[TOC]
一、配置跨集群搜索
¶1、水平扩展的痛点
如果 Es 一直以单集群的状态运行的时候,当水平扩展的时候,节点数不能无限增加。因为随着节点数的增加,集群的 meta 信息(节点、索引、集群状态)过多,会导致更新压力变大,单个 Active Master 会称为性能瓶颈,导致整个集群无法正常工作。
在早期版本,通过 Tribe Node 可以实现多集群访问的需求,但是还是存在一定的问题:
- 当前集群的 Tribe Node 会以 Client Node 的方式加入其他每个集群。其他集群中 Master节点的任务变更需要当前集群的 Tribe Node 的回应才能继续。
- Tribe Node 不保存 Cluster State 信息,一旦重启,初始化很慢
- 当多个集群存在索引重名的情况时,只能设置一种 Prefer 规则
¶2、Cross Cluster Search(跨集群搜索)
早期 Tribe Node 的方案存在一定的问题,现已被 Deprecated。在 Elasticsearch 5.3 引入了跨集群搜索的功能(Cross Cluster Search),推荐使用:
- 允许任何节点扮演 federated 节点,以轻量的方式,将搜索请求进行代理
- 不需要以 Client Node 的形式加入其他集群
¶3、设定步骤
-
分别启动各个 Cluster(前面也提到过这个启动命令,这里的区别是我们指定了3个集群名称,每个集群只有一个节点)
//启动3个集群 bin/elasticsearch -E node.name=cluster0node -E cluster.name=cluster0 -E path.data=cluster0_data -E discovery.type=single-node -E http.port=9200 -E transport.port=9300 bin/elasticsearch -E node.name=cluster1node -E cluster.name=cluster1 -E path.data=cluster1_data -E discovery.type=single-node -E http.port=9201 -E transport.port=9301 bin/elasticsearch -E node.name=cluster2node -E cluster.name=cluster2 -E path.data=cluster2_data -E discovery.type=single-node -E http.port=9202 -E transport.port=9302 -
通过_cluster/setting api 设定 Cross Cluster Search(persistent.cluster.remote.${clustername}.seeds:“ip:port”),另外我们可以在各个集群的配置中进行一些定制化配置,例如下面集群0的
transport.ping_schedule=30s、集群1的transport.compress=true和skip_unavailable=true(表示当前集群如果挂了,无响应,可以跳过它)… …参考模板
//在每个集群上设置动态的设置 PUT _cluster/settings { "persistent": { "cluster": { "remote": { "cluster0": { "seeds": [ "127.0.0.1:9300" ], "transport.ping_schedule": "30s" }, "cluster1": { "seeds": [ "127.0.0.1:9301" ], "transport.compress": true, "skip_unavailable": true }, "cluster2": { "seeds": [ "127.0.0.1:9302" ] } } } } }我们通过以下
curl命令进行 cross cluster search 的设置:#CURL curl -XPUT "http://localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d' {"persistent":{"cluster":{"remote":{"cluster0":{"seeds":["127.0.0.1:9300"],"transport.ping_schedule":"30s"},"cluster1":{"seeds":["127.0.0.1:9301"],"transport.compress":true,"skip_unavailable":true},"cluster2":{"seeds":["127.0.0.1:9302"]}}}}}' curl -XPUT "http://localhost:9201/_cluster/settings" -H 'Content-Type: application/json' -d' {"persistent":{"cluster":{"remote":{"cluster0":{"seeds":["127.0.0.1:9300"],"transport.ping_schedule":"30s"},"cluster1":{"seeds":["127.0.0.1:9301"],"transport.compress":true,"skip_unavailable":true},"cluster2":{"seeds":["127.0.0.1:9302"]}}}}}' curl -XPUT "http://localhost:9202/_cluster/settings" -H 'Content-Type: application/json' -d' {"persistent":{"cluster":{"remote":{"cluster0":{"seeds":["127.0.0.1:9300"],"transport.ping_schedule":"30s"},"cluster1":{"seeds":["127.0.0.1:9301"],"transport.compress":true,"skip_unavailable":true},"cluster2":{"seeds":["127.0.0.1:9302"]}}}}}' -
分别为各个集群添加文档数据到具有相同索引名称"users"的索引中
#创建测试数据 curl -XPOST "http://localhost:9200/users/_doc" -H 'Content-Type: application/json' -d' {"name":"user1","age":10}' curl -XPOST "http://localhost:9201/users/_doc" -H 'Content-Type: application/json' -d' {"name":"user2","age":20}' curl -XPOST "http://localhost:9202/users/_doc" -H 'Content-Type: application/json' -d' {"name":"user3","age":30}' -
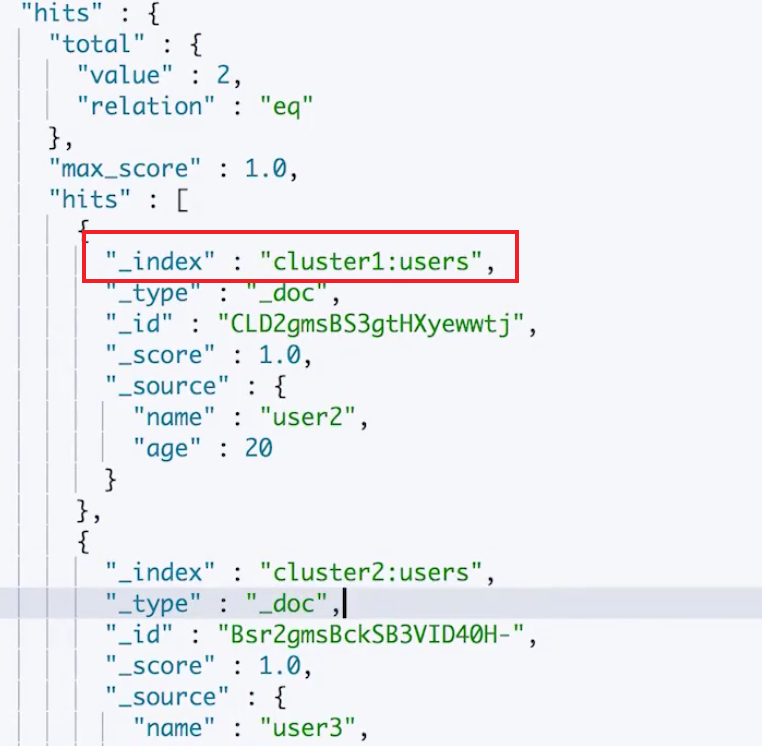
在查询的时候可以通过指定"集群名称:索引名"来进行搜索,如果不指定"集群名称",默认在当前集群内进行搜索:
#查询 GET /users,cluster1:users,cluster2:users/_search { "query": { "range": { "age": { "gte": 20, "lte": 40 } } } }而返回结果中也包含了索引的完整名字"${集群名字}:索引名"
-
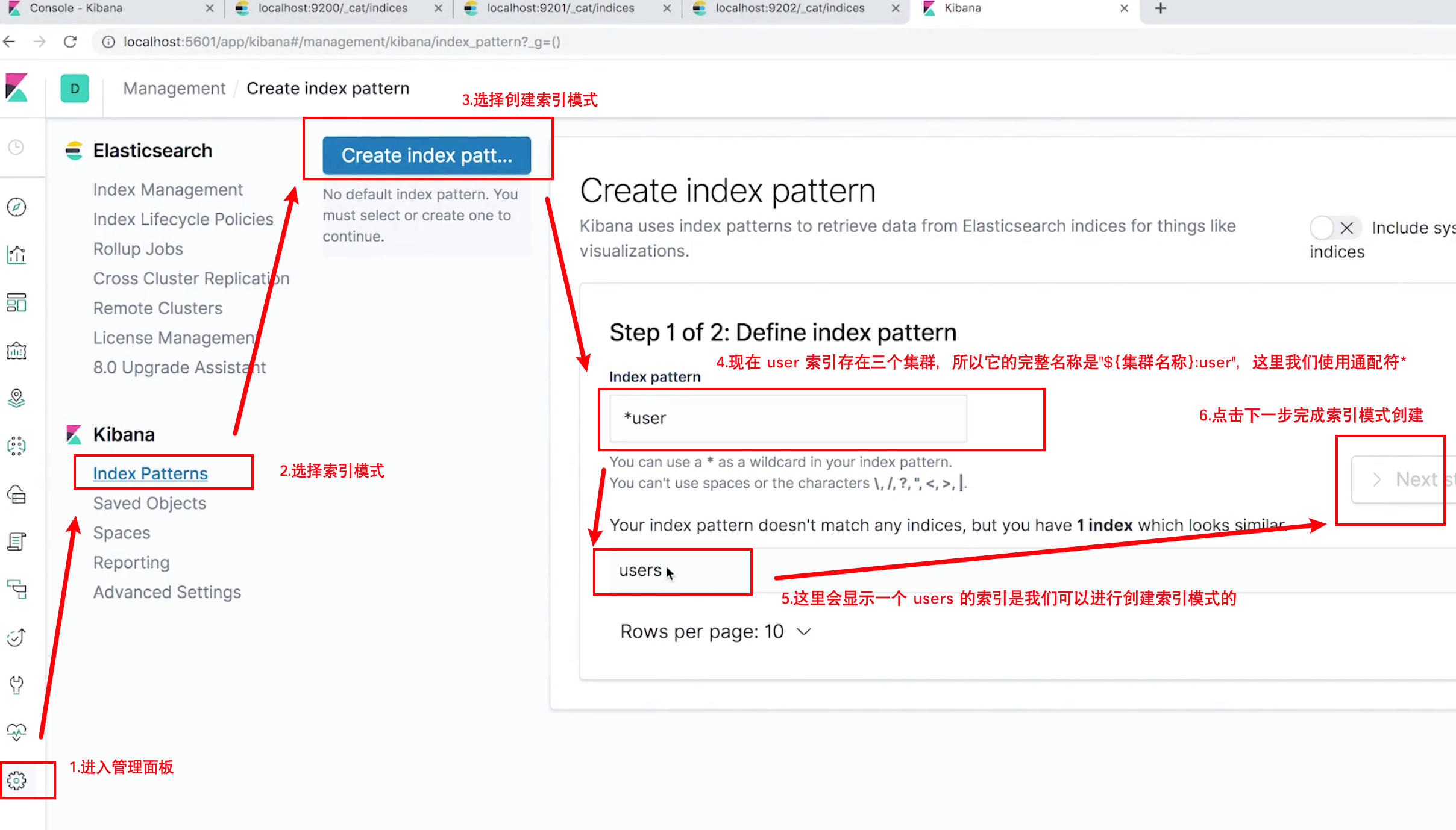
设置 Kibana 中的"索引管理"对多集群可见
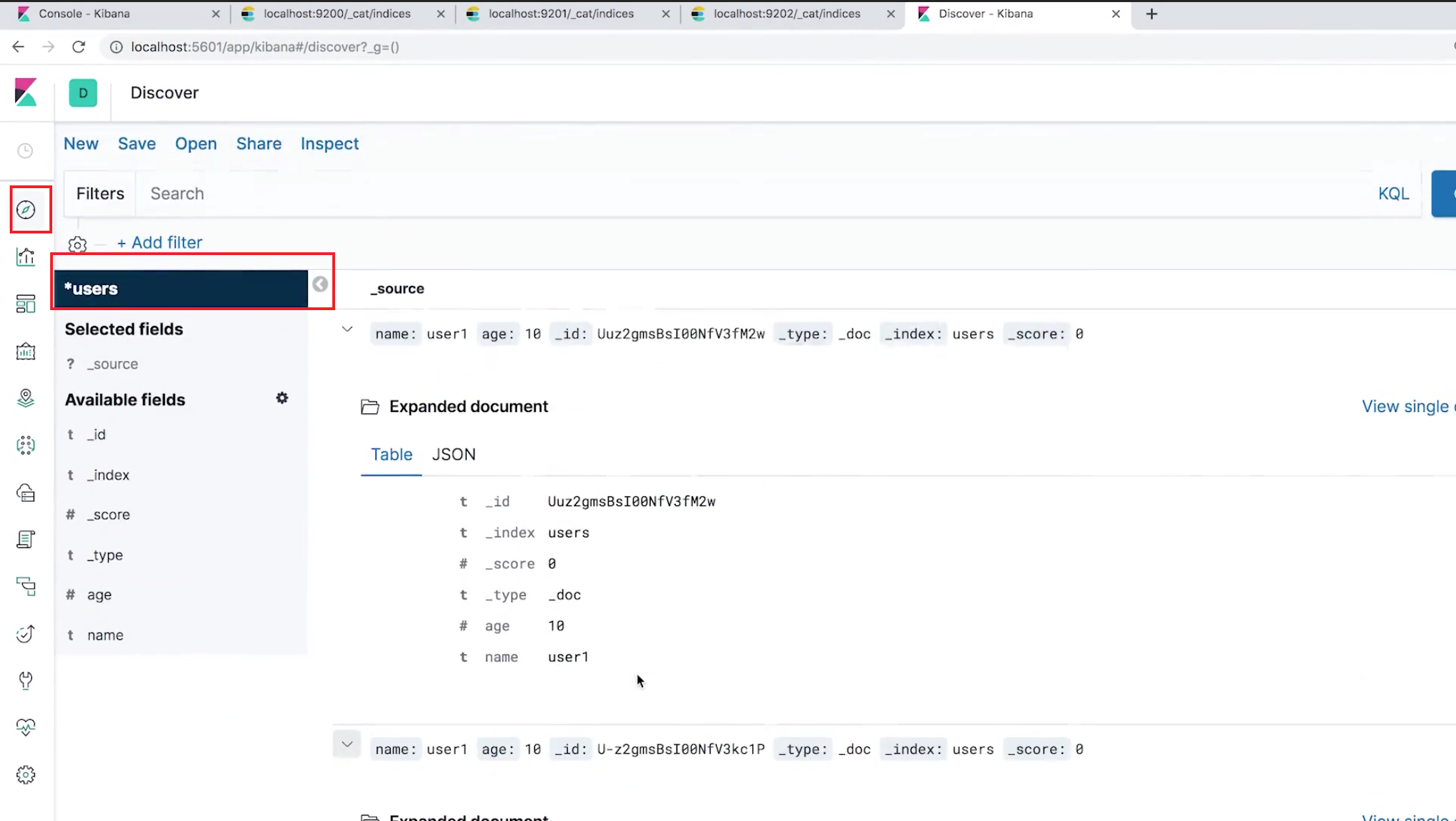
进入 Discover 面板可以看到多集群中的 users 索引 的信息了:
¶相关阅读
二、集群分布式模型及选主与脑裂问题
¶1、分布式特性
Elasticsearch 的分布式架构带来了以下好处:
- 存储的水平扩容,支持 PB 级数据
- 提高系统的可用性,部分节点停止服务,整个集群的服务不受影响
Elasticsearch 的分布式架构
- 不同的集群通过不同的名字来区分,默认名字"elasticsearch"
- 通过配置文件(elasticsearch.yml)修改,或者在命令行
-E cluster.name=geektime进行设定
¶2、Elasticsearch 中的节点
节点是一个 Elasticsearch 实例,其本质上就是一个 Java 进程。一台机器上可以运行多个 Elasticsearch 进程,但是生产环境一般建议一台机器上就运行一个 Elasticsearch 实例。
每个节点都有名字,通过配置文件(elasticsearch.yml)配置,或者启动时-E node.name=geektime 指定
每一个节点在启动之后,会分配一个 UID,保存在 data 目录下
¶3、Coordinating Node
处理请求的节点,叫 Coordinating Node。它负责路由请求到正确的节点,例如创建索引的请求,需要路由到 Master节点。
默认情况下,所有节点都是 Coordinating Node,我们可以通过将node.xxxx的参数全部设置为 false,使其成为 Dedicated Coordinating Node(专职)。但是不能取消任何一个节点作为 Coordinating Node的功能!
¶4、Data Node
可以保存数据的节点,叫做 Data Node。节点启动后,默认就是数据节点。可以设置 node.data:false 禁止其称为 Data Node。
Data Node 的职责是保存分片数据。在数据扩展上起到了至关重要的作用(由Master Node 决定如何把分片分发到数据节点上),通过增加数据节点,可以解决数据水平扩展和解决数据单点问题。
¶5、Master Node
Master Node 的职责是
- 处理创建,删除索引等请求
- 决定分片被分配到哪个节点
- 维护并且更新 Cluster State
Master Node 的最佳实践
Master 节点非常重要,在部署上需要考虑解决单点的问题。为一个集群设置多个 Master(Eligible、备选)节点,每个节点只承担 Master 的单一角色,如果 Master 节点发生故障,其他备选 Master 节点就可以顶上。
¶Master Eligible Nodes
一个集群,支持配置多个 Master Eligible 节点。这些节点可以在必要时(Master 节点出现故障,网络故障时)参与选主流程,称为 Master 节点。
每个节点启动后,默认就是一个 Master Eligible 节点,我们可以通过设置node.master:flase禁止。这样该节点可以加入集群,但是不会参与 Master 节点选主称为 Master 节点。
¶选主流程
- 当集群内第一个 Master Eligible 节点启动的时候,它会将自己选举称为 Master 节点。
- 一旦发现被选中的主节点丢失,就会选举出新的 Master 节点,所有节点互相 ping 对方,Node Id 低的会被选举为 Master。
¶6、集群状态
集群状态信息(Cluster State)维护了一个集群中必要的信息:
- 所有的节点信息
- 所有的索引和其相关的 Mapping 与 Setting 信息
- 分片的路由信息
在每个节点上都保存了集群的状态信息,但是只有 Master 节点才能修改集群的状态信息,并负责同步给其他节点,因为任意节点都能修改信息会导致 Cluster State 信息的不一致。
¶7、脑裂问题(Split-Brain)
这是分布式系统的经典网络问题。我们看下面示例:当出现网络问题,一个节点node1和其他节点 node2 和 node3 无法连接:
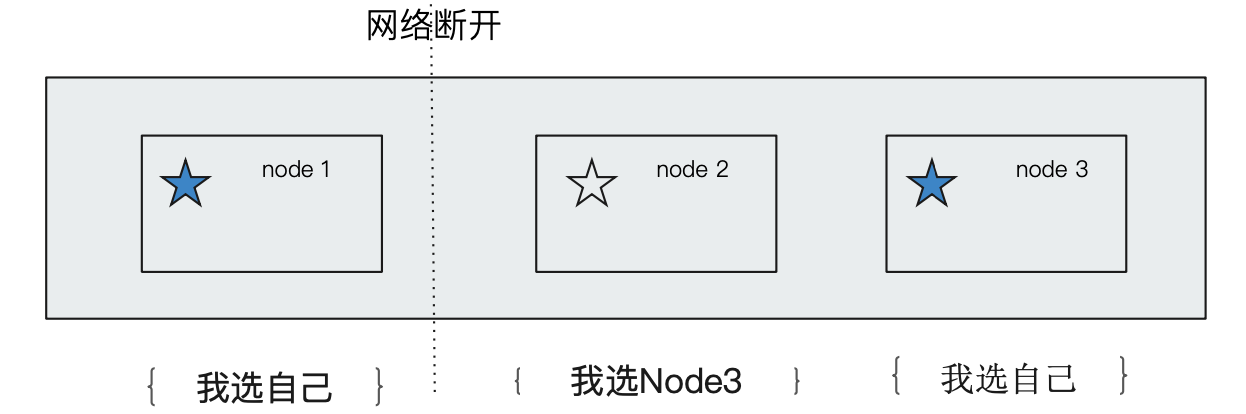
- Node2和 Node3会重新选举 Master
- Node1自己还是作为 Master,组成一个集群,同时更新 Cluster State
- 导致2个 master 维护不同的 Cluster State,当网络恢复的时候,造成混乱,无法正确恢复集群状态。
针对这个问题,我们需要限定一个选举条件,设置 quorum(仲裁),只有在 Master eligible 节点数大于 quorum 时才能进行选举:
- Quorum = (Master Eligible 节点总数 / 2) + 1。
- 当3个 master eligible 时,设置
discovery.zen.minimum_master_nodes=2,即可避免脑裂。(其他节点数量视情况而设定)
从ES7.0开始,无需进行这个配置,它移除了 minimum_master_nodes参数,让 Elasticsearch 自己选择可以形成仲裁的节点。典型的主节点选举现在只需要很短的时间就可以完成。集群的伸缩变得更安全、更容易,并且可能造成丢失数据的系统配置选项更少了。节点更清除地记录它们的状态,有助于诊断为什么它们不能加入集群或为什么无法选举出主节点。
¶8、通过 Cerebro 观察集群状态
- 通过命令行方式启动一个 ES 集群

