬如对客户端编译器来说包括字节码、HIR生成、LIR生成、寄存器分配过程、本地代码生成等数据)输出到文件中。然后使用Java HotSpot Client Compiler Visualizer(用于分析客户端编译器)或Ideal Graph Visualizer(用于分析服务端编译器)打开这些数据文件进行分析。
服务端编译器的中间代码表示是一种名为理想图(Ideal Graph)的程序依赖图(Program Dependence Graph,PDG),在运行Java程序的FastDebug或SlowDebug优化级别的虚拟机上的参数中加入-XX:PrintIdealGraphLevel=2、-XX:PrintIdealGraphFile=ideal.xml,即时编译后将会产生一个名为ideal.xml的文件,它包含了服务端编译器编译代码的全过程信息,可以使用Ideal Graph Visualizer对这些信息进行分析。
¶编译Ideal Graph Visualizer及使用
上面地址里面的是基于JDK7版本的,8及以上都不能用。打算自己基于open jdk9版本编译一份出来,记录下编译步骤:
-
下载ant构建工具并配置环境变量
ANT_HOME=${ANT路径}、PATH=$PATH:$ANT_HOME/bin -
进入openjdk IdealGraphVisualizer路径:
${openjdk9 sourcecode 根路径}/hotspot/src/share/tools/IdealGraphVisualizer/ -
参考目录下的
README.md进行编译,直接运行ant build,但是遇到以下问题:-
下载
tasks.jar超时:download: [echo] Downloading clusters ide|platform [get] Getting: http://deadlock.netbeans.org/hudson/job/nbms-and-javadoc/lastSuccessfulBuild/artifact/nbbuild/netbeans/harness/tasks.jar [get] To: /var/folders/82/yy1bqb7s141_3m40prm43xz40000gn/T/tasks.jar [get] Error getting http://deadlock.netbeans.org/hudson/job/nbms-and-javadoc/lastSuccessfulBuild/artifact/nbbuild/netbeans/harness/tasks.jar to /var/folders/82/yy1bqb7s141_3m40prm43xz40000gn/T/tasks.jar BUILD FAILED /Users/zhonghongpeng/ClionProjects/jvm/openjdk/hotspot/src/share/tools/IdealGraphVisualizer/build.xml:7: The following error occurred while executing this line: /Users/zhonghongpeng/ClionProjects/jvm/openjdk/hotspot/src/share/tools/IdealGraphVisualizer/nbproject/build-impl.xml:41: The following error occurred while executing this line: /Users/zhonghongpeng/ClionProjects/jvm/openjdk/hotspot/src/share/tools/IdealGraphVisualizer/nbproject/platform.xml:27: java.net.ConnectException: Operation timed out (Connection timed out)解决:
参考了以下链接的描述将
./nbproject/platform.properties中的bootstrap.url属性设置成http://bits.netbeans.org/dev/nbms-and-javadoc/lastSuccessfulBuild/artifact/nbbuild/netbeans/harness/tasks.jar。 -
下载的
catalog.xml.gz文件有问题[autoupdate] Downloading http://updates.netbeans.org/netbeans/updates/7.4/uc/final/distribution/catalog.xml.gz [autoupdate] 九月 23, 2020 9:37:32 上午 org.netbeans.nbbuild.AutoUpdateCatalogParser getInputSource [autoupdate] 信息: The file at http://updates.netbeans.org/netbeans/updates/7.4/uc/final/distribution/catalog.xml.gz, corresponding to the catalog at