Logstash 入门及架构介绍
Logstash 是一款开源的 ETL 工具,支持200多个插件,下面是它可以抽取的一些数据源的例子以及一些支持写入数据的一些例子:
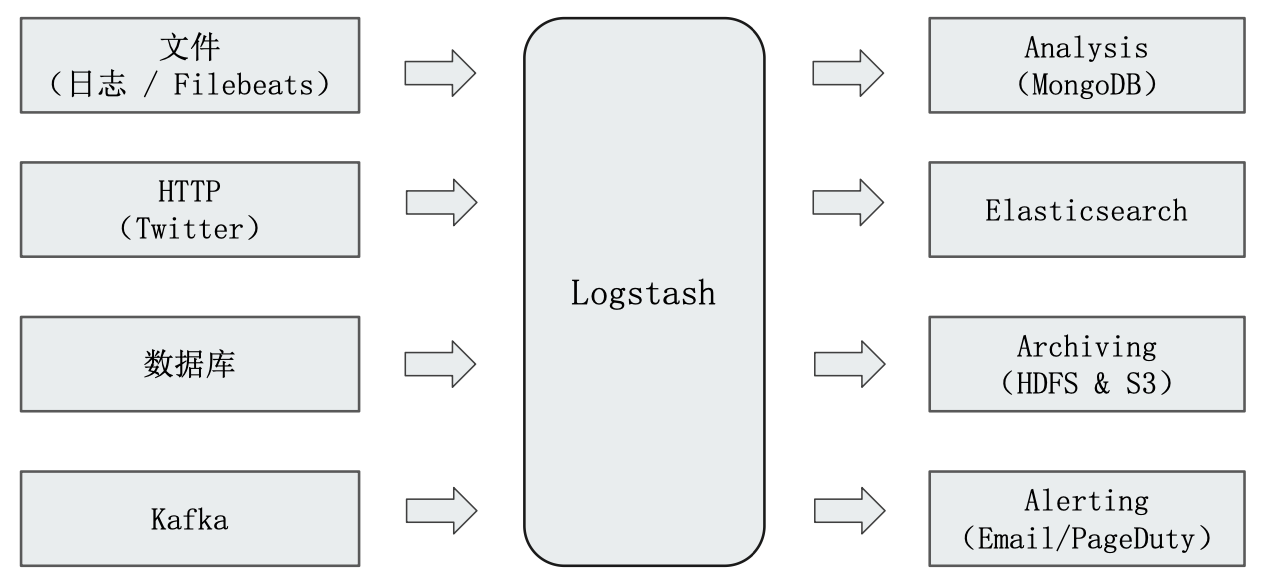
¶Logstash Concepts
-
Pipeline
- 包含了 input-filter-output 三个阶段的处理流程,其中 input是抽取数据、filter 是数据转换、output 是数据输出
- 插件生命周期管理
- 队列管理(Logstash 内部实现了一个消息队列)
-
Logstash Event:数据在内部流转的时候的具体表现形式。数据在 input 阶段被转换成 Event,在 output 的时候被转化成目标格式数据。一个 Event 其实是一个 Java Object,在配置文件中,对 Event 的属性进行增删改查。
-
Codec(code/decode):上面提到的 Event 和原始数据格式、输出数据的格式之间的转换就是由 Codec 完成。在 Logstash 中它指的是两个动作的集合,分别是"将原始数据 decode 成 Event"以及"将 Event encode 成目标数据"。
下面是 Logstash 的一个架构简介:

Input 、Filter 和 Output 三个阶段都是由不同的插件堆砌而成的,例如上面:
- input 我们使用了一个"Stdin"从控制台获取数据以及使用JDBC 获取数据的插件(Logstash 支持多数据源输入)
- 在 FIlter 阶段我们使用 Mutate、Date、User Agent 等转换插件对数据进行转换
- 在 output 的阶段使用了 Elasticsearch 这个插件将数据输出到 ES
¶Queue
Logstash 内部实现了一个消息队列,所有经过 Input 采集到的数据经过 Codec 转换成 Event 之后都会扔到 Queue 中,由 Batcher 自己去Queue 中获取 Event 进行消费,传递给 Filter,完了之后再给 Output。Logstash 的消息是支持持久化的,也就是可以配置数据落盘,这样即使是在运行过程中Logstash 被中止了,已经转换好并入队的 Event 也不会丢失。
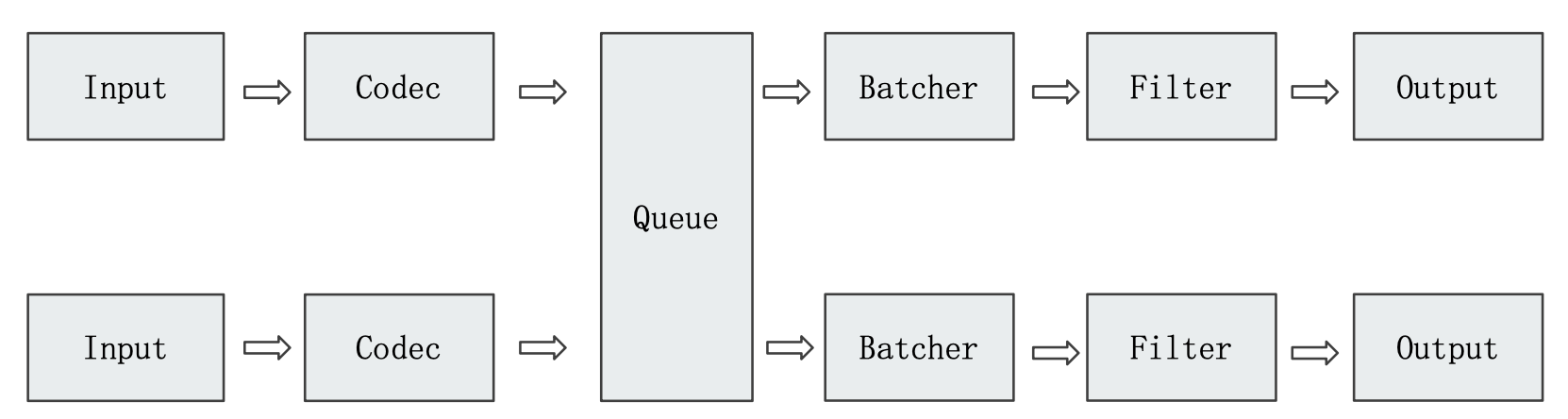
在 Logstash 中,queue 按照存储方式分为两种:
- In Memory Queue:进程 Crash、机器宕机,都会引起数据的丢失,它是默认的存储方式。
- Persistent Queue: 在 pipeline配置文件中配置
Queue.type:persisted,Logstash 会对 queue 中的数据进行落盘,机器宕机数据也不会丢失,保证数据会被消费,一定程度上可以替代 Kafka 等消息队列缓冲区的作用。
另外,queue 的默认大小为4GB,可以通过queue.max_bytes:4GB来实现自定义。
¶Multi-Pipeline
Logstash 除了可以在一个 Pipeline 中有多个 input 之外,其实还可以支持多个 pipeline,以下是多 pipeline 的一个配置示例(pipelines.yml):
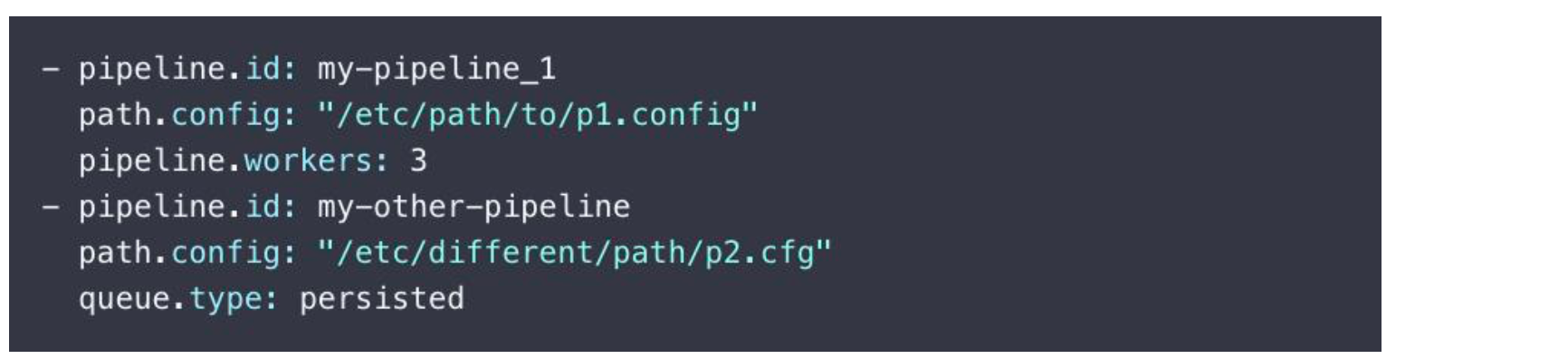
- pipeline.id:指定 pipeline 的唯一标识
- path.config:指定了 pipeline 的逻辑配置文件配置(对应前面介绍到的 logstash-sample.conf)
- pipelnie.works:该配置项配置的是该pipeline的线程数,默认是 CPU 核心数。
