[toc]
数据的关联关系
真实世界中有很多重要的关联关系:
- 博客、作者、评论
- 银行账户有多次交易记录
- 客户有多个银行账户
- 目录文件有多个文件和子目录
在关系型数据库中,提供了一些范式化设计。
- 1NF:消除非主属性对键的部分函数依赖
- 2NF:消除非主要属性对键的传递函数依赖
- 3NF:消除主属性对键的传递函数依赖
- BCNF:主属性不依赖于主属性
范式化设计(Normalization) 主要目的是"减少不必要的更新"。但是带来的副作用就是,一个完全范式化设计的数据库会经常面临"查询缓慢"的问题(数据库越范式化,就需要 join 越多的表)在最近的场景中,随着查询场景的增多,这个问题会暴露的越明显。除了可以简化操作(减少不必要的更新)之外还有节省存储空间的优点。但是最近存储空间却越来越便宜。
所以就有了反范式化设计(Denormalization)的概念。反范式化设计就是使得数据"Flattening"(扁平化),不使用关联关系,而是在文档中保存冗余的数据拷贝。
- 其优点是无需处理 join 操作,数据读取性能好。Elasticsearch 通过压缩_source 字段,减少磁盘空间的开销。
- 缺点是不适合在数据频繁修改的场景,一条数据的改动,可能会引起很多数据的更新。
关系型数据库一般会考虑 Normalize 数据;而在 Elasticsearch 中,往往考虑 Denormalize 数据,读取数据的时候无需连接表、无需行锁、读取速度变快。
Elasticsearch 并不擅长处理关联关系。我们一般采用以下4种方法处理关联:
- 对象类型
- 嵌套对象(Nested Object)
- 父子关联关系(Parent/Child)
- 用户自己在应用端关联
¶对象及 Nested 对象
数据关系其实可以最终抽象为一对一、一对多的关系(多对一和多对多关系都是由它们转化或者组合而来)。
¶案例1:一对一关系(对象)
我们来看一个以博客为主导的博客和作者的关系,对于一个博客来说,它只会有一个作者。所以我们可以通过以下设置来设定"博客"索引的 mapping。可以看到:
- 我们在mappings 下面的 properties 属性中设置博客索引的子属性,通过设置每个 properties 的子属性的一个 type 属性来指定其具体的"ES 普通类型"。(content、time 属性)
- 但是在 user 属性中,我们没有对其 type 属性值进行设定,而是设定了一个 properties 属性,属性值是一个嵌套的 JSON 对象,它包含了"text"类型的"city"属性、"long"类型的"userid"属性、"keyword"类型的"username"属性。这就是 ES 的 "对象"类型数据的设定方式。
DELETE blog
# 设置blog的 Mapping
PUT /blog
{
"mappings": {
"properties": {
"content": {
"type": "text"
},
"time": {
"type": "date"
},
"user": {
"properties": {
"city": {
"type": "text"
},
"userid": {
"type": "long"
},
"username": {
"type": "keyword"
}
}
}
}
}
}
其实我们插入一条文档数据
# 插入一条 Blog 信息
PUT blog/_doc/1
{
"content":"I like Elasticsearch",
"time":"2019-01-01T00:00:00",
"user":{
"userid":1,
"username":"Jack",
"city":"Shanghai"
}
}
在查询的时候通过 user.xxx=xxx 的指定作者的信息进行条件查询(包括查询的时候也是这样来更新指定博客文档中的作者信息):
# 查询 Blog 信息
POST blog/_search
{
"query": {
"bool": {
"must": [
{"match": {"content": "Elasticsearch"}},
{"match": {"user.username": "Jack"}}
]
}
}
}
¶案例2:一对多关系(Nested 对象)
我们来看一个电影和演员的例子,这是一个一对多关系,一个电影可以包含多个演员。下面我们来分析下在 ES 中关于一对多关系是如何存储的。
¶1、在索引中设置对象型字段
先准备数据。可以看到我们创建了一个电影索引,其包含了两个字段:一个是 title 字段,类型为普通类型"text";另一个 actors 字段是一个对象类型。这个对象包含一个"keyword"普通类型的 first_name 字段和一个"keyword"普通类型的 last_name 字段(注意,在 ES 中不用指定数组类型,每个文档的每个字段默认可以存储多个值)。
然后我们写入了一条电影文档数据:title 为 “Speed”;actors 有:“Keanu Reeves"和"Dnnis Hopper” 两位。
DELETE my_movies
# 电影的Mapping信息
PUT my_movies
{
"mappings" : {
"properties" : {
"actors" : {
"properties" : {
"first_name" : {
"type" : "keyword"
},
"last_name" : {
"type" : "keyword"
}
}
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
# 写入一条电影信息
POST my_movies/_doc/1
{
"title":"Speed",
"actors":[
{
"first_name":"Keanu",
"last_name":"Reeves"
},
{
"first_name":"Dennis",
"last_name":"Hopper"
}
]
}
¶2、基于对象型字段的查询
下面我们尝试来查询数据,分别指定"actors.first_name"和"actors.last_name"为"Keanu"和"Hopper",理论上应该查询不出来数据。但是实际上看到竟然匹配到了数据。下面我们来分析下为什么会匹配到了数据
# 查询电影信息
POST my_movies/_search
{
"query": {
"bool": {
"must": [
{"match": {"actors.first_name": "Keanu"}},
{"match": {"actors.last_name": "Hopper"}}
]
}
}
}

¶3、ES 对对象型字段的存储方法
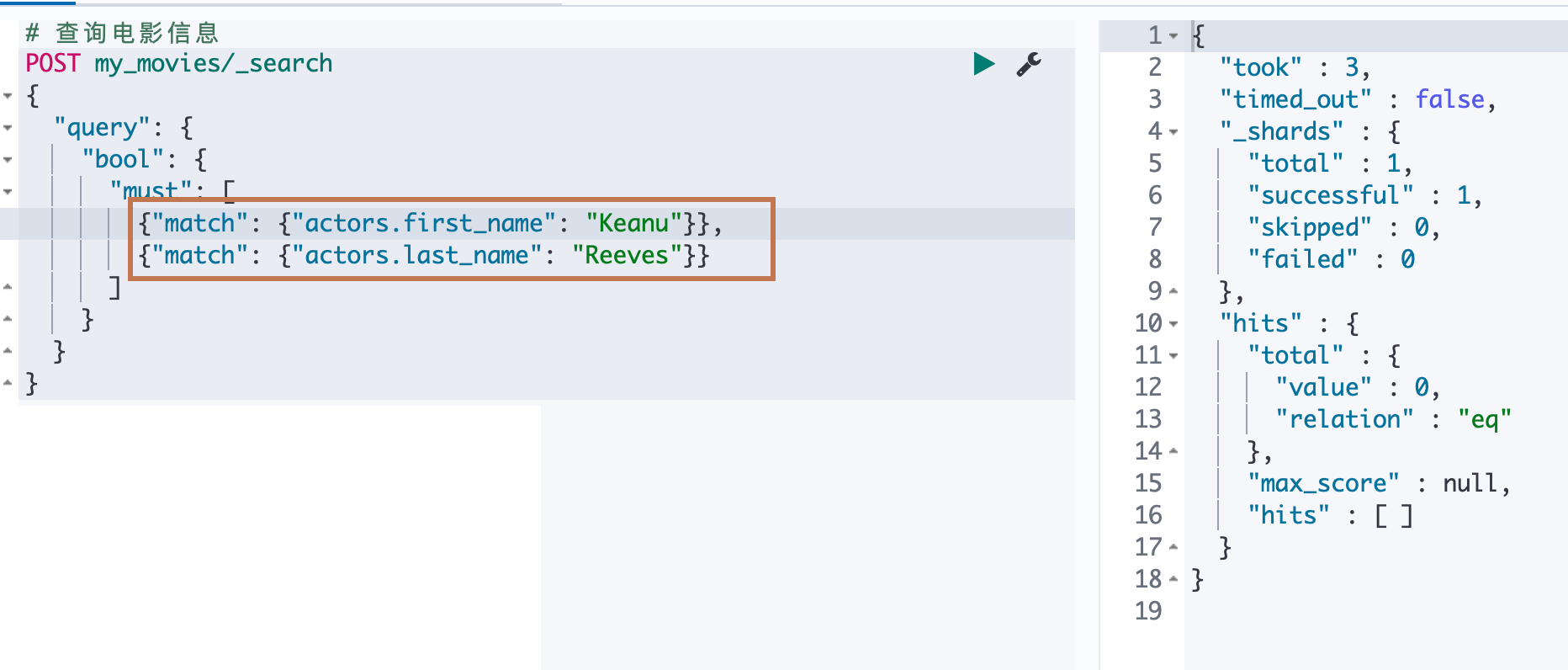
为什么上面会匹配到数据呢?这是因为,ES 在对文档数据进行存储的时候,内部对象的边界是没有考虑在内的,JSON 格式被处理成扁平式键值对的结构。

当对一个对象类型的属性进行多值"并"查询的时候就会导致了意外的搜索结果。此时我们可以通过用 Nested Data Type解决这个问题。
¶4、创建 nested 对象型字段
创建 nested 类型字段。删除之前创建的索引,重新创建索引,可以看到,我们在设定"actors"字段的时候除了指定"properties"属性之外,还设定了一个"type"属性为"nested"。
DELETE my_movies
# 创建 Nested 对象 Mapping
PUT my_movies
{
"mappings" : {
"properties" : {
"actors" : {
"type": "nested",
"properties" : {
"first_name" : {"type" : "keyword"},
"last_name" : {"type" : "keyword"}
}},
"title" : {
"type" : "text",
"fields" : {"keyword":{"type":"keyword","ignore_above":256}}
}
}
}
}
POST my_movies/_doc/1
{
"title":"Speed",
"actors":[
{
"first_name":"Keanu",
"last_name":"Reeves"
},
{
"first_name":"Dennis",
"last_name":"Hopper"
}
]
}
¶5、基于 nested 型字段的查询和聚合
基于 nested 类型字段的查询。此时我们如果需要对 nested 类型字段进行查询,就需要使用一个 “nested” 查询,然后通过设定其"path"属性为我们要查询的"nested"类型的字段名称"actors"。然后再在里面嵌套上我们前面的 bool 查询的内容。可以看到,这次查询不正确的姓和名组合就没有返回数据了。
# Nested 查询
POST my_movies/_search
{
"query": {
"bool": {
"must": [
{"match": {"title": "Speed"}},
{
"nested": {
"path": "actors",
"query": {
"bool": {
"must": [
{"match": {
"actors.first_name": "Keanu"
}},
{"match": {
"actors.last_name": "Hopper"
}}
]
}
}
}
}
]
}
}
}