- 启动 cerebro

-
进入 cerebro 界面,可以看到只有一个节点,索引、分片、文档等都是空的。该节点也是一个 master 节点
-
通过 more-create index 创建索引

-
创建一个 “test” 索引,有3个主分片,1个副本分片,点击创建,返回成功。但是我们留意到上面的状态条变成了黄色。
-
回到主界面,我们可以发现刚刚我们创建的 test 索引已经显示出来了,我们指定了三个主分片也分片到了 Master 节点上。但是我们指定的3份副本分片(每个主分片都有一个副本,所有是3个)是一个待分配状态,因为现在集群中只有一个节点,所以无法分配副本分片。

-
这时候我们再启动一个节点

-
切换 cerebro 界面进行刷新。我们可以发现状态条恢复绿色。有一个节点加入了集群,副本分片也分配到了该节点上。这样,当另一个节点发生故障的时候,数据不会发生丢失。

¶9、配置节点类型
一个节点默认情况下时一个 Master Eligible、Data And Ingest Node。

所有的节点都是默认支持ingest的,任何节点都可以处理ingest请求,也可以创建一个专门的Ingest nodes。
¶10、相关阅读
https://www.elastic.co/cn/blog/a-new-era-for-cluster-coordination-in-elasticsearch
三、分片与集群的故障转移
分片是 Elasticsearch 分布式集群存储的基石,其中分为主分片和副本分片。
¶1、Primary Shard
通过主分片,ES 将数据分布在所有Data Ndoe上,实现存储的水平扩展。主分片数在索引创建的时候指定,后续默认不能修改,如要修改,需要重建索引。
¶2、Replica Shard
副本分片可以提高数据的可用性。一旦主分片丢失,副本分片可以 Promote 成主分片。副本分片数可以动态调整。每个节点上都有完备的数据。如果不设置副本分片,一旦出现节点硬件故障,就有可能造成数据丢失。
副本分片由主分片同步。通过支持增加 Replica 个数,一定程度可以提高读取的吞吐量。
¶3、分片数的设定
我们需要谨慎规划一个索引的主分片和副本分片数:
如果主分片数过小,例如 ES 现在最新版本是默认创建一个主分片,如果一个索引只创建了一个主分片,如果该索引增长很快,集群无法通过增加节点实现对这个索引的数据扩展。
如果主分片数量设置过大,也会导致单个 Shard 容量很小,引发一个节点上有过多分片,影响性能。
如果副本分片数量设置过多,会降低集群整体的写入性能。
¶4、集群故障转移过程
上一节中我们也看到了一例子,我们启动了一个只有一个节点的集群,然后创建一个索引,指定其主分片数量为3,副本分片数量为1。会发现副本分片无法分配,集群状态为黄色。(另外,可以看到多个主分片是可以分布在同一个节点中的)
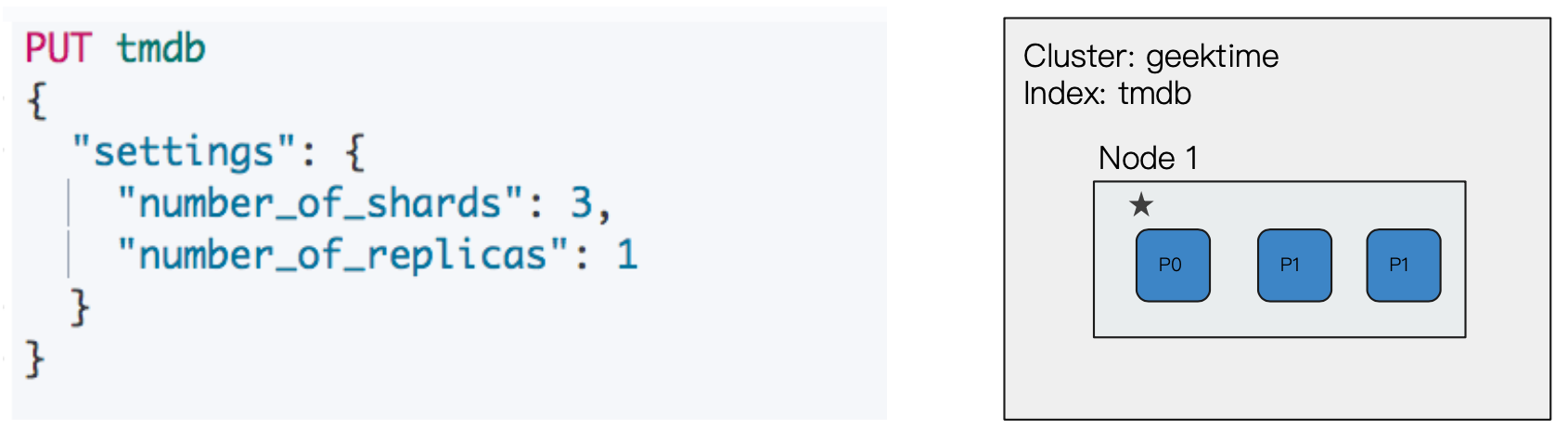
这时候我们可以通过增加一个数据节点,集群将Node1中的所有主分片备份到 Node2的副本分片之后集群状态恢复绿色。此时整个集群已经具备故障转移的能力。
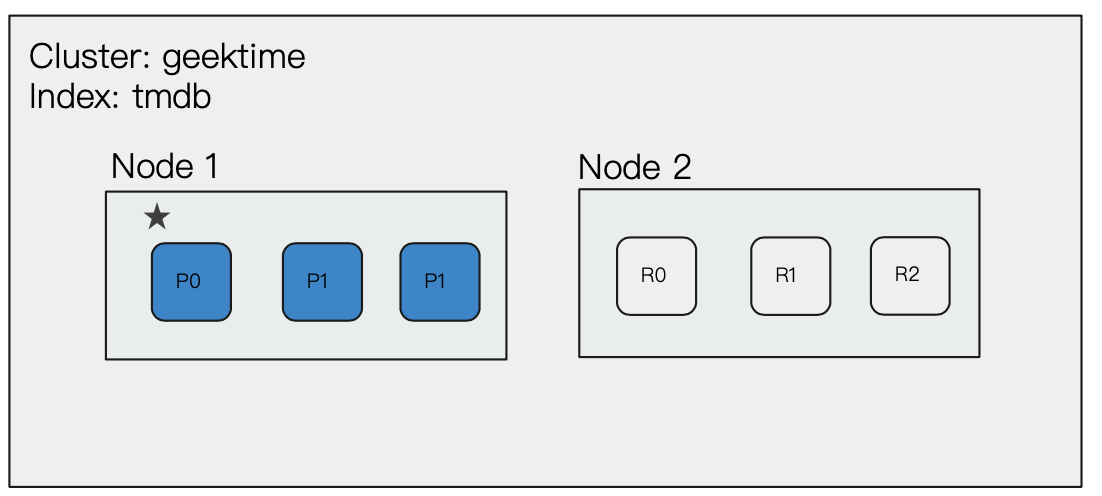
此时我们再为集群增加一个数据节点,Master 节点会决定分片分配到哪个节点上。可以看到此时三个主分片都分布到了三个不同的节点上,并且三个节点互相备份其他节点的 Master 分片。(通过增加节点,提高集群的计算能力)
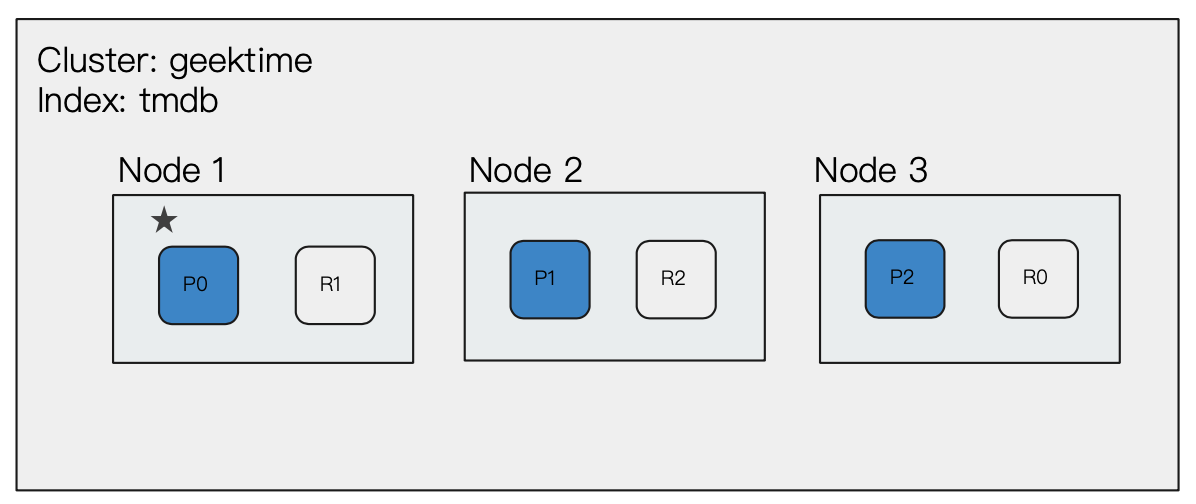
现在我们模拟一个故障过程:
节点1Master 节点意外出现故障,此时整个集群状态变红。集群重新选举 Master 节点,Node3上的 R0 副本分片提升为 P0 主分片进行数据接收,提升完毕之后集群状态变黄,P0 和 P1两个主分片的数据待备份,此时 Node3 负责备份 P1主分片为 R1,Node2负责备份 P0主分片为 R0,备份完毕之后集群状态变绿。
其中这里面有几个时间点需要注意:
- 如果存在数据写入 P0 之后P0没来得及备份到 R0副本,Node1就挂掉了,这时候 R0是没有这些数据的,在 Node1恢复之前数据都无法获得,而当 Node1恢复重新加入集群之后,会从
translog中恢复没有写入的数据。 - Node1挂掉之后,P0主分片还没选举出来之前应该路由到 P0的数据进来了,如果有创建index或者分片reallocation有可能会出错。(即集群是黄色变绿的过程,副本分片提升为主分片,不影响读写;如果集群在红变黄的过程,缺少主分片,会影响读写)
¶5、集群健康状态
- Green:健康状态,所有的主分片和副本分片都可用
- Yellow:亚健康,所有的主分片可用,部分副本分片不可用
- Red:不健康状态,部分主分片不可用
四、文档分布式存储
¶1、文档存储在分片上
文档会存储到具体的某个主分片和副本分片上,而存储到哪个分片上则需要一个映射算法来负责,而这个算法需要确保文档能均匀分布在所用分片上,充分利用硬件资源,避免部分机器控线,部分机器繁忙。
潜在的算法:
- 随机、Round Robin(轮询):当查询文档1,分片数很多,需要多次查询才可能查到文档1
- 维护文档到分片的映射关系,当文档数据量很大的时候,维护成本高
- 通过 hash 算法对文档的 hash key 进行实时计算,自动算出,需要到哪个分片上获取文档
¶2、ES 中的路由算法
shard = hash(_routing) % number_of_primary_shards
- 由 hash 算法确保文档均匀地 hash 到各个分片中
- 默认的_routing 值是文档 id
- 可以自行制定 routing 数值,例如用相同国家的商品,都分配到指定的 shard
- 设置 index settings 后,Primary shard数不能随意修改的根本愿意就是这里的文档 hash 到分片对主分片数进行了计算
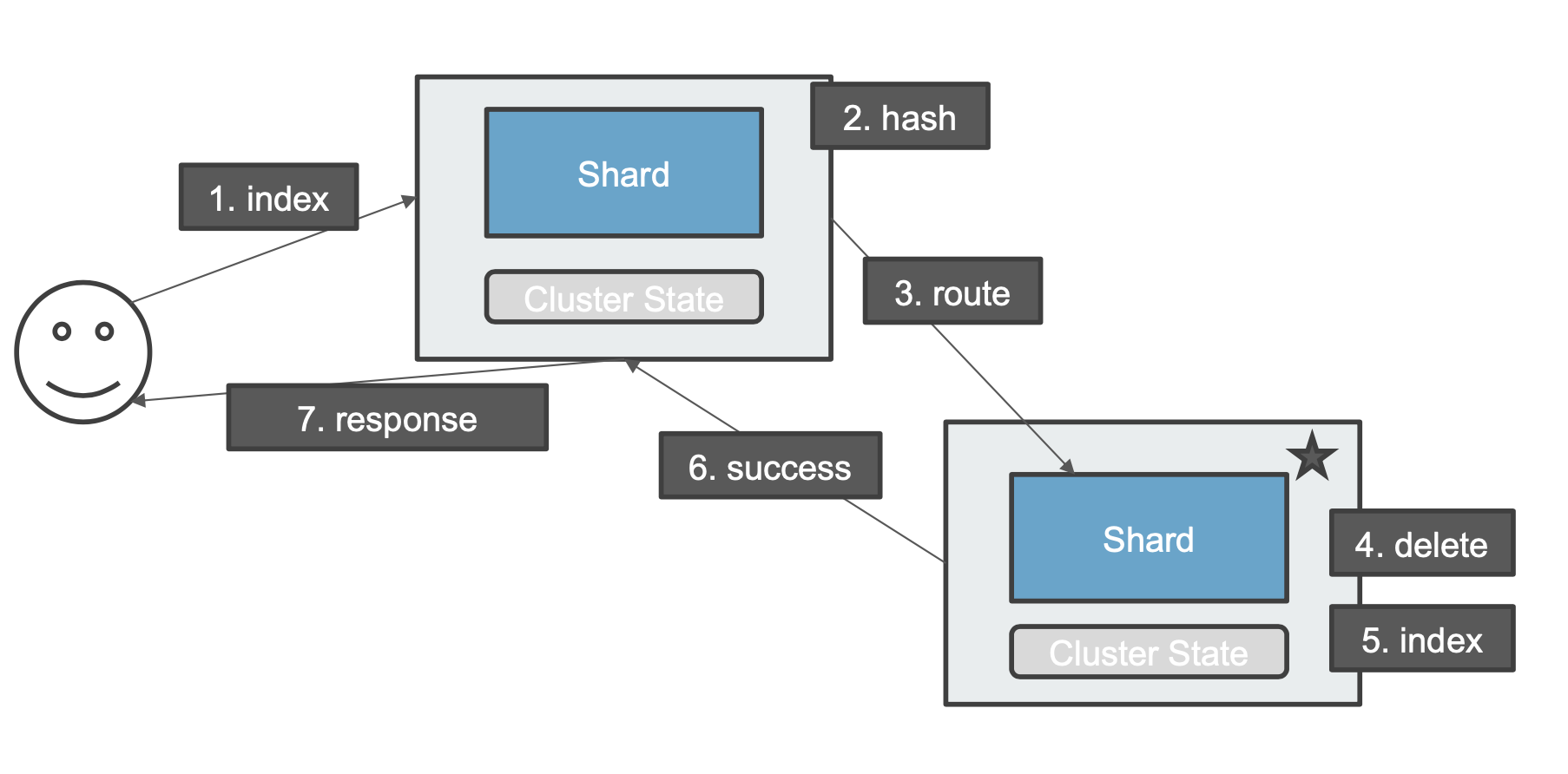
¶3、更新一个文档的流程(没有副本分片)
一个更新请求发送到 coordinating 节点,该节点对文档进行 hash 计算(根据集群状态),最终将这个请求路由到该文档对应的主分片节点上,主分片节点对文档进行删除操作之后再进行索引操作,然后返回成功到 coordinating 节点,然后 coordinating 节点响应用户。
¶4、删除一个文档的流程(涉及副本分片)
一个删除请求发送到 coordinating 节点,该节点对文档进行 hash 计算(根据集群状态),最终将这个请求路由到该文档对应的主分片节点上,主分片节点对文档进行删除操作之后,发送同步请求到副本分片节点进行删除(根据集群状态),副本分片删除索引之后返回成功到主分片节点,主分片节点收到响应之后返回成功到 coordinating 节点,然后 coordinating 节点响应用户。