- pipeline.batch.size:batcher 一次批量获取等待处理的event (可以认为是 es 中的文档数,也就是"一行数据"),默认是126。需要结合 jvm.options 调节。
- pipeline.batch.delay:batcher 等待时间。
- queue.type:设置queue 的类型是持久的还是基于内存的。
¶LogStash 配置文件
Logstash 配置文件在"${Logstash_Home}/config"下面,分别有
- jvm.options:JVM 配置
- log4j2.properties:日志文件配置
- logstash-sample.conf:一个具体 pipeline 的逻辑的配置样例(对 input、filter、output 进行配置)
- logstash.yml:logstash 本身的一些系统级属性配置
- pipelines.yml: logstash 支持多 pipeline,这是对于pipelines的一些配置
- startup.options:一些启动配置项
¶logstash-sample.conf
下面是一个 Logstash 的 pipeline 逻辑配置文件的示例,可以看到分别分成了 input、filter、output 三个部分。我们通过${Logstash_Home}/bin/logstash -f demo.conf命令即可根据一个 demo.conf 的配置文件来启动 logstash 执行ETL 工作。

下面是一个使用 file input 插件从一个 csv文件中读取数据并经过多个 filter 插件的转换最终使用 elasticsearch output 插件写入到 es 索引中的例子:
input {
file {
path => "/usr/local/software/elasticsearch/movielens/ml-latest-small/movies.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
columns => ["id","content","genre"]
}
mutate {
split => { "genre" => "|" }
remove_field => ["path", "host","@timestamp","message"]
}
mutate {
split => ["content", "("]
add_field => { "title" => "%{[content][0]}"}
add_field => { "year" => "%{[content][1]}"}
}
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host","@timestamp","message","content"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "movies"
document_id => "%{id}"
}
stdout {}
}
¶Input Plugins
一个 Pipeline 可以有 input 插件,Logstash 提供了许多开箱即用的输入插件:
- 一些没有规范格式的输入:Stdin、File
- 一些现有中间件的输入:Beats、Log4J、Elasticsearch、JDBC、Kafka、Rabbitmq、Redis
- 一些抽象协议的输入:JMX、HTTP、Websocket、UDP、TCP
- 一些云存储的输入:Google Cloud Storage、S3
- Github、Twitter