当我们查询正确的姓名组合的时候,就可以返回正确的数据
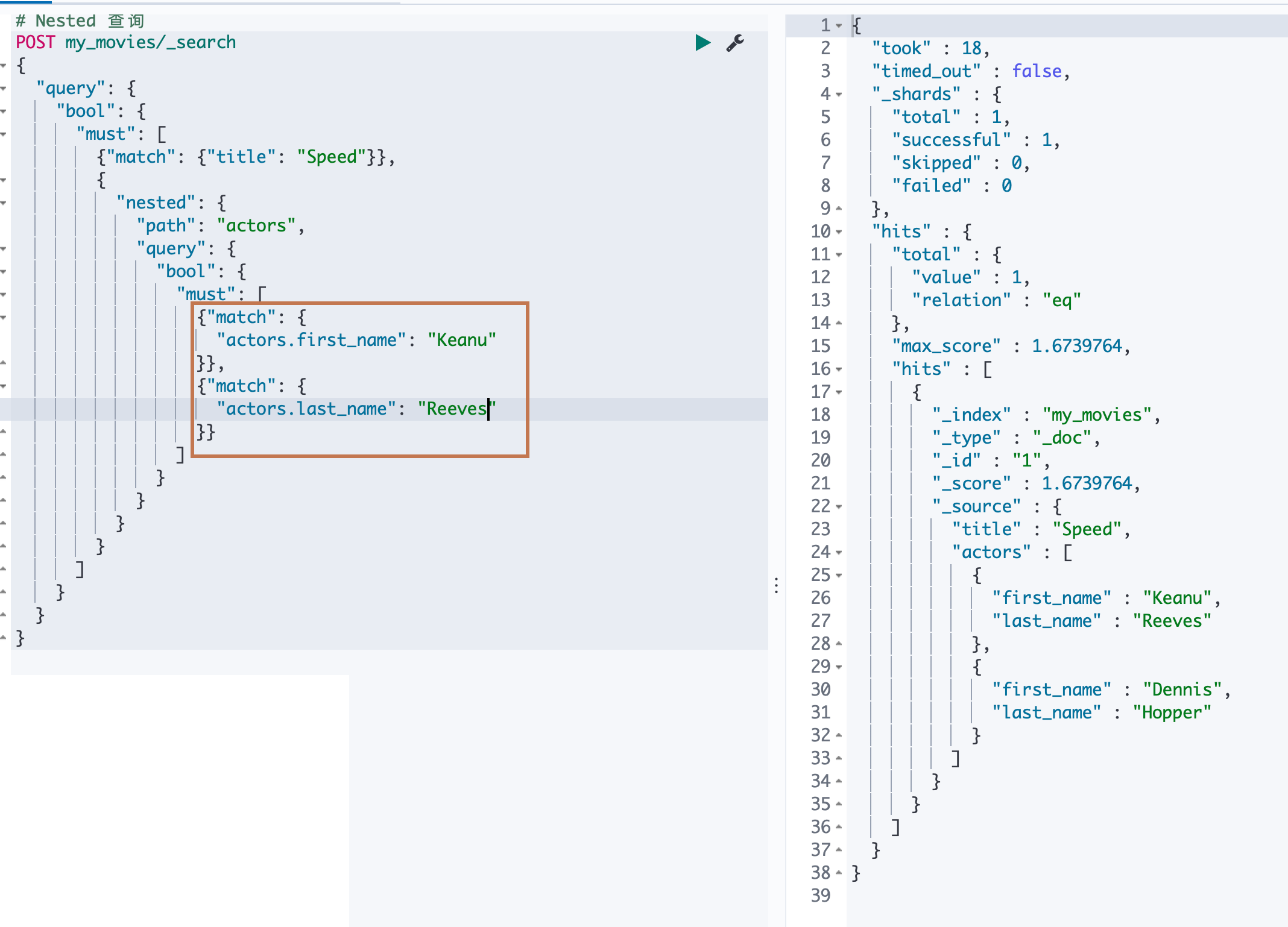
当我们再用一个正确的姓名组合去做一个普通的非 nested 的 bool 查询的时候,会发现也匹配不到数据了,为什么会这样呢?下面我们来分析一下原因。
另外当我们需要对 nested 类型的字段进行聚合的时候,我们一样要声明当前聚合操作是对于 nested 类型字段的聚合。通过在具体的 agg 对象内部声明一个"nested"的属性对象,一样的,该对象的"path"属性设置为 nested 类型字段的名称。
# Nested Aggregation
POST my_movies/_search
{
"size": 0,
"aggs": {
"actors": {
"nested": {
"path": "actors"
},
"aggs": {
"actor_name": {
"terms": {
"field": "actors.first_name",
"size": 10
}
}
}
}
}
}
¶6、ES 对于 nested 型字段的存储方法
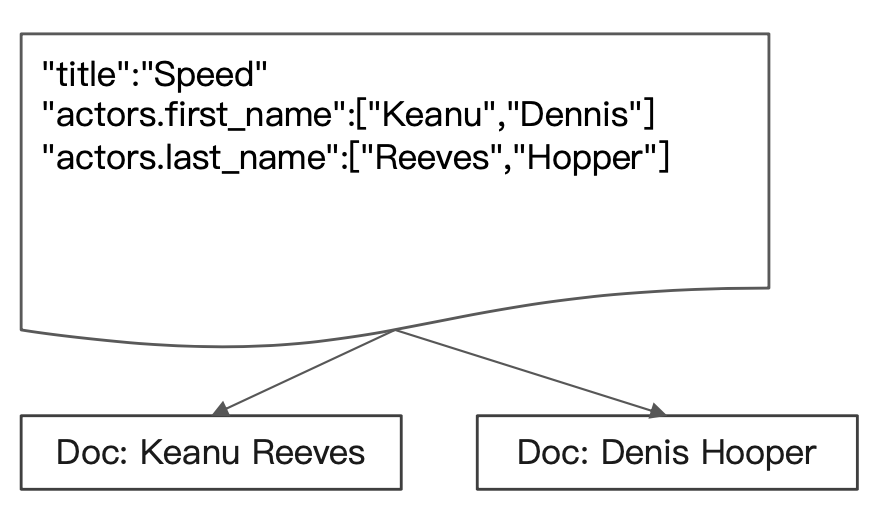
在 ES 中,对于 nested 数据类型,会对该字段所有对象进行独立索引。在 ES 内部会将这个多个nested 类型属性对象索引到多个分隔的 Lucene 文档中,在查询的时候做 Join 处理。所以我们在对 nested 类型数据的时候需要 nested 查询,该查询会让 ES 知道当前用户需要到另外的一个独立的 nested 文档集合进行数据查找,而 nested 这个文档集合的名称(用来在当前索引中聚合这些文档,其实可以理解为给这些文档起了个统一前缀)在建立的时候是取的该 nested 类型字段名做关联的,所以我们需要指定字段名告诉 ES 到哪个nested 文档集合进行关联查询。
另外我们上面还尝试使用正确姓和名的组合是查询不出来数据的。正如我们上面的描述,ES 在存储 nested 类型数据的时候是存储到另外一个专门存储 nested 类型字段数据的独立文档中的,所以一个正常的 bool 查询就是在当前文档中进行指定的"键值匹配"。当然找不到数据!
¶相关阅读
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/query-dsl-nested-query.html
¶文档的父子关系
经过上面的介绍我们知道了可以使用对象类型字段和 nested 对象类型字段存储有关系的数据。但是使用这两种数据类型有一个局限性就是,当需要对文档中的嵌套的对象类型字段或者 nested 对象类型字段进行更新的时候,我们往往也要更新其他文档中的数据。
例如1个作者有3篇文章,我们在 ES 中存储了以文章为主导的文档数据,其中文章文档中有一个对象(或者 nested 对象)类型字段表示其作者。所以当前索引中是有三个文章文档的作者字段内容是一样的,但我们修改了这个作者的信息的时候,需要同时更新这三个文章文档。
这在某些索引的写操作远远比读操作要频繁的时候,是很不友好的。所以 ES 还提供了另外一种类似关系型数据库中 join 的实现。使用 join 数据类型实现,可以 通过维护 parent、child 的关系,从而分离两个对象:
- 父文档和子文档是同时存在于索引中的两个独立的文档
- 更新父文档无需重新索引子文档。子文当被添加,更新或者删除也不会影响父文档和其他的子文档。
¶1、定义父子关系的几个步骤
我们使用以下请求创建一个名为"my_blogs"的索引:
-
通过 settings 设定了该索引的分片数为2
-
在 mappinigs 中显示设置了两个字段为 context 和 title,前者为 text 类型,后者为 keyword 类型。在业务上,这两个字段都属于博客的字段。
-
此外在 mappings 中我们还设置了一个关键属性"blog_comments_relation",它的 type 字段不是 ES 中的普通字段类型也不是 nested 类型,而是"join",ES 会基于该属性在该索引上建立一个父子文档关系对象。
其中由"relations"关键字来维护多个父子关系集合,relation 对象的每个属性都代表一个父子关系,可以通过设置多个属性来设置多个父子关系:其中属性名为当前父子关系中的父文档的标识;属性值为当前父子关系的子文档标识。在往当前索引中索引文档的时候通过设置文档字段"blog_comments_relation.name"为 relation 中某个属性的属性名后者属性值来指定当前文档是哪对父子关系中的父或者子文档。
(注意:同一个索引中不能创建多个"join"类型的同级属性;relations 关键字不支持多值。设置了就会报4xx 的错误)
DELETE my_blogs
# 设定 Parent/Child Mapping
PUT my_blogs
{
"settings": {
"number_of_shards": 2
},
"mappings": {
"properties": {
"blog_comments_relation": {
"type": "join",
"relations": {
"blog": "comment"
}
},
"content": {
"type": "text"
},
"title": {
"type": "keyword"
}
}
}
}
¶2、索引父文档
下面我们索引两个父文档(博客数据对象)到索引中:
- 我们分别为它们指定了 id 为"blog1"和"blog2",为了后面索引子文档的时候方便获取该 id
- 它们包含的字段有"title"和"content"
- 其中我们还通过指定文档数据的"blog_comments_relation.name"来标识其为"blog:comment"父子关系中的父文档(blog)
#索引父文档
PUT my_blogs/_doc/blog1
{
"title":"Learning Elasticsearch",
"content":"learning ELK @ geektime",
"blog_comments_relation":{
"name":"blog"
}
}
#索引父文档
PUT my_blogs/_doc/blog2
{
"title":"Learning Hadoop",
"content":"learning Hadoop",
"blog_comments_relation":{
"name":"blog"
}
}
¶3、索引子文档
下面我们往索引中索引了3个子文档:
-
我们分别指定了它们的 id 为 comment1、comment2和 comment3并给他们设置了路由分片的 hash key 为对应的父文档 id,这非常重要,我们需要保证父文档和子文档必须存在相同的分片上以确保查询 join 的性能。(如果父文档和子文档没有同时在同一个分片上会发生什么?这个待后续研究)
-
子文档包含了两个未在 mapping 上显示声明的字段 comment 和 username
-
通过指定文档的"blog_comments_relation.name"属性为 comment 来指定当前文档为"blog:comment"父子关系中的子文档。
通过指定文档的"blog_comments_relation.parent"属性为当前文档的父文档 id 来指定当前子文档的父文档,这是必须的
#索引子文档
PUT my_blogs/_doc/comment1?routing=blog1
{
"comment":"I am learning ELK",
"username":"Jack",
"blog_comments_relation":{
"name":"comment",
"parent":"blog1"
}
}
#索引子文档
PUT my_blogs/_doc/comment2?routing=blog2
{
"comment":"I like Hadoop!!!!!",
"username":"Jack",
"blog_comments_relation":{
"name":"comment",
"parent":"blog2"
}
}
#索引子文档
PUT my_blogs/_doc/comment3?routing=blog2
{
"comment":"Hello Hadoop",
"username":"Bob",
"blog_comments_relation":{
"name":"comment",
"parent":"blog2"
}
}
¶4、查询
¶1)查询所有文档
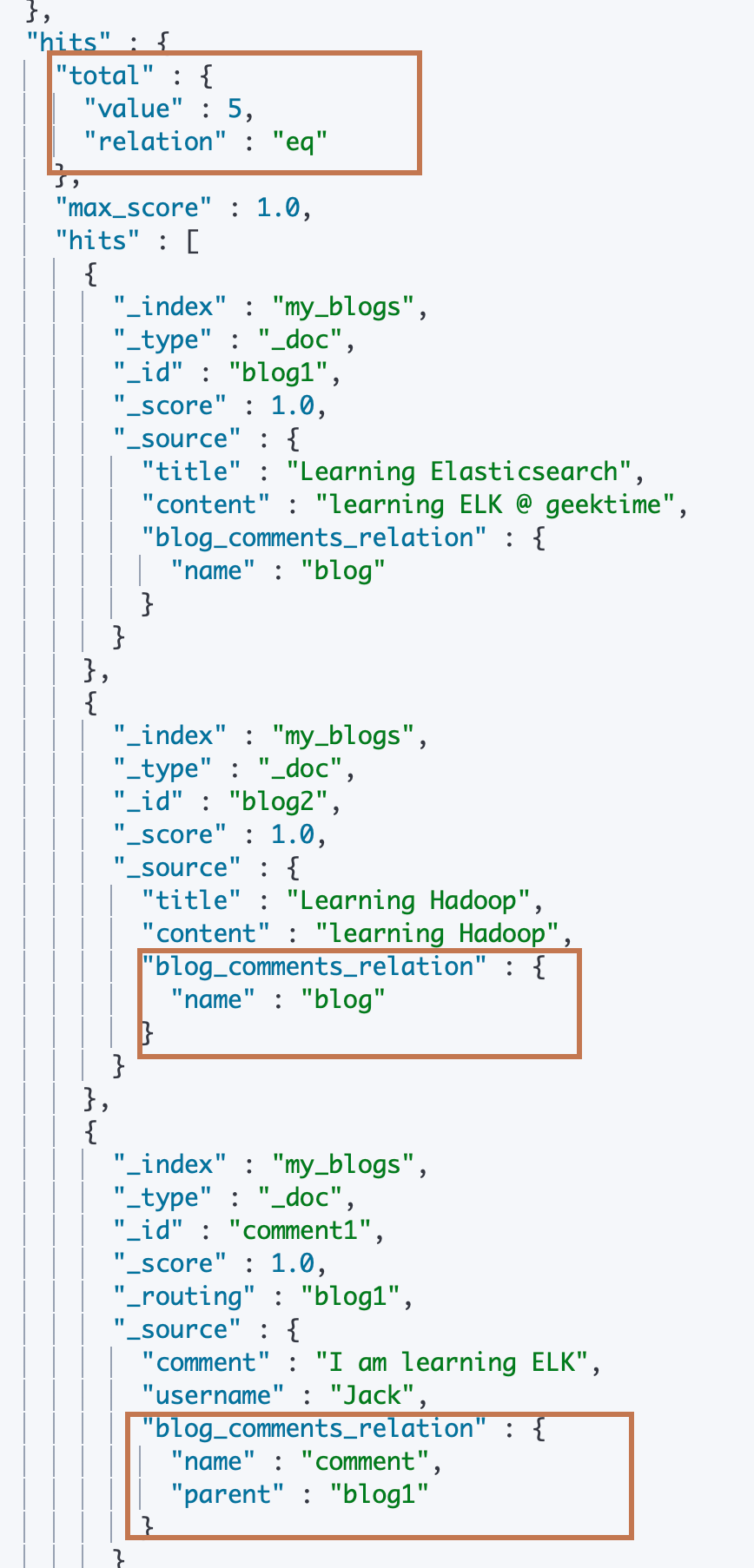
可以看到查询所有文档的时候,索引内的所有父子文档都是可以返回的,包括文档的父子关系标识信息。
# 查询所有文档
POST my_blogs/_search
{
}
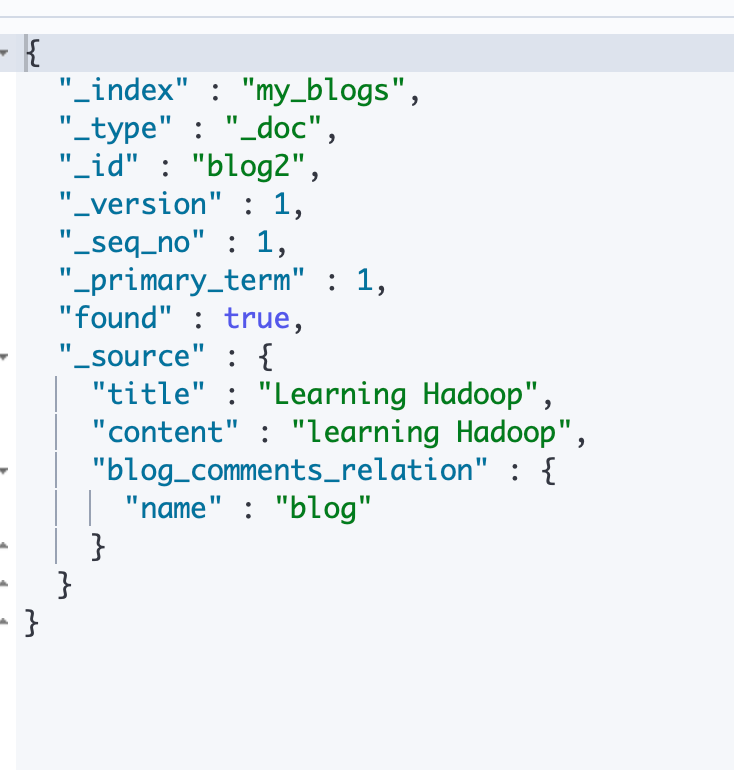
¶2)通过文档 id 直接查询父文档(不包含子文档内容)
可以看到也是可以返回的,父文档不包含子文档的内容
#根据父文档ID查看
GET my_blogs/_doc/blog2
¶3)通过 “parent_id” 查询查询子文档信息
- 指定 query 为 parent_id 类型的查询
- 并设置parent_id 的子属性 type 为 comment(即 mapping 中设置的 relations 关键字中的属性值)指定子文档的类型
- 指定 parent_id 的子属性 id 为父文档的 id “blog2”
可以看到,ES 返回了 blog2 父文档的2个子文档 comment2和 comment3
# Parent Id 查询
POST my_blogs/_search
{
"query": {
"parent_id": {
"type": "comment",
"id": "blog2"
}
}
}
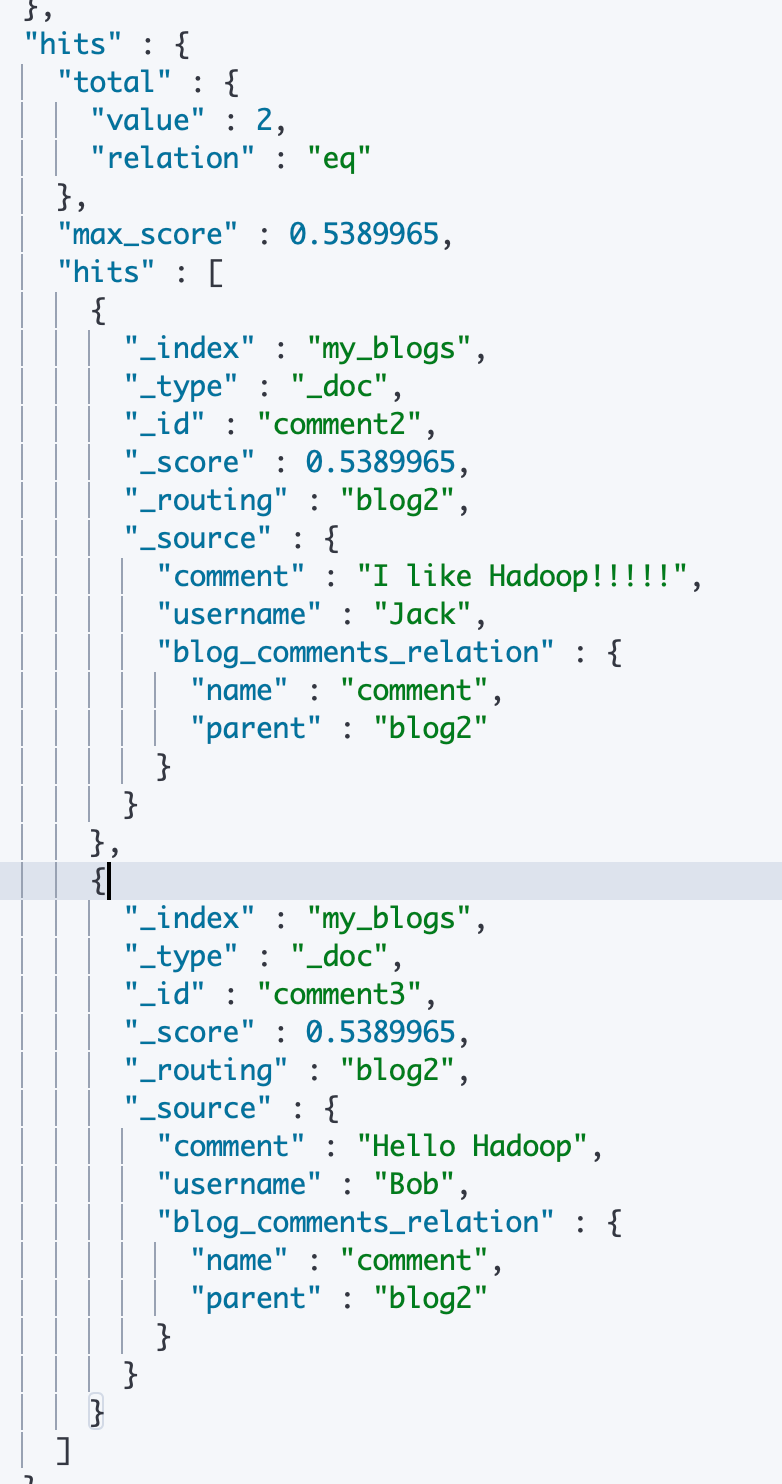
¶4)“has_child” 查询通过子文档的信息查询父文档
- 指定 query 类型为"has_child"查询类型
- 通过设置 has_child 的子属性 type 为comment(即 mapping 中设置的 relations 关键字中的属性值)指定子文档的类型
- 设置一个查询对象到 has_child 的子属性,这里设置为 match 查询类型,查询字段是 username,值为 “Jack”
以上请求在收到信息之后会去查询类型为 comment 的子文档中是否有 username 为"jack"的文档,如果有,则返回其关联的父文档。可以看到,结果中返回了 blog1和 blog2父文档,它们分别关联一个comment1和 comment2子文档其中 username 字段都是 Jack。
# Has Child 查询,返回父文档
POST my_blogs/_search
{
"query": {
"has_child": {
"type": "comment",
"query" : {
"match": {
"username" : "Jack"
}
}
}
}
}