¶5、 为什么 ES 不支持一致性 Hash 算法动态增加主分片
Why doesn’t Elasticsearch support incremental resharding?
Going from N shards to N+1 shards, aka. incremental resharding, is indeed a feature that is supported by many key-value stores. Adding a new shard and pushing new data to this new shard only is not an option: this would likely be an indexing bottleneck, and figuring out which shard a document belongs to given its _id, which is necessary for get, delete and update requests, would become quite complex. This means that we need to rebalance existing data using a different hashing scheme.The most common way that key-value stores do this efficiently is by using consistent hashing. Consistent hashing only requires 1/N-th of the keys to be relocated when growing the number of shards from N to N+1. However Elasticsearch’s unit of storage, shards, are Lucene indices. Because of their search-oriented data structure, taking a significant portion of a Lucene index, be it only 5% of documents, deleting them and indexing them on another shard typically comes with a much higher cost than with a key-value store. This cost is kept reasonable when growing the number of shards by a multiplicative factor as described in the above section: this allows Elasticsearch to perform the split locally, which in-turn allows to perform the split at the index level rather than reindexing documents that need to move, as well as using hard links for efficient file copying.
In the case of append-only data, it is possible to get more flexibility by creating a new index and pushing new data to it, while adding an alias that covers both the old and the new index for read operations. Assuming that the old and new indices have respectively M and N shards, this has no overhead compared to searching an index that would have M+N shards.
五、分片及生命周期
¶1、分片的内部原理
ES 中的分片是最小的工作单元,也是一个 Lucene 的 Index。
我们从以下一些问题出发探索 ES 中的分片:
- 为什么 ES 的搜索是近实时的(1秒后被搜到)
- ES 如何保证在断点时数据也不会丢失
- 为什么删除文档,并不会立刻释放空间
¶2、倒排索引不可变性
倒排索引采用 Immutable Design,一旦生成就不可更改。不可变性带来了如下好处:
- 无需考虑并发写文件的问题,避免了锁机制带来的性能问题。(如果可以更新可能会出现并发更新的情况,为了保持数据一致性,往往需要加锁,而倒排索引都是直接删除然后新增,执行的是覆盖操作)
- 一旦写入内核的文件系统缓存,便留在那里。只要文件系统存有足够的空间,大部分请求就会直接请求内存,不会命中磁盘,提升了很大的性能
- 缓存容易生成和维护,数据可以被压缩
不可变更性也带来了挑战:如果需要让一个新的文档可以被搜索,需要重建整个索引。
¶3、Lucene Index
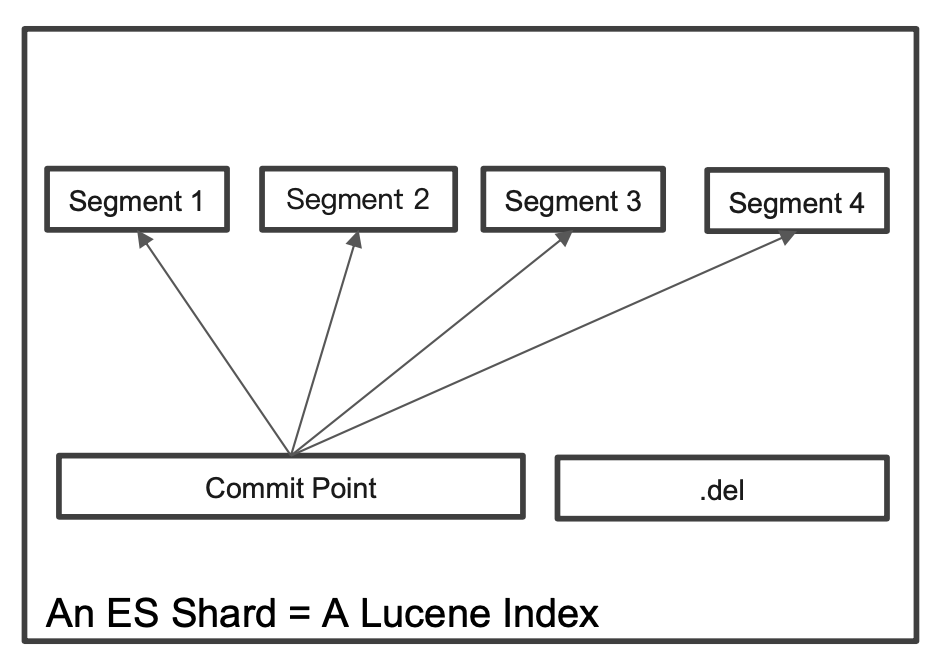
在 Lucene 中,单个倒排索引文件被称为 Segment。Segment 是自包含的,不可变更的。当有新文档写入的时候,会生成新 Segment,查询时会同时查询所有 Segments,并且对结果汇总。多个 Segments 汇总在一起,称为 Lucene 的 Index,其对应的就是 ES 中的 Shard。
Lucene 中有一个文件,用来记录所有 Segments 信息,叫做 Commit Point。删除的文档信息,保存在".del"文件中。
¶4、什么是 Refresh
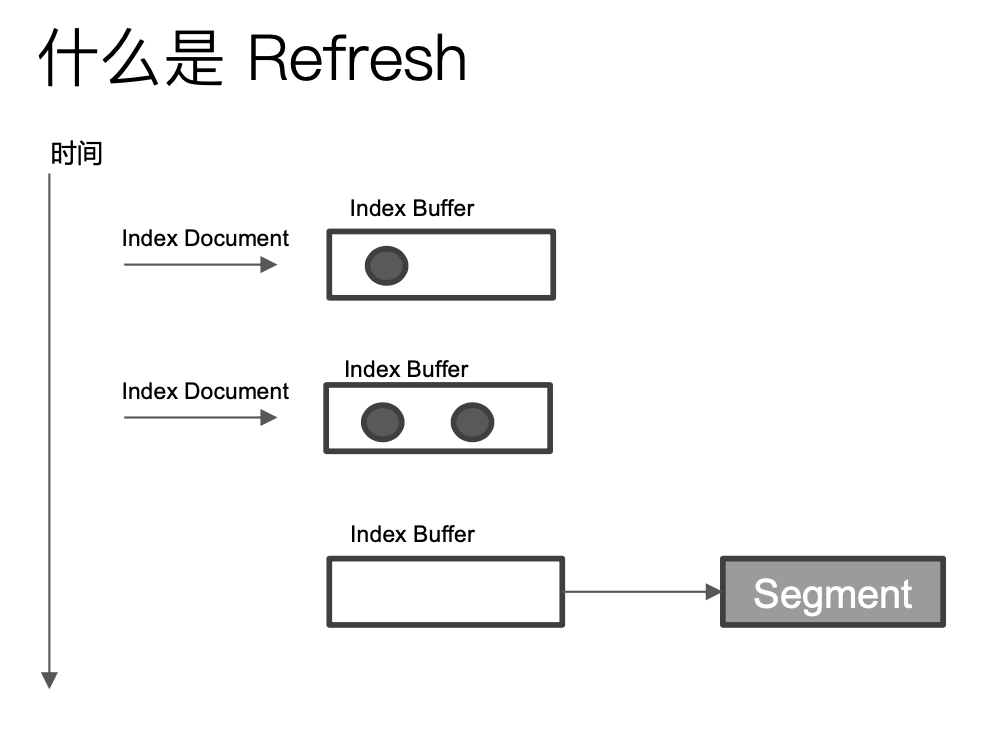
在将一个新的文档写入到 ES 的时候,会将这个文档先写入到一个 Index Buffer 中,当到达一定的时候,会将 Index Buffer 写入 Segment ,然后清空 Buffer,从 Index Buffer写入信息到 Segment 的过程就叫做 Refresh。(Refresh 不执行 fsync 操作)
Refresh 频率默认是1秒发生一次,可通过 index.refresh_interval 配置。Refresh 后,数据就可以被搜索到了。这也是为什么 Elasticsearch 被称为近实时搜索。
如果系统有大量的数据写入,那就会产生很多的 Segment,当 Index Buffer 被占满时,也会触发 Refresh,这个 Buffer默认值是 JVM 的10%。
¶5、什么是 Transaction Log
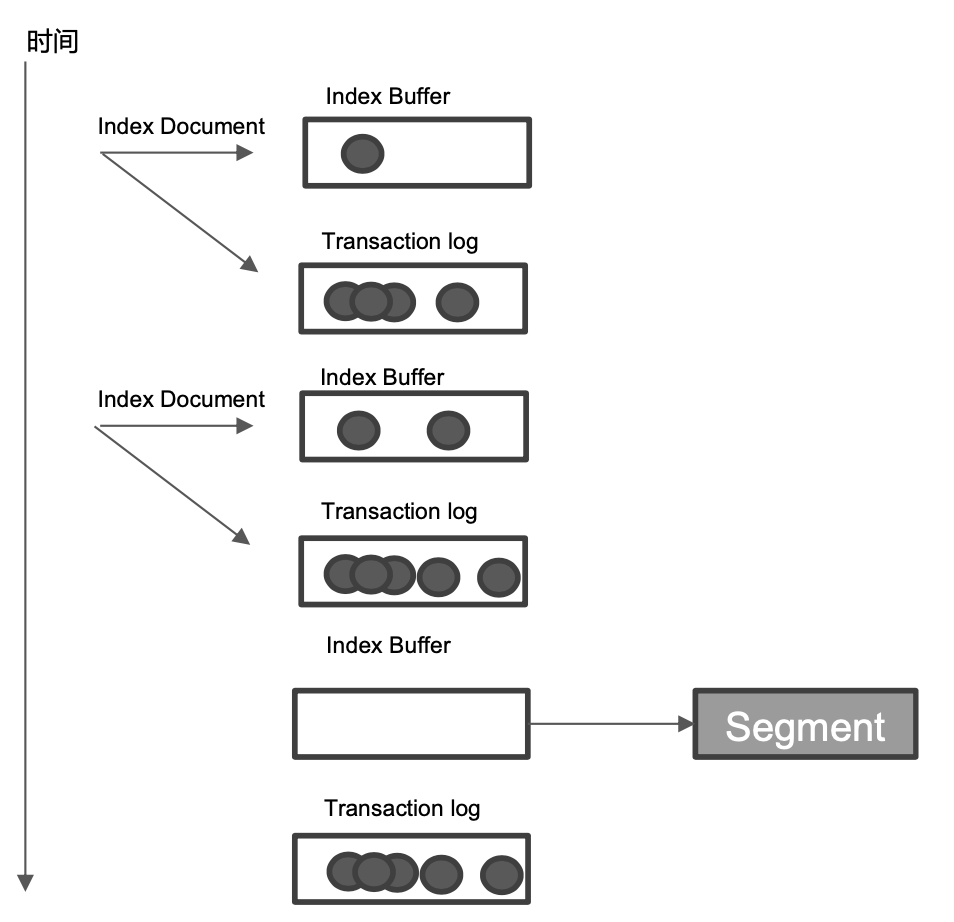
上面介绍了一个新的文档的写入是先写入 ES 的 Index Buffer 中,在一定时候"refresh"到 Segments,而Segment 写入磁盘的过程相对耗时(特别时存在大量写入文档操作的时候),借助文件系统缓存,Refresh 时,先将 Segment 写入缓存以开放查询。
但是因为此时数据是写入到内存中的,为了保证此段时间数据不会丢失。所以ES 在 Index 一个新创建的文档的时候,除了将其写入到 Index Buffer 中,同时还写 Transaction Log(这是一个异步动作,不会阻塞文档写入 Index Buffer 以及 refresh)。高版本开始,Transaction Log 默认落盘。每个分片都有一个 Transaction Log。