¶Input Plugin:File
支持从文件中读取数据,如日志文件。从文件中读取数据有一些通用的需求,就是一个文件只会被读取一次(数据不被重复读取),如果读取的过程中发生了重启,需要从上一次读取的位置继续,logstash 都实现了这些需求(通过 sincedb 实现,把位置信息保存到 sincedb 中)。
读取到文件新内容,发现新文件的时候都会自动处理。
文档发生归档操作(文档位置发生变化,日志 rotation),不会影响当前的内容读取。
¶Output Plugins
output 是 pipeline 的最后阶段,负责将 Event 发送到特定的目的地。常见的 plugins:
- ELasticsearch
- Email、Pageduty
- Influxdb、Kafka、Mongodb、Opentsdb、Zabbix
- Http、TCP、Websocket
¶Codec Plugins
将原始数据 decode 成 event,将 event encode 成目标数据:
- Line、Multiline
- JSON、Avro、Cef(ArcSight Common Event Format)
- Dots、Rubydebug
¶Codec Plugin:Single Line、dots
通过在pipeline 逻辑配置文件中指定 input 里面的某个 input 插件的 codec 为 line(“codec=>line”)来实现,这会使得 codec 将input 插件抓取过来的数据按照每一行(换行符)数据转换成一个 Event 对象:
- 通过
-e参数在命令行启动 logstash 的时候动态输入配置文件指定 input 为 stdin(codec 为 line),output 为 stdout

-
logstash在启动后就等待着我们的输入,这时候我们输入一个"hello world",可以看到它立马就返回一个输出,然后再等待下一次输入

-
当我们将输出插件中的 codec 从 rubydebug 改成 dots,然后重启 logstash,可以看到我们输入 hello world 之后,dots codec 直接将所有的 events 都转换成了一个点传递给 stdout,控制台就输出了一个点给我们


¶Codec Plugin:json
-
将前面例子中的 stdin 里面的 codec 改成 json,重启 logstash

-
此时还是输入 hello world,此时报了一个 json 转换的异常
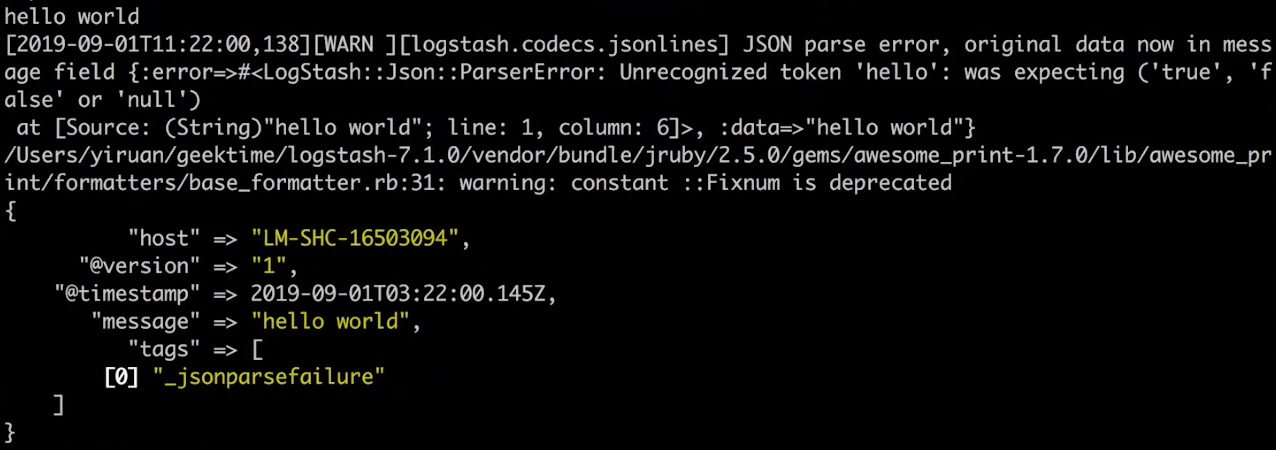
-
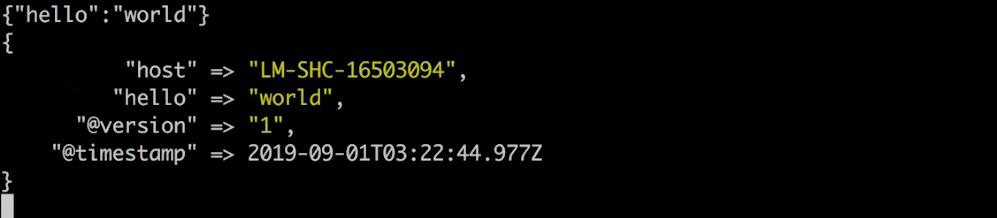
输入{“hello”:“world”},json 转换成功并输出
¶Codec Plugin:Multiline
前面示例中 input 插件中的 codec 都是对输入数据按行转换 events 的,我们可以通过指定 input 插件的 codec 为 multiline,并为 multiline 指定一些参数即可实现多行识别:
- pattern:设置行匹配的正则表达式
- what:如果匹配成功,那么当前行是和前面的行一起作为一个 event (合并到前面的 event 中)还是和后面的行一起作为一个 event(另起一个 event)。
- 参数值:pervious/next
- negate:是否对 pattern 结果取反
- 参数值:true/false
下面是一个具体的例子:
对于以下的一个多行输入:

我们有这么一个配置文件

可以看到我们为标准输入 stdin 配置了一个 multiliine 的 codec:
- 其中 pattern 为 “^\s”