¶5)“has_parent” 查询通过父文档的信息查询子文档
和"has_child"类似,"has_parent"则是通过父文档的信息查询子文档。
- 指定 query 类型为"has_parent"查询类型
- 通过设置 has_parent 的子属性 type 为 blog(即 mapping 中设置的 relations 关键字中的属性值)指定父文档的类型
- 设置一个查询对象到 has_parent 的子属性,这里设置为 match 查询类型,查询字段是 title,值为 “Learning Hadoop”
以上请求在收到信息之后会去查询类型为 blog 的父文档中进行"titile = Learning Hadoop"的 match 查询,如果匹配到了文档数据,则返回其关联的子文档。可以看到,结果中返回了 comment2和 comment3 子文档,它们都关联 blog2父文档,而该父文档的 title 就是"Learning Hadoop"(该字段类型是 keyword,精准匹配)。
# Has Parent 查询,返回相关的子文档
POST my_blogs/_search
{
"query": {
"has_parent": {
"parent_type": "blog",
"query" : {
"match": {
"title" : "Learning Hadoop"
}
}
}
}
}
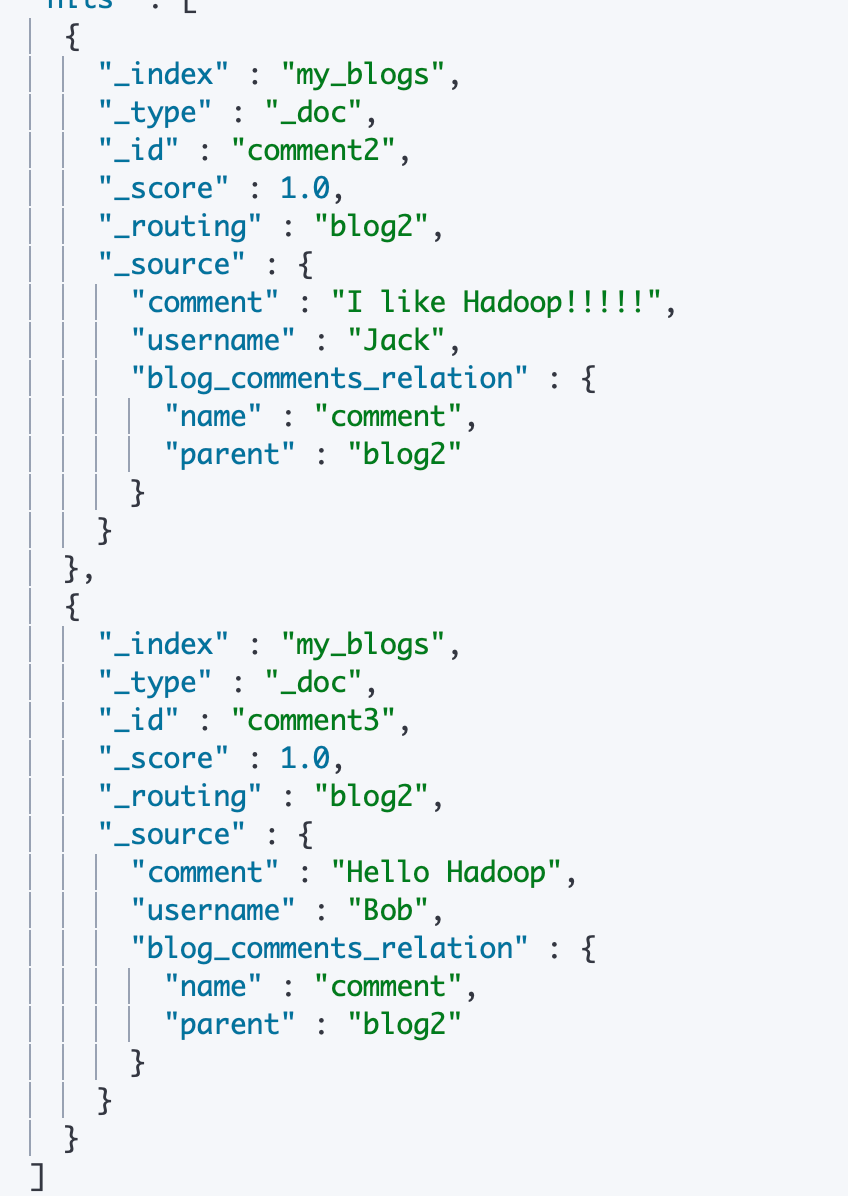
¶6) 通过文档 id 直接访问子文档
当我们直接通过子文档的 id 进行访问子文档的时候,是查询不到子文档的。
#通过ID ,访问子文档
GET my_blogs/_doc/comment3
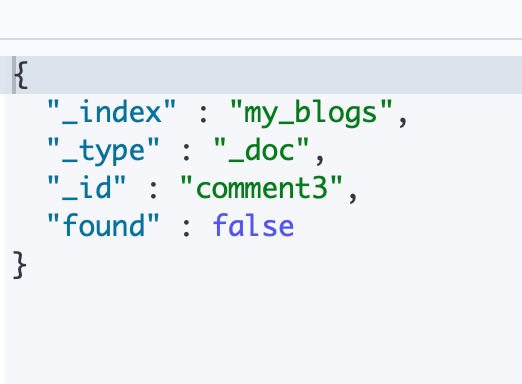
需要在id 后面加上 routing 才行:
#通过ID和routing ,访问子文档
GET my_blogs/_doc/comment3?routing=blog2

另外通过 id 更新子文档的时候也要指定 routing:
#更新子文档
PUT my_blogs/_doc/comment3?routing=blog2
{
"comment": "Hello Hadoop??",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}
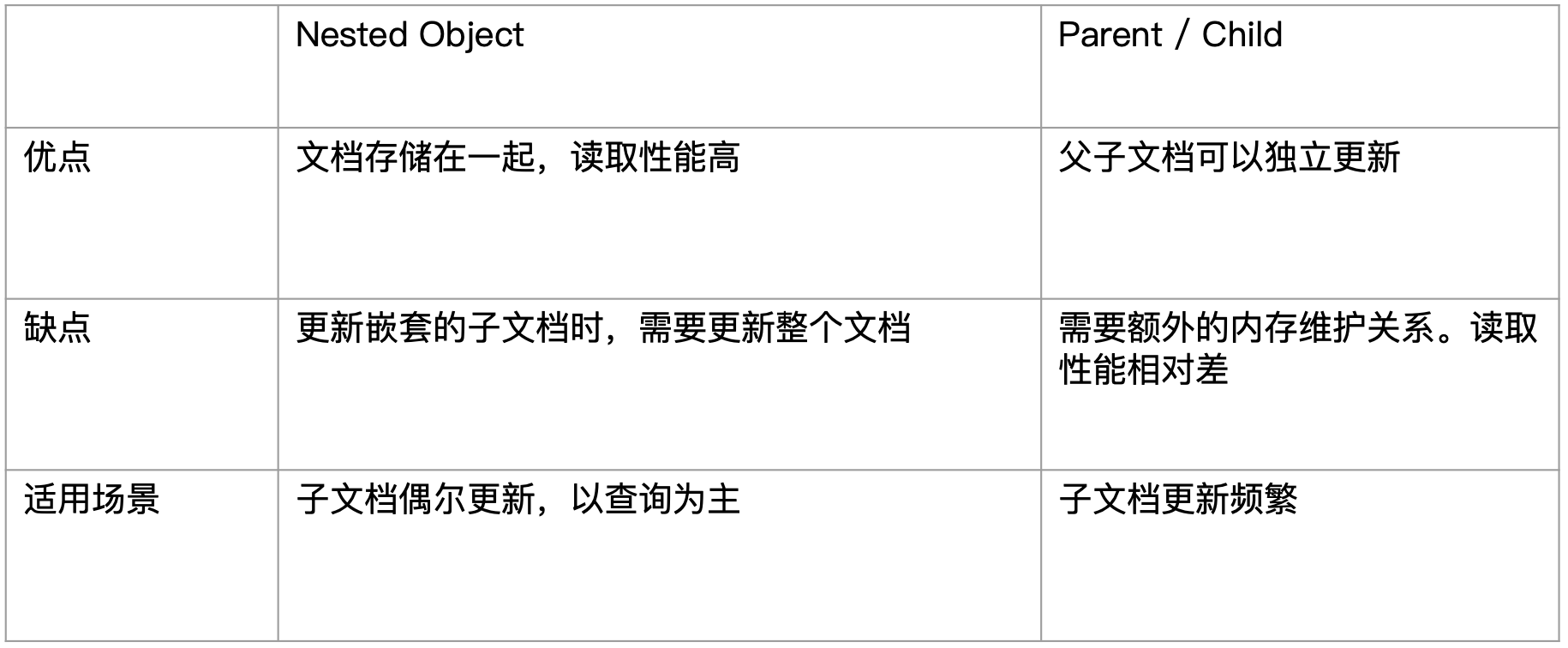
¶嵌套对象 v.s. 父子文档
¶相关阅读
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/query-dsl-has-child-query.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/query-dsl-has-parent-query.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/query-dsl-parent-id-query.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/query-dsl-parent-id-query.html
重建索引
一般在以下几种情况时,我们需要重建索引:
- 索引的 Mappings 发生变更:字段类型更改、分词器及字段更新
- 索引的 Settings 发生变更:索引的主分片数发生改变
- 集群内/集群间需要做数据迁移
ES 内置的关于重建索引的 API 两个:
- Update By Query:在现有索引上重建
- Reindex:在其他索引上重新构建出当前索引
¶案例1:为索引增加子字段(Update By Query)
下面我们来描述一个给索引 mapping 中的字段增加一个子字段并使用 Update By Query 重建索引的过程。
-
直接往一个索引在写入文档,使用 ES 的 Dynamic Mapping 自动创建索引
DELETE blogs/ # 写入文档 PUT blogs/_doc/1 { "content":"Hadoop is cool", "keyword":"hadoop" } -
查看刚刚创建的索引,可以看到 ES 为这个索引创建了一个 Mapping,并自动设置content和 keyword 字段,类型都是 text,并且都为他们创建一个子字段keyword,类型为 keyword。
# 查看 Mapping
GET blogs/_mapping