在 ES Refresh 时,即使是Index Buffer 被清空,刷到 Segments 的缓存当中,Transaction log 不会清空。所以为什么 ES 节点产生"断电"的时候,它已经写入的数据是"不会"丢失的,就是因为它已经将 Transaction log 进行了落盘,在这个节点重启之后,会重新加载 Transaction Log 对数据进行 recover。
¶6、什么是 FLush
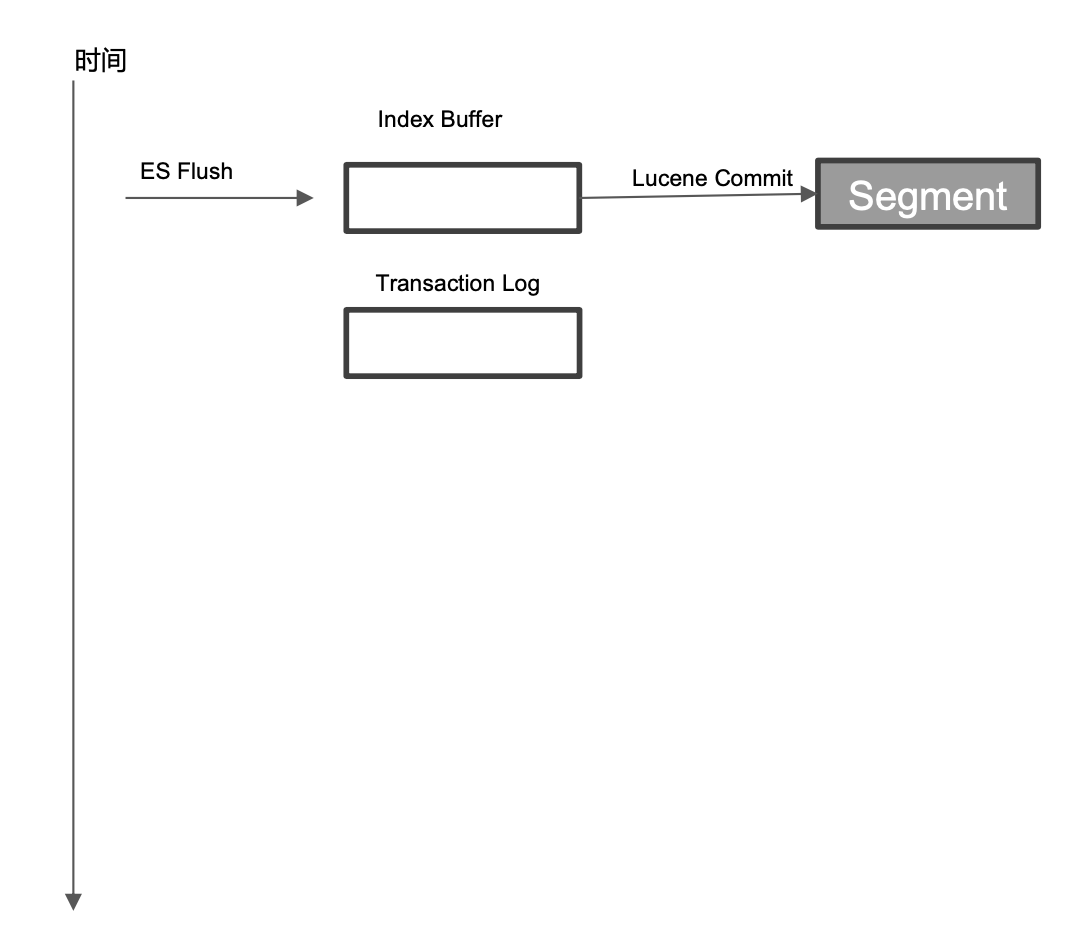
它可以理解为"ES FLush"和"Lucene Commit"两个过程:
- 先执行一次 Refresh,Index Buffer 清空并且将数据刷到 Segments cache
- 调用 fsync,将缓存中的 Segments 写入磁盘
- 清空(删除)Transaction Log
Flush 操作默认30分钟调用一次;另外当 Transaction Log满地时候也会触发调用(默认512MB)
¶7、Merge
Merge 操作指的是当 Segment 很多地时候,需要被定期合并,减少 Segments,并真正删除已经删除地文档。
ES 和 Lucene 会自动进行 Merge 操作,我们也可以通过 POST my_index/_forcemergeAPI 进行强制 merge。
¶8、总结
- 客户端发起数据写入请求,对你写的这条数据根据_routing规则选择发给哪个Shard。
- 确认Index Request中是否设置了使用哪个Filed的值作为路由参数
- 如果没有设置,则使用Mapping中的配置,
- 如果mapping中也没有配置,则使用_id作为路由参数,然后通过_routing的Hash值选择出Shard,最后从集群的Meta中找出出该Shard的Primary节点。
- 写入请求到达Shard后,先把数据写入到内存(index buffer)中,同时会写入一条日志到translog日志文件中去。
- 当写入请求到shard后,首先是写Lucene,其实就是创建索引。
- 索引创建好后并不是马上生成segment,这个时候索引数据还在缓存中,这里的缓存是lucene的缓存,并非Elasticsearch缓存,lucene缓存中的数据是不可被查询的。
- 执行refresh操作:从内存buffer中将数据写入os cache(操作系统的内存),产生一个segment file文件,buffer清空。
- 写入os cache的同时,建立倒排索引,这时数据就可以供客户端进行访问了。
- 默认是每隔1秒refresh一次的,所以es是准实时的,因为写入的数据1秒之后才能被看到。
- buffer内存占满的时候也会执行refresh操作,buffer默认值是JVM内存的10%。
- 通过es的restful api或者java api,手动执行一次refresh操作,就是手动将buffer中的数据刷入os cache中,让数据立马就可以被搜索到。
- 若要优化索引速度, 而不注重实时性, 可以降低刷新频率。
- translog会每隔5秒或者在一个变更请求完成之后,将translog从缓存刷入磁盘。
- translog是存储在os cache中,每个分片有一个,如果节点宕机会有5秒数据丢失,但是性能比较好,最多丢5秒的数据。。
- 可以将translog设置成每次写操作必须是直接fsync到磁盘,但是性能会差很多。
- 可以通过配置增加transLog刷磁盘的频率来增加数据可靠性,最小可配置100ms,但不建议这么做,因为这会对性能有非常大的影响。
- 每30分钟或者当tanslog的大小达到512M时候,就会执行commit操作(flush操作),将os cache中所有的数据全以segment file的形式,持久到磁盘上去。
- 第一步,就是将buffer中现有数据refresh到os cache中去。
- 清空buffer 然后强行将os cache中所有的数据全都一个一个的通过segmentfile的形式,持久到磁盘上去。
- 将commit point这个文件更新到磁盘中,每个Shard都有一个提交点(commit point), 其中保存了当前Shard成功写入磁盘的所有segment。
- 把translog文件删掉清空,再开一个空的translog文件。
- flush参数设置:
- index.translog.flush_threshold_period:
- index.translog.flush_threshold_size:
- # 控制每收到多少条数据后flush一次
- index.translog.flush_threshold_ops:
- Segment的merge操作:
- 随着时间,磁盘上的segment越来越多,需要定期进行合并。
- Es和Lucene 会自动进行merge操作,合并segment和删除已经删除的文档。
- 我们可以手动进行merge:POST index/_forcemerge。一般不需要,这是一个比较消耗资源的操作。
六、剖析分布式查询及相关性算分
Elasticsearch 的搜索,会分两个阶段进行:
- 第一阶段-Query
- 第二阶段-Fetch
即Query-Then-Fetch。
¶1、Query 阶段
- 用户发出搜索请求到 ES 节点。节点收到请求后,会以Coordinating 节点的身份,在6个主副分片中随机选择3个分片,发送查询请求。
- 被选中的分片执行查询,执行排序。然后,每个分片都会查询 From + Size 个排序后的文档 id 和排序值给 Coordinating 节点。
¶2、Fetch 阶段
- Coordinating Node 会将 Query 阶段,从每个分片获取的排序后的文档 id 列表,重新进行排序。再获取第 from 索引开始的 size 个文档进行返回。
- 以 multi get 请求的方式,到相应的分片获取详细的文档数据。
¶3、Query Then Fetch 潜在问题
-
性能问题
每个分片上需要查询的文档个数=from+size,最终协调节点需要处理:number_of_shard * (from+size),如果查询的数量很大,协调节点就需要处理很多的文档。对于分布式搜索来说,搜索引擎在处理深度分页的时候对性能有很大的挑战。
-
相关性算分
每个分片都基于自己的分片上的数据进行相关度计算。这会导致打分偏离的情况。特别是数据量很少时。相关性算分在分片之间是相互独立。当文档总数很少的情况下,如果主分片大于1,主分片数越多,相关性算分会越不准。
¶4、解决算分不准的方法
-
数据量不大的时候,可以将主分片数设置为1,当数据量足够大的时候只要保证文档均匀分散在各个分片上,结果一般就不会出现偏差。
-
使用 DFS Query Then Fetch
在搜索的 URL中指定参数
_search?search_type=dfs_query_then_fetch,到每个分片把各分片的词频和文档频率进行搜集,然后完整地进行一次相关性算分,这会耗费更多的 CPU 和内存,执行性能底下,一般不建议使用。
¶5、 算分不准演示例子
-
建立一个索引分别写入三个文档,不指定分片数,默认1个主分片,不会出现分布式算分不准的情况,我们调用一次对于 content 字段的 term 查询。
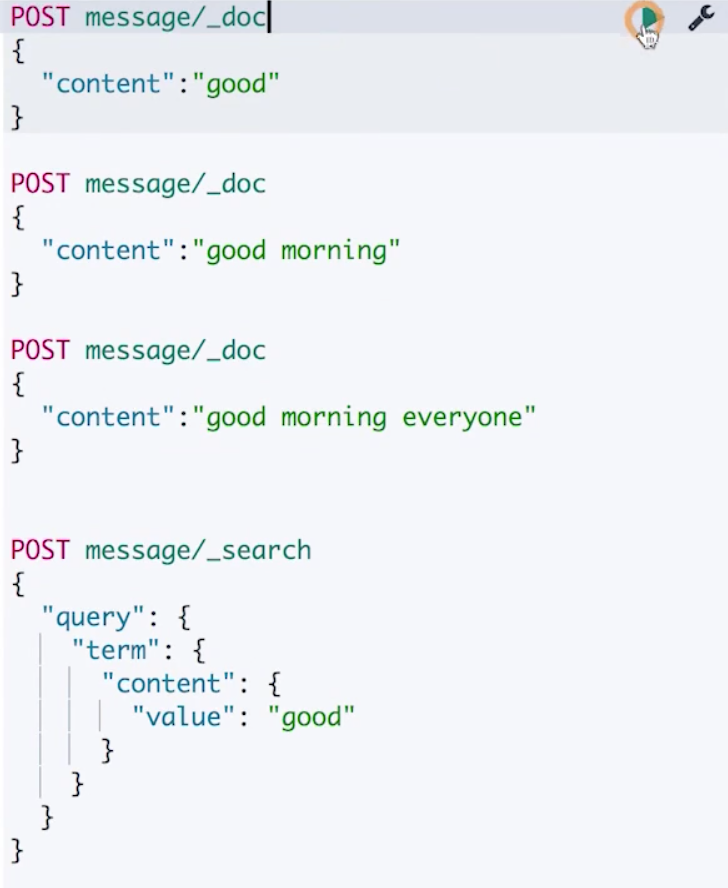
发现得到的结果确实是正确的,good 的算分是最高的