http://updates.netbeans.org/netbeans/updates/7.4/uc/final/distribution/catalog.xml.gz, does not look like the gzip file, trying to parse it as the pure xml [autoupdate] java.io.EOFException [autoupdate] at java.util.zip.GZIPInputStream.readUByte(GZIPInputStream.java:268) [autoupdate] at java.util.zip.GZIPInputStream.readUShort(GZIPInputStream.java:258) [autoupdate] at java.util.zip.GZIPInputStream.readHeader(GZIPInputStream.java:164)解决:
参考
https://stackoverflow.com/questions/54326975/unable-to-connect-to-the-netbeans-distribution-because-of-zero-sized-file将./nbproject/platform.properties中的autoupdate.catalog.url属性的"http"改成"https"。
-
-
构建完成后授权执行即可:
zhonghongpeng@bogon IdealGraphVisualizer % chmod 777 ./igv.sh zhonghongpeng@bogon IdealGraphVisualizer % ./igv.sh -
使用参数
-XX:PrintIdealGraphLevel=2 -XX:PrintIdealGraphFile=ideal.xml -Xbatch运行上面的代码得到多份ideal<n>.xml(注意参考README.md,其中就说明了最后一个参数如果不加将会导致程序结束后dump的xml文件不完整,导入到Ideal Graph Visualizer会报错)
在Ideal Graph Visualizer中全部打开即可进行查看
¶利用一些监控工具查看编译情况
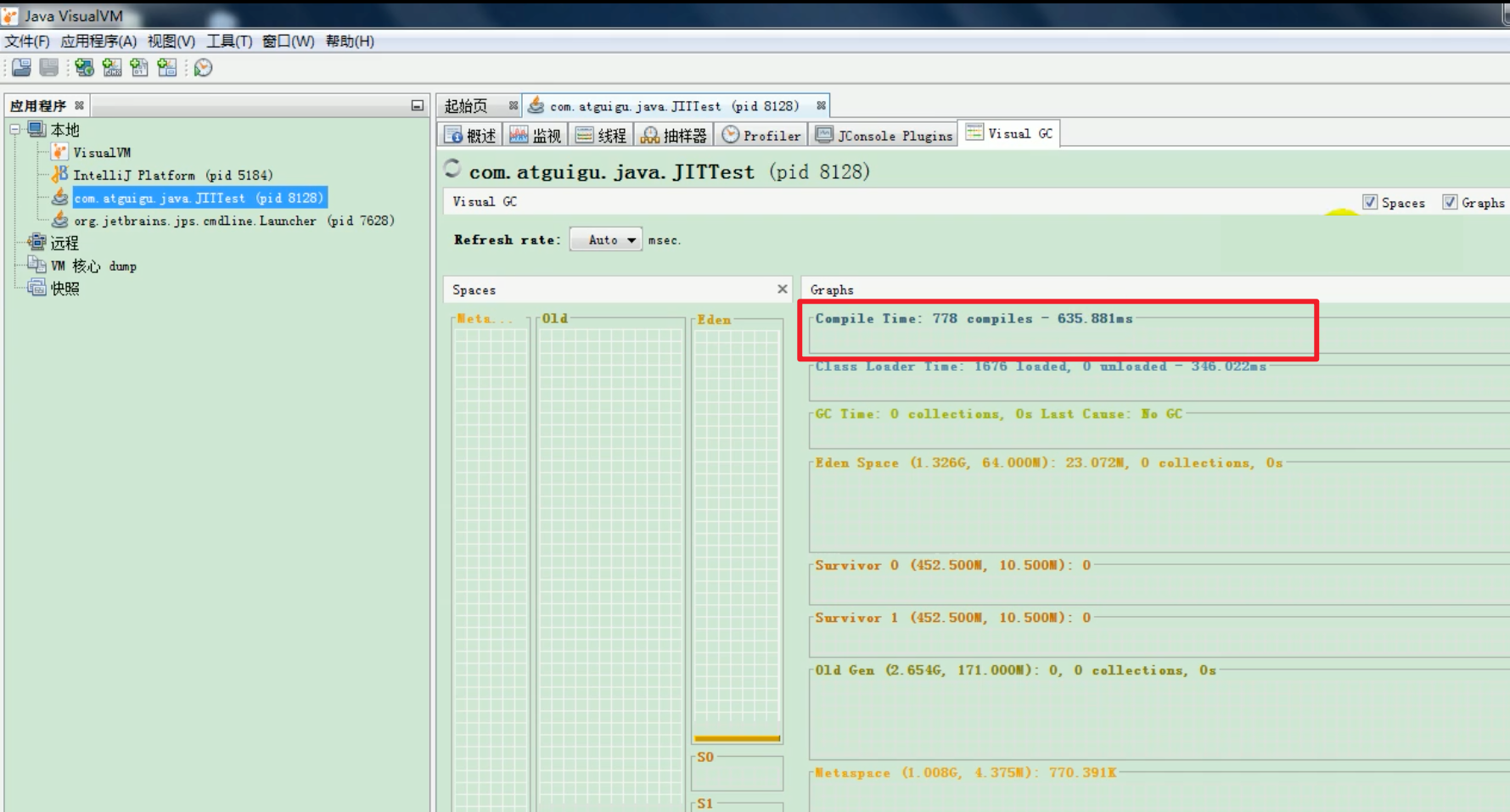
¶VisualVM查看编译次数和时间
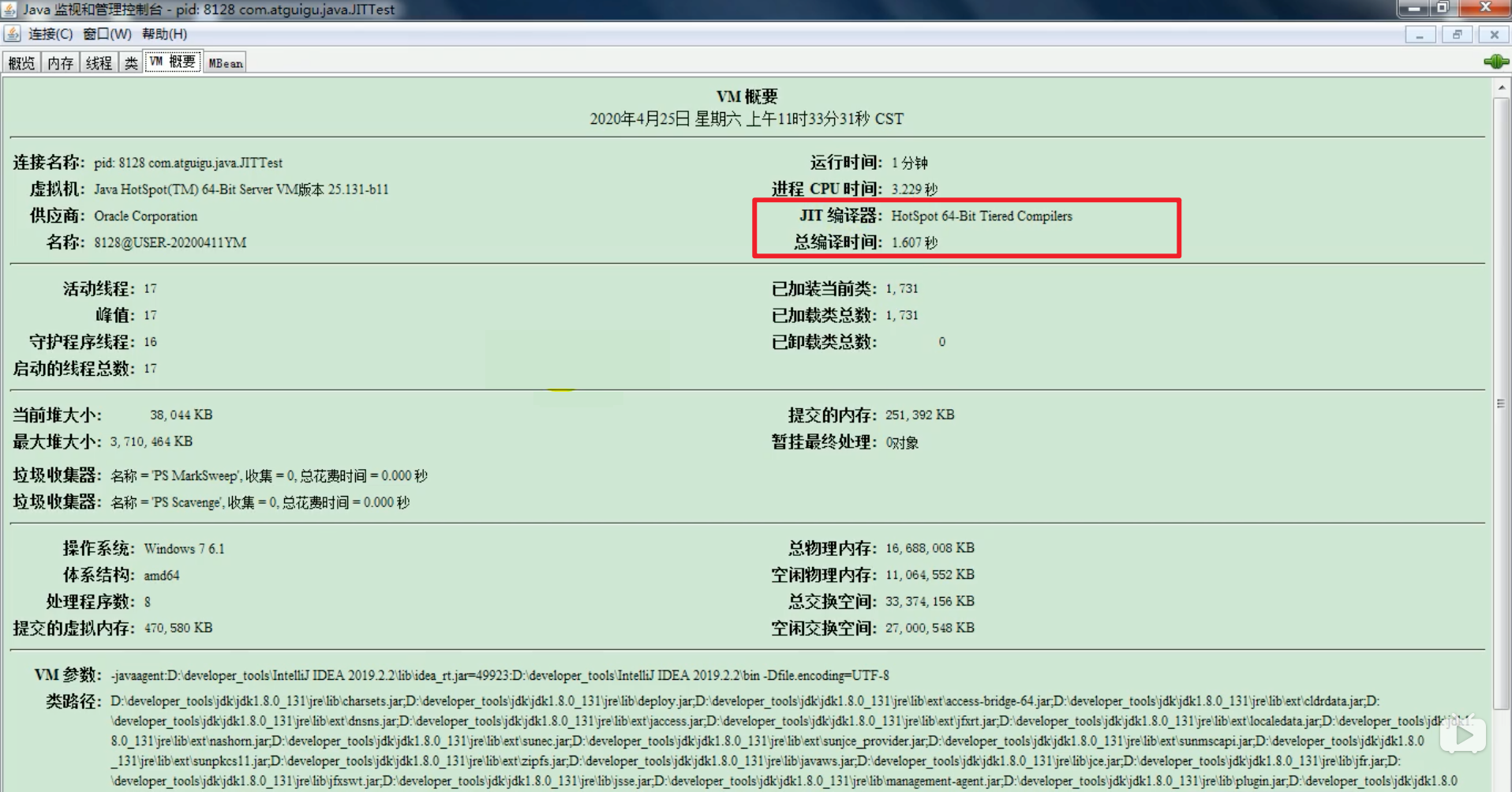
¶Jconsole查看
¶6.3.5、分层优化
由于即时编译器编译本地代码需要占用程序运行时间,通常要编译出优化程度越高的代码,所花费的时间便会越长;而且想要编译出优化程度更高的代码,解释器可能还要替编译器收集性能监控信息,这对解释执行阶段的速度也有所影响。为了在程序启动响应速度与运行效率之间达到最佳平衡, HotSpot虚拟机在编译子系统中加入了分层编译的功能[2],分层编译的概念其实很早就已经提出,但直到JDK 6时期才被初步实现,后来一直处于改进阶段,最终在JDK 7的服务端模式虚拟机中作为默认编译策略被开启。分层编译根据编译器编译、优化的规模与耗时,划分出不同的编译层次,其中包括:
- 第0层。程序纯解释执行,并且解释器不开启性能监控功能(Profiling)。
- 第1层。使用客户端编译器将字节码编译为本地代码来运行,进行简单可靠的稳定优化,不开启性能监控功能。
- 第2层。仍然使用客户端编译器执行,仅开启方法及回边次数统计等有限的性能监控功能。
- 第3层。仍然使用客户端编译器执行,开启全部性能监控,除了第2层的统计信息外,还会收集如分支跳转、虚方法调用版本等全部的统计信息。
- 第4层。使用服务端编译器将字节码编译为本地代码,相比起客户端编译器,服务端编译器会启用更多编译耗时更长的优化,还会根据性能监控信息进行一些不可靠的激进优化。
实施分层编译后,解释器、客户端编译器和服务端编译器就会同时工作,热点代码都可能会被多次编译,用客户端编译器获取更高的编译速度,用服务端编译器来获取更好的编译质量,在解释执行的时候也无须额外承担收集性能监控信息的任务,而在服务端编译器采用高复杂度的优化算法时,客户端编译器可先采用简单优化来为它争取更多的编译时间。
¶配置执行引擎运行方式
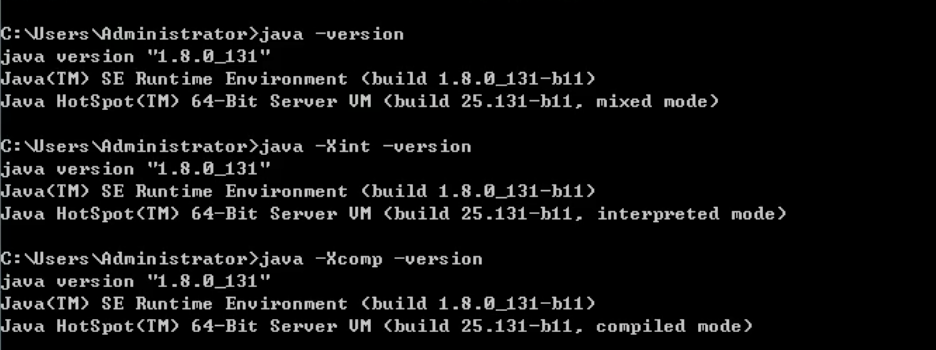
缺省情况下 HotSpot VM是采用解释器与即时编译器并存的架构,当然开发人员可以根据具体的应用场景,通过命令显式地为Java虚拟机指定在运行时到底是完全采用解释器执行,还是完全采用即时编译器执行。如下所示:
-Xint:完全采用解释器模式执行程序
-Xcomp:完全采用即时编译器模式执行程序。如果即时编译出现问题,解释器会介入执行。
-Xmixed:采用解释器+即时编译器的混合模式共同执行程序
¶6.3.6、编译器优化技术
¶优化技术概览


**即时编译器对这些代码优化变换是建立在源代码转换得的中间表示或者是机器码之上的,绝不是直接在Java源码上去做的。**下面仅仅基于Java源码作一个比喻:
¶代码示例
static class B {
int value;
final int get() {
return value;
}
}
public void foo() {
y = b.get();
// ...do stuff...