-
其实我们想修改 Mapping 中的 content 字段,为其增加一个子字段"english",类型不变,设置分词器为"english",使得我们更好地使用英文内容对该字段进行搜索。
# 修改 Mapping,增加子字段,使用英文分词器 PUT blogs/_mapping { "properties" : { "content" : { "type" : "text", "fields" : { "english" : { "type" : "text", "analyzer":"english" } } } } } -
写入新的文档并对新加的字段进行查询,是可以查出来数据的
# 写入文档 PUT blogs/_doc/2 { "content":"Elasticsearch rocks", "keyword":"elasticsearch" } # 查询新写入文档 POST blogs/_search { "query": { "match": { "content.english": "Elasticsearch" } }
-
但是当我们对旧的文档对新加字段进行查询的时候,发现查询不到数据。
# 查询 Mapping 变更前写入的文档 POST blogs/_search { "query": { "match": { "content.english": "Hadoop" } } }
-
使用
_update_by_queryapi 进行现有的索引重建后再查询新数据。即可查询出来了。# Update所有文档 POST blogs/_update_by_query { } # 查询之前写入的文档 POST blogs/_search { "query": { "match": { "content.english": "Hadoop" } } }
¶案例2:更改 Mapping 中的字段的类型(ReIndex)
ES 是不允许我们修改现有 mapping 中已经定义的字段的类型的,直接报错:
PUT blogs/_mapping
{
"properties" : {
"content" : {
"type" : "text",
"fields" : {
"english" : {
"type" : "text",
"analyzer" : "english"
}
}
},
"keyword" : {
"type" : "keyword"
}
}
}

那么如果我们确实要修改字段类型怎么办呢?只能创建新的索引,并且设置正确的字段类型,再通过 reindex api 将老索引的数据导入到新索引。下面我们来描述一个修改Mapping 中字段的场景:
-
创建新索引并设置正确的字段类型
DELETE blogs_fix # 创建新的索引并且设定新的Mapping PUT blogs_fix/ { "mappings": { "properties" : { "content" : { "type" : "text", "fields" : { "english" : { "type" : "text", "analyzer" : "english" } } }, "keyword" : { "type" : "keyword" } } } } -
调用 ES 的
_reindexapi 将老索引的数据重新导入到新索引# Reindx API POST _reindex { "source": { "index": "blogs" }, "dest": { "index": "blogs_fix" } }从新索引查询 id 为1的文档
GET blogs_fix/_doc/1
我们刚刚将一个 keyword 字段从 text 类型修改为 keyword 类型,通过 terms agg 进行测试,是没有问题的:
# 测试 Term Aggregation POST blogs_fix/_search { "size": 0, "aggs": { "blog_keyword": { "terms": { "field": "keyword", "size": 10 } } } }
¶ReIndex 总结
¶1、使用场景
- 修改索引的主分片数
- 改变 Mapping 中的字段类型
- 集群内数据迁移/跨集群的数据迁移
¶2、数据冲突的解决方案
另外当我们往新索引中进行 _reindex 的时候,有可能已经存在了一些数据。在默认情况下以及设置"dest.version_type=internal"的时候,ES 将会将强制覆盖所有已经存在的文档,然后版本号+1。
//默认情况
POST _reindex
{
"source": {
"index": "twitter"
},
"dest": {
"index": "new_twitter"
}
}
//设置 version_type 为 internal
POST _reindex
{
"source": {
"index": "twitter"
},
"dest": {
"index": "new_twitter",
"version_type": "internal"
}
}
通过设置"dest.version_type=external"可以让 ES 在遇到已经存在的文档的时候比较两者的版本,当已存在于 dest 中的文档的版本低于 source 中版本的时候,就会更新dest 中的该文档;如果无冲突将直接索引文档。
另外我们可以通过设置"dest.op_type=create"来让 _reindex 仅仅创建目标 index 中缺失的文档。所有的已经存在的文档都会导致一个版本冲突。

默认情况下,以上版本冲突会使得 _reindex 操作中止。我们可以通过设置 _reindex 的直接属性 “conflicts=proceed” 让 _reindex 在遇到版本冲突的时候跳过当前这个文档,继续处理下一个文档,当 _reindex 完成之后会返回遇到版本冲突的数量。(注意,这个参数仅仅可以对版本冲突错误有效,其他错误还是会中止 _reindex 操作)
¶3、筛选需要 _reindex 的数据
有时,我们并不想对所有的文档进行迁移。我们可以通过在 source 属性中指定一个查询来筛选我们需要 _reindex 的数据。此外,对于 size、sort 等在查询动作中设定的参数都是可以设置的,具体参考官方文档。
POST _reindex
{
"source": {
"index": "twitter",
"query": {
"term": {
"user": "kimchy"
}
}
},
"dest": {
"index": "new_twitter"
}
}
¶4、跨集群 Reindex
ES 同时还支持跨集群的 reindex,我们先在本地(dest)中修改 elasticearch.yml 文件中的配置reindex.remote.whitelist: "otherhost:9200, another:9200”开启白名单(对 source 的端口),然后设置 source 的 remote 属性进行远程连接配置,最后发起 _reindex 操作

¶5、异步 reiindex
同时 reindex 还支持异步操作。通过指定 url 参数wait_for_completion=false来实现:
POST _reindex?wait_for_completion=false
{
... ...
}
此时执行该请求将会得到一个 task id。可以通过 _task api 来查看任务状态:
GET _tsak?detailed=true&actions=*reindex
{
}

使用 Reindex API 的注意点:
- 在进行 reindex 操作的 source index 中,必须保证所有文档的 _source 字段是可用的。
- reindex api 不会去尝试创建目标索引,也不会复制源索引的 settings 到目标索引。用户必须在进行 _reindex 之前手动设置目标索引的 mappings、shard 数量、replicas 等。
- 建议对 api 使用 alias,在 reindex 好之后可以直接切换 alias 指向的新 index 即可。
¶相关阅读
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/docs-reindex.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/docs-update-by-query.html
Ingest Pipeline & Painless Script
¶Ingest Node
Ingest Node 是在 Elasticsearch 5.0后,引入了一种新的节点。默认配置下,每个节点都是Ingest Node。
- 可拦截 Index 或者 Bulk API 的请求,对数据进行预处理(如:为某个字段设置默认值、重命名某个字段的字段名、对字段值进行 Split 操作等),处理完成之后重新返回给 index 或者 Buik API
- 相对 Logstash 无需额外引入新的工具依赖,就可以进行数据预处理
- 支持设置 Painless 脚本,对数据进行更加复杂的加工
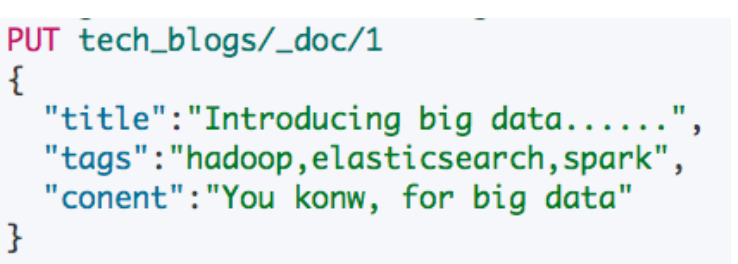
例如以下 index 的请求中 tags 字段时候一个使用逗号分隔的文本,我们现在需要对其进行分隔之后再存入 ES,方便后期需要对 Tags 字段进行Aggregation 统计:
¶1、Pipeline & Processor
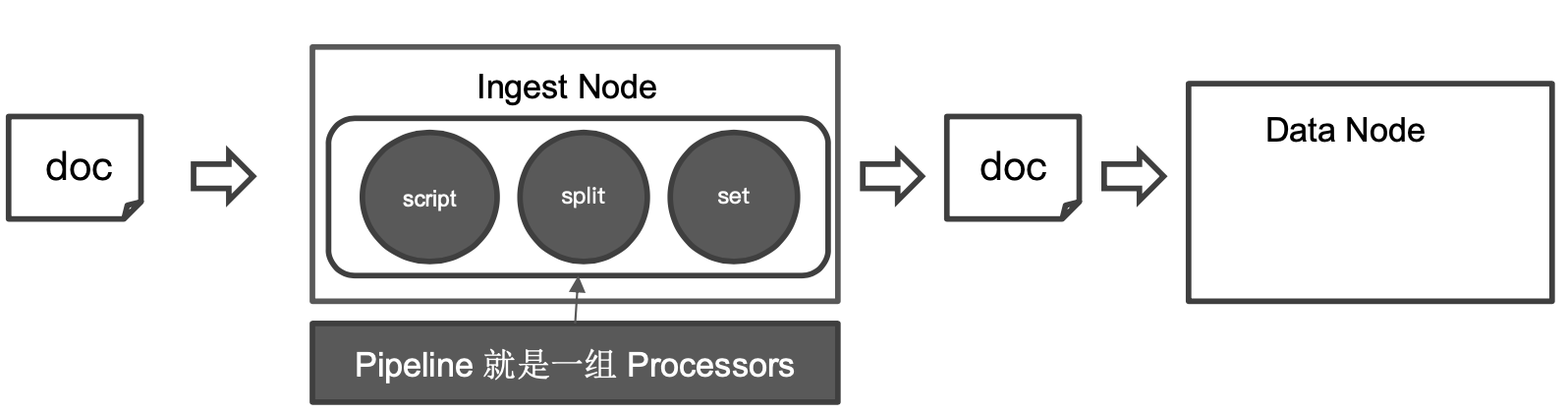
Pipeline:管道会对通过的数据(文档)按照顺序进行加工。
Processor:Elasticsearch 对一些加工的行为进行了抽象包装,它提供了很多内置的 Processors。也支持通过插件的方式,实现自己的 Processor。
¶2、Ingest API
参考下面的示例,ingest api 在 ES 中是一个定级 api,路径为_ingest。后面紧跟的就是 pipeline,即我们上面提到的概念。

¶1)Ingest pipeline 测试
在 pipeline 后面定义的路径或者 restful 方法就是ES 实际提供的 ingest api。_simulate 是 ES 提供的一个可以对 ingest pipeline 进行测试的 api。参考以下示例:
-
我们对该 api 的请求体对象中的 pipeline属性进行了定义,包括这个 pipeline 的描述和 pipeliine 中包含的 processors。
这里仅定义了两个 processors:第一个是"split" processor,它对所有文档的"tags"字段进行一个以",“为分隔符的分隔操作,然后将分隔后得到的一个字符串数组覆盖到文档的 tags 属性中;第二个是"set” processor,为每一个文档增加一个字段,并设置默认值为0。
-
然后在 api 请求体中通过设置 docs 填充测试文档数据。可以看到这些文档数据都包含一个 tags 字段,都是以逗号分隔。且都增加了一个 view 字段,值为0。
可以看到api 发出调用后返回的结果中,两个文档的 tags 字段都被分隔成了一个数组。
//对 tags 字段进行逗号切割,并为所有文档增加一个字段默认值为0
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description": "to split blog tags",
"processors": [
{
"split": {
"field": "tags",
"separator": ","
}
},
{
"set":{
"field": "views",
"value": 0
}
}
]
},
"docs": [
{
"_index":"index",
"_id":"id",
"_source":{
"title":"Introducing big data......",
"tags":"hadoop,elasticsearch,spark",
"content":"You konw, for big data"
}
},
{
"_index":"index",
"_id":"idxx",
"_source":{
"title":"Introducing cloud computering",
"tags":"openstack,k8s",
"content":"You konw, for cloud"
}
}
]
}