-
设置主分片数为20,重新写入数据并指定它们的路由 key 为1、2、3将它们路由到不同的节点上

-
然后再进行一次查询:

-
发现返回的3条结果的分值是一样的,"good"排在了最后。

-
我们对查询加上 explain 参数之后可以发现3个文档是位于不同的分片上的

-
使用
_search?search_type=dfs_query_then_fetch参数查询,算分又正确了


¶6、Kibana 测试请求
DELETE message
PUT message
{
"settings": {
"number_of_shards": 20
}
}
GET message
POST message/_doc?routing=1
{
"content":"good"
}
POST message/_doc?routing=2
{
"content":"good morning"
}
POST message/_doc?routing=3
{
"content":"good morning everyone"
}
POST message/_search
{
"explain": true,
"query": {
"match_all": {}
}
}
POST message/_search
{
"explain": true,
"query": {
"term": {
"content": {
"value": "good"
}
}
}
}
POST message/_search?search_type=dfs_query_then_fetch
{
"query": {
"term": {
"content": {
"value": "good"
}
}
}
}
七、排序及 Doc Value&Fielddata
¶1、排序
Elasticsearch 默认采用相关性算分对结果进行降序排序,可以通过设定 sort 参数,自行设定排序。如果不指定_score 排序,算分为 null。