z = b.get();
sum = y + z;
}
- 方法内联,它的主要目的有两个:一是去除方法调用的成本(如查找方法版本、建立栈帧等); 二是为其他优化建立良好的基础。方法内联膨胀之后可以便于在更大范围上进行后续的优化手段,可以获取更好的优化效果。因此各种编译器一般都会把内联优化放在优化序列最靠前的位置。内联后的代码:
public void foo() {
y = b.value;
// ...do stuff...
z = b.value;
sum = y + z;
}
- 冗余访问消除(Redundant Loads Elimination),假设代码中间注释掉的
…do stuff…所代表的操作不会改变b.value的值,那么就可以把z=b.value替换为z=y,因为上一句y=b.value已经保证了变量y与b.value是一致的,这样就可以不再去访问对象b的局部变量了。如果把b.value看作一个表达式,那么也可以把这项优化看作一种公共子表达式消除(Common Subexpression Elimination)
public void foo() {
y = b.value;
// ...do stuff...
z = y;
sum = y + z;
}
- 复写传播(Copy Propagation),因为这段程序的逻辑之中没有必要使用一个额外的变量z,它与变量y是完全相等的,因此我们可以使用y来代替z。
public void foo() {
y = b.value;
// ...do stuff...
y = y;
sum = y + y;
}
- 无用代码消除(Dead Code Elimination),无用代码可能是永远不会被执行的代码,也可能是完全没有意义的代码。因此它又被很形象地称为“Dead Code”, 如
y=y是没有意义的
public void foo() {
y = b.value;
// ...do stuff...
sum = y + y;
}
最终优化出来得代码达到的效果是一致的,但是前者比后者省略了许多语句,体现在字节码和机器码指令上的差距会更大,执行效率的差距也会更高。
¶最重要的优化技术之一:方法内联
方法内联,说它是编译器最重要的优化手段,甚至都可以不加上“之一”。内联被业内戏称为优化之母,因为除了消除方法调用的成本之外,它更重要的意义是为其他优化手段建立良好的基础
public static void foo(Object obj) {
if (obj != null) {
System.out.println("do something");
}
}
public static void testInline(String[] args) {
Object obj = null;
foo(obj);
}
以上所示的简单例子就揭示了内联对其他优化手段的巨大价值:没有内联,多数其他优化都无法有效进行。例子里testInline()方法的内部全部是无用的代码,但如果不做内联,后续即使进行了无用代码消除的优化,也无法发现任何“Dead Code”的存在。如果分开来看,foo()和testInline()两个方法里面的操作都有可能是有意义的。
方法内联的优化行为理解起来是没有任何困难的,不过就是把目标方法的代码原封不动地“复制”到发起调用的方法之中,避免发生真实的方法调用而已。但实际上Java虚拟机中的内联过程却远没有想象中容易,甚至如果不是即时编译器做了一些特殊的努力,按照经典编译原理的优化理论,大多数的Java方法都无法进行内联。
无法内联的原因:只有使用invokespecial指令调用的私有方法、实例构造器、父类方法和使用invokestatic指令调用的静态方法才会在编译期进行解析。除了上述四种方法之外(最多再除去被final修饰的方法这种特殊情况,尽管它使用invokevirtual指令调用,但也是非虚方法,《Java语言规范》中明确说明了这点),其他的Java方法调用都必须在运行时进行方法接收者的多态选择,它们都有可能存在多于一个版本的方法接收者,简而言之,Java语言中默认的实例方法是虚方法。
对于一个虚方法,编译器静态地去做内联的时候很难确定应该使用哪个方法版本, 如果不依赖上下文,是无法确定b的实际类型是什么的。假如有ParentB和SubB是两个具有继承关系的父子类型,并且子类重写了父类的get()方法,那么此时对象obj.get()是执行父类的get()方法还是子类的get()方法,这应该是根据实际类型动态分派的,而实际类型必须在实际运行到这一行代码时才能确定,编译器很难在编译时得出绝对准确的结论。
更糟糕的情况是,由于Java提倡使用面向对象的方式进行编程,而Java对象的方法默认就是虚方法,可以说Java间接鼓励了程序员使用大量的虚方法来实现程序逻辑。根据上面的分析可知,内联与虚方法之间会产生“矛盾”,那是不是为了提高执行性能,就应该默认给每个方法都使用final关键字去修饰呢(即由程序员通过编译器约定的关键字来告诉编译器那些虚方法可以进行内联)?