- what 为 “previous”
即当一行数据是以空白字符开头的时候,它就和前面的行数据一起作为一个 event,看到我们前面的一个多行输入,第一行是以"E"开头的,后面三行都是空白字符开头,所以这四行数据都会被作为一个 Event 进行转换。
¶Filter Plugins
处理 event,进行相关的数据转换动作
- Mutate:操作 Event 的字段
- Metrics:Aggregate metrics
- Ruby:执行 Ruby 代码动态修改 Event
- Date:日期解析
- Dissect:分隔符解析
- Grok:正则匹配解析
¶Filter Plugin:Mutate
- Convert:类型转换
- Gsub:字符串替换
- Split、Join、Merge:字符串切割、数组合并字符串、数组合并数组
- Rename:字段重命名
- Update、Replace:字段内容更新替换
- Remove_field:字段删除
¶相关阅读
https://www.elastic.co/guide/en/logstash/7.1/output-plugins.html
https://www.elastic.co/guide/en/logstash/7.1/codec-plugins.html
https://www.elastic.co/guide/en/logstash/7.1/filter-plugins.html
https://www.elastic.co/guide/en/logstash/7.1/persistent-queues.html
利用Logstash JDBC 插件导入数据到 Elasticsearch
¶需求
将数据库中的数据同步到ES,借助 ES 的全文搜索,提高搜索速度。
- 需要把新增用户信息同步到 Elasticsearch 中
- 用户信息 update 后,需要能被更新到 Elasticsearch
- 支持增量更新
- 用户注销后,不能被 ES 搜索到
¶Logstash JDBC Input Plugin & 设计实现思路
¶1、对于新增和更新数据的同步
本节中使用 logstash 的 jdbc 插件实现从 mysql 中抽取数据写入到 ES。这个 jdbc input 插件还支持 Scheduling,其语法来自 Rufus-scheduler,扩展了 Cron,支持时区。所以我们大概的实现思路就是:
- 在每个需要同步数据到 ES 的表中增加了最后更新时间的字段
- 然后启用 jdbc input 插件中的定时任务,定时从数据库中查询最后更新时间大于上一次更新时间的数据(上一次更新时间要进行保存,初始值设置为0),然后将查出来的数据覆盖到 ES,并将其上一次更新时间字段更新为当前时间
需要注意的是,我们需要自备 jdbc 的 jar 包,通过配置文件中的input.jdbc.jdbc_driver_library指定 jar 包路径。( 如果不想指定,就将这个 jar 包拷贝到 Logstash 的 classpath 路径,就是其 jar 包lib 目录,“${logstash_home}/logstash-core/lib/jars”)
上面提到的最后更新时间字段通过配置文件的
input.jdbc.use_column_value、input.jdbc.tracking_column、input.jdbc.tracking_column_type、record_last_run、last_run_metadata_path实现,另外"查询最后更新时间大于上一次更新时间的逻辑"参考input.jdbc.statemetn中的where last_updated > :sql_last_value,sql_last_value貌似是一个关键字,待研究。