¶2、多字段进行排序
传入一个数组到 sort 属性,组合多个条件,优先考虑写在前面的字段的排序,支持混合相关性算分进行排序

¶3、Doc Values vs Fielddata
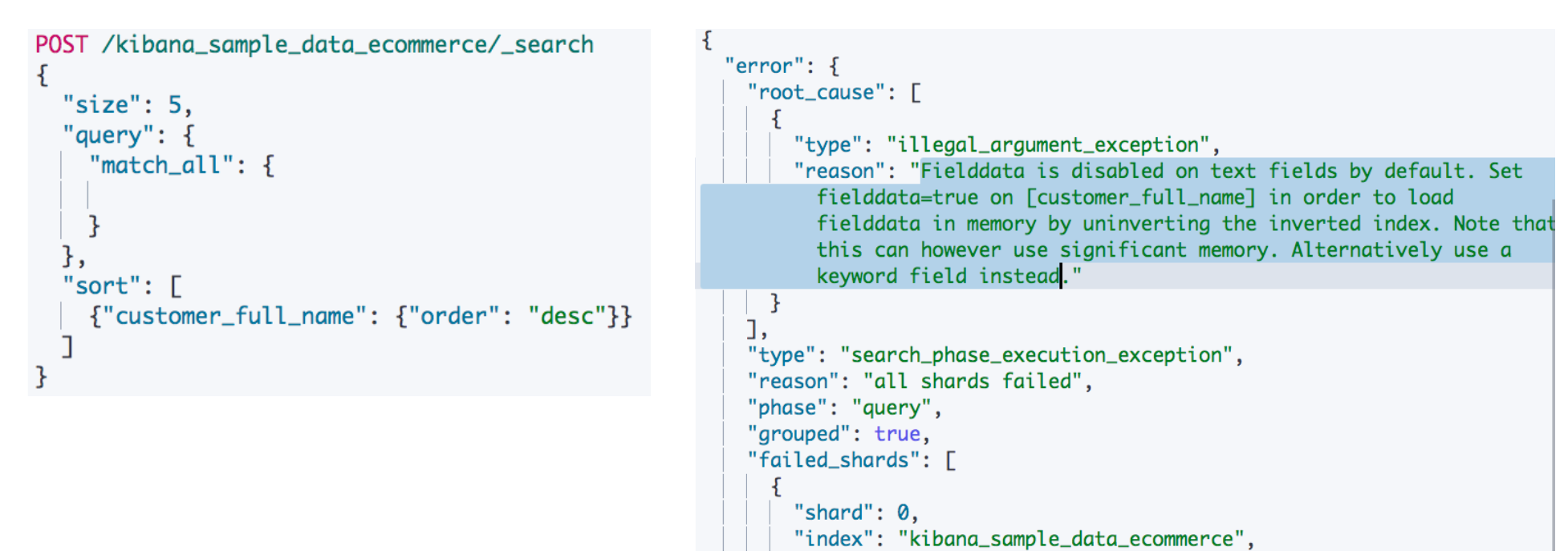
¶对 Text 类型字段排序
当我们尝试对一个 text 类型的字段"customer_full_name"进行排序的时候,遇到一个报错告诉我们fielddata默认是关闭的,需要打开才能执行
现在我们来了解一下排序的过程:
- 排序是真毒 i字段原始内容进行的。此时倒排索引无法发挥作用,需要用到正排索引。通过文档 id 和字段快速得到字段原始内容。
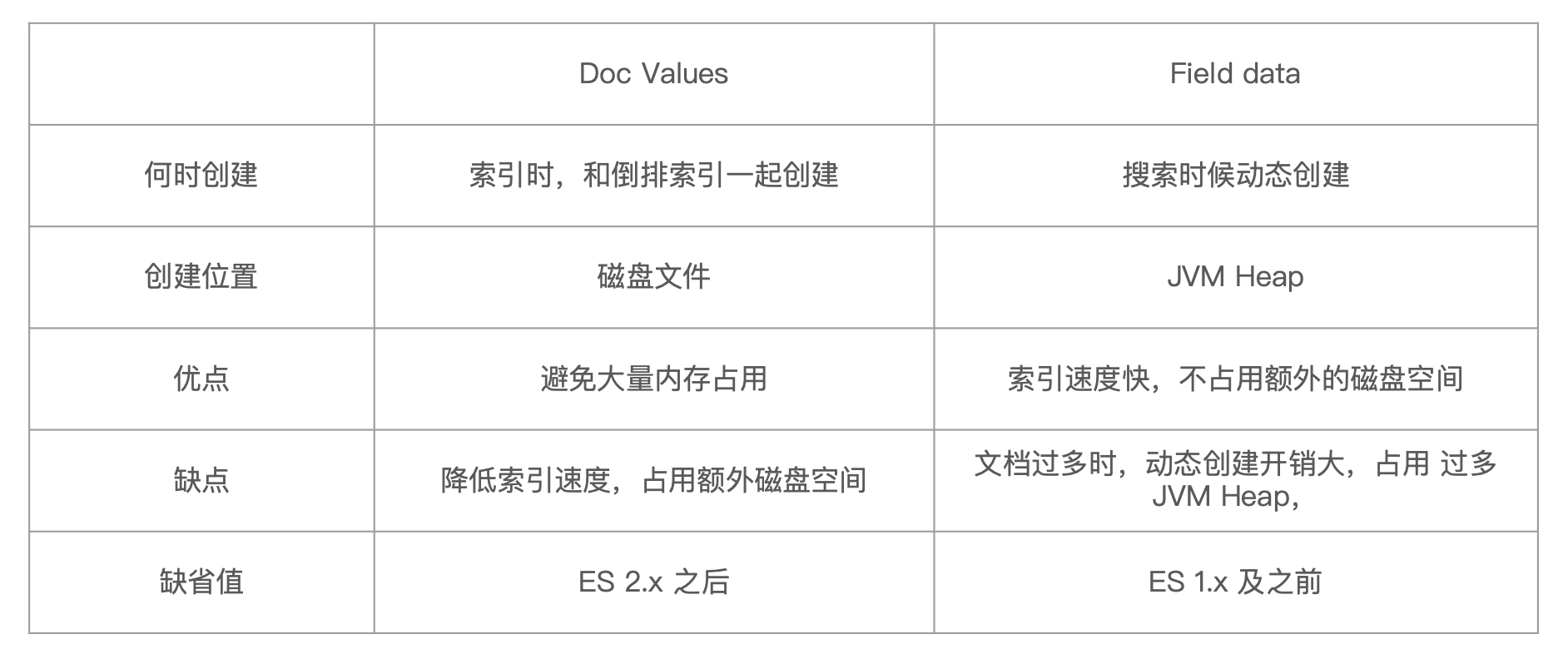
- Elasticsearch 对于排序有两种实现方法:Fielddata 和 DocValues(列式存储,对 Text 类型无效)
Doc Values 现在的版本是默认打开的,它是随着倒排索引的创建一起创建(非文本类型都是结构化数据)放在磁盘上的;而 Fielddata 现在的版本默认是关闭的,因为对于文本类型数据的排序本来就是意义不大的,它是将文本数据加载到内存中进行排序的,如果排序的内容很多,就会导致内存占用很大。
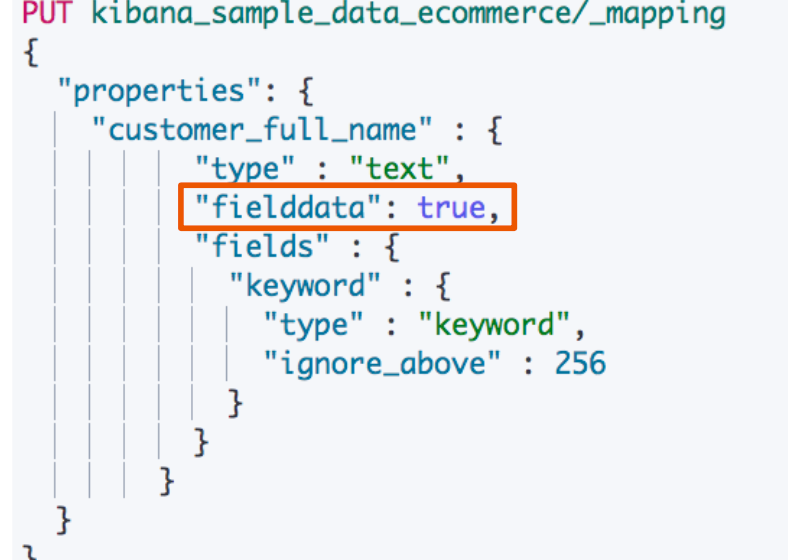
¶打开 Fieldata
通过 Mapping 设置打开。修改设置后,即时生效,无需重建索引。
只支持对 Text 进行设定,其他字段类型不支持。打开后可以对 Text 字段进行排序。但是是对分词后的 term排序,所以,结果往往无法满足预期,不建议使用。
部分情况下打开,满足一些聚合分析的特定需求。
¶关闭 Doc Values
通过 Mapping 设置关闭,可以增加索引的速度,减少磁盘空间。
如果关闭之后重新打开,需要重建索引。所以我们要再明确不需要做排序和聚合分析的时候才关闭。

¶获取 Doc Values & Fielddata 中存储的内容
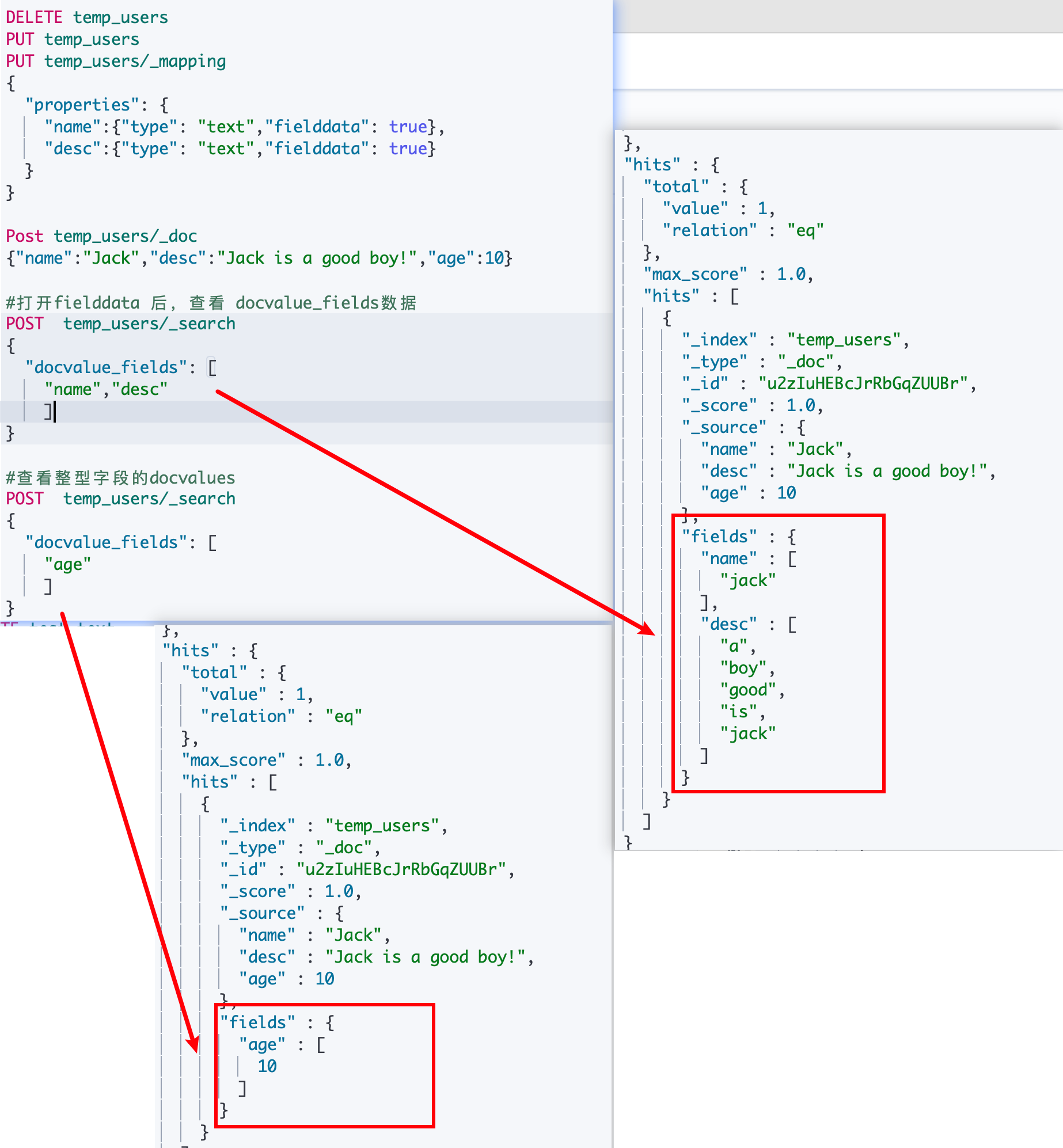
八、分页与遍历:From、Size、Search After & Scroll API
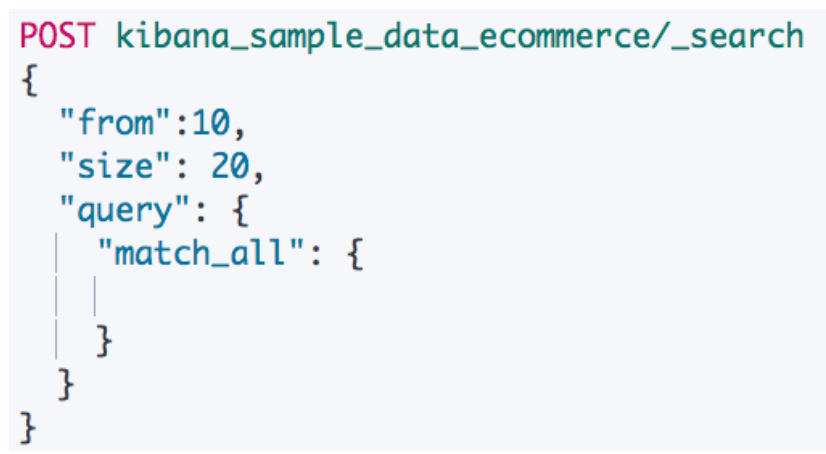
¶From & Size
默认情况下,ES 查询按照相关度算分排序,返回前10条记录。这是一个比较标准的容易理解的分页方案,from 表示开始位置,size 表示期望获取文档的总数。
¶分布式系统中深度分页的问题
ES 天生就是分布式的。查询信息的时候数据分别保存在多个分片,多台机器上,ES 天生就需要满足排序的需要(按照相关性算分)。
如果一个查询是分页参数from=990、size=10。ES 会在每个分片上先都获取1000个文档。然后,通过 Coordinating Node 聚合所有结果。最后再通过排序选取出前1000个文档,然后取第990位开始的后10个文档进行返回。
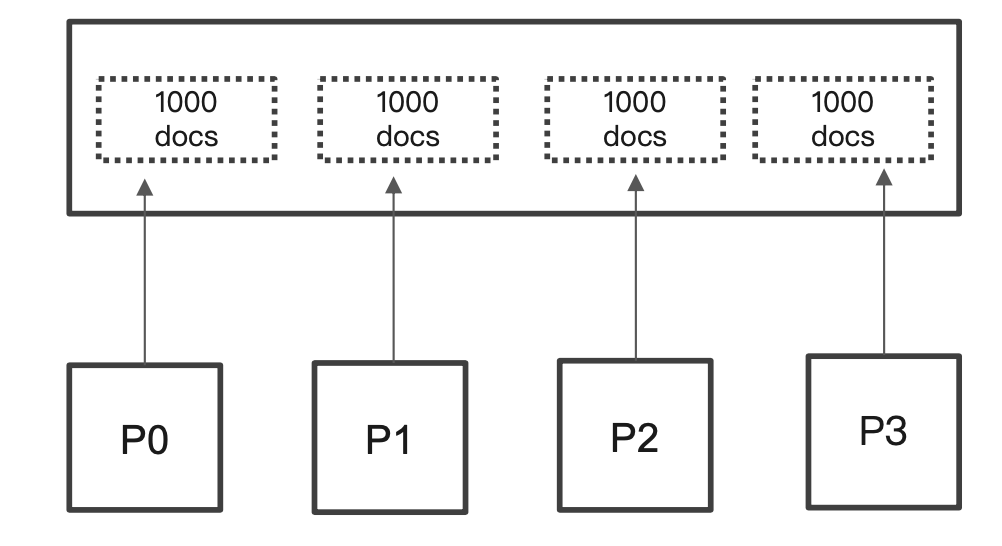
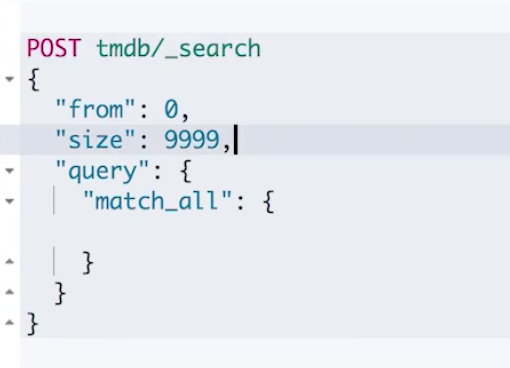
当页数越深的时候,占用内存就越多。为了避免深度分页带来的内存开销。ES 有一个设定,默认限定到10000 个(from + size)文档。另外,我们可以通过index.max_result_window来调整这个数值。
下面我们在图一图二分别尝试设置 from 和 size 到比较大的数量,让 from+size 超过10000,就会获得图三的报错。
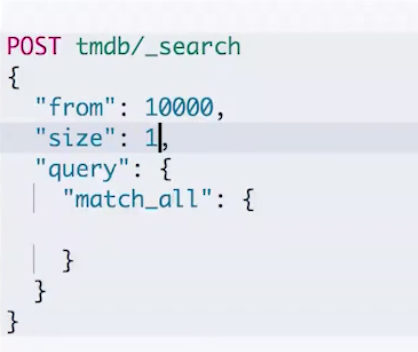
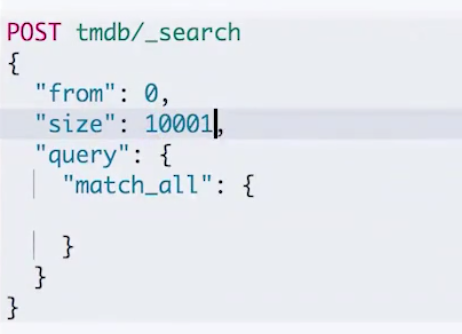