- C和C++语言的确是这样做的,默认的方法是非虚方法,如果需要用到多态,就用
virtual关键字来修饰 - 但Java选择了在虚拟机中解决这个问题。
为了解决虚方法的内联问题,Java虚拟机首先引入了一种名为类型继承关系分析(Class Hierarchy Analysis,CHA)的技术,这是整个应用程序范围内的类型分析技术,用于确定在目前已加载的类中,某个接口是否有多于一种的实现、某个类是否存在子类、某个子类是否覆盖了父类的某个虚方法等信息。这样,编译器在进行内联时就会分不同情况采取不同的处理:
-
如果是非虚方法,那么直接进行内联就可以了,这种的内联是有百分百安全保障的;
-
如果遇到虚方法,则会向CHA查询此方法在当前程序状态下是否真的有多个目标版本可供选择:
-
如果查询到只有一个版本,那就可以假设“应用程序的全貌就是现在运行的这个样子”来进行内联,这种内联被称为守护内联(Guarded Inlining)。
不过由于Java程序是动态连接的,说不准什么时候就会加载到新的类型从而改变CHA结论,因此这种内联属于激进预测性优化,必须预留好“逃生门”,即当假设条件不成立时的“退路”(Slow Path)。假如在程序的后续执行过程中**,虚拟机一直没有加载到会令这个方法的接收者的继承关系发生变化的类**,那这个内联优化的代码就可以一直使用下去。如果加载了导致继承关系发生变化的新类,那么就必须抛弃已经编译的代码,退回到解释状态进行执行,或者重新进行编译。
-
假如向CHA查询出来的结果是该方法确实有多个版本的目标方法可供选择,那即时编译器还将进行最后一次努力,使用内联缓存(Inline Cache)的方式来缩减方法调用的开销。这种状态下方法调用是真正发生了的,但是比起直接查虚方法表还是要快一些。内联缓存是一个建立在目标方法正常入口之前的缓存,它的工作原理大致为:
在未发生方法调用之前,内联缓存状态为空,当第一次调用发生后,缓存记录下方法接收者的版本信息,并且每次进行方法调用时都比较接收者的版本。
- 如果以后进来的每次调用的方法接收者版本都是一样的,那么这时它就是一种单态内联缓存(Monomorphic Inline Cache)。通过该缓存来调用,比用不内联的非虚方法调用,仅多了一次类型判断的开销而已。
- 但如果真的出现方法接收者不一致的情况,就说明程序用到了虚方法的多态特性,这时候会退化成超多态内联缓存(Megamorphic Inline Cache),其开销相当于真正查找虚方法表来进行方法分派。
-
所以说,在多数情况下Java虚拟机进行的方法内联都是一种激进优化。事实上,激进优化的应用在高性能的Java虚拟机中比比皆是,极为常见。除了方法内联之外,对于出现概率很小(通过经验数据或解释器收集到的性能监控信息确定概率大小)的隐式异常、使用概率很小的分支等都可以被激进优化“移除”,如果真的出现了小概率事件,这时才会从“逃生门”回到解释状态重新执行。
¶最前沿的优化技术之一:逃逸分析
逃逸分析(Escape Analysis)是目前Java虚拟机中比较前沿的优化技术,它与类型继承关系分析一样,并不是直接优化代码的手段,而是为其他优化措施提供依据的分析技术。
逃逸分析的基本原理是分析对象动态作用域,当一个对象在方法里面被定义后,它可能被外部方法所引用:
- 例如作为调用参数或者返回值传递到其他方法中、赋值到全局变量中,这种称为方法逃逸
- 甚至还有可能被外部线程访问到,譬如赋值给可以在其他线程中访问的实例变量,这种称为线程逃逸
从不逃逸、方法逃逸到线程逃逸,称为对象由低到高的不同逃逸程度。
如果能证明一个对象不会逃逸到方法或线程之外(换句话说是别的方法或线程无法通过任何途径访问到这个对象),或者逃逸程度比较低(只逃逸出方法而不会逃逸出线程),则可能为这个对象实例采取不同程度的优化,如:
¶1>栈上分配(Stack Allocations)[3]
在Java虚拟机中,Java堆上分配创建对象的内存空间几乎是Java程序员都知道的常识,Java堆中的对象对于各个线程都是共享和可见的,只要持有这个对象的引用,就可以访问到堆中存储的对象数据。虚拟机的垃圾收集子系统会回收堆中不再使用的对象,但回收动作无论是标记筛选出可回收对象,还是回收和整理内存,都需要耗费大量资源。如果确定一个对象不会逃逸出线程之外,那让这个对象在栈上分配内存将会是一个很不错的主意,对象所占用的内存空间就可以随栈帧出栈而销毁。在一般应用中,完全不会逃逸的局部对象和不会逃逸出线程的对象所占的比例是很大的,如果能使用栈上分配,那大量的对象就会随着方法的结束而自动销毁了,垃圾收集子系统的压力将会下降很多。栈上分配可以支持方法逃逸,但不能支持线程逃逸。
¶2>标量替换(Scalar Replacement)
若一个数据已经无法再分解成更小的数据来表示了,Java虚拟机中的原始数据类型(int、long等数值类型及reference类型等)都不能再进一步分解了,那么这些数据就可以被称为标量。相对的,如果一个数据可以继续分解,那它就被称为聚合量(Aggregate),Java 中的对象就是典型的聚合量。
这里的标量和线性代数中的标量还不是一回事
如果把一个Java对象拆散,根据程序访问的情况,将其用到的成员变量恢复为原始类型来访问,这个过程就称为标量替换。假如逃逸分析能够证明一个对象不会被方法外部访问,并且这个对象可以被拆散,那么程序真正执行的时候将可能不去创建这个对象,而改为直接创建它的若干个被这个方法使用的成员变量来代替。将对象拆分后,除了可以让对象的成员变量在栈上(栈上存储的数据,很大机会被虚拟机分配至物理机器的高速寄存器中存储)分配和读写之外,还可以为后续进一步的优化手段创建条件。标量替换可以视作栈上分配的一种特例,实现更简单(不用考虑整个对象完整结构的分配),但对逃逸程度的要求更高,它不允许对象逃逸出方法范围内。
¶3>同步消除(Synchronization Elimination)
线程同步本身是一个相对耗时的过程,如果逃逸分析能够确定一个变量不会逃逸出线程,无法被其他线程访问,那么这个变量的读写肯定就不会有竞争, 对这个变量实施的同步措施也就可以安全地消除掉。
线程同步的代价是相当高的,同步的后果是降低并发性和性能。同步锁消除能大大提高并发性能。

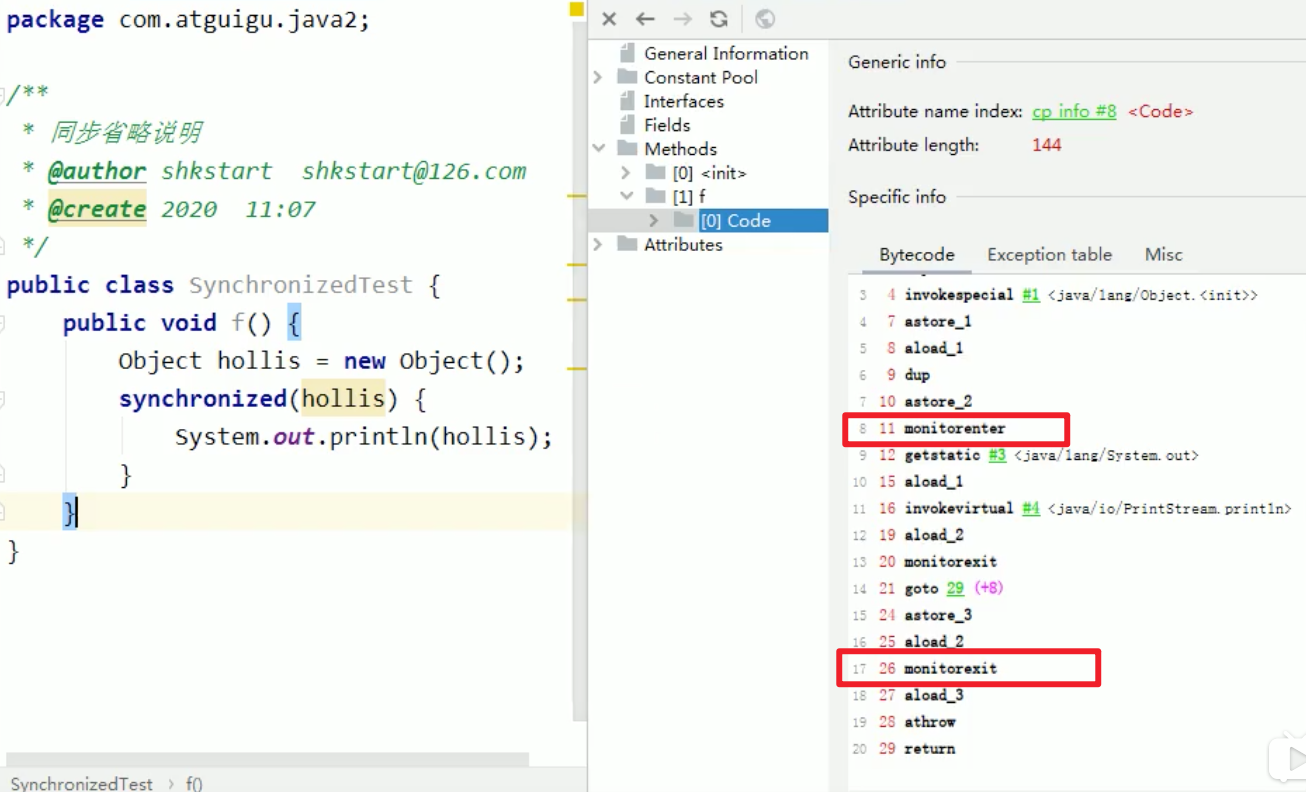
以下方法锁对象未发生逃逸,在转换成字节码之后,可以看到还是有加锁字节码指令的,所以前端编译器完全没有参与到逃逸分析和同步锁消除得过程,它完全依赖后端(JIT)编译器。
¶逃逸分析发展
关于逃逸分析的研究论文早在1999年就已经发表,但直到JDK 6,HotSpot才开始支持初步的逃逸分析,而且到现在这项优化技术尚未足够成熟,仍有很大的改进余地。不成熟的原因主要是逃逸分析的计算成本非常高,甚至不能保证逃逸分析带来的性能收益会高于它的消耗。如果要百分之百准确地判断一个对象是否会逃逸,需要进行一系列复杂的数据流敏感的过程间分析,才能确定程序各个分支执行时对此对象的影响。前面介绍即时编译、提前编译优劣势时提到了过程间分析这种大压力的分析算法正是即时编译的弱项。可以试想一下,如果逃逸分析完毕后发现几乎找不到几个不逃逸的对象, 那这些运行期耗用的时间就白白浪费了,所以目前虚拟机只能采用不那么准确,但时间压力相对较小的算法来完成分析。
在实际的应用程序中,尤其是大型程序中反而发现实施逃逸分析可能出现效果不稳定的情况,或分析过程耗时但却无法有效判别出非逃逸对象而导致性能(即时编译的收益)下降,所以曾经在很长的一段时间里,即使是服务端编译器,也默认不开启逃逸分析[4],甚至在某些版本(如JDK 6 Update 18)中还曾经完全禁止了这项优化,一直到JDK 7时这项优化才成为服务端编译器默认开启的选项。如果有需要,或者确认对程序运行有益,用户也可以使用参数-XX:+DoEscapeAnalysis来手动开启逃逸分析, 开启之后可以通过参数-XX:+PrintEscapeAnalysis来查看分析结果。有了逃逸分析支持之后,用户可以使用参数-XX:+EliminateAllocations来开启标量替换,使用+XX:+EliminateLocks来开启同步消除,使用参数-XX:+PrintEliminateAllocations查看标量的替换情况。