¶2)新增一个 ingest pipeline
在上面经过测试之后我们的 ingest pipeline 是没有问题的,此时我们就可以创建这个 pipeline 对象了。通过调用 PUT 方法并在 _ingest/pipeline/ 后面加上我们要创建的这个 pipeline 对象的 id进行创建。
然后可以通过 GET 方法使用同样的 URI 进行查询动作。
另外我们还能对创建之后的 pipeline 再次进行 _simulate 的测试动作,请求方法为 POST 方法,URI 则是上面创建和查询使用的 URI 拼接上子路径 _simulate,然后在请求体中直接设置测试文档到"docs"属性。而不用像前面的测试动作一样需要指定"pipeline"属性。
# 为ES添加一个 Pipeline
PUT _ingest/pipeline/blog_pipeline
{
"description": "a blog pipeline",
"processors": [
{
"split": {
"field": "tags",
"separator": ","
}
},
{
"set":{
"field": "views",
"value": 0
}
}
]
}
#查看Pipleline
GET _ingest/pipeline/blog_pipeline
#测试pipeline
POST _ingest/pipeline/blog_pipeline/_simulate
{
"docs": [
{
"_source": {
"title": "Introducing cloud computering",
"tags": "openstack,k8s",
"content": "You konw, for cloud"
}
}
]
}

¶3)使用创建之后的 ingest pipeline
在创建了 ingest pipeline 之后我们就可以在对文档 index 的时候(通过 index或者 bulk api)使用这些 pipeline 了。
下面我们来看一些例子:
我们在第一个请求中没使用 ingest pipeline,tags 中的数据是原封不动地存储到文档中然后被索引;而在第二个请求中,我们在索引数据的 URI 后面使用了一个"piipeline=${pipeline_name}"的参数,指定了我们要对本次文档数据使用id 为"blog_pipeline"的 ingest pipeline 进行预处理,即我们前面创建的 pipeline。
两个索引文档的请求都执行之后,我们通过 _search api 查询索引后的两个文档。可以看到第一个文档的 tags 还是没有处理的;而第二个文档的 tags 字段则是被分隔成了一个字符串数组。
#不使用pipeline更新数据
PUT tech_blogs/_doc/1
{
"title":"Introducing big data......",
"tags":"hadoop,elasticsearch,spark",
"content":"You konw, for big data"
}
#使用pipeline更新数据
PUT tech_blogs/_doc/2?pipeline=blog_pipeline
{
"title": "Introducing cloud computering",
"tags": "openstack,k8s",
"content": "You konw, for cloud"
}
#查看两条数据,一条被处理,一条未被处理
POST tech_blogs/_search
{}

除了上面的例子,我们还可以在前面提到的重构索引的 api _update_by_query中使用 ingest pipeline。但是如果基于上面的数据直接执行的话,会得到类型转换异常的错误,因为有一个文档的该字段已经被转成了数组类型,对应 java 中的 ArrayList,"split"操作需要的是一个字符串类型字段,而此时它已经不是一个 String,解决方法看下面。
#update_by_query 会导致错误
POST tech_blogs/_update_by_query?pipeline=blog_pipeline
{
}

此时我们可以通过设置 _update_by_query的 api 设置查询参数实现将我们更新过的数据进行过滤。可以看到我们前面设置的 pipeline 中其实还设置了一个给文档增加一个新字段 view 的操作。所以我们可以将查询条件设置为必须不存在一个 view字段的数据才进行 _update_by_query 操作。此时再对该字段指定我们前面设置的pipeline,就不会遇到已经被处理过的数据了,即可正常执行。
#增加update_by_query的条件
POST tech_blogs/_update_by_query?pipeline=blog_pipeline
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "views"
}
}
}
}
}
¶3、一些内置Processors
-
Split Processor (例:将给定字段值分成⼀一个数组)
-
Remove / Rename Processor (例:移除⼀个重命名字段)
-
Append (例:为商品增加⼀个新的标签)
-
Convert(例:将商品价格,从字符串转换成 float 类型)
-
Date / JSON(例:⽇期格式转换,字符串转 JSON 对象)
-
Date Index Name Processor (例:将通过该处理器的⽂档,分配到指定时间格式的索引中)
-
Fail Processor (⼀旦出现异常,该 Pipeline 指定的错误信息能返回给用户)
-
Foreach Process(数组字段,数组的每个元素都会使⽤到一个相同的处理器)
-
Grok Processor(⽇志的⽇期格式切割)
-
Gsub / Join / Split(字符串替换 / 数组转字符串/ 字符串转数组)
-
Lowercase / Upcase(⼤小写转换)
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/ingest-processors.html
¶4、Ingest Node v.s. Logstash
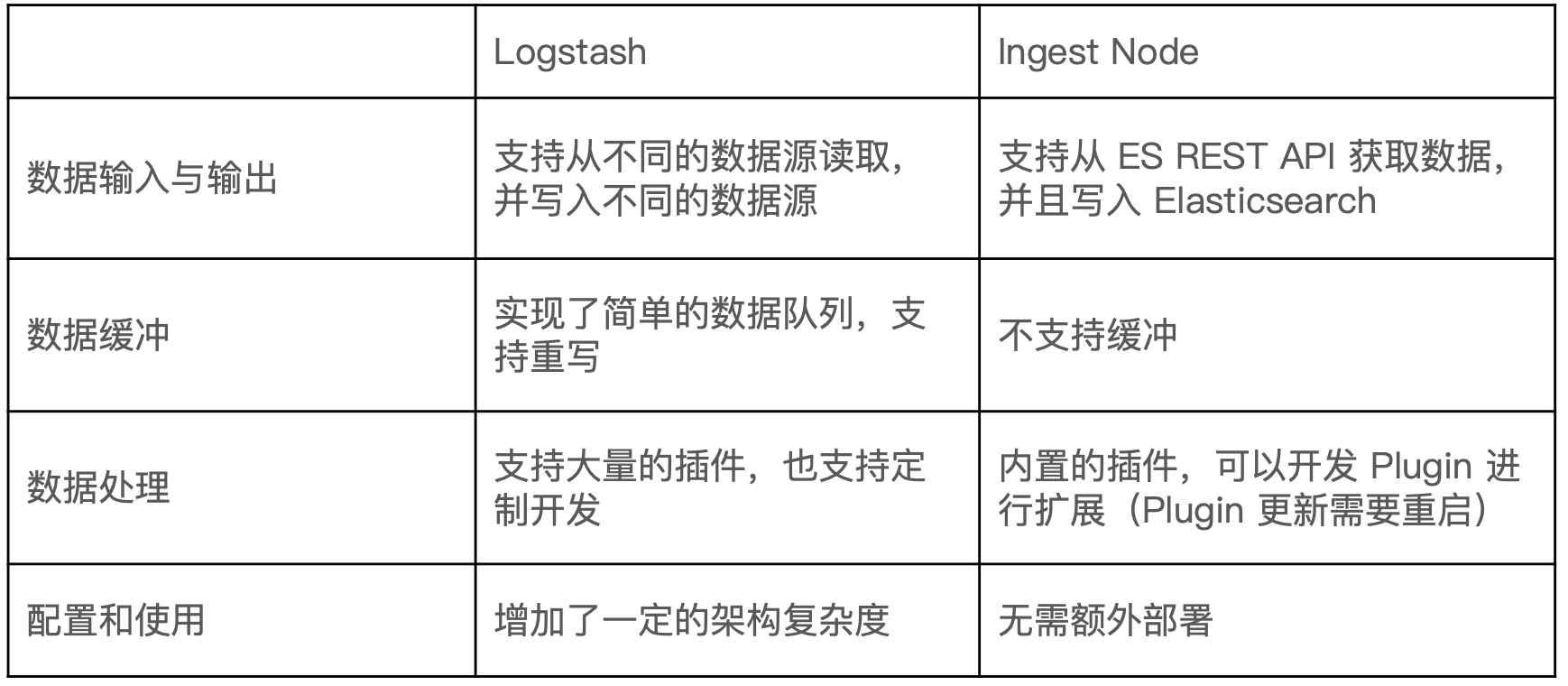
我应该使用 logstash 还是 es ingest node:https://www.elastic.co/cn/blog/should-i-use-logstash-or-elasticsearch-ingest-nodes
¶Painless
自 Elasticsearch 5.x 后引入,专门为 Elasticsearch 设计,扩展了 Java 的语法。
6.0 开始,ES 只支持 Painless。Groovy、Javascript 和 Python 都不再支持。
Painless 支持所有 Java 的数据类型及 Java API 子集。具备以下特性:
- 高性能
- 安全
- 支持显示类型或者动态定义类型
Painless 的用途:
- 可以对文档字段进行加工处理:
- 更新或者删除字段,处理数据聚合操作
- Script Field:对返回的字段提前进行计算
- Function Score:对文档的算分进行处理
- 在 Ingest Pipeline 中执行脚本
- 在 Reindex API、Update By Query 时,对数据进行处理
¶1、在 Painless 脚本中访问字段
在 Painless 脚本中访问字段根据当前使用脚本的上下文的不同对字段的访问语法也不同,具体参考下列表格:
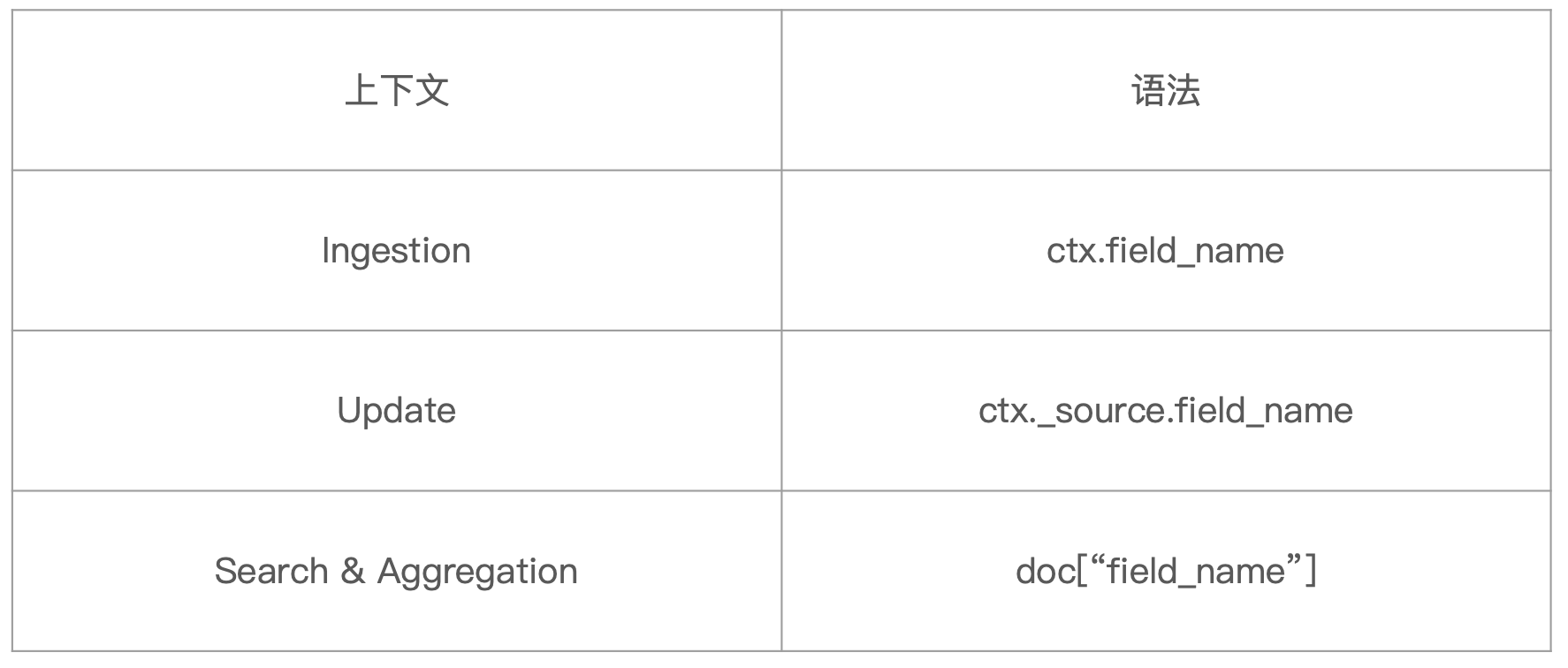
可以看到在 Ingestion 中,ctx 引用的是文档的 _source 属性对象;在 Update 的时候,ctx 引用的就是文档对象;在 Search 和 Agg 的时候, 没有提供 ctx 的引用,提供了一个 doc 的引用,引用的是文档的 _source 属性对象。
¶2、 在 Ingest Pipeline 中的使用示例
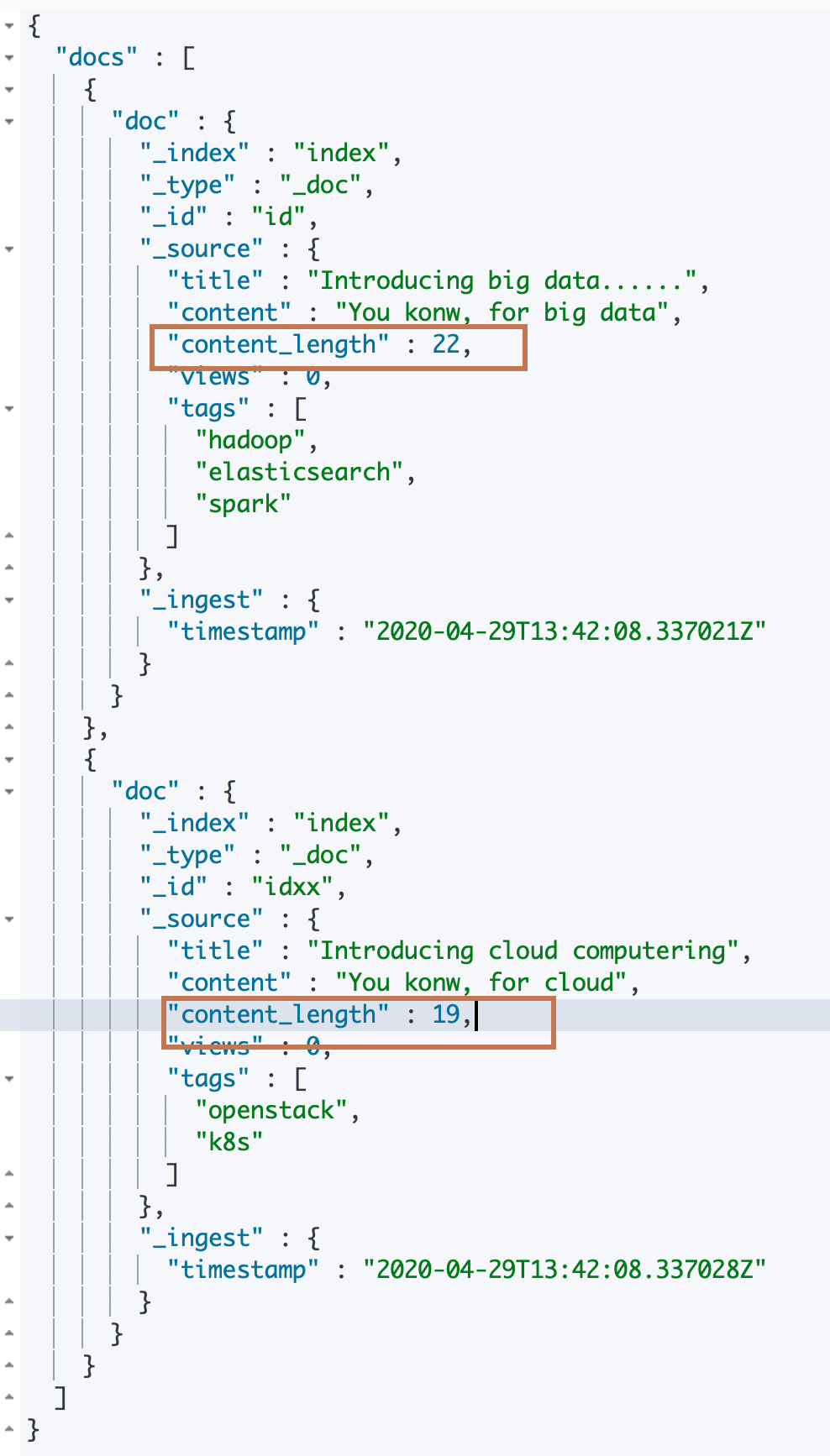
可以看到在下面的例子中,我们在之前的 ingest pipeline 中加入了一个新的 processor,这是一个"script" processor。它需要处理的字段是"source"。即直接访问文档的封装了所有字段的属性。处理逻辑是:如果文档(的 _source)中包含一个 content 字段,就将该字段的长度设置到一个"content_length"字段中,没有该字段就新增;如果不包含一个 content 字段,则直接设置 content_length 为0。
可以看到输出结果中增加了一个 content_length 字段,值为 content 的内容长度。
# 增加一个 Script Prcessor
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description": "to split blog tags",
"processors": [
{
"split": {
"field": "tags",
"separator": ","
}
},
{
"script": {
"source": """
if(ctx.containsKey("content")){
ctx.content_length = ctx.content.length();
}else{
ctx.content_length=0;
}
"""
}
},
{
"set":{
"field": "views",
"value": 0
}
}
]
},
"docs": [
{
"_index":"index",
"_id":"id",
"_source":{
"title":"Introducing big data......",
"tags":"hadoop,elasticsearch,spark",
"content":"You konw, for big data"
}
},
{
"_index":"index",
"_id":"idxx",
"_source":{
"title":"Introducing cloud computering",
"tags":"openstack,k8s",
"content":"You konw, for cloud"
}
}
]
}
¶3、在文档字段更新中使用示例
我们先是初始化了一个浏览数是0的博客文档。然后在更新的时候使用了一个"script"类型的更新操作,在其子属性source 中指定了 painless 脚本的内容,并可以利用请求体中的 script 对象的子属性构建脚本执行的时候的参数上下文。
例如下面例子中我们给"script"设置了一个"params"属性对象,并给该对象设置了一个"new_views:100"的属性对。此时脚本在执行的时候会将"script"对象作为其上下文的一部分,在识别脚本中的"params.new_views"部分的时候就可以匹配到"scirpt"对象的"params.newviews"属性值100了。所以构成的更新语义就是将 id 为1的文档的 views 字段的值加上100。
DELETE tech_blogs
# 输入一个博客文档,并设置其浏览数 view 为0
PUT tech_blogs/_doc/1
{
"title":"Introducing big data......",
"tags":"hadoop,elasticsearch,spark",
"content":"You konw, for big data",
"views":0
}
# 将id 为1的博客文档的浏览数加上100
POST tech_blogs/_update/1
{
"script": {
"source": "ctx._source.views += params.new_views",
"params": {
"new_views":100
}
}
}
# 查看views计数
POST tech_blogs/_search
{
}
¶4、在搜索的时候使用示例
参考下面的例子,我们在 _search api 中指定了一个 “script_fields” api,然后再后面定义了一个match_all 的"query" api。
- match_all query api 表示查询出所有文档数据
- 而 _search 会将 query 得到的文档数据输入到定义在它下面的"script_fields"对象中,该对象的子属性名"rnd_views"将表示当前"script_fields"的名称。而"rnd_views"属性对象中我们通过指定该对象的子属性"lang"为 palinless 标识它为一个 painless 脚本,并在 source 中填入了脚本内容,脚本逻辑为调用 Java 的 Random 函数随机生成一个值并加上每一个文档中的 views 字段的值。
可以看到返回的结果中只包含了"script_fields"的结果,文档的字段都没有被返回。
GET tech_blogs/_search
{
"script_fields": {
"rnd_views": {
"script": {
"lang": "painless",
"source": """
java.util.Random rnd = new Random();
doc['views'].value+rnd.nextInt(1000);
"""
}
}
},
"query": {
"match_all": {}
}
}