如果我们设置在10000的范围之内,可以返回结果,但是需要消耗比较长的时间,本示例消耗了2-3秒。
¶Search After
我们可以使用 Search After 来避免深度分页带来的性能问题,这个 API 表示实时获取下一页文档信息。但是它在功能上有以下的限制:
- 不支持指定页数(设定 From 值)
- 只能往下翻
调用 Search After:
- 第一步搜索需要指定 sort,并且保证值是唯一的(可以通过加入_id 保证唯一性)
- 然后后面的查询就使用上一次返回的文档的 sort 值进行查询
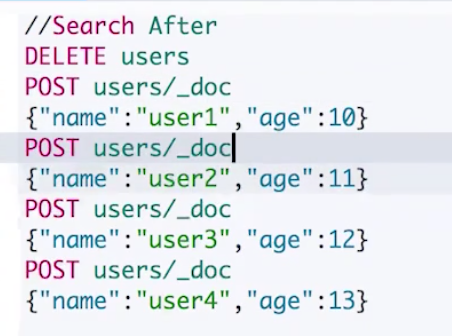
Demo:
-
写入数据
-
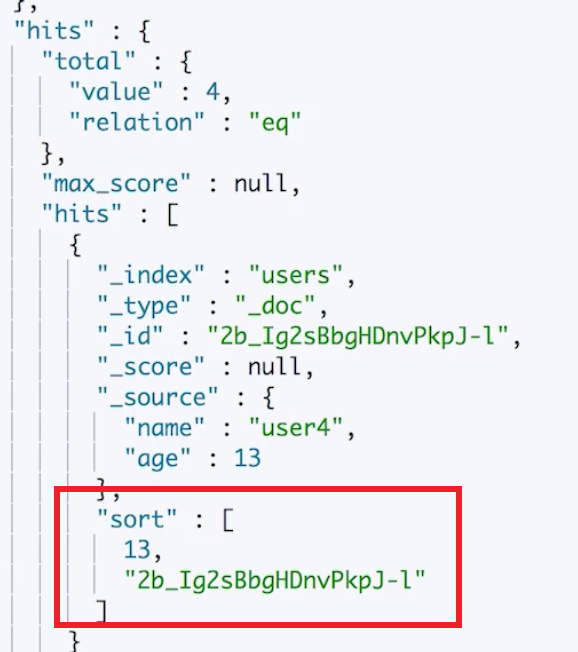
第一次查询:指定 size 是1,表示每次查询只返回1条记录,然后我们是根据 age 来排序并分页的,但是为了保证排序的唯一性,我们加入了_id 字段。
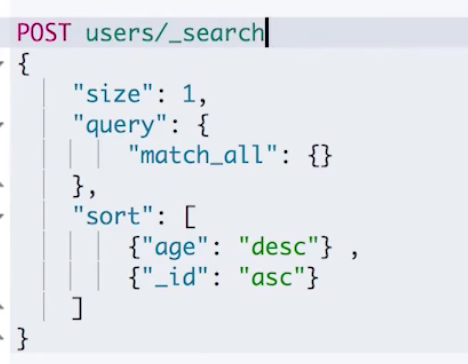
执行之后返回以下数据,包含了一个文档,同时也返回了一个 sort 值(返回文档中按照指定排序之后的最后一个文档的 sort 字段的值)给我们用于下一次查询。
-
将第一次获取到的 sort 值传入到 search_after 属性中

执行,即可得到第2次结果,这次执行又返回了一个 sort 值,我们通过不断地将上一次查询返回的 sort 值放到查询的 search_after 属性中进行下一次查询即可达到一个不断分页的效果,直到达到了最后 size 条数据,则没有返回一个没有文档数据的空数组。

¶Search After 如何解决深度分页问题
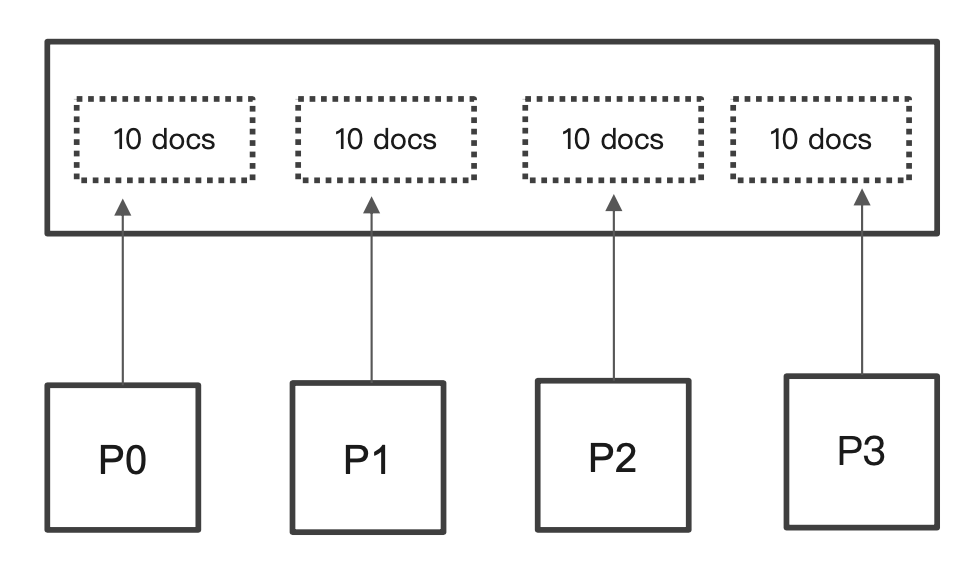
每个 ES 分片通过指定唯一排序值定位到大于等于唯一排序值之后的 size 个文档进行返回。
这样的话在 from 比较大,size 比较小的深度分页问题上,例如当查询from=990,size=10 的时候,原本每个分片都会返回 i000个文档,现在只会返回10个文档给 coordinating 节点进行处理。(但是如果是 size 非常大的深度分页,还是有一定的问题)
¶Scroll API
ES 还提供了一个 Scoll API,它会基于当前的查询创建一个快照,用户可以对这个快照进行遍历操作。但是如果创建快照之后有新的数据写入到该索引,这个快照对于这个数据是无感知的,也就是说在遍历快照的时候是查询不到这个数据的。
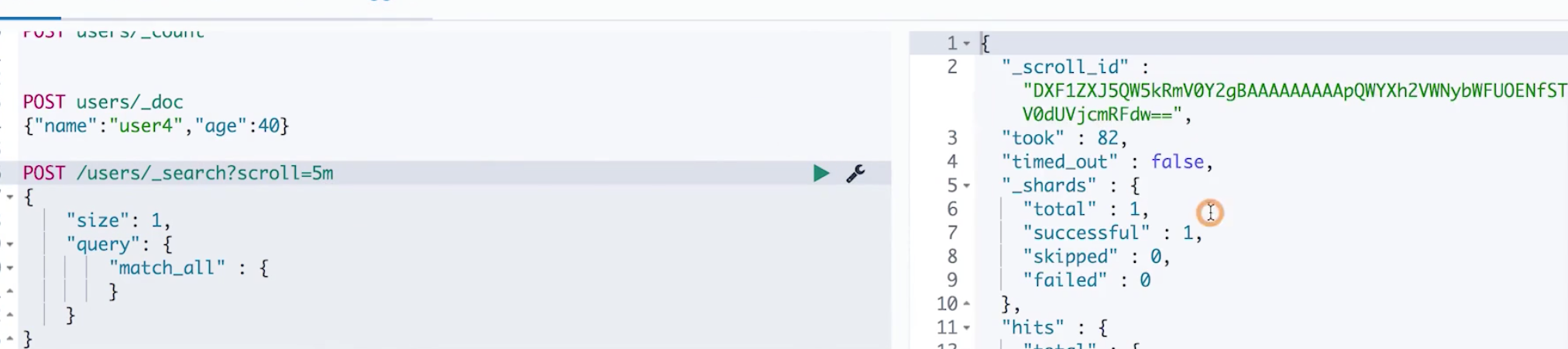
我们看一下下面的 Demo,在第一次查询的时候我们执行一个 search 操作,并通过参数scroll=5m表示基于当前的查询结果创建一个5分钟的快照。执行之后可以看到返回结果中包含了一个 _scroll_id,表示我们下一次遍历的指针。( 同时下面也返回了查询的结果,这里截图没有截出来)
然后我们将这个_scroll_id 拿出来放到下面的 _search/ scroll api进行进行遍历操作,可以看到,我们拿到了当前遍历的结果,并且返回了下一次遍历要用到的 _scroll_id,以此类推,我们就可以实现对一个快照进行遍历的操作。(另外,scroll api 应该还有其他的一些配置项,带研究)