¶逃逸分析优化示例
C和C++语言里面原生就支持了栈上分配(不使用new操作符即可)。
而C#也支持值类型,可以很自然地做到标量替换(但并不会对引用类型做这种优化)。
在灵活运用栈内存方面,确实是Java的一个弱项。在现在仍处于实验阶段的Valhalla项目里,设计了新的inline关键字用于定义Java的内联类型, 目的是实现与C#中值类型相对标的功能。有了这个标识与约束,以后逃逸分析做起来就会简单很多。
// 完全未优化的代码
public int test(int x) {
int xx = x + 2;
Point p = new Point(xx, 42);
return p.getX();
}
// 步骤1:将Point的构造函数和getX()方法进行内联优化
public int test(int x) {
int xx = x + 2;
Point p = point_memory_alloc(); // 在堆中分配P对象的示意方法
p.x = xx; // Point构造函数被内联后的样子
p.y = 42
return p.x; // Point::getX()被内联后的样子
}
// 步骤2:经过逃逸分析,发现在整个test()方法的范围内Point对象实例不会发生任何程度的逃逸, 这样可以对它进行标量替换优化,把其内部的x和y直接置换出来,分解为test()方法内的局部变量,从而避免Point对象实例被实际创建
public int test(int x) {
int xx = x + 2;
int px = xx;
int py = 42
return px;
}
// 步骤3:通过数据流分析,发现py的值其实对方法不会造成任何影响,那就可以放心地去做无效代码消除得到最终优化结果
public int test(int x) {
return x + 2;
}
¶参考阅读
¶语言无关的经典优化技术之一:公共子表达式消除
公共子表达式消除是一项非常经典的、普遍应用于各种编译器的优化技术,它的含义是:如果一个表达式E之前已经被计算过了,并且从先前的计算到现在E中所有变量的值都没有发生变化,那么E 的这次出现就称为公共子表达式。对于这种表达式,没有必要花时间再对它重新进行计算,只需要直接用前面计算过的表达式结果代替E。如果这种优化仅限于程序基本块内,便可称为局部公共子表达式消除(Local Common Subexpression Elimination),如果这种优化的范围涵盖了多个基本块,那就称为全局公共子表达式消除(Global Common Subexpression Elimination)。
基本块可以通俗理解为一个没有嵌套的大括号范围,如:
if语句块、while语句块等。
int d = (c * b) * 12 + a + (a + b * c);
如果这段代码交给Javac编译器则不会进行任何优化,那生成的代码如下
iload_2 // b
imul // 计算b*c
bipush 12 // 推入12
imul // 计算(c * b) * 12
iload_1 // a
iadd // 计算(c * b) * 12 + a
iload_1 // a
iload_2 // b
iload_3 // c
imul // 计算b * c
iadd // 计算a + b * c
iadd // 计算(c * b) * 12 + a + a + b * c
istore 4
当这段代码进入虚拟机即时编译器后,它将进行如下优化:编译器检测到cb与bc是一样的表达式,而且在计算期间b与c的值是不变的。因此这条表达式就可能被视为:
int d = E * 12 + a + (a + E);
这时候,编译器还可能(取决于哪种虚拟机的编译器以及具体的上下文而定)进行另外一种优化——代数化简(Algebraic Simplification),在E本来就有乘法运算的前提下,把表达式变为:
int d = E * 13 + a + a;
¶语言相关的经典优化技术之一:数组边界检查消除
组边界检查消除(Array Bounds Checking Elimination)是即时编译器中的一项语言相关的经典优化技术。我们知道Java语言是一门动态安全的语言,对数组的读写访问也不像C、C++那样实质上就是裸指针操作。如果有一个数组foo[],在Java语言中访问数组元素foo[i]的时候系统将会自动进行上下界的范围检查,即i必须满足i>=0&&i<foo.length的访问条件,否则将抛出一个运行时异常: java.lang.ArrayIndexOutOfBoundsException。这对软件开发者来说是一件很友好的事情,即使程序员没有专门编写防御代码,也能够避免大多数的溢出攻击。但是对于虚拟机的执行子系统来说,每次数组元素的读写都带有一次隐含的条件判定操作,对于拥有大量数组访问的程序代码,这必定是一种性能负担。
无论如何,为了安全,数组边界检查肯定是要做的,但数组边界检查是不是必须在运行期间一次不漏地进行则是可以“商量”的事情。例如:
-
下面这个简单的情况:数组下标是一个常量,如
foo[3],只要在编译期根据数据流分析来确定foo.length的值,并判断下标3没有越界,就去掉检查的代码, 在执行的时候就没有了检查边界的那一步了。 -
更加常见的情况是,数组访问发生在循环之中,并且使用循环变量来进行数组的访问。如果编译器只要通过数据流分析就可以判定循环变量的取值范围永远在区间
[0,foo.length)之内,那么在循环中就可以把整个数组的上下界检查消除掉,这可以节省很多次的条件判断操作。 -
把这个数组边界检查的例子放在更高的视角来看,大量的安全检查使编写Java程序比编写C和C程序容易了很多,比如:数组越界会得到
ArrayIndexOutOfBoundsException异常;空指针访问会得到NullPointException异常;除数为零会得到ArithmeticException异常……在C和C程序中出现类似的问题,一个不小心就会出现Segment Fault信号或者Windows编程中常见的“XXX内存不能为Read/Write”之类的提示,处理不好程序就直接崩溃退出了。但这些安全检查也导致出现相同的程序, 从而使Java比C和C++要做更多的事情(各种检查判断),这些事情就会导致一些隐式开销,如果不处理好它们,就很可能成为一项“Java语言天生就比较慢”的原罪。为了消除这些隐式开销,除了如数组边界检查优化这种尽可能把运行期检查提前到编译期完成的思路之外,还有一种避开的处理思路——隐式异常处理,Java中空指针检查和算术运算中除数为零的检查都采用了这种方案:
虚拟机会注册一个
Segment Fault信号的异常处理器,此时不用进行任何检查,而代价就是发生空指针调用或者除0的时候,必须转到异常处理器中恢复中断并抛出NullPointException或者ArithmeticException异常。进入异常处理器的过程涉及进程从用户态转到内核态中处理的过程,结束后会再回到用户态,速度远比一次判空检查要慢得多。当这样的错误发生极少的时候,隐式异常优化是值得的,但假如发生很频繁,这样的优化反而会让程序更慢。幸好HotSpot虚拟机足够聪明,它会根据运行期收集到的性能监控信息自动选择最合适的方案。
¶6.4、提前编译器:AOT
前编译在Java技术体系中并不是新事物。1996年JDK 1.0发布,Java有了正式的运行环境,第一个可以使用外挂即时编译器的Java版本是1996年7月发布的JDK 1.0.2,而Java提前编译器的诞生并没有比这晚多少。仅几个月后,IBM公司就推出了第一款用于Java语言的提前编译器(IBM High Performance Compiler for Java)。在1998年,GNU组织公布了著名的GCC家族(GNU Compiler Collection)的新成员GNU Compiler for Java(GCJ,2018年从GCC家族中除名),这也是一款Java的提前编译器[1],而且曾经被广泛应用。在OpenJDK流行起来之前,各种Linux发行版带的Java实现通常就是GCJ。