¶5、脚本缓存
上面的在 api 中直接输入脚本的源字符串,在 api 执行的时候实时编译脚本,这种脚本叫做 inline script;此外还可以将脚本进行预编译之后缓存到 ES 中,之后可以直接通过预编译的脚本 id 直接对编译后的脚本对象进行调用,而这种脚本叫做 Stored Script。
脚本的预编译通过 _script api 实现,可以看到下面例子中先是对脚本进行了预编译并,然后直接通过脚本 id 调用预编译之后的脚本。
#保存脚本在 Cluster State
POST _scripts/update_views
{
"script":{
"lang": "painless",
"source": "ctx._source.views += params.new_views"
}
}
# 通过指定script 的 id直接取出编译后的脚本进行使用
POST tech_blogs/_update/1
{
"script": {
"id": "update_views",
"params": {
"new_views":1000
}
}
}
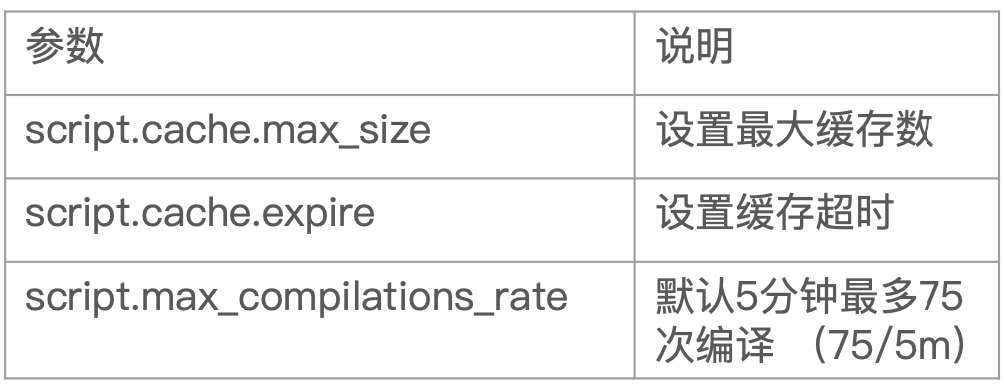
因为脚本编译的开销相较大,所以推荐使用预编译的脚本。在 ES 中,对于Inline Scripts 和 Stored Scripts 都会进行缓存,默认缓存数量是100个。可以通过以下参数进行设置。
¶相关阅读
https://www.elastic.co/cn/blog/should-i-use-logstash-or-elasticsearch-ingest-nodes
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/ingest-apis.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/ingest-processors.html
https://www.elastic.co/guide/en/elasticsearch/painless/7.1/painless-lang-spec.html
https://www.elastic.co/guide/en/elasticsearch/painless/7.1/painless-api-reference.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/ingest-processors.html
https://www.elastic.co/cn/blog/should-i-use-logstash-or-elasticsearch-ingest-nodes
Elasticsearch 数据建模
数据建模(Data modeling),是创建数据模型的过程。数据模型是对真实世界进行抽象描述的一种工具和方法,实现对现实世界的映射。
数据建模包含3个过程:
- 概念模型
- 逻辑模型
- 数据模型(第三范式):结合具体的数据库,在满足业务读写性能等需求的前提下,确定最终的定义。
数据建模一般基于功能需求和性能需求两个角度进行考虑:
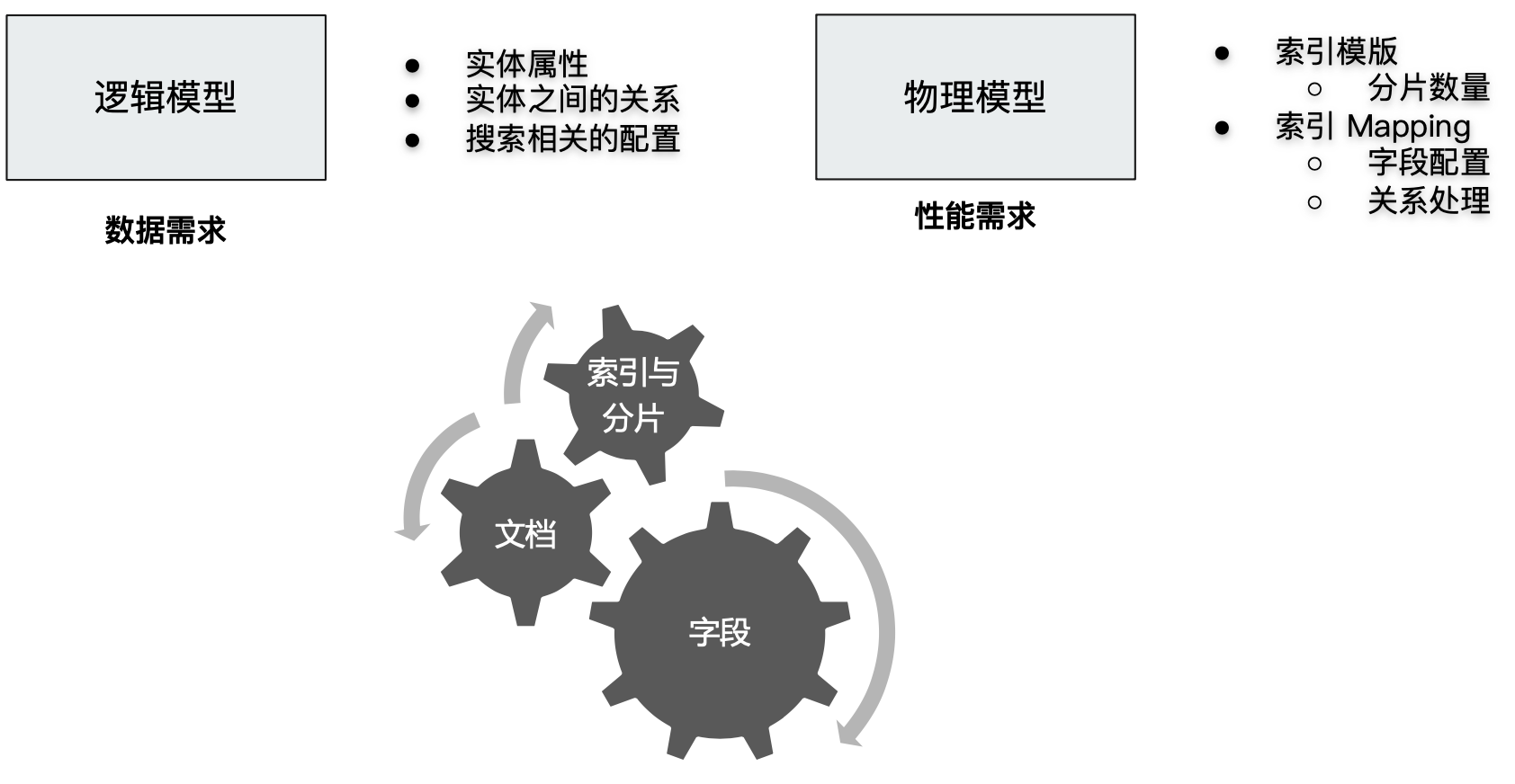
那么在 ES 中我们应该如何进行数据建模呢?ES 中数据建模主要分为两方面:一方面是对于索引、文档和对象关系的规划建模;另一方面是对于文档字段的建模。
¶字段建模
在对字段建模的过程,我们一般从以下4个方面进行分析:

¶1、字段类型
- Text & Keyword
- Text:用于全文本字段,文本会被 Analyzer 分词。默认不支持聚合分析及排序,需要设置 fielddata 为 true。
- keyword:用于 id,枚举及不需要分词的文本。例如电话号码、email 地址、手机号码、邮政编码、性别等。适用于字段需要被 Filter(精确匹配),Soring 和 Aggregation 的场景。
- 设置多字段类型:如果用户没有在 mappnig 中显式设置字符串字段的类型,ES 默认会将其设置为 text 类型并且设置一个 keyword 的子字段。在处理人类语言时,通过增加"英文","拼音"和"标准"分词器,提高搜索结构。
- 结构化数据
- 数值类型:尽量选择贴近的类型。例如可用用 byte,就不要用 long。
- 枚举类型:设置为 keyword。即便时数字,也应该设置成 keyword,获取更好的性能。
- 其他:日期、布尔、地理信息… …都需要将其设置为正确的字段类型。
¶2、是否需要搜索
- 如果不需要对该字段进行检索、排序和聚合分析:Enable 设置为 false。
- 如果仅仅是不需要检索:只将 index 设置为 false。
- 对需要检索的字段,可以通过如下配置:
- index_options:设置索引的粒度
- norms:该字段用于在查询的时候进行查询的分值字段的,如果对这个字段的查询不需要计算分值,可以关闭这个选项,它也会占用一定的存储空间。
- … …
¶3、聚合及排序
- 如果不需要对该字段进行检索、排序和聚合分析:Enable 设置为 false。
- 如果仅仅是不需要排序或者聚合分析功能:Doc_values/fielddata 设置为 false。
- 更新频繁、聚合查询频繁的 keyword 类型的字段:推荐将 eager_global_ordinals 设置为 true。
¶4、额外的存储
文档的所有字段默认都是存储在 _source 字段下的,我们需要基于一些特定场景来判断是否需要将这些字段存储在 _source 之外。
-
_source 字段是否必须:当文档中的内容相当大或者查询文档并不需要每次都返回所有字段的内容的时候,基于节约磁盘的角度,可以考虑 disable _source。当 disable _source 字段之后:
- 将在查询的时候在文档的返回结果中无法看到 _source 字段
- 且无法做 reindex,无法做 update
- Kibana 中无法做 discovery
所以一般建议先考虑增加压缩比来节约磁盘。一般是一些指标型数据适合关闭 _source,参考下图中的官方描述:

- 是否需要专门存储当前字段数据,Store 设置成 true,可以对该字段的原始内容进行专门的存储。一般结合 _source 的 enable 设置为 false 使用。
¶5、一个字段建模实例
-
使用 ES 的默认 Dynamic Mapping 创建索引 Mapping。可以看到我们下面先是索引了一本书的信息,其包含以下字段信息:
- 书名
- 简介
- 作者
- 发行日期
- 图书封面链接
ES 会为我们默认创建一个索引。可以看到所有字段都设置成了 text 类型并且增加了一个keyword 类型的子字段。
# Index 一本书的信息 PUT books/_doc/1 { "title":"Mastering ElasticSearch 5.0", "description":"Master the searching, indexing, and aggregation features in ElasticSearch Improve users’ search experience with Elasticsearch’s functionalities and develop your own Elasticsearch plugins", "author":"Bharvi Dixit", "public_date":"2017", "cover_url":"https://images-na.ssl-images-amazon.com/images/I/51OeaMFxcML.jpg" } #查询自动创建的Mapping GET books/_mapping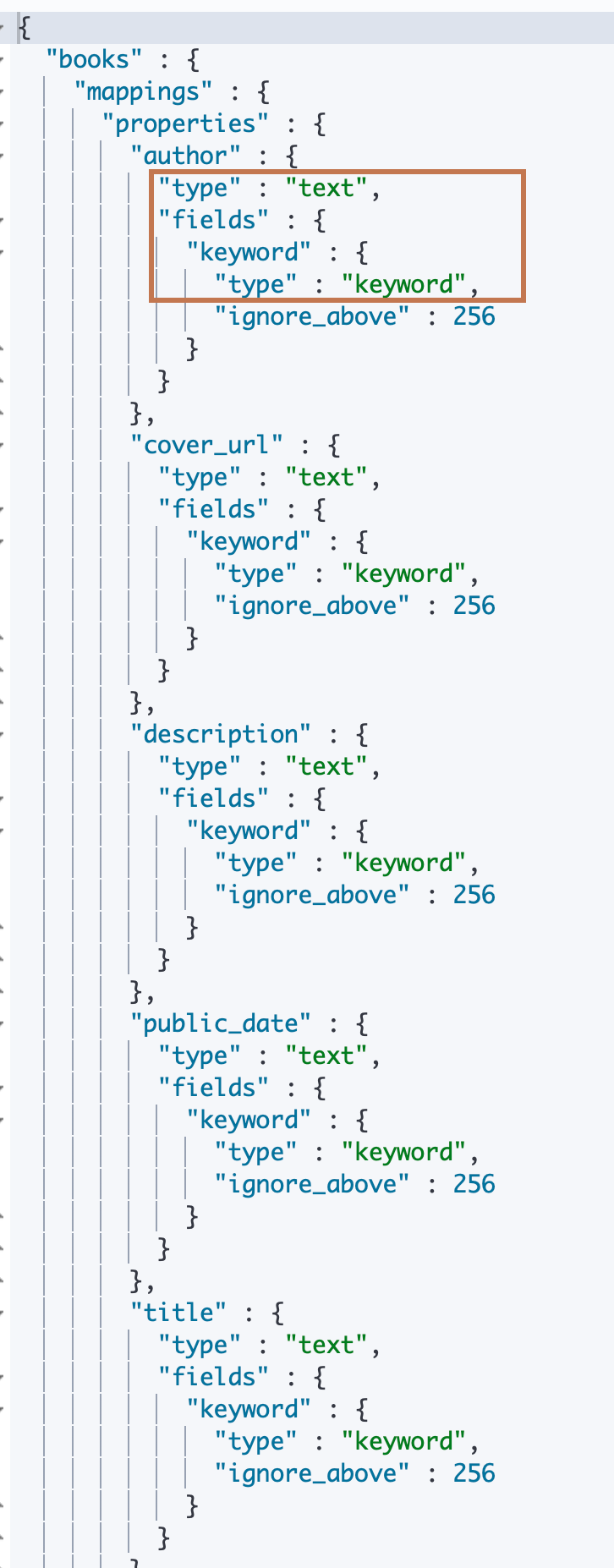
-
优化字段设定。
- 类型:我们知道,图书的作者、封面链接都是一个精确值,所以将它们都设置为 keyword;另外,将发行日期设置为日期格式;而简介时不需要一个 keyword 子字段的,它本身在99.99%的情况下都不会作为一个精确值被检索,所以无需再针对这个字段进行精确索引;而书名在一般情况下都会支持全文检索和精确检索两种情况,所以保持默认类型不用变化。
- 是否需要索引:对于封面链接,一般是不会有人基于该字段来检索图书,所以我们设置 index 为 false。
DELETE books #优化字段类型 PUT books { "mappings" : { "properties" : { "author" : {"type" : "keyword"}, "cover_url" : {"type" : "keyword","index": false}, "description" : {"type" : "text"}, "public_date" : {"type" : "date"}, "title" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 100 } } } } } } #Cover URL index 设置成false,无法对该字段进行搜索,尝试对该字段进行搜索会报错。 POST books/_search { "query": { "term": { "cover_url": { "value": "https://images-na.ssl-images-amazon.com/images/I/51OeaMFxcML.jpg" } } } } #Cover URL index 设置成false,依然支持聚合分析 POST books/_search { "aggs": { "cover": { "terms": { "field": "cover_url", "size": 10 } } } } -
需求变更。现在我们收到了新的需求变更,需要在图书文档中增加一个图书内容的字段,并要求能对图书的内容进行全文检索的同时支持高亮显示。
这个新需求会导致 _source 的内容过大。默认情况下对于文档的检索无论是 data node 返回数据给 coordinating node 还是 coordinating node 返回数据给用户都会携带着 _source 一起返回,这样每次查询无论用户是否真的需要获取全部的字段(或者数据量比较大的图书内容字段)信息都会导致大量数据的传输。
考虑到图书信息一般在导入之后就不再会有 update 操作,我们可以通过关闭 _source 字段,并将所有字段的 “store” 设置为 true 来解决问题。下面我们删除图书索引并重新设置 mapping,然后重新索引一个图书文档。
DELETE books #新增 Content字段。数据量很大。选择将Source 关闭 PUT books { "mappings" : { "_source": {"enabled": false}, "properties" : { "author" : {"type" : "keyword","store": true}, "cover_url" : {"type" : "keyword","index": false,"store": true}, "description" : {"type" : "text","store": true}, "content" : {"type" : "text","store": true}, "public_date" : {"type" : "date","store": true}, "title" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 100 } }, "store": true } } } } # Index 一本书的信息,包含Content PUT books/_doc/1 { "title":"Mastering ElasticSearch 5.0", "description":"Master the searching, indexing, and aggregation features in ElasticSearch Improve users’ search experience with Elasticsearch’s functionalities and develop your own Elasticsearch plugins", "content":"The content of the book......Indexing data, aggregation, searching. something else. something in the way............", "author":"Bharvi Dixit", "public_date":"2017", "cover_url":"https://images-na.ssl-images-amazon.com/images/I/51OeaMFxcML.jpg" }此时尝试查询的时候,_source 字段关闭了,ES 默认是不会返回文档额外存储的字段的。
#查询结果中,Source不包含数据 POST books/_search {}
我们需要指定 API 中具体需要操作或者查询的字段
- 下面我们通过在 _search API 的 "stored_fields"的动作对象,这个对象会抓取经过查询出来的文档数据的具体字段值然后封装到一个"fields"对象中,这个"fields"对象会作为返回信息的文档对象的一个属性值返回,这样我们就能看到一个文档中我们指定的具体字段信息了。
- 另外我们还通过在 _search API 的 “highlight” 动作对象,该对象和"stored_fields"对象的逻辑差不多,只不过它在从文档的(用户)指定字段中把字段数据抓取出来之后经过高亮标签拼接再封装到一个"highlight"对象,然后设置到返回信息的文档对象的"highlight"属性中。
#搜索,通过store 字段显示数据,同时高亮显示 conent的内容 POST books/_search { "stored_fields": ["title","author","public_date"], "query": { "match": { "content": "searching" } }, "highlight": { "fields": { "content":{} } } }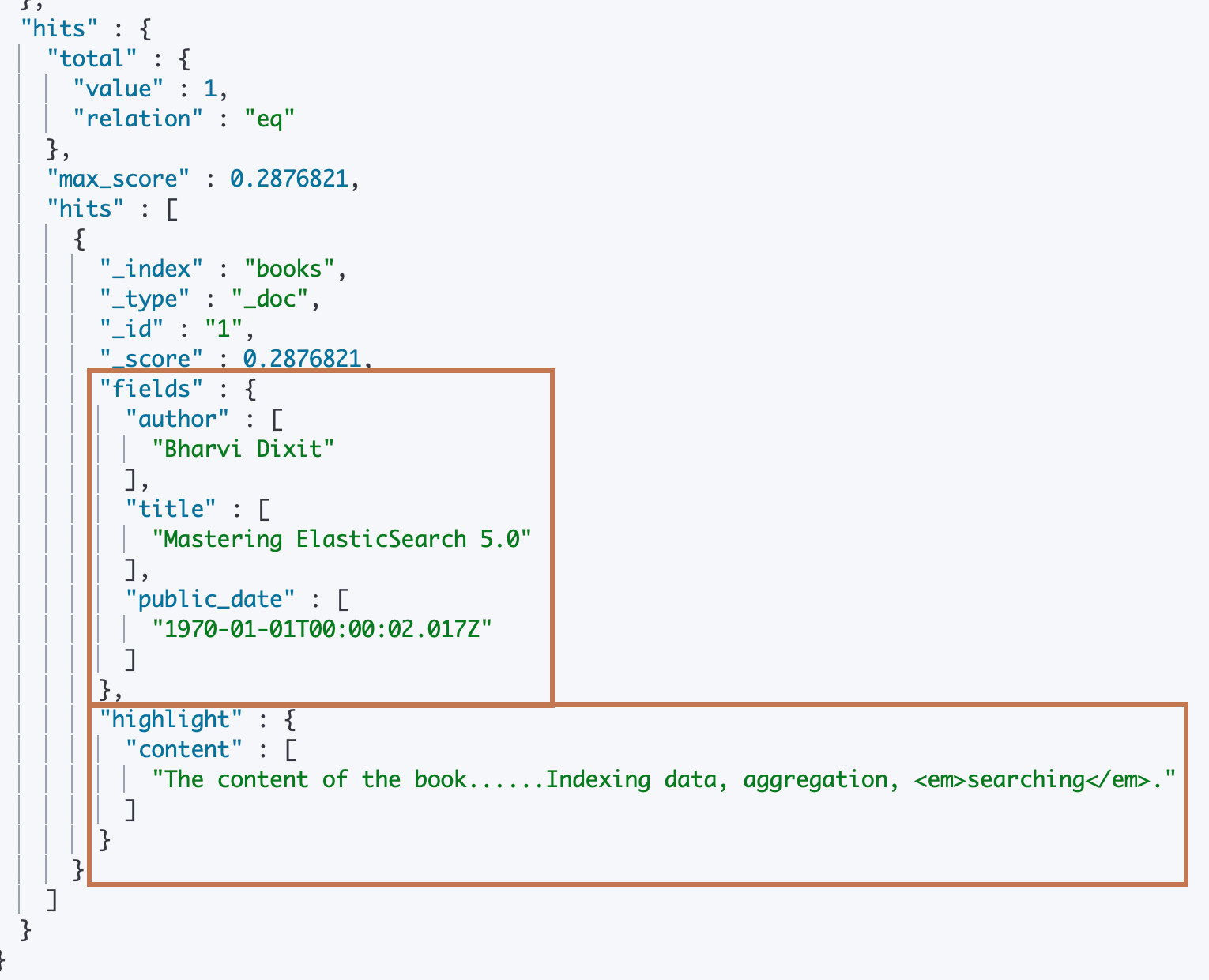
¶6、Mapping 字段的相关设置
- Enabled – 设置成 false,仅做存储,不支持搜索和聚合分析 (数据保存在 _source 中)
- Index – 是否构倒排索引。设置成 false,⽆法被搜索,但还是支持 aggregation,并出现在 _source中
- Norms – 如果字段仅用做过滤和聚合分析,可以关闭,节约存储
- Doc_values – 是否启⽤用 doc_values,用于排序和聚合分析
- Field_data – 如果要对 text 类型启用排序和聚合分析, fielddata 需要设置成true
- Store – 默认不存储,数据默认存储在 _source。
- Coerce – 默认开启,是否开启数据类型的自动转换(例如,字符串转数字)
- Multifields 多字段特性
- Dynamic – true / false / strict 控制 Mapping 的⾃动更新
¶7、数据建模中一些相关的 API
- Index Template & Dynamic Template:根据索引的名字匹配不同的 Mapping 和 Settings。可以在一个 Mapping 上动态的设定字段类型
- Index Alias:无需停机,无需修改程序,修改 alias 之后立即生效,即可使用该 alias(可进行零停机 reindex 等动作)
- Update By Query & Reindex
¶8、相关阅读
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-params.html
¶文档及关系建模及一些数据建模最佳实践
¶建模建议(一):如何处理关联关系
下图就是我们在选择索引中的文档关系的一个优先考虑流程:

需要注意的是:在 Kibana 中目前暂时没有对 nested 类型和 parent/child 类型提供一个很好的支持。在未来有可能会支持。如果需要使用 Kibana 进行数据分析,在数据建模时仍需对嵌套和父子关系类型作出取舍。
¶建模建议(二):避免过多字段
一个文档中,最好避免大量的字段:
- 过多的字段不容易维护
- Mapping 信息保存在 Cluster State 中,数据量过大,对集群性能会有影响(Cluster State 信息需要和所有的节点同步)
- 后期再删除或者修改字段需求 reindex
ES 中默认最大字段数是1000,可以通过设置index.mapping.total)fields.limit限定最大字段数。
可能导致文档中有成百上千的字段的原因:
可能是因为启用了 Dynamic Mapping,用户在对其数据结构不是很准确的了解和控制的情况下会导致一些为止的新字段的写入。所以在生产环境中我们尽量不要使用 Dynamic Mapping。通过 Mapping 中的"_doc.dynamic"属性控制:
- true:未知字段会被自动加入以及索引
- false:新字段不会被索引,但是会保存到 _source
- strict:索引未知字段会失败,直接报错
¶示例:Cookie Service 的数据
我们现在有一个保存 Cookie 的服务,我们打算将 cookie 数据索引到 ES 的一个 cookie_service 中,并在一开始使用了 dynamic mapping,直接索引数据。
可以看到在下面的例子中,我们分别保存了两个 cookies,而两个 cookie 中的含有的键值对是不一样的,主要是 cookie 的键,因为 cookie 是一个可以由用户自定义的一个键值对,所以cookie 对象中的属性字段输入到 ES 可能就会有成千上百以上了!
##索引数据,dynamic mapping 会不断加入新增字段
PUT cookie_service/_doc/1
{
"url":"www.google.com",
"cookies":{
"username":"tom",
"age":32
}
}
PUT cookie_service/_doc/2
{
"url":"www.amazon.com",
"cookies":{
"login":"2019-01-01",
"email":"xyz@abc.com"
}
}
此时,我们可以使用 nested Object 来解决这个问题。看下面的例子,我们删除了原本的 cookie_service 索引,并进行显示 mapping 设置。我们重新定义了索引中文档的"cookies"字段为一个"nested"类型的字段,这个对象有4个属性:
- “name”:存储的就是一个 cookie 键
- 根据cookie 值的不同类型存储到不同的value字段:
- “dataValue”:date 类型
- “keywordValue”:keyword 类型
- “intValue”:integer 类型
经过这样的数据字段抽象定义和约定,我们在写入以上的 cookies 对象的时候,就可以通过对一个对象只支持一组 “key-value” 属性的cookies对象数组来存储到一个URL链接对象中,而不是像一开始那样设置一个 cookies 对象然后设置不同的属性名存储到 URL 链接对象中。
在查询的时候,也需要通过 nested 查询来根据指定的 cookie 信息进行检索。
这样即可起到控制cookies 字段数量但是又支持 cookies 属性自定义的作用。
DELETE cookie_service
#使用 Nested 对象,增加key/value
PUT cookie_service
{
"mappings": {
"properties": {
"cookies": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"dateValue": {
"type": "date"
},
"keywordValue": {
"type": "keyword"
},
"IntValue": {
"type": "integer"
}
}
},
"url": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
##写入数据,使用key和合适类型的value字段
PUT cookie_service/_doc/1
{
"url":"www.google.com",
"cookies":[
{
"name":"username",
"keywordValue":"tom"
},
{
"name":"age",
"intValue":32
}
]
}
PUT cookie_service/_doc/2
{
"url":"www.amazon.com",
"cookies":[
{
"name":"login",
"dateValue":"2019-01-01"
},
{
"name":"email",
"IntValue":32
}
]
}
# Nested 查询,通过bool查询进行过滤
POST cookie_service/_search
{
"query": {
"nested": {
"path": "cookies",
"query": {
"bool": {
"filter": [
{
"term": {
"cookies.name": "age"
}
},
{
"range":{
"cookies.intValue":{
"gte":30
}
}
}
]
}
}
}
}
}
但是虽然通过 Nested 对象保存这种 key/value 数据可以减少字段数量,解决了 Cluster State 中保存过多 Meta 信息的问题,但是同时也导致了查询语句复杂度增加;另外 nested 对象不利于在 Kibana 中实现可视化分析。
¶建模建议(三):避免正则查询
我们应该尽量避免在 ES 中使用正则、通配符查询,特别是将通配符放在开头,会导致性能的灾难。前面也提到 ES 提供了一个基于前缀的 terms 查询,但是性能不够好。
下面我们来分析一个案例提供一些对于"匹配"查询的一些优化思路。
¶示例:模糊查询版本信息
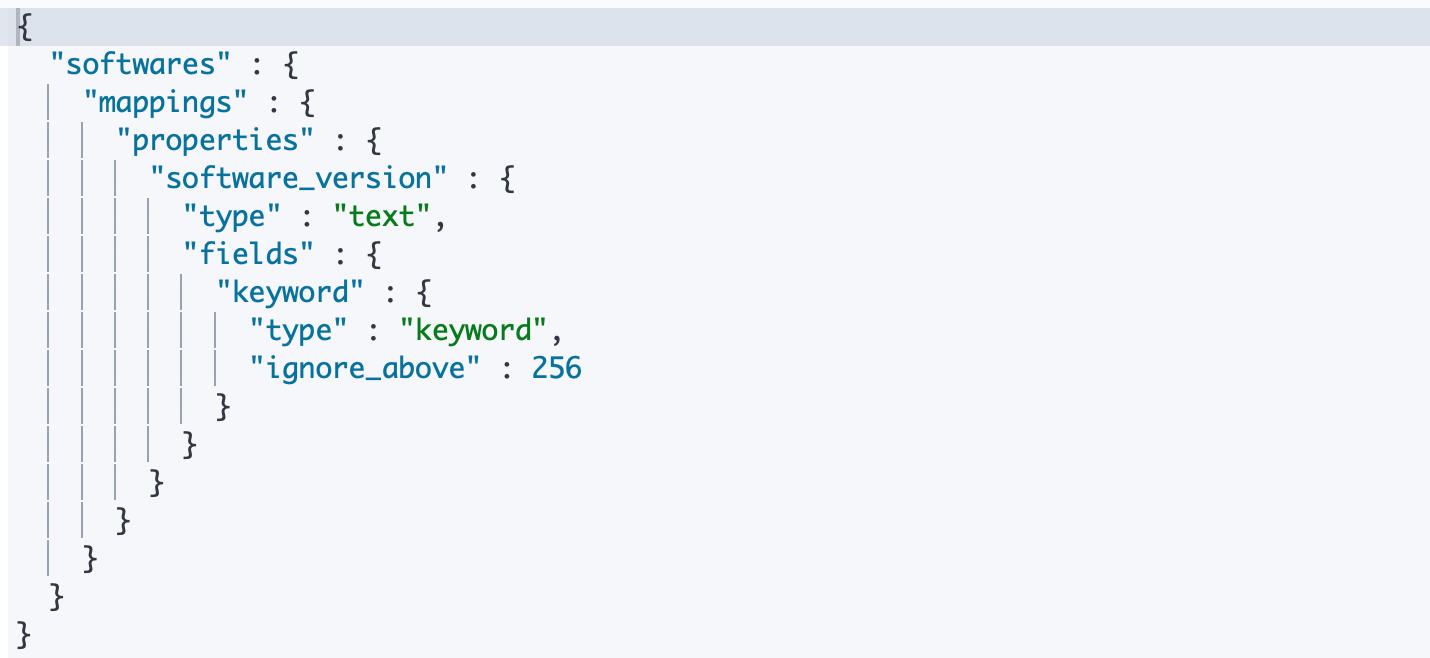
我们拥有一个 softwares 的一个索引,里面索引了一些软件的信息。其中的一个 version 字段包含了软件的版本信息,以 ES 为例,可能包含一个值为"7.1.0"的ES文档。 现在我们需要该字段支持模糊查询,例如:搜索所有是 bug fix 版本的软件并返回每个主版本号所关联的文档?
PUT softwares/_doc/1
{
"software_version":"7.1.0"
}
GET softwares/_mapping
解决方案可以将 version 经过各部分的拆分之后,从字符串类型转为对象类型,可以看到我们为 version 属性设置了4个属性:
- display_name:keyword 类型,维护原始的版本字符串信息
- hot_fix:byte 类型,将版本信息拆分之后截取出来的 hot fix 版本号
- marjor:byte 类型,将版本信息拆分之后截取出来的 major 版本号
- minor:byte 类型,将版本信息拆分之后截取出来的 minor 版本号
这样,原本的"7.1.0"我们就拆成了"hot_fix=7;marjor=1;minor=0",在检索的时候根据具体子版本号使用 bool 查询即可,大大提升性能:
DELETE softwares
# 优化,使用inner object
PUT softwares/
{
"properties": {
"version": {
"properties": {
"display_name": {
"type": "keyword"
},
"hot_fix": {
"type": "byte"
},
"marjor": {
"type": "byte"
},
"minor": {
"type": "byte"
}
}
}
}
}
}
#通过 Inner Object 写入多个文档
PUT softwares/_doc/1
{
"version":{
"display_name":"7.1.0",
"marjor":7,
"minor":1,
"hot_fix":0
}
}
PUT softwares/_doc/2
{
"version":{
"display_name":"7.2.0",
"marjor":7,
"minor":2,
"hot_fix":0
}
}
PUT softwares/_doc/3
{
"version":{
"display_name":"7.2.1",
"marjor":7,
"minor":2,
"hot_fix":1
}
}
# 通过 bool 查询,
POST softwares/_search
{
"query": {
"bool": {
"filter": [
{
"match":{
"version.marjor":7
}
},
{
"match":{
"version.minor":2
}
}
]
}
}
}
¶建模建议(四):避免空值引起的聚合不准
请看下面示例,我们分别一个ratings 索引中创建了两个文档,它们都只有一个字段"rating",文档1的值为5,文档2的值为 null。
然后我们进行了一次对"rating"的 avg metric agg,发现得到的 rating 平均值是5,因为 ES 在进行字段 Metric计算的时候,是会过滤空值的,但是对于用户来说,一个文档在这个字段的空值其实指的应该是该文档语义下该字段的默认值,比如这里的 rating 字段,如果是空我们认为它是排名第一的,在这种语义下,下面的 Metric 结果就是错误的。
PUT ratings/_doc/1
{
"rating":5
}
PUT ratings/_doc/2
{
"rating":null
}
POST ratings/_search
{
"size": 0,
"aggs": {
"avg": {
"avg": {
"field": "rating"
}
}
}
}

基于上面的问题,我们可以通过 mapping.properties.null_value属性来处理空值,这个属性的值就指定了其所属字段的默认值。下面的例子中我们设置了 rating 的字段的默认值是1,这样我们重新索引文档后再进行 metric 操作就能得到一个想要的值了。
# Not Null 解决聚合的问题
DELETE ratings
PUT ratings
{
"mappings": {
"properties": {
"rating": {
"type": "float",
"null_value": 1.0
}
}
}
}
# 重新索引文档
PUT ratings/_doc/1
{
"rating":5
}
PUT ratings/_doc/2
{
"rating":null
}
POST ratings/_search
{
"query": {
"term": {
"rating": {
"value": 1
}
}
}
}
POST ratings/_search
{
"size": 0,
"aggs": {
"avg": {
"avg": {
"field": "rating"
}
}
}
}

¶建模建议(五):为索引的 Mapping 加入 Meta 信息
Mappings 设置非常重要,需要从两个维度进行考虑:
- 功能:搜索、聚合、排序
- 性能:存储的开销、内存的开销、搜索的开销
同时 Mappings 的设置也是一个迭代的过程
-
加入新的字段很容易(必要时需要 update_by_query)
-
更新删除字段不允许(需要 reindex 到一个新的索引)
-
最好能对 Mappings 加入 Meta 信息,更好的进行版本控制
参考下面例子,一开始在 _mapping 中设置了一个 _meta 属性,并在这个属性中再增加一个子属性 software_version_mapping 表示当前 mapping 的版本号,在之后的 mapping 更新中要手动的维护这个版本号:
# 在Mapping中加入元信息,便于管理 PUT softwares/ { "mappings": { "_meta": { "software_version_mapping": "1.0" } } } PUT softwares/_mapping { "_meta": { "software_version_mapping": "2.0" }, "properties": { "new_file": { "type": "keyword" } } } -
可以考虑将 Mapping 文件上传 git 进行管理
¶相关阅读
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/general-recommendations.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/tune-for-disk-usage.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/tune-for-search-speed.html