input {
jdbc {
jdbc_driver_library => "the_path_of_your_jdbc.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/db_example"
jdbc_user => root
jdbc_password => ymruan123
#启用追踪,如果为true,则需要指定tracking_column
use_column_value => true
#指定追踪的字段,
tracking_column => "last_updated"
#追踪字段的类型,目前只有数字(numeric)和时间类型(timestamp),默认是数字类型
tracking_column_type => "numeric"
#记录最后一次运行的结果
record_last_run => true
#上面运行结果的保存位置
last_run_metadata_path => "jdbc-position.txt"
# 获取数据的 sql
statement => "SELECT * FROM user where last_updated >:sql_last_value;"
# 定时任务 Cron 表达式
schedule => " * * * * * *"
}
}
output {
elasticsearch {
document_id => "%{id}"
document_type => "_doc"
index => "users"
hosts => ["http://localhost:9200"]
}
stdout{
codec => rubydebug
}
}
¶2、对于删除数据的同步
以上都是对于新增和更新数据的同步方案,但是如果是删除数据的话,物理删除对上以上方案中的 logstash 来说是无感知的,因为它都是使用"select *"来获取数据的。所以对于删除数据的同步方案,我们考虑在 mysql 中设置一个"id_deleted"的字段来标识一条记录是否被删除(逻辑删除),在要删除一条数据的时候我们并不是真正地在 mysql 中对其 delete 掉,而是将这行记录地这个字段更新为 true(integer 的 1),然后更新最后更新时间字段为当前时间。
然后我们需要解决的是 ES 中查询逻辑删除地数据的问题,因为即使是逻辑删除的数据在 ES 中也是可以直接查询出来的,如果用户想要根据索引来查询没有删除的数据,就要手动加上一个"is_deleted=false"的条件,很不友好,所以我们可以使用 ES 的 aliases 的功能,为这个索引建议一个 alias,然后在 alias 中定义一个 filter,过滤出那些"is_deleted=false"的数据,这样用户查询的时候直接根据这个 alias 来查询得到全部都是没有被删除的数据了。
# 创建 alias,只显示没有被标记 deleted的用户
POST /_aliases
{
"actions": [
{
"add": {
"index": "users",
"alias": "view_users",
"filter" : { "term" : { "is_deleted" : false } }
}
}
]
}
# 通过 Alias查询,查不到被标记成 deleted的用户
POST view_users/_search
{
}
¶总结
这种方案采用的是轮询"select *"的方式同步数据,其中还经过了 jdbc 协议的转换,性能可能是不太好的,现有的一些比较好的方案都是通过同步 binlog 的方式进行的。