但是提前编译很快又在Java世界里沉寂了下来,因为当时Java的一个核心优势是平台中立性,其宣传口号是“一次编译,到处运行”,这与平台相关的提前编译在理念上就是直接冲突的。GCJ出现之后在长达15年的时间里,提前编译这条故事线上基本就再没有什么大的新闻和进展了。
现在提前编译产品和对其的研究有着两条明显的分支:
- 一条分支是做与传统C、C++编译器类似的,在程序运行之前把程序代码编译成机器码的静态翻译工作,这是传统的提前编译应用形式:
- 它在Java中存在的价值直指即时编译的最大弱点即时编译要占用程序运行时间和运算资源。即使现在先进的即时编译器已经足够快,但是,无论如何,即时编译消耗的时间都是原本可用于程序运行的时间,消耗的运算资源都是原本可用于程序运行的资源,这个约束从未减弱,更不会消失。在编译过程中最耗时的优化措施之一是通过“过程间分析”(Inter-Procedural Analysis,IPA,也经常被称为全程序分析,即Whole Program Analysis)来获得诸如某个程序点上某个变量的值是否一定为常量、某段代码块是否永远不可能被使用、在某个点调用的某个虚方法是否只能有单一版本等的分析结论。这些信息对生成高质量的优化代码有着极为巨大的价值,但是要精确(譬如对流敏感、对路径敏感、对上下文敏感、对字段敏感)得到这些信息, 必须在全程序范围内做大量极耗时的计算工作,目前所有常见的Java虚拟机对过程间分析的支持都相当有限,要么借助大规模的方法内联来打通方法间的隔阂,以过程内分析(Intra-Procedural Analysis, 只考虑过程内部语句,不考虑过程调用的分析)来模拟过程间分析的部分效果;要么借助可假设的激进优化,不求得到精确的结果,只求按照最可能的状况来优化,有问题再退回来解析执行。
- 但如果是在程序运行之前进行的静态编译,这些耗时的优化就可以放心大胆地进行了,譬如Graal VM中的Substrate VM,在创建本地镜像的时候,就会采取许多原本在HotSpot即时编译中并不会做的全程序优化措施以获得更好的运行时性能,反正做镜像阶段慢一点并没有什么大影响。
- 另外一条分支是把原本即时编译器在运行时要做的编译工作提前做好并保存下来,下次运行到这些代码(譬如公共库代码在被同一台机器其他Java进程使用)时直接把它加载进来使用。本质是给即时编译器做缓存加速,去改善Java程序的启动时间,以及需要一段时间预热后才能到达最高性能的问题。这种提前编译被称为动态提前编译(Dynamic AOT)或者索性就大大方方地直接叫即时编译缓存(JIT Caching)。
- 真正引起业界普遍关注的是OpenJDK/OracleJDK 9中所带的Jaotc提前编译器,这是一个基于Graal编译器实现的新工具,目的是让用户可以针对目标机器,为应用程序进行提前编译。HotSpot运行时可以直接加载这些编译的结果,实现加快程序启动速度,减少程序达到全速运行状态所需时间的目的。这里面确实有比较大的优化价值,试想一下,各种Java应用最起码会用到Java的标准类库,如java.base等模块,如果能够将这个类库提前编译好,并进行比较高质量的优化,显然能够节约不少应用运行时的编译成本。
- 这的确是很好的想法,但实际应用起来并不是那么容易,原因是这种提前编译方式不仅要和目标机器相关,甚至还必须与HotSpot虚拟机的运行时参数绑定。譬如虚拟机运行时采用了不同的垃圾收集器,这原本就需要即时编译子系统的配合(典型的如生成内存屏障代码,见第3章相关介绍)才能正确工作,要做提前编译的话,自然也要把这些配合的工作平移过去。至于前面提到过的提前编译破坏平台中立性、字节膨胀等缺点当然还存在,这里就不重复了。尽管还有许多困难,但提前编译无疑已经成为一种极限榨取性能(启动、响应速度)的手段,且被官方JDK关注,相信日后会更加灵活、更加容易使用
¶和JIT编译对比
¶性能分析制导优化(Profile-Guided Optimization,PGO)
在解释器或者客户端编译器运行过程中,会不断收集性能监控信息,譬如某个程序点抽象类通常会是什么实际类型、条件判断通常会走哪条分支、方法调用通常会选择哪个版本、循环通常会进行多少次等,这些数据一般在静态分析时是无法得到的,或者不可能存在确定且唯一的解, 最多只能依照一些启发性的条件去进行猜测。但在动态运行时却能看出它们具有非常明显的偏好性。
如果一个条件分支的某一条路径执行特别频繁,而其他路径鲜有问津,那就可以把热的代码集中放到一起,集中优化和分配更好的资源(分支预测、寄存器、缓存等)给它。
¶激进预测性优化(Aggressive Speculative Optimization)
这也已经成为很多即时编译优化措施的基础。静态优化无论如何都必须保证优化后所有的程序外部可见影响(不仅仅是执行结果) 与优化前是等效的,不然优化之后会导致程序报错或者结果不对,若出现这种情况,则速度再快也是没有价值的。然而,相对于提前编译来说,即时编译的策略就可以不必这样保守,如果性能监控信息能够支持它做出一些正确的可能性很大但无法保证绝对正确的预测判断,就已经可以大胆地按照高概率的假设进行优化,万一真的走到罕见分支上,大不了退回到低级编译器甚至解释器上去执行,并不会出现无法挽救的后果。只要出错概率足够低,这样的优化往往能够大幅度降低目标程序的复杂度, 输出运行速度非常高的代码。譬如在Java语言中,默认方法都是虚方法调用,部分C、C++程序员(甚至一些老旧教材)会说虚方法是不能内联的,但如果Java虚拟机真的遇到虚方法就去查虚表而不做内联的话,Java技术可能就已经因性能问题而被淘汰很多年了。实际上虚拟机会通过类继承关系分析等一系列激进的猜测去做去虚拟化(Devitalization),以保证绝大部分有内联价值的虚方法都可以顺利内联。内联是最基础的一项优化措施。(即编译期还有一个解释器逃生门)
¶链接时优化(Link-Time Optimization,LTO)
Java语言天生就是动态链接的,一个个Class文件在运行期被加载到虚拟机内存当中,然后在即时编译器里产生优化后的本地代码,这类事情在Java程序员眼里看起来毫无违和之处。但如果类似的场景出现在使用提前编译的语言和程序上,譬如C、C的程序要调用某个动态链接库的某个方法,就会出现很明显的边界隔阂,还难以优化。这是因为主程序与动态链接库的代码在它们编译时是完全独立的,两者各自编译、优化自己的代码。这些代码的作者、编译的时间,以及编译器甚至很可能都是不同的,当出现跨链接库边界的调用时,那些理论上应该要做的优化——譬如做对调用方法的内联,就会执行起来相当的困难。如果刚才说的虚方法内联让C、C程序员理解还算比较能够接受的话(其实C++编译器也可以通过一些技巧来做到虚方法内联),那这种跨越动态链接库的方法内联在他们眼里可能就近乎于离经叛道了(但实际上依然是可行的)。
¶最大好处
Java虚拟机加载已经预编译成二进制库,可以直接执行。不必等待即时编译器的预热,减少Java应用给人带来“第一次运行慢”的不良体验。
¶缺点
- 破坏了java"一次编译,到处运行”,必须为每个不同硬件、OS编译对应的发行包。
- 降低了Java链接过程的动态性,加载的代码在编译期就必须全部已知。
- 还需要继续优化中,最初只支持 Linux x64 java base
¶实战:Jaotc的提前编译
JDK 9引入了用于支持对Class文件和模块进行提前编译的工具Jaotc,以减少程序的启动时间和到达全速性能的预热时间,但由于这项功能必须针对特定物理机器和目标虚拟机的运行参数来使用,加之限制太多,Java开发人员对此了解、使用普遍比较少
我们首先通过一段测试代码(什么代码都可以,最简单的HelloWorld都可以,内容笔者就不贴了)来演示Jaotc的基本使用过程,操作如下:
$ javac HelloWorld.java
$ java HelloWorld Hello World!