¶不同的搜索类型和使用场景
- Regular:需要实时获取顶部的部分文档。例如查询最新的订单
- Scroll:需要全部文档,例如导出全部数据
- Pagination:From 和 Size;如果需要深度分页,则选用 Search API。( 深度分页,并不是搜索引擎所擅长的。google也一样。应该结合其他存储介质例如关系型数据库和es一起使用。es用来实现全文检索)
九、 处理读写操作
¶并发控制的必要性
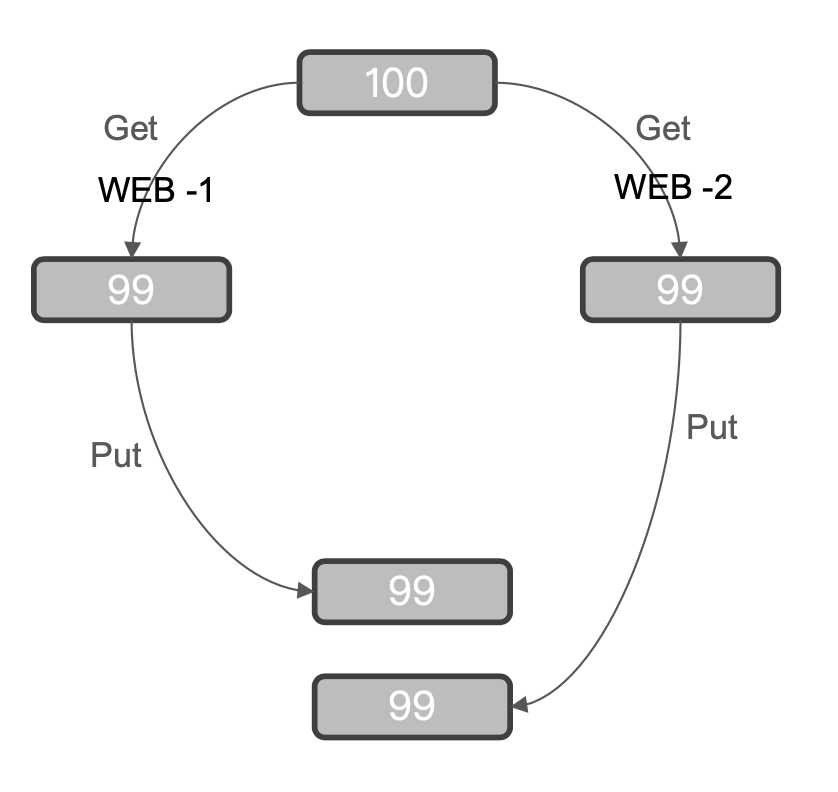
举个例子,当有两个 Web 应用分别销售了一个商品,这时候需要进行扣减库存的操作,那么它们同时从 ES 中获取了一个商品的库存为100,然后分别做了库存扣减1的动作,然后 WEB1更新 ES 中该商品库存为99,然后 WEB2又将 ES 中该商品库存进行更新为99。那么这时候这个库存就不对了。它实际上应该是98,这就是修改丢失的并发问题。
处理这种问题有两种方式:
-
悲观并发控制
假定有变更冲突的可能。会对资源加锁,防止冲突,例如数据库行锁。
-
乐观并发控制
假定冲突是不会发生的,不会阻塞正在尝试的操作。如果数据在读写中被修改,更新将会失败。应用程序决定如何解决冲突,例如重试更新,使用新的数据,或者将错误报告给用户。
而 ES 采用的是乐观并发控制。
¶ES 的乐观并发控制
ES 中的文档是不可变更的。如果你更新一个文档,会将该文档标记为删除,同时增加一个全新的文档。同时文档的 version 字段加1。
ES 提供的乐观并发控制分为内部版本控制和外部版本控制:
-
内部版本控制:使用 _seq_no 和 _primary_term 两个字段
在 ES 的早期版本中,它是可以通过 _version 属性来实现内部的版本控制的,但是在新版本中使用 _version 来进行并发控制已经被废除了。现在我们来看一个例子。
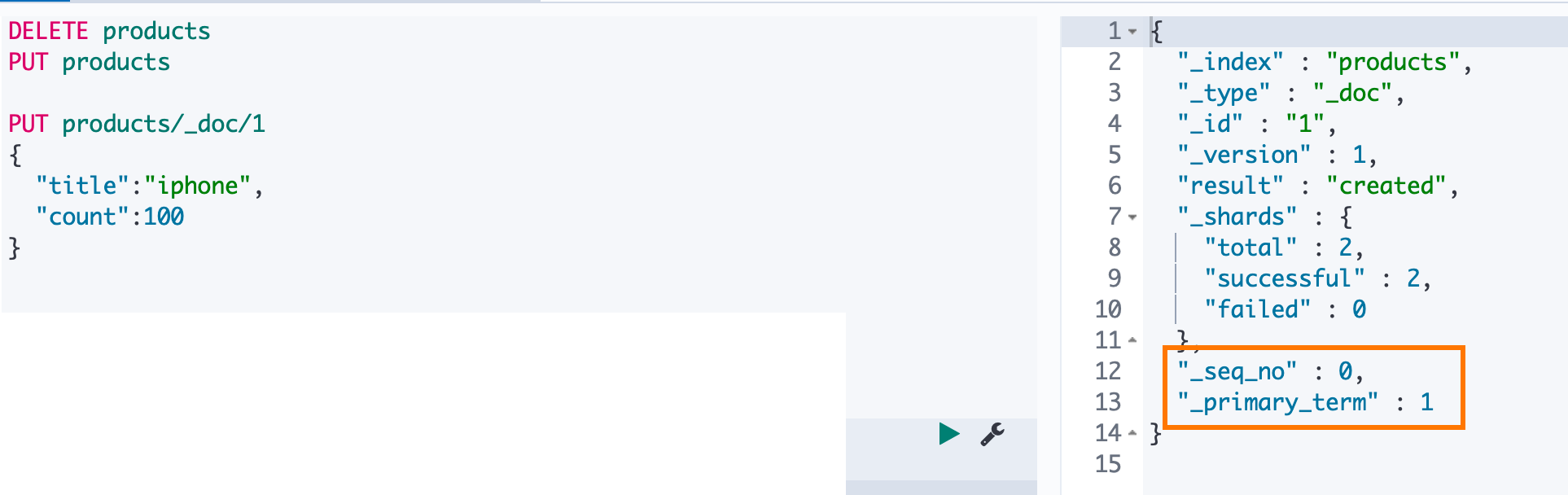
我们先建立一个 products 的索引然后写入一个 id为1的文档。可以看到写入数据成功,ES 给我们返回的 _version 是1,另外还有 _seq_no 和 _primary_term 两个属性值为0和1。
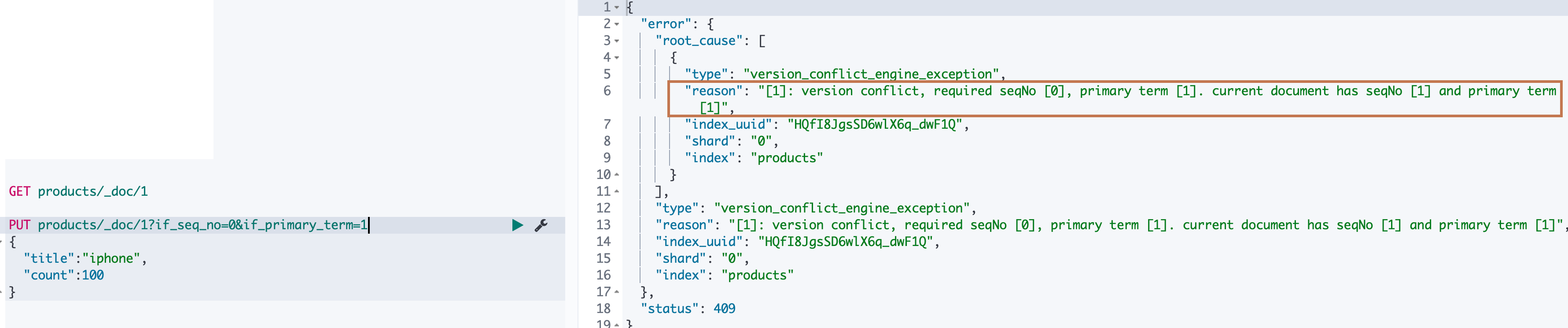
现在我们尝试对该文档进行更新,并使用 ES 的乐观版本控制,我们在请求的时候带上我们在修改数据之前通过查询得到的 _seq_no 和 _primary_term (0和1)。可以看到更新成功,返回的版本号 _version 被更新为2。另外 _seq_no 被更新为1, _primary_term 不变,还是1(这个 _primary_term 个人猜测应该是一个文档的唯一标识,这里应该就是 _id)。

然后我们尝试对该请求参数再发起一次请求,ES 给我们返回了版本冲突错误:
-
外部版本控制:使用 _version 和 _version_type 属性
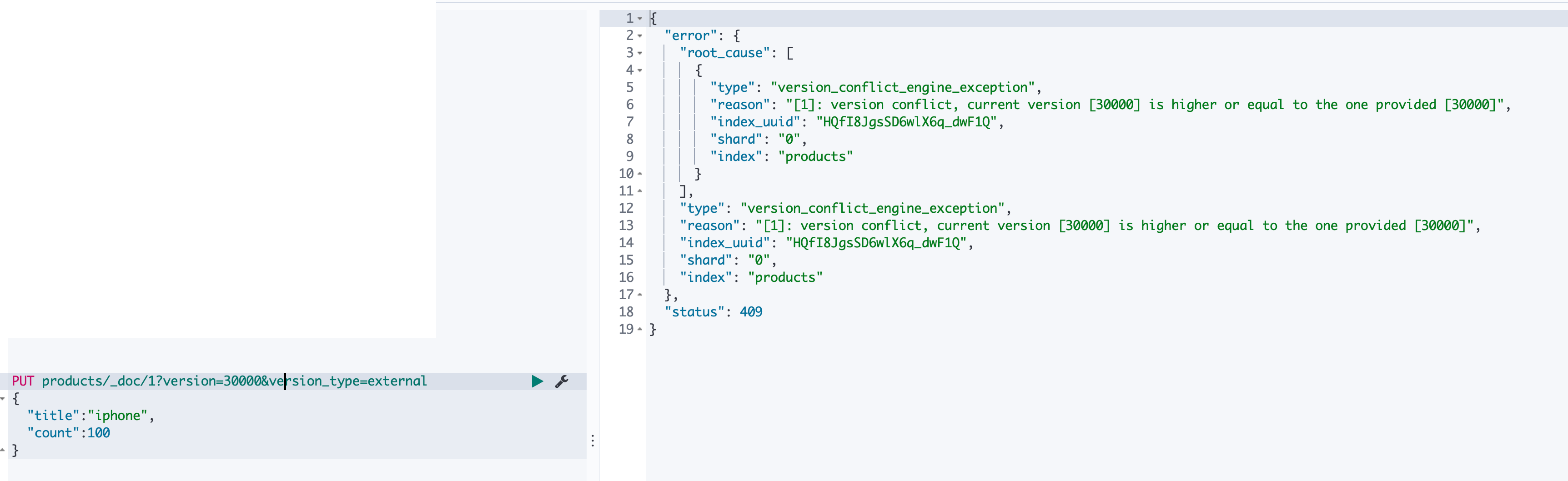
如果我们是使用数据库作为主要的数据存储介质,ES 仅仅是作为一个搜索引擎将数据同步到其中,那么我们可以设计在数据库中存储一个版本字段,然后将这个字段的值在 ES 中进行版本控制。我们看下面例子,在请求将 id 为1的文档进行更新的时候,我们对两个请求参数进行了设置: _version_type 设置为 external,这时候 ES 就允许我们对 _version 进行设值,我们可以将我们在数据库中设计的那个版本控制的字段的值设置到该字段,进行更新操作。可以看到更新成功,商品的版本号变成了我们写入的那个。(因为 _seq_no 不能被我们外部修改,所以区分了内部版本控制和外部版本控制)

此时我们再将该请求发送到 ES 的时候,将会收到版本冲突报错
¶其他注意
可以看到 ES 为我们提供了乐观版本控制的方式来解决"修改丢失"(或者叫修改覆盖)的方法。但是它并没有提供相关的传统关系型数据库中的事务解决方案(四大隔离级别,解决脏读、幻读、不可重复读的问题),所以如果我们对于事务有很强的要求,那么必须使用数据库进行数据更新的交互,在一个事务最终完成之后得到了一个当前事务的结果之后再使用以上的 ES 乐观版本控制进行 ES 的同步。