$ jaotc --output libHelloWorld.so HelloWorld.class
通过以上命令,就生成了一个名为libHelloWorld.so的库,我们可以使用Linux的ldd命令来确认这是否是一个静态链接库,使用mn命令来确认其中是否包含了HelloWorld的构造函数和main()方法的入口信息,操作如下
$ ldd libHelloWorld.so statically linked
$ nm libHelloWorld.so
……0000000000002a20 t HelloWorld.()V
0000000000002b20 t HelloWorld.main([Ljava/lang/String;)V
……
现在我们就可以使用这个静态链接库而不是Class文件来输出HelloWorld了:
java -XX:AOTLibrary=./libHelloWorld.so HelloWorld Hello World!
提前编译一个HelloWorld只具备演示价值,下一步我们来做更有实用意义的事情:把java.base模块编译成类似的静态链接库。java.base包含的代码数量庞大,虽然其中绝大部分内容现在都能被Jaotc的提前编译所支持了,但总还有那么几个“刺头”会导致编译异常。因此我们要建立一个编译命令文件来排除这些目前还不支持提前编译的方法,将此文件取名为java.base-list.txt,其具体内容如下:
# jaotc: java.lang.StackOverflowError
exclude sun.util.resources.LocaleNames.getContents()[[Ljava/lang/Object;
exclude sun.util.resources.TimeZoneNames.getContents()[[Ljava/lang/Object;
exclude sun.util.resources.cldr.LocaleNames.getContents()[[Ljava/lang/Object;
exclude sun.util.resources..*.LocaleNames_.*.getContents\(\)\[\[Ljava/lang/Object;
exclude sun.util.resources..*.LocaleNames_.*_.*.getContents\(\)\[\[Ljava/lang/Object;
exclude sun.util.resources..*.TimeZoneNames_.*.getContents\(\)\[\[Ljava/lang/Object;
exclude sun.util.resources..*.TimeZoneNames_.*_.*.getContents\(\)\[\[Ljava/lang/Object;
# java.lang.Error: Trampoline must not be defined by the bootstrap classloader
exclude sun.reflect.misc.Trampoline.()V
exclude sun.reflect.misc.Trampoline.invoke(Ljava/lang/reflect/Method;Ljava/lang/Object;[Ljava/lang/Object;)Ljava/lang/Object;
# JVM asserts
exclude com.sun.crypto.provider.AESWrapCipher.engineUnwrap([BLjava/lang/String;I)Ljava/security/Key;
exclude sun.security.ssl.*
exclude sun.net.RegisteredDomain.()V
# Huge methods
exclude jdk.internal.module.SystemModules.descriptors()[Ljava/lang/module/ModuleDescriptor;
然后我们就可以开始进行提前编译了,使用的命令如下所示:
jaotc -J-XX:+UseCompressedOops -J-XX:+UseG1GC -J-Xmx4g --compile-for-tiered --info --compile-commands java.base-list.txt --output libjava.base-coop.so --module java.base
上面Jaotc用了-J参数传递与目标虚拟机相关的运行时参数,这些运行时信息与编译的结果是直接相关的,编译后的静态链接库只能支持运行在相同参数的虚拟机之上,如果需要支持多种虚拟机运行参数(譬如采用不同垃圾收集器、是否开启压缩指针等)的话,可以花点时间为每一种可能用到的参数组合编译出对应的静态链接库。此外,由于Jaotc是基于Graal编译器开发的,所以现在ZGC和Shenandoah收集器还不支持Graal编译器,自然它们在Jaotc上也是无法使用的。事实上,目前Jaotc只支持G1和Parallel(PS+PS Old)两种垃圾收集器。使用Jaotc编译java.base模块的输出结果如下所示:
$ jaotc -J-XX:+UseCompressedOops -J-XX:+UseG1GC -J-Xmx4g --compile-for-tiered --info --compile-commands java.base-list.txt --output libjava.base-coop.so --module java.base Compiling libjava.base-coop.so...
6177 classes found (335 ms)
55845 methods total, 49575 methods to compile (1037 ms)
Compiling with 4 threads
……
49575 methods compiled, 0 methods failed (138821 ms)
Parsing compiled code (906 ms)
Processing metadata (10867 ms)
Preparing stubs binary (0 ms)
Preparing compiled binary (103 ms)
Creating binary: libjava.base-coop.o (2719 ms)
Creating shared library: libjava.base-coop.so (5812 ms)
Total time: 163609 ms
编译完成后,我们就可以使用提前编译版本的java.base模块来运行Java程序了,方法与前面运行HelloWorld是一样的,用-XX:AOTLibrary来指定链接库位置即可,譬如:
java -XX:AOTLibrary=java_base/libjava.base-coop.so,./libHelloWorld.so HelloWorld
Hello World!
我们还可以使用-XX:+PrintAOT参数来确认哪些方法使用了提前编译的版本,从输出信息中可以看到,如果不使用提前编译版本的java.base模块,就只有HelloWord的构造函数和main()方法是提前编译版本的
$ java -XX:+PrintAOT -XX:AOTLibrary=./libHelloWorld.so HelloWorld
11 1 loaded ./libHelloWorld.so aot library
105 1 aot[ 1] HelloWorld.()V
105 2 aot[ 1] HelloWorld.main([Ljava/lang/String;)V
Hello World!
但如果加入libjava.base-coop.so,那使用到的几乎所有的标准Java SE API都是被提前编译好的,输出如下:
java -XX:AOTLibrary=java_base/libjava.base-coop.so,./libHelloWorld.so HelloWorld
Hello World!
13 1 loaded java_base/libjava.base-coop.so aot library
13 2 loaded ./libHelloWorld.so aot library
[Found [Z in java_base/libjava.base-coop.so] ……
// 省略其他输出
[Found [J in java_base/libjava.base-coop.so]
31 1 aot[ 1] java.lang.Object.()V
31 2 aot[ 1] java.lang.Object.finalize()V ……
// 省略其他输出
目前状态的Jaotc还有许多需要完善的地方,仍难以直接编译SpringBoot、MyBatis这些常见的第三方工具库,甚至在众多Java标准模块中,能比较顺利编译的也只有java.base模块而已。不过随着Graal编译器的逐渐成熟,相信Jaotc前途还是可期的。
此外除了Jaotc,同样有发展潜力的Substrate VM也不应被忽视。Jaotc做的提前编译属于本节开头所说的“第二条分支”,即做即时编译的缓存;而Substrate VM则是选择的“第一条分支”,做的是传统的静态提前编译。
¶6.5、Graal
自JDK10起, HotSpot又加入一个全新的编译器: Graal编译器,它是HotSpot即时编译器以及提前编译器共同的最新成果。编译效果短短几年时间就追评了C2编译器。未来可期。目前,带着“实验状态"标签,需要使用开关参数-xx:+UnlockExperimentalVMOptions、-xx:+UseJVMCICompiler去激活,才可以使用。
¶历史背景
2012年,Graal编译器从Maxine虚拟机(也是一款Java虚拟机)项目中分离,成为一个独立发展的Java编译器项目,Oracle Labs希望它最终能够成为一款高编译效率、高输出质量、支持提前编译和即时编译,同时支持应用于包括HotSpot在内的不同虚拟机的编译器。由于这个编译器使用Java编写,代码清晰,又继承了许多来自HotSpot的服务端编译器的高质量优化技术,所以无论是科技企业还是高校研究院,都愿意在它上面研究和开发新编译技术。HotSpot服务端编译器的创造者Cliff Click自己就对Graal编译器十分推崇,并且公开表示再也不会用C、C++去编写虚拟机和编译器了。Twitter的Java虚拟机团队也曾公开说过C2目前犹如一潭死水, 亟待一个替代品,因为在它上面开发、改进实在太困难了。
Graal编译器在JDK 9时以Jaotc提前编译工具的形式首次加入到官方的JDK中,从JDK 10起,Graal 编译器可以替换服务端编译器,成为HotSpot分层编译中最顶层的即时编译器。这种可替换的即时编译器架构的实现,得益于HotSpot编译器接口的出现。
早期的Graal曾经同C1及C2一样,与HotSpot的协作是紧耦合的,这意味着每次编译Graal均需重新编译整个HotSpot。JDK 9时发布的JEP 243:Java虚拟机编译器接口(Java-Level JVM Compiler Interface,JVMCI)使得Graal可以从HotSpot的代码中分离出来。JVMCI主要提供如下三种功能:
-
响应HotSpot的编译请求,并将该请求分发给Java实现的即时编译器。
-
允许编译器访问HotSpot中与即时编译相关的数据结构,包括类、字段、方法及其性能监控数据等,并提供了一组这些数据结构在Java语言层面的抽象表示。
-
提供HotSpot代码缓存(Code Cache)的Java端抽象表示,允许编译器部署编译完成的二进制机器码。
综合利用上述三项功能,我们就可以把一个在HotSpot虚拟机外部的、用Java语言实现的即时编译器(不局限于Graal)集成到HotSpot中,响应HotSpot发出的最顶层的编译请求,并将编译后的二进制代码部署到HotSpot的代码缓存中。此外,单独使用上述第三项功能,又可以绕开HotSpot的即时编译系统,让该编译器直接为应用的类库编译出二进制机器码,将该编译器当作一个提前编译器去使用(如Jaotc)。
¶构建编译调试环境
由于Graal编译器要同时支持Graal VM下的各种子项目,如Truffle、Substrate VM、Sulong等,还要支持作为HotSpot和Maxine虚拟机的即时编译器,所以只用Maven或Gradle的话,配置管理过程会相当复杂。为了降低代码管理、依赖项管理、编译和测试等环节的复杂度,Graal团队专门用Python 2写了一个名为mx的小工具来自动化做好这些事情。我们要构建Graal的调试环境,第一步要先把构建工具mx 安装好,这非常简单,进行如下操作即可:
$ git clone https://github.com/graalvm/mx.git
$ export PATH=`pwd`/mx:$PATH
然Graal编译器是以Java代码编写的,那第二步自然是要找一个合适的JDK来编译。考虑到Graal VM项目是基于OpenJDK 8开发的,而JVMCI接口又在JDK 9以后才会提供,所以Graal团队提供了一个**带有JVMCI功能的OpenJDK 8版本,我们可以选择这个版本的JDK 8来进行编译。如果只关注Graal 编译器在HotSpot上的应用而不想涉及Graal VM其他方面时,可直接采用JDK 9及之后的标准Open/OracleJDK**。选择好JDK版本后,设置JAV A_HOME环境变量即可,这是编译过程中唯一需要手工处理的依赖:
export JAVA_HOME=/usr/lib/jvm/oraclejdk1.8.0_212-jvmci-20-b01
第三步是获取Graal编译器代码,编译器部分的代码是与整个Graal VM放在一块的,我们把Graal VM复制下来,大约有700MB,操作如下:
$ git clone https://github.com/graalvm/graal.git
其他目录中存放着Truffle、Substrate VM、Sulong等其他项目,这些在本次实战中不会涉及。进入compiler子目录,使用mx构建Graal编译器,操作如下:
$ cd graal/compiler
$ mx build
由于整个构建过程需要的依赖项都可以自动处理,需要手动处理的只有OpenJDK一个,所以编译一般不会出现什么问题,大概两三分钟编译即可完成。此时其实已经可以修改、调试Graal编译器了。mx工具能够支持Eclipse、Intellij IDEA和NetBeans三种主流的Java IDE项目的创建, Graal团队中使用Eclipse占多数,支持也最好,生成eclipse配置文件如下
$ cd graal/compiler
$ mx eclipseinit
无论使用哪种IDE,都需要把IDE配置中使用的Java堆修改到2GB或以上,才能保证Graal在IDE中的编译构建能够顺利进行,譬如Eclipse默认配置(eclipse.ini文件)下的Java堆最大为1GB,这是不够的。设置完成后,在Eclipse中选择File->Open Projects from File System,再选择Graal项目的根目录,将会导入整个Graal VM
图
如果你采用的是JDK 8,那么要记得在Eclipse中也必须将那个带有JVMCI功能的特殊JDK 8用作Eclipse里面“Java SE-1.8”的环境配置(Windows->Preferences->Java->Install JREs->Execution Environments->Java SE-1.8),此外,还需要手工将以其他版本号结尾的工程关闭。这对于采用其他版本JDK来编译的读者也是一样的。到此为止,整个编译、调试环境就已经构建完毕。
¶JVMCI编译器接口
准确地说,应当是回边的次数而不是循环次数,因为并非所有的循环都是回边,如空循环实际上就可以视为自己跳转到自己的过程,因此并不算作控制流向后跳转,也不会被回边计数器统计。 ↩︎
分层编译在JDK 6时期出现,到JDK 7之前都需要使用
-XX:+TieredCompilation参数来手动开启, 如果不开启分层编译策略,而虚拟机又运行在服务端模式,服务端编译器需要性能监控信息提供编译依据,则是由解释器收集性能监控信息供服务端编译器使用。分层编译的相关资料可参见: http://weblogs.java.net/blog/forax/archive/2010/09/04/tiered-compilation。 ↩︎由于复杂度等原因,HotSpot中目前暂时还没有做这项优化,但一些其他的虚拟机(如Excelsior JET)使用了这项优化 ↩︎
从JDK 6 Update 23开始,服务端编译器中开始才默认开启逃逸分析。 ↩︎



